[Lập trình song song] Bài 8 : Unified memory
Bài đăng này đã không được cập nhật trong 2 năm
Ở bài này mình sẽ giới thiệu về Unified memory - có thể nói Unified memory là 1 bước đột phá lớn vào thời kì cuda 6.0
Unified memory
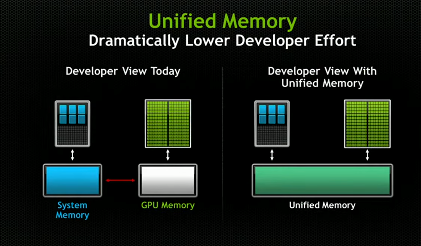
Unified Memory là 1 bộ nhớ đặc biệt (nằm trên CPU) nhưng CPU và GPU đều cùng có thể truy cập trực tiếp mà không cần sao chép dữ liệu qua lại giữa hai loại bộ nhớ riêng biệt.
Đó là lý do tại sao gọi Unified memory dựa trên nguyên lý zero copy
Như mình đã đề cập thì khi nói đến memory thì sẽ luôn đi kèm 2 khái niệm Physical memory và Virtual memory thì Unified memory ở 2 góc nhìn này sẽ có sự khác nhau.
- Virtual memory (developer view): nếu ở góc nhìn này thì Unified memory là 1 bộ nhớ thống nhất giữa CPU và GPU ( tại đó CPU và GPU đều có thể truy cập trực tiếp ).
- Physical memory (computer view) : Như mình đã đề cập thì CPU và GPU là 2 bộ nhớ riêng biệt và không thể truy cập trực tiếp ( mà chỉ thông qua PCIs) và ở đây Unified memory sẽ nằm ở CPU nhưng nhờ vào cơ chế zero copy nên chúng ta mới thấy Unified memory là bộ nhớ thống nhất CPU và GPU lại.
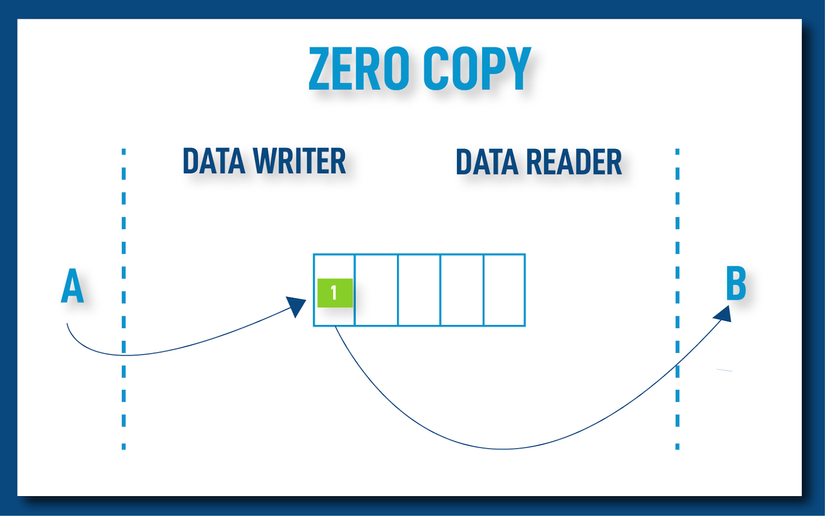
Zero Copy: là một phương thức tối ưu hóa truyền dữ liệu, nơi mà dữ liệu được TỰ ĐỘNG chuyển trực tiếp từ bộ nhớ của một thiết bị này (ví dụ: CPU) sang thiết bị khác (ví dụ: GPU) mà không cần phải qua một bước trung gian (như bộ nhớ đệm - buffer). Điều này giảm đáng kể thời gian và tài nguyên cần thiết cho việc sao chép dữ liệu, từ đó cải thiện hiệu suất.
Tóm tắt
Unified memory là 1 bộ nhớ đặc biệt mà khi chúng ta sử dụng thì không cần phải quan tâm đến quá trình copy h2d hay d2h mà những việc đó sẽ được máy tính làm giúp ==> giúp chúng ta dễ dàng hơn trong việc quản lý bộ nhớ NHƯNG nhờ vào việc tự động nên sẽ không được tối ưu hay còn gọi là page faults

Page faults
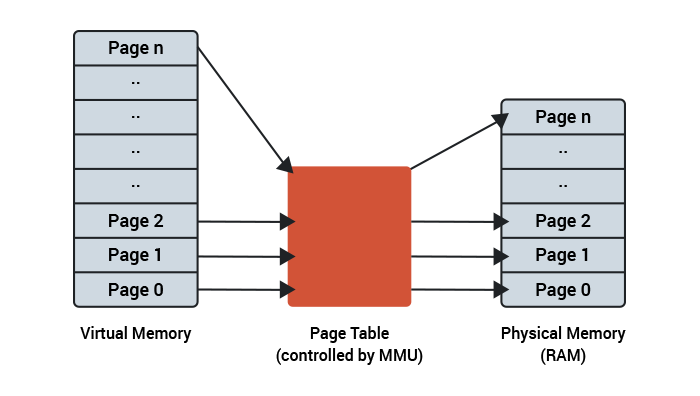
Page faults: là hiện tượng khi CPU hoặc GPU yêu cầu truy cập dữ liệu nào đó trong bộ nhớ của nó nhưng dữ liệu đó chưa được tải về từ Unified memory
Có thể hiểu đơn giản là Unified memory là bộ nhớ trung gian giữa CPU và GPU, khi có sự thay đổi dữ liệu ở Unified memory thì dữ liệu thay đổi đó sẽ được đồng thời thay đổi ở CPU và GPU ( dựa trên cơ chế mapping ) NHƯNG chúng ta sẽ không biết được khi nào dữ liệu đó sẽ được mapping về CPU và GPU nên mới dẫn đến tình trạng page faults ( không tìm thấy dữ liệu yêu cầu )
Và giả sữ xuất hiện tình trạng page faults thì máy tính sẽ thực hiện cơ chế MMU ( memory management unit): thiết bị sẽ gửi yêu cầu page faults tới MMU để kiểm tra xem dữ liệu đó có tồn tại hay không và nếu có thì sẽ được tải về
Như vậy mỗi khi xuất hiện tình trạng page faults thì chúng ta lại phải tốn thêm 1 lượng thời gian đáng kể để MMU tìm kiếm dữ liệu
Và lưu ý là page faults chỉ xảy ra khi ta dùng cơ chế zero copy nói chung và Unified memory nói riêng, tức là những phương pháp thông thường như cudaMemcpy thì sẽ không xuất hiện page faults vì lúc này chúng ta chỉ định rằng copy xong hết mới xử lí, giống như 1 trình tự xong bước này mới tới bước khác
Code
#include <stdio.h>
#include <cassert>
#include <iostream>
using std::cout;
__global__ void vectorAdd(int *a, int *b, int *c, int N)
{
int tid = (blockDim.x * blockIdx.x) + threadIdx.x;
if (tid < N)
{
c[tid] = a[tid] + b[tid];
}
}
int main()
{
const int N = 1 << 16;
size_t bytes = N * sizeof(int);
int *a, *b, *c;
cudaMallocManaged(&a, bytes);
cudaMallocManaged(&b, bytes);
cudaMallocManaged(&c, bytes);
for (int i = 0; i < N; i++)
{
a[i] = rand() % 100;
b[i] = rand() % 100;
}
int BLOCK_SIZE = 1 << 10;
int GRID_SIZE = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;
vectorAdd<<<GRID_SIZE, BLOCK_SIZE>>>(a, b, c, N);
cudaDeviceSynchronize();
for (int i = 0; i < N; i++)
{
assert(c[i] == a[i] + b[i]);
}
cudaFree(a);
cudaFree(b);
cudaFree(c);
cout << "COMPLETED SUCCESSFULLY!\n";
return 0;
}
Đây là 1 đoạn code đơn giản cộng 2 vector sử dụng Unified memory, như các bạn có thể thấy chúng ta đã bỏ đi quá trình copy h2d và d2h và thay vào đó chỉ định int a, b, c được lưu ở Unified memory bằng cudaMallocManaged VÀ như đã đề cập phía trên nên chúng ta cần cudaDeviceSynchronize() để đồng bộ CPU và GPU sau quá trình zero copy NHƯNG đoạn code này sẽ xuất hiện page faults
Và đây sẽ là cách kiểm tra page faults cũng như khắc phục
$nvcc <tên file>.cu
$./a.out
$nsys nvprof ./a.out ( xin lưu ý là để chạy được dòng lệnh này thì các bạn cần tải nsight system, mình đã làm 1 bài viết hướng dẫn tải ở đây)
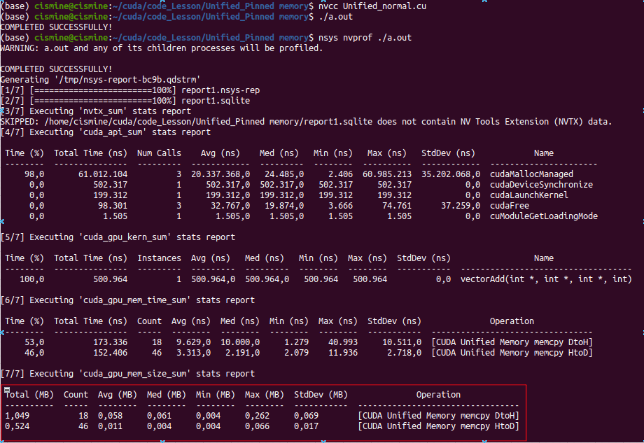
Như trong hình các bạn có thể thấy chúng ta tốn tận 18 lần để copy d2h và 46 lần để copy từ h2d nhờ vào cơ chế zero copy ===> page faults đã xuất hiện
Cách khắc phục
#include <stdio.h>
#include <cassert>
#include <iostream>
using std::cout;
__global__ void vectorAdd(int *a, int *b, int *c, int N)
{
int tid = (blockDim.x * blockIdx.x) + threadIdx.x;
if (tid < N)
{
c[tid] = a[tid] + b[tid];
}
}
int main()
{
const int N = 1 << 16;
size_t bytes = N * sizeof(int);
int *a, *b, *c;
cudaMallocManaged(&a, bytes);
cudaMallocManaged(&b, bytes);
cudaMallocManaged(&c, bytes);
// Get the device ID for prefetching calls
int id = cudaGetDevice(&id);
// Set some hints about the data and do some prefetching
cudaMemAdvise(a, bytes, cudaMemAdviseSetPreferredLocation, cudaCpuDeviceId);
cudaMemAdvise(b, bytes, cudaMemAdviseSetPreferredLocation, cudaCpuDeviceId);
cudaMemPrefetchAsync(c, bytes, id);
// Initialize vectors
for (int i = 0; i < N; i++)
{
a[i] = rand() % 100;
b[i] = rand() % 100;
}
// Pre-fetch 'a' and 'b' arrays to the specified device (GPU)
cudaMemAdvise(a, bytes, cudaMemAdviseSetReadMostly, id);
cudaMemAdvise(b, bytes, cudaMemAdviseSetReadMostly, id);
cudaMemPrefetchAsync(a, bytes, id);
cudaMemPrefetchAsync(b, bytes, id);
int BLOCK_SIZE = 1 << 10;
int GRID_SIZE = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;
vectorAdd<<<GRID_SIZE, BLOCK_SIZE>>>(a, b, c, N);
cudaDeviceSynchronize();
// Prefetch to the host (CPU)
cudaMemPrefetchAsync(a, bytes, cudaCpuDeviceId);
cudaMemPrefetchAsync(b, bytes, cudaCpuDeviceId);
cudaMemPrefetchAsync(c, bytes, cudaCpuDeviceId);
// Verify the result on the CPU
for (int i = 0; i < N; i++)
{
assert(c[i] == a[i] + b[i]);
}
// Free unified memory (same as memory allocated with cudaMalloc)
cudaFree(a);
cudaFree(b);
cudaFree(c);
cout << "COMPLETED SUCCESSFULLY!\n";
return 0;
}
Và lần này chúng ta cũng làm các bước tương tự để xem có page faults hay không
$nvcc <tên file>.cu
$./a.out
$nsys nvprof ./a.out
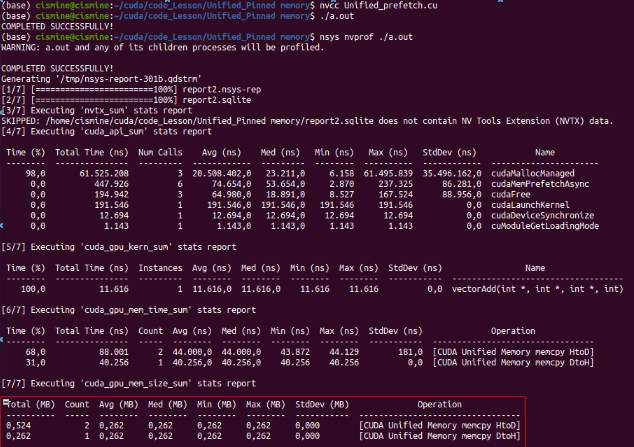
Giải thích
Ở đây chúng ta đã thêm các function đặc biệt như:
-
cudaMemAdvise: đưa ra gợi ý về cách quản lý bộ nhớ ở CPU hoặc GPU, Các gợi ý của cudaMemoryAdvise bao gồm:
- cudaMemAdviseSetReadMostly: Gợi ý rằng vùng nhớ sẽ được truy cập nhiều lần để đọc.
- cudaMemAdviseUnsetReadMostly: Gợi ý rằng gợi ý trước đó không còn được áp dụng.
- cudaMemAdviseSetPreferredLocation: Gợi ý rằng vùng nhớ nên được nằm trên thiết bị GPU nhất định.
- cudaMemAdviseUnsetPreferredLocation: Gợi ý rằng gợi ý trước đó không còn được áp dụng.
- cudaMemAdviseSetAccessedBy: Gợi ý rằng vùng nhớ sẽ được truy cập bởi một hoặc nhiều thiết bị GPU.
- cudaMemAdviseUnsetAccessedBy: Gợi ý rằng gợi ý trước đó không còn được áp dụng.
-
cudaMemPrefetchAsync: được sử dụng để tiền tải dữ liệu từ một vùng nhớ trên host hoặc device vào một vùng nhớ khác trên device hoặc host. Hàm này cho phép bạn tường minh điều khiển quá trình tiền tải dữ liệu để cung cấp sự tối ưu hóa hiệu suất và truy cập dữ liệu hiệu quả trên GPU
file code mình sẽ để ở đây
Bài tập
Viết 1 đoạn script đơn giản để chứng minh tại unified memory thì cả CPU và GPU đều cùng truy cập được
Đáp án mình sẽ để ở đây.
All rights reserved
