[Lập trình song song] Bài bonus 2: Các thuật ngữ trong lập trình song song
Bài đăng này đã không được cập nhật trong 2 năm
Ở bài này mình sẽ giải thích các thuật ngữ thường hay được đề cập tới trong lập trình song song
Lưu ý nhỏ: như lời mở đầu mình đã đề cập, các thuật ngữ mình sẽ giữ nguyên nghĩa tiếng anh chứ không dịch sang tiếng việt trong suốt series này, nếu bạn nào muốn đọc full bằng tiếng anh thì có thể ghé qua github, vì tiếng anh nên từ ngữ dùng sẽ chính xác hơn khi viết lại bằng tiếng việt.
PHYSICAL và LOGICAL
Trước khi giải thích 2 khái niệm 'PHYSICAL' và 'LOGICAL' thì mình sẽ đi qua 1 ví dụ để các bạn có 1 cái nhìn tổng quát và dễ hình dung hơn và xin lưu ý là 2 thuật ngữ này khá quan trọng nên mong các bạn đọc thật kĩ.
Ví dụ:
Một ngôi trường sẽ có nhiều lớp học, và trong 1 lớp học sẽ có nhiều bạn học sinh( số lượng lớp học và học sinh mỗi lớp sẽ tùy vào từng ngôi trường khác nhau dựa trên nhiều yếu tố nhưng vấn đề kinh tế vẫn là hàng đầu). Tiếp đến chúng ta có 1 nùi công việc ( không xác định được số lượng công việc - mình sẽ giải thích rõ ràng ở phần dưới) cần phân phối cho các bạn học sinh xử lí và chúng ta phải tuân thủ các QUY TẮC này:
- Mỗi lớp học chỉ nhận tối đa 1024 công việc
- tại 1 thời điểm, trong 1 lớp học sẽ có (32* số warp) công việc được thực thi ( warp là gì thì mình sẽ giải thích ở phần dưới và số lượng warp sẽ dựa trên kiến trúc của máy tính) => tức là nếu chúng ta có 5 lớp học => sẽ có 32* số warp * 5 công việc được thực thi => N lớp học thì có 32* số warp * N công việc được thực thi
Tóm lại physical có thể hiểu đơn giản là những thứ có thể thấy được, số lượng cố định và trong ví dụ này là các bạn học sinh, logical nói nôm na là thứ không thấy được nhưng mình có thể hình dung và mường tượng ra được, nhưng số lượng không cố định và trong trường hợp này là số công việc
Physical ứng với SM, SP
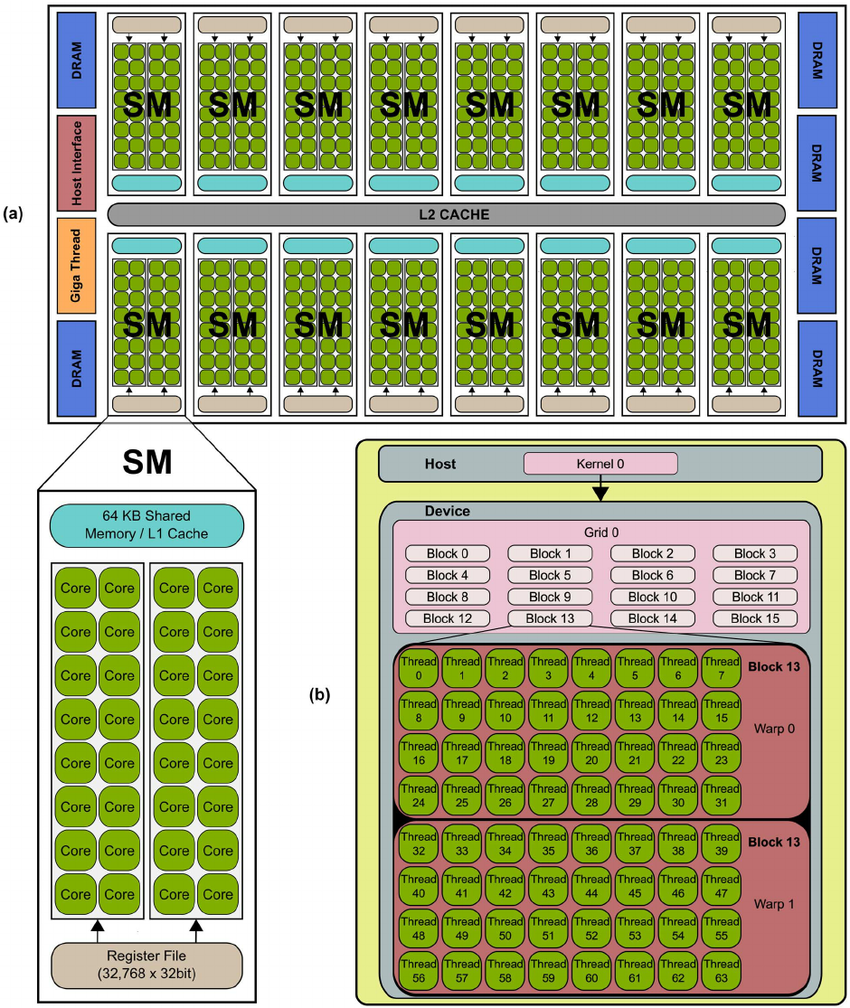
Như trong hình chúng ta có thể thấy có 16SM và trong mỗi SM có 32 core. Vậy SM và core là gì?
- Streaming Processor(viết tắt là SP hay còn gọi quen thuộc là core) là những đơn vị xử lý chính trên GPU và có khả năng thực hiện các phép tính đồng thời trên nhiều dữ liệu => giống như các bạn học sinh (1 học sinh là 1 SP) => chúng ta có càng nhiều SP (học sinh) thì số lượng công việc được xử lí đồng thời càng nhiều
- Streaming Multiprocessor(viết tắt là SM, có 1 số tài liệu ghi là multiprocessor) có thể hiểu đơn giản là tập hợp của các SP, tức là 1 SM có nhiều SP ( SM giống như lớp học vậy)
Số lượng SM và SP sẽ tùy thuộc vào máy tính của mỗi người ( số lượng cố định)
Ở cuối bài viết mình có đưa code để các bạn có thể check SM và SP của mình
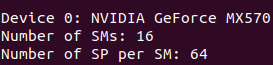

Logical ứng với thread, block, grid
Thread hiểu đơn giản là công việc ( 1 thread là 1 công việc)
Block là tập hợp của các thread ( 1 nùi công việc nhưng tối đa là 1024 threads vì cơ chế của máy tính là vậy áp dụng cho mọi máy tính)
![]()
![]()
Ở đây bạn không cần tập trung quá nhiều về grid mà chỉ cần tập trung vào Thread và Block là được
Công việc ở đây là data, tức là ở mỗi bài toán chúng ta sẽ có số lượng data khác nhau (vì vậy nên mình mới nói là không xác định trước được)
Như trong hình chúng ta có thể thấy có 6 blocks và mỗi block có 12 threads
Các con số (0,0) (0,1) là index dùng để xác định block nằm vị trí nào và thread nằm vị trí nào, giống như ma trận vậy a[1][2] nhưng ở đây cái index nó xác định hơi khác 1 tí, mình sẽ giải thích rõ ở các bài sau.
Ở đây các bạn sẽ có câu hỏi là tại sao chúng ta lại chia các thread ra những block riêng mà không gộp lại thành 1 block siêu lớn đi cho dễ. Nếu chúng ta làm vậy chúng ta sẽ vi phạm QUY TẮC 1 là Mỗi lớp học chỉ nhận tối đa 1024 công việc vậy nên chúng ta mới cần chia nhỏ các thread ( tức là số lượng công việc) ra thành các block.
Và 1 điểm cộng lớn khi chia nhỏ các thread thành các block là vì QUY TẮC 2 : nếu chúng ta có 1024 thread thì chỉ cần 1 block là đủ nhưng tại 1 thời điểm nó chỉ xử lí đc (32* 1) công việc ( giả sử số warp =1 ) thì chúng ta phải đợi nó xử lí xong 32 cái đầu rồi mới tới 32 cái sau và lặp đi lặp lại 1 cách tuần tự.
Nếu lúc này chúng ta chia ra thành 32 block, mỗi block 32 thread (32 * 32=1024) thì có phải chỉ tại 1 thời điểm nó đã xử lí hết 1024 thread rùi hong 32* 1* 32(32* số warp * N )
Nó khá giống với ví dụ ăn bánh, thay vì xử lí tuần tự 32 cái bánh (threads) mỗi lần tại mỗi thời điểm thì lúc này 1024 cái bánh (threads) đã đc xử lí song song
Tóm tắt:
SM(s) là (những) lớp học, 1 SP là 1 học sinh, 1 Thread là 1 công việc, Block là 1 nùi công việc, ở đây bạn có thể tưởng tượng block là 1 cái hộp chứa các công việc(thread) cần xử lí. Và mỗi SM sẽ xử lí 1 số lượng blocks ( tùy thuộc vào số lượng data để chia ra các block)==> 1SP có thể xử lí nhiều hơn 1 thread (1học sinh có thể làm nhiều hơn 1 công việc)
Ở đây sẽ có 1 vấn đề là làm sao để phân phối các công việc(blocks) cho từng lớp học(SM) vì SM,Block là 2 khái niệm riêng biệt( physical và logical) nên chúng nó sẽ không thể tương tác trực tiếp mà phải thông qua trung gian gọi là WARP, vậy thì warp là gì và con số 32 có liên quan gì?
WARP: physical và logical
Physical và logical là 2 khái niệm riêng biệt nên sẽ không thể tương tác trực tiếp được nên phải thông qua trung gian gọi là WARP . Warp ở đây vừa là physical và là logical.
Quay lại ví dụ về trường học, thì warp ở đây là các tổ trưởng của mỗi lớp (số lượng warp (tổ trưởng) sẽ tùy thuộc vào từng máy tính và cái này liên quan đến các kiến trúc như Tesla,Fermi,... và phần này mình sẽ làm 1 bài riêng để nói về những điều này ). các tổ trưởng (các warps) có 2 nhiệm vụ
- là đi lấy các blocks để đem về cho tổ mình xử lí ==> ở đây các blocks đã nằm sẵn trong từng lớp học (SM)
Ở đây có 2 bước, bước 1 là phân phối các blocks cho các SM ( mang các blocks đến từng lớp), bước 2 là lấy blocks đã nằm sẵn trong lớp học và mang đi phân phối cho các bạn học sinh xử lí. Thì warp sẽ thực hiện bước thứ 2, còn bước 1 mình sẽ giải thích ở bài sau
- Sau khi warp mang các block về cho tổ của mình thì warp sẽ làm thêm 1 nhiệm vụ nữa là phân chia công việc cho các thành viên trong tổ. Và mỗi lần phân chia tối đa là 32 công việc 1 lần. Sau khi 32 công việc đó được xử lí xong mới đưa tiếp 32 công việc tiếp theo để xử lí. Tức là tại mỗi thời điểm 1 warp phân phối 32 thread mà mỗi lớp sẽ có nhiều warp ( tổ trưởng) nên số công việc tại 1 thời điểm = (32* số warp) công việc
Ở đây lí do tại sao 1 warp chỉ có thể phân phối tối đa 32 threads thì là do chức năng của máy tính là vậy, áp dụng cho mọi máy tính
Warp (Physical) : tức là các bạn tổ trưởng này sẽ dẫn dắt các bạn học sinh trong tổ của mình hay nói cách khác warp kiểm soát các SP trong việc xử lí công việc ( ví dụ bạn A ĐƯỢC PHÂN CÔNG làm công việc A, bạn B ĐƯỢC PHÂN CÔNG làm công viêc B ....)
warp(Logical) : tức là các bạn tổ trưởng này sẽ kiểm soát số lượng thread ( công việc)
1 lưu ý nhỏ là mình lấy ví dụ warp là tổ trưởng nhưng sẽ không được tính là 1 thành viên trong lớp, tức là 1 lớp học có 50 bạn học sinh và 5 tổ trưởng thì SP vẫn là 50 chứ không phải 55
Bài này đến đây là kết thúc mong các bạn nắm được nội dung bài học, vì mình biết 2 khái niệm physical và logical sẽ khá là nhầm lẫn nên mỗi khi suy nghĩ về logical và physical thì có thể lấy ví dụ các bạn học sinh và 1 nùi công việc để suy luận sẽ dễ hơn rất nhiều
Đày là code để các bạn có thể check máy của mình, và sẽ có những thông số khác như memory thì mình sẽ nói vào 1 bài khác và nếu các bạn dùng gg colab thì nhớ %%cu
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
int _ConvertSMVer2Cores(int major, int minor) {
// Returns the number of streaming processors (CUDA cores) per SM for a given compute capability version
switch ((major << 4) + minor) {
case 0x10:
return 8;
case 0x11:
case 0x12:
return 8;
case 0x13:
return 8;
case 0x20:
return 32;
case 0x21:
case 0x30:
return 192;
case 0x35:
case 0x37:
return 192;
case 0x50:
return 128;
case 0x52:
case 0x53:
return 128;
case 0x60:
return 64;
case 0x61:
case 0x62:
return 128;
case 0x70:
case 0x72:
case 0x75:
return 64;
case 0x80:
case 0x86:
return 64;
default:
printf("Unknown device type\n");
return -1;
}
}
//get cuda card properties
cudaError_t cardProperties()
{
cudaError_t cudaStatus = cudaSuccess;
int deviceCount;
cudaGetDeviceCount(&deviceCount);
printf("Number of CUDA devices: %d\n", deviceCount);
for (int dev = 0; dev < deviceCount; dev++) {
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, dev);
printf("\nDevice %d: %s\n", dev, deviceProp.name);
printf("Number of SMs: %d\n", deviceProp.multiProcessorCount);
printf("Number of SP per SM: %d\n", _ConvertSMVer2Cores(deviceProp.major, deviceProp.minor));
printf("Max Threads per Block: %d\n", deviceProp.maxThreadsPerBlock);
printf("Total registers: %d\n", deviceProp.regsPerBlock * deviceProp.warpSize);
printf("Total shared memory: %ld bytes\n", deviceProp.sharedMemPerBlock);
printf("Total global memory: %lu bytes\n", deviceProp.totalGlobalMem);
printf("Total constant memory: %ld bytes\n", deviceProp.totalConstMem);
printf("Global memory bandwidth (GB/s): %f\n", 2.0 * deviceProp.memoryClockRate * (deviceProp.memoryBusWidth / 8) / 1.0e6);
}
return cudaStatus;
}
int main()
{
cudaError_t cudaStatus = cardProperties();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
// cudaDeviceReset must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
cudaStatus = cudaDeviceReset();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
return 0;
}
Nếu các bạn thấy bài viết hay thì xin hãy star cho mình ở github nha
All rights reserved
