[Lập trình song song] Bài 9: Pinned memory
Bài đăng này đã không được cập nhật trong 2 năm
Ở baì viết này mình sẽ nói về khái niệm pinned memory - xin lưu ý là nó sẽ liên quan tới bài tiếp theo ( streaming ) nên sẽ rất tốt nếu các bạn nắm được kiến thức ở bài này.
Pinned memory
Trước khi giải thích pinned memory là gì thì mình sẽ đi qua cách máy tính vận hành khi chúng ta code để hiểu rõ hơn - và yên tâm là mình sẽ giải thích 1 cách đơn giản và dễ hiểu nên không nhất thiết là các bạn phải cần có kiến thức về phần cứng
Cách hoạt động của máy tính
Khi đã nhắc đến memory thì chúng ta luôn luôn có 2 góc nhìn: Physical memory và virtual memory ( hoặc logical memory ).
- Physical memory: bộ nhớ trực tiếp được cài trên CPU và các thanh RAM, được kết nối trực tiếp. Là các ô nhớ nằm trên bo mạch
- Virtual memory: là 1 khái niệm trừu tượng ( giúp người lập trình dễ thao tác hơn ), là bộ nhớ mà hệ điều hành hoặc trình điều khiển quản lí dùng. OS tạo ra logical memory bằng cách sử dụng 1 phần không gian của CPU thông qua việc ánh xạ từ logic --> physical adress trong RAM.
Không gian của virtual memory lớn hơn nhiều so với physical memory.
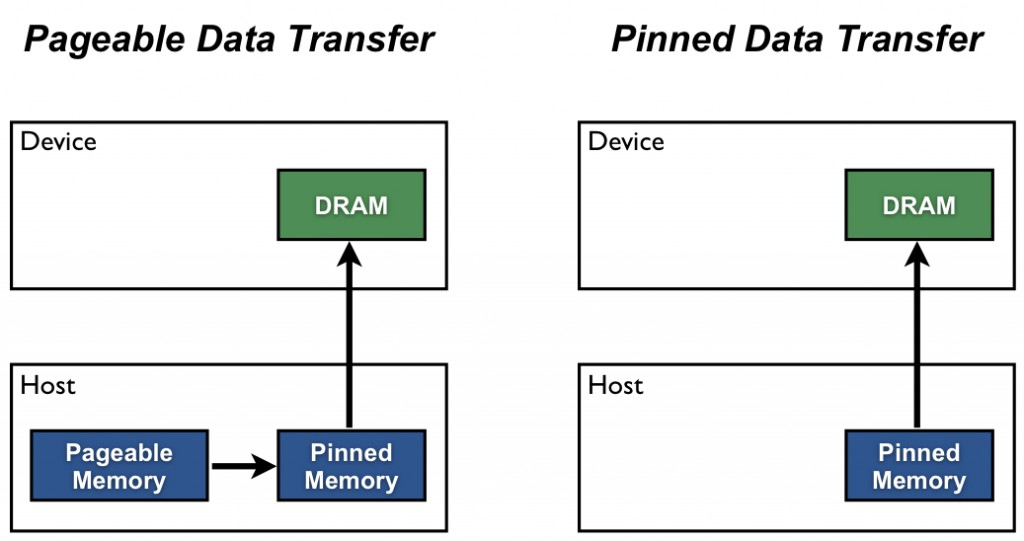
 Ban đầu khi chúng ta cấp phát bộ nhớ cho CPU thì sẽ được nằm trên RAM - Main memory ( physical ) hoặc pageable memory ( logical) và nếu chúng ta muốn copy data từ CPU sang GPU khi data nằm trên pageable memory thì sẽ gây ra 1 vấn đề rất lớn gọi là swapping
Ban đầu khi chúng ta cấp phát bộ nhớ cho CPU thì sẽ được nằm trên RAM - Main memory ( physical ) hoặc pageable memory ( logical) và nếu chúng ta muốn copy data từ CPU sang GPU khi data nằm trên pageable memory thì sẽ gây ra 1 vấn đề rất lớn gọi là swapping
Khi dữ liệu được lưu trữ trong pageable memory, nó có thể không luôn sẵn sàng để truy cập nhanh vì hệ thống có thể chuyển dữ liệu này xuống đĩa cứng (magnetic disk) để giải phóng RAM cho các tác vụ khác. Điều này gọi là "swapping".
Khi dữ liệu cần được chuyển từ CPU sang GPU và dữ liệu đó đang nằm trên đĩa cứng (do quá trình swapping), bạn sẽ gặp phải vấn đề "missing data". Điều này xảy ra bởi vì GPU cần truy cập nhanh vào dữ liệu, nhưng dữ liệu đó lại không sẵn sàng trên RAM.
===> Nên vì vậy cuda đã thực hiện 1 cơ chế trước khi copy từ CPU sang GPU là đẩy tất cả dữ liệu cần được copy sang pinned memory ( có thể hiểu đơn giản là mình đã ghim dữ liệu cần thiết vì vậy nó không thể nào bị đẩy xuống đĩa cứng được ) sau khi đẩy qua hết pinned memory rồi mới bắt đầu copy từ host sang device.
cudaMemcpy: tức là sẽ tốn 2 lần copy ( từ pageable memory ==> pinned memory ==> device memory )
Thay vì phải tốn 2 lần copy, NVIDIA đã phát triển 1 function giúp chúng ta ngay từ đầu chỉ dịnh dữ liệu được lưu ở pinned memory ( chỉ tốn 1 lần copy từ host sang device )
CODE
#include <cassert>
#include <iostream>
using std::cout;
using std::end;
__global__ void vectorAdd(int *a, int *b, int *c, int N)
{
int tid = (blockIdx.x * blockDim.x) + threadIdx.x;
if (tid < N)
{
c[tid] = a[tid] + b[tid];
}
}
void verify_result(int *a, int *b, int *c, int N)
{
for (int i = 0; i < N; i++)
{
assert(c[i] == a[i] + b[i]);
}
}
int main()
{
constexpr int N = 100;
size_t bytes = sizeof(int) * N;
// Vectors for holding the host-side (CPU-side) data
int *h_a, *h_b, *h_c;
// Allocate pinned memory
cudaMallocHost(&h_a, bytes);
cudaMallocHost(&h_b, bytes);
cudaMallocHost(&h_c, bytes);
for (int i = 0; i < N; i++)
{
h_a[i] = rand() % 100;
h_b[i] = rand() % 100;
}
// Allocate memory on the device
int *d_a, *d_b, *d_c;
cudaMalloc(&d_a, bytes);
cudaMalloc(&d_b, bytes);
cudaMalloc(&d_c, bytes);
// Copy data from the host to the device (CPU -> GPU)
cudaMemcpy(d_a, h_a, bytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, bytes, cudaMemcpyHostToDevice);
int NUM_THREADS = 1 << 10;
int NUM_BLOCKS = (N + NUM_THREADS - 1) / NUM_THREADS;
// Execute the kernel
vectorAdd<<<NUM_BLOCKS, NUM_THREADS>>>(d_a, d_b, d_c, N);
// Copy data from device to host (GPU -> CPU)
cudaMemcpy(h_c, d_c, bytes, cudaMemcpyDeviceToHost);
// Check result for errors
verify_result(h_a, h_b, h_c, N);
// Free pinned memory
cudaFreeHost(h_a);
cudaFreeHost(h_b);
cudaFreeHost(h_c);
// Free memory on device
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
cout << "COMPLETED SUCCESSFULLY\n";
return 0;
}
Nó chỉ đơn giản khác ở chỗ cấp phát data cho host là cudaMallocHost
Bài tập
Code 1 đoạn script để so sánh thời gian copy data từ h2d - d2h giữa pageable memory và pinned memory.
code và đáp án mình sẽ để ở đây.
All rights reserved
