[Lập trình song song] Bài 10: Streaming
Bài đăng này đã không được cập nhật trong 2 năm
Ở bài này mình sẽ hướng dẫn các bạn 1 kĩ thuật để optimize 1 chương trình trong cudaC ( kĩ thuật này cũng khá đơn giản nhưng sẽ tốt hơn nếu các bạn đã đọc qua bài Pinned memory và Async-Sync )
Streaming
Như mình đã đề cập thì CPU và GPU là 2 thành phần riêng biệt nên vì vậy thời điểm mà đoạn code nằm trên CPU hoặc GPU sẽ được chạy 1 cách riêng biệt mà không quan tâm lẫn nhau ==> chúng ta sẽ tận dụng tính chất này để tối ưu chương trình của chúng ta thêm 1 bước song song
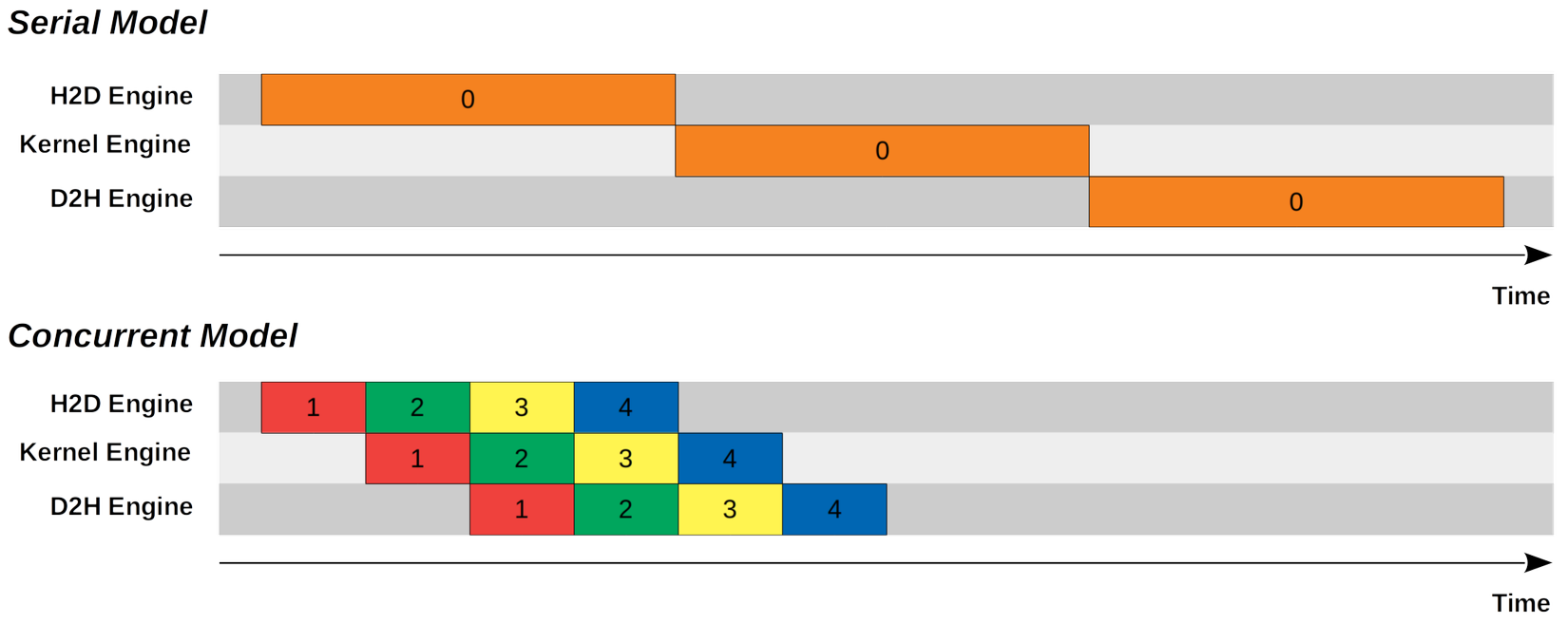
Khi code về cuda-C chúng ta sẽ quan tâm đến 2 khái niệm compute bound và memory bound ( có thể hiểu 1 cách đơn giản là chúng ta gặp 2 vấn đề: tốn quá nhiều thời gian cho tính toán hoặc load/store memory ) và kĩ thuật Streaming này sẽ giúp chúng ta giải quyết 1 phần nào đó về memory bound
2 khái niệm compute bound và memory bound mình sẽ đi sâu ở series NVIDIA-Tools nên nếu các bạn hứng thú có thể ghé qua đọc, còn ở đây mình chỉ tập trung vào code
Như mình đã đề cập, để code chạy trên GPU thì chúng ta phải copy từ CPU --> GPU vì vậy sẽ khá là lãng phí thời gian cho việc này ( vì nếu chúng ta dùng cudaMemcpy thì chúng ta phải đợi copy xong hết mọi thứ mới thực hiện bước tiếp theo ) vì vậy thay vì đợi copy hết thì chúng ta có thể chia nhỏ thành từng phần ( batch ) để tối ưu hóa cho việc này ( giống như trên hình )
Cơ chế hoạt động
Có 2 thành phần chính luôn xuất hiện khi ta nhắc tới Streaming là: Pinned memory
- Pinned memory: lý do mà pinned memory xuất hiện ở trong kĩ thuật Streaming là vì memory đó nhỏ và nhanh
Như phía trên đã đề cập, chúng ta sẽ chia nhỏ dữ liệu ra để copy từng phần ==> chỉ cần 1 lượng memory nhỏ là đủ và pinned memory đáp ứng được điều đó và nhanh
- Stream branch: là cách tổ chức các threads trên GPU để chúng có thể làm việc độc lập và song song trên cùng một dữ liệu
Có thể hiểu đơn giản từng stream branch là từng người quản lí công việc phân chia các thread, nếu không để cập dùng bao nhiêu branching thì sẽ là mặc định
Code
Ở đây có 2 phương pháp để dùng streaming ( tùy thuộc vào mỗi loại máy tính để lựa chọn phương pháp cho riêng mình )
Như mình đã nói là 1 cục dữ liệu lớn sẽ được chia nhỏ và xử lí, ở đây việc chia nhỏ và xử lí sẽ được thực hiện song song chứ không phải tuần tự nhờ vào cơ chế stream branch
Việc đầu tiên khi sử dụng streaming là ta phải tạo ra các stream branch bằng:
cudaStream_t stream[nStreams]
Còn lại là tương tự chỉ khác 1 tí ở:
cudaMemcpyAsync(&d_a[offset], &a[offset], streamBytes, cudaMemcpyHostToDevice,stream[i])
kernel<<<streamSize / blockSize, blockSize, 0, stream[i]>>>(d_a, offset);
Như mình đã nói, vì chỉ copy 1 phần nên chúng ta cân phải xác định index hay còn gọi là offset để duy trì việc copy đúng ở các branch khác nhau.
Ở đây tham số thứ 3 ở kernel: '0' là shared memory thì các bạn chưa cần quan tâm đâu.
asynchronous version 1: loop over {copy, kernel, copy}

Phương pháp đầu tiên là ta sẽ gộp copy d2h - kernel - h2d thành 1 quy trình và chia nhỏ quy trình đó ra
for (int i = 0; i < nStreams; ++i) {
int offset = i * streamSize;
cudaMemcpyAsync(&d_a[offset], &a[offset], streamBytes, cudaMemcpyHostToDevice, stream[i]);
kernel<<<streamSize/blockSize, blockSize, 0, stream[i]>>>(d_a, offset);
cudaMemcpyAsync(&a[offset], &d_a[offset], streamBytes, cudaMemcpyDeviceToHost, stream[i]);
}
asynchronous version 2: loop over copy, loop over kernel, loop over copy

Phương pháp thứ 2 là ta sẽ tách riêng từng công việc thành nhiều phần
for (int i = 0; i < nStreams; ++i) {
int offset = i * streamSize;
cudaMemcpyAsync(&d_a[offset], &a[offset],
streamBytes, cudaMemcpyHostToDevice, cudaMemcpyHostToDevice, stream[i]);
}
for (int i = 0; i < nStreams; ++i) {
int offset = i * streamSize;
kernel<<<streamSize/blockSize, blockSize, 0, stream[i]>>>(d_a, offset);
}
for (int i = 0; i < nStreams; ++i) {
int offset = i * streamSize;
cudaMemcpyAsync(&a[offset], &d_a[offset],
streamBytes, cudaMemcpyDeviceToHost, cudaMemcpyDeviceToHost, stream[i]);
}
Bài tập
- Code để so sánh thời gian của 2 phương pháp trên
- làm sao để xác định mình cần chia thành bao nhiêu branch
Gợi ý: không phải cứ chia nhiều là tốt, như mình đã ví dụ stream branch giống như người quản lí vì vậy giả sử số lượng công việc ít nhưng chúng ta thuê quá nhiều quản lí thì rất phí tiền trong khi chỉ cần 1 người quản lí là đủ.
All rights reserved
