[Lập trình song song] Bài 3: Hello world cuda-C
Bài đăng này đã không được cập nhật trong 2 năm
Ở các bài trước chúng ta đã học quá nhiều lý thuyết rùi, nên ở bài này chúng ta sẽ bắt đầu code những dòng đầu tiên bằng ngôn ngữ cuda-C và 1 lần nữa nếu máy tính các bạn không có GPU thì không sao cả mình đã làm 1 bài viết hướng dẫn cách setup để code trên gg colab ở đây
1 lưu ý nhỏ là về sau các phần bài tập cũng như đáp án mình sẽ up lên github, và chỉ những bài nào thú vị thì mình mới chia sẽ lên viblo nên nếu các bạn hứng thứ muốn luyện tập có thể ghé qua github và 1 điểm cộng nữa là các nội dung mình chia sẽ trên viblo đều được viết bằng tiếng anh trên github
Hello world Cuda-C
Lập trình song song trên GPU tức là chúng ta sẽ đưa các data từ CPU về GPU để xử lí/tính toán bằng ngôn ngữ Cuda C/C++
Nói đến đây phần lớn các bạn sẽ thắc mắc 2 điều:
- Cuda là gì?
- Làm sao chúng ta có thể đưa data từ CPU về GPU và sử dụng GPU core như thế nào?
1 lưu ý nhỏ là nếu các biết bạn không biết về GPU ( cách thức hoạt động/ các thành phần trong GPU) thì đừng lo vì bài viết này sẽ không cần những kiến thức đó và yên tâm là mình sẽ làm 1 bài riêng để nói về GPU để bạn đọc có thể nắm những kiến thức cần thiết
Cuda là gì?
CUDA (Compute Unified Device Architecture) là một nền tảng tính toán song song được phát triển bởi NVIDIA, Nó cho phép chúng ta, các lập trình viên sử dụng GPU (Graphics Processing Unit - Đơn vị xử lý đồ họa hay nói 1 cách đơn giản là GPU core) để thực hiện các tác vụ tính toán thông qua các ngôn ngữ lập trình như C, C++
Cách thức hoạt động của Cuda
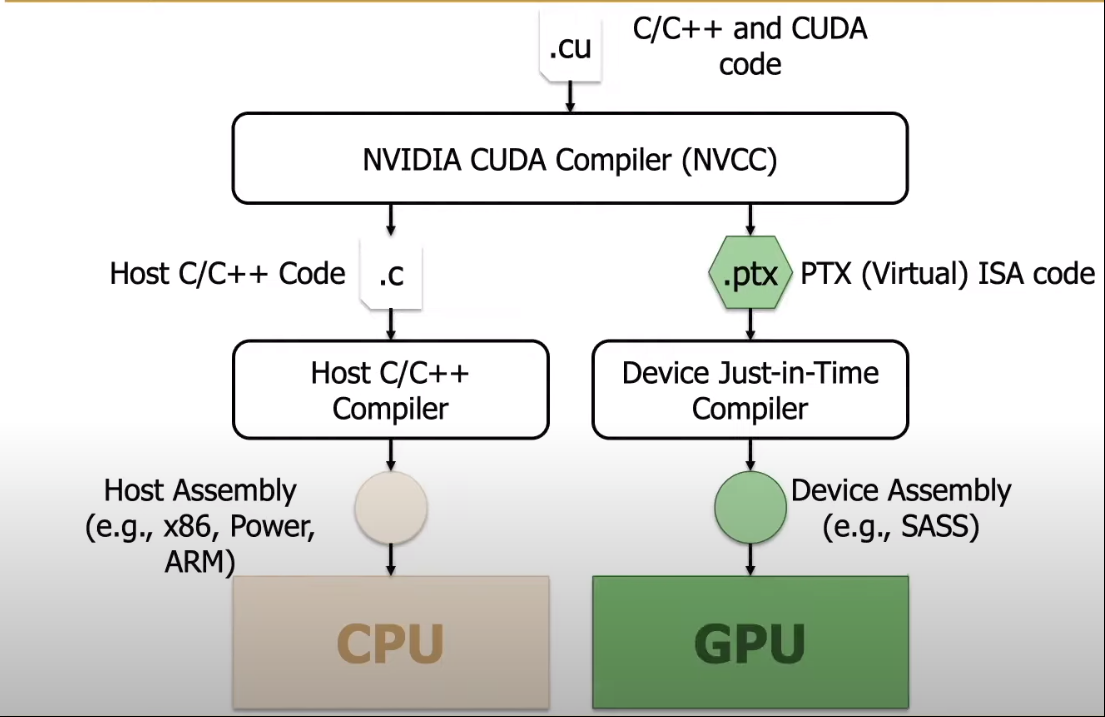
Khi chúng ta code xong và lưu file, ở cuối đuôi file chúng ta thường hay thêm file extension ví dụ
- Python thì .py
- C thì .c
- C++ thì .cpp
Vậy thì ở đây cudaC/C++ là .cu
Như tên gọi là CudaC/C++ thì code vừa là C (hoặcC++) và là Cuda nên chúng ta cần 1 compiler nào đó có thể vừa biên dịch C/C++ binary và Cuda binary vậy nên NVIDIA đã tạo ra NVCC nhằm giải quyết vấn đề đó.
Để giải thích 1 cách đơn giản thì NVCC hoạt động theo các bước sau:
- Phân tích cú pháp: NVCC kiểm tra và hiểu mã nguồn CUDA.
- Tạo mã giao tiếp: NVCC tạo mã chạy trên CPU( tức là C/C++) để gọi các hàm CUDA trên GPU.
- Tạo mã kernel: NVCC biên dịch các hàm CUDA thành mã chạy trực tiếp trên GPU.
- Ghép mã: NVCC kết hợp mã giao tiếp và mã kernel thành một chương trình hoàn chỉnh.
- Tối ưu mã: NVCC tối ưu hóa mã CUDA để tăng hiệu suất tính toán trên GPU. ( cái này mỗi máy tính khác nhau sẽ có những cách tối ưu khác nhau )
- Sinh mã máy: NVCC tạo ra mã máy để chạy chương trình CUDA trên GPU. ( nó tạo ra file tên là a.out giống như khi execute code C thì tạo ra file exe)
Tóm lại, NVCC là công cụ giúp biên dịch mã nguồn CUDA thành mã máy có thể chạy trên GPU, cho phép bạn thực hiện tính toán song song nhanh chóng và hiệu quả.
Tóm tắt
Tóm lại các bạn có thể hình dung là đầu tiên chúng ta sẽ code bằng C hoặc C++ để lấy data và lưu data đó vào CPU memory và từ CPU chúng ta gọi kernel ( tức là function được chạy trên GPU tức là code bằng Cuda) để copy data từ CPU memory sang GPU memory để thực hiện tính toán. Và sau khi tính toán xong chúng ta lại copy ngược lại từ GPU về CPU để in kết quả
1 lưu ý nhỏ là từ về sau mình sẽ gọi là CudaC chứ không còn là CudaC/C++ vì như mình đã nói ở phía trên là đầu tiên chúng ta sẽ code bằng C hoặc C++ để lấy data và lưu data đó vào CPU memory và ở đây mình sẽ chọn là code bằng C vì C sẽ có những cú pháp khá tương đồng với Cuda nên sẽ dễ dàng hơn trong việc đọc code.
Làm sao chúng ta có thể đưa data từ CPU về GPU và sử dụng GPU core như thế nào?
Mục tiêu code của chúng ta sẽ là COPY các data cần tính toán từ CPU về GPU để tính toán 1 cách nhanh chóng hơn và COPY kết quả đã tính toán xong đưa về lại CPU.
Tại sao lại là COPY : là vì CPU và GPU sở hữu các memory riêng biệt ( mình sẽ dành 1 bài viết riêng để nói về đều này) nên không thể truy cập trực tiếp lẫn nhau mà phải copy data thông qua PCI (bus)
Chúng ta sẽ chạy những dòng code đầu tiên và cùng phân tích
#include <stdio.h>
__global__ void kernel()
{
printf("hello world");
}
int main()
{
kernel<<<1,1>>>();
cudaDeviceSynchronize();
return 0;
}
Như mình đã giải thích cách hoạt động của cuda thì mình sẽ lưu file ở dạng <tên file>.cu xong rồi compile bằng 2 dòng lệnh( khi compile mở terminal lên rồi vô đúng thư mục bạn đã lưu code):
1)nvcc <tên file>.cu
2)./a.out

Nếu các bạn nào dùng gg colab thì chỉ cần thêm %%cu ngay đầu tiên rồi chạy thui.
Phân tích code
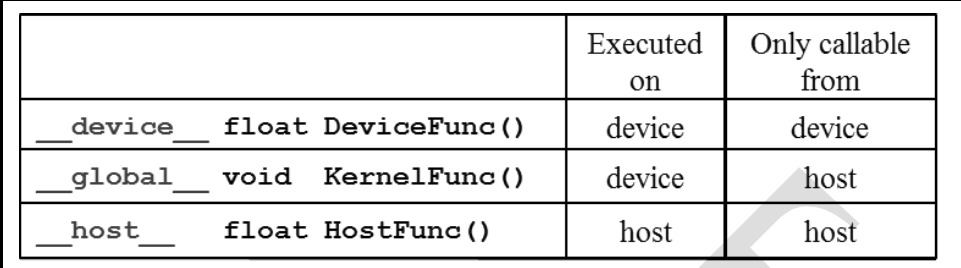
Ở đây chúng ta có 2 khái niệm mới là Host tức là CPU và Device là GPU
- __ host __ : là 1 normal function được gọi và thực thi trên CPU ( tức là khi các bạn tạo 1 hàm bất kì, nếu không chỉ định gì thêm thì nó sẽ được thực thi ở trên CPU
int add(int x, int y) __host__ int add(int x, int y)
{ {
return x + y ; return x + y ;
} }
Ví dụ ở 2 đoạn code trên là như nhau, nếu không chỉ định function được thực thi ở đâu thì sẽ mặc định là ở CPU ( tức là ở host) và rõ nhất là khi ta tạo main function: int main()
- __ global __ void: là 1 function được gọi bởi host (tức là CPU) và thực thi bởi device (GPU) và thường được gọi với 1 cái tên quen thuộc là kernel function
kernel function : thi hành lệnh trên GPU, CPU launches ( khởi chạy) kernel với các syntask đặc biệt ( mình đã giải thích ở phía trên NVCC ) để GPU biết có bao nhiêu threads được dùng
Mình sẽ giải thích rõ ý nghĩa của câu này ở phía dưới, và lưu ý là __ global __ void luôn đi chung 1 cặp tức là nó sẽ không có giá trị trả về, lý do là vì CPU và GPU là 2 thành phần riêng biệt không thể giao tiếp trực tiếp với nhau vì vậy các kết quả không thể trả về cho CPU như các hàm thông thường mà phải copy data qua lại lẫn nhau thông qua PCI (bus)
int add(int x, int y) __global__ void kernelAdd(int x, int y)
{ {
int a = 0 ;
return x + y ; a = x + y ;
} }
Tức là ở đây chúng ta có 2 function add - kernelAdd:
- add : được gọi và thực thi ở CPU tức là phép tính x + y sẽ được thực hiện bởi CPU core
- kernelAdd: được gọi bởi CPU nhưng lại được thực thi ở GPU tức là phép tính x + y sẽ được thực hiện bởi GPU core
Qua 2 ví dụ trên bạn đã biết làm thế nào để sử dụng GPU core
Sẽ có 1 số bạn thắc mắc là tại sao kernel function lại được gọi bởi host(CPU) nhưng lại được thực thi bởi device (GPU), đơn giản là vì khi ta tạo 1 function con và khi gọi nó ta thường sẽ để chúng trong main function, vậy thì kernel function cũng vậy, ta cũng gọi kernel function ở main và main là function của host nên đó là lý do tại sao kernel function được gọi bởi host nhưng được thực thi trên GPU. Xin lưu ý là cách giải thích này nó không được đúng cho lắm nhưng các bạn có thể hiểu đơn giản là vậy, lý do thực sự là sự tối ưu khi chuyển giao data giữa CPU và GPU và 1 số thứ phức tạp nữa mà mình cũng không biết 😅
- __ device __ <datatype> : là 1 function được gọi bởi device và thực thi trên device ( có thể hiểu đơn giản là __ global __ void là main function ở GPU và __ device __ <datatype> là 1 function con, và thường là các function con được tạo và gọi bởi main nên đó là lý do tại sao __ device __ được gọi và thực thi bởi GPU )
__device__ void PrintHello()
{
printf("hello");
}
__global__ void kernel()
{
PrintHello();
}
Quay trở lại với code của chúng ta
#include <stdio.h>
__global__ void kernel()
{
printf("hello world");
}
int main()
{
kernel<<<1,1>>>();
cudaDeviceSynchronize();
return 0;
}
Tức là ở đây chúng ta tạo kernel function để in hello world ( được thực thi bởi GPU core) và chúng ta gọi kernel function này ở main ( CPU ). Tại đây chúng ta có 2 thứ cần giải thích:
- <<<1,1>>>: số 1 đầu tiên là số block, số 1 thứ 2 là số thread trong 1 block. Block và Thread mình đã giải thích rồi nên mình sẽ không giải thích lại. NHƯNG ở đây sẽ hơi ngược 1 tí so với lý thuyết mình đã giải thích là: như mình đã nói thread là số công việc nhưng ở đây thread chính là số core (GPU core) tức là ở trường hợp này thread là SP. Tức là ở đây mình chỉ định sẽ có bao nhiêu bạn học sinh ( SP) thực hiện công việc in hello world ==> <<<1,1>>> tức là có 1 lớp học và trong 1 lớp học có 1 học sinh thực hiện công việc in hello world. 1 cách tổng quát là <<<N,N>>> tức là trong N lớp học sẽ có N học sinh thực hiện công việc in hello world => hello world sẽ được in N * N lần
Như vậy có thể nói là chúng ta có thể chỉ định bao nhiêu GPU core ( hay là bao nhiêu Thread) được dùng để thực thi vì vậy chúng ta mới có câu nói:
kernel function : thi hành lệnh trên GPU, CPU launches ( khởi chạy) kernel với các syntask đặc biệt ( mình đã giải thích ở phía trên NVCC ) để GPU biết có bao nhiêu threads được dùng
- Vì CPU và GPU là 2 thành phần riêng biệt nên tốc độ xử lí là khác nhau vì vậy chúng ta cần sự đồng bộ giữa 2 thành phần này nên NVIDIA đã tạo ra cudaDeviceSynchronize(): là một hàm đồng bộ hóa, nghĩa là nó đảm bảo rằng tất cả các tác vụ tính toán trước đó trên GPU đã hoàn thành trước khi chương trình tiếp tục thực hiện các tác vụ tiếp theo trên CPU.
Bài tập
- Các bạn thử tạo các hàm __ device __ rồi gọi nó bởi __ global __ void, và gọi __ global __ void bởi 1 function con của host và gọi function con đó trong main function. Sau đó hay thử đảo vị trí gọi để xem nó ảnh hưởng gì không? (ví dụ hãy thử gọi __ global __ void bên trong __ device __)
#include <stdio.h>
__device__ void Device1()
{
//
}
__device__ void Device2()
{
//
}
__global__ void kernel()
{
Device1();
Device2();
}
void sub_Function_in_Host()
{
kernel<<<1, 1>>>();
cudaDeviceSynchronize();
}
int main()
{
sub_Function_in_Host();
return 0;
}
- Các bạn thử chạy 1 câu lệnh bất kì trong main function trước và sau khi dùng cudaDeviceSynchronize() để xem output như thế nào? có giống với lý thuyết mà mình đã đề cập không
CPU và GPU là 2 thành phần riêng biệt nên tốc độ xử lí là khác nhau vì vậy chúng ta cần sự đồng bộ giữa 2 thành phần này nên NVIDIA đã tạo ra cudaDeviceSynchronize(): là một hàm đồng bộ hóa, nghĩa là nó đảm bảo rằng tất cả các tác vụ tính toán trước đó trên GPU đã hoàn thành trước khi chương trình tiếp tục thực hiện các tác vụ tiếp theo trên CPU.
-
Như lý thuyết mình đã đề cập <<<1,1>>> tức là có 1 lớp học và trong 1 lớp học có 1 học sinh thực hiện công việc in hello world. Vậy nếu chúng ta thay đổi thành
<<<1,10>>> thì lúc này trong 1 lớp học sẽ có 10 bạn học sinh thực hiện việc in hello world ( 1 cách đồng thời/ song song )
<<<2,5>>> thì lúc này trong 2 lớp học sẽ có 5 bạn học sinh thực hiện việc in hello world ( 1 cách đồng thời/ song song )
==> Cả 2 cách trên đều output là 10 lần hello world nhưng điểm khác nhau là gì?
Mình sẽ đưa 2 gợi ý là:
-
Nó có liên quan tới SIMT, vậy SIMT là gì
-
Mình từng nói qua trong bài bonus 2
Nếu các bạn thấy bài viết hay thì xin hãy star cho mình ở github nha
All rights reserved
