[Lập trình song song] Bài 6: Sử dụng các bộ nhớ trong GPU
Bài đăng này đã không được cập nhật trong 2 năm
Ở bài 5 mình đã giới thiệu về các bộ nhớ nằm trong GPU ( công dụng/tốc độ/phạm vi truy cập của các thread (scope) ), thì ở bài này mình sẽ hướng dẫn các bạn sử dụng chúng bằng ngôn ngữ cuda-C
Các bộ nhớ trong GPU
Trước khi đi vào code thì mình sẽ trả lời 2 câu hỏi mà mình đã đề cập ở bài 5 là:
- Như trong hình thì tại sao shared memory và L1 lại được ghép chung thành 1 memory chứ không phải là 2 memory riêng biệt?
- Tại sao phạm vi truy cập của L1 là các Thread trong cùng 1 block nhưng của L2 lại là toàn bộ các Thread
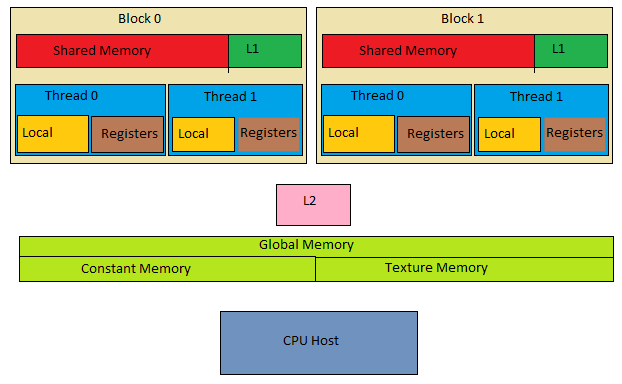
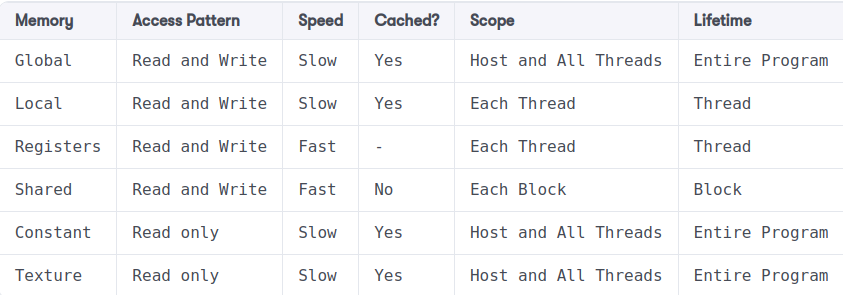
Nếu góc nhìn của chúng ta là Physical view thì chắc chắn là shared memory và L1 là 2 thanh bộ nhớ riêng biệt và câu hỏi của mình là dưới góc nhìn Logical view nên chúng sẽ là 1. Lý do là vì: theo như các nhà nghiên cứu đã phân tích thì nếu tách riêng ra thành các vùng nhớ riêng biệt thì sẽ khó để quản lý và sẽ rất phí tài nguyên.
Nếu các bạn ngay tại đây có suy nghĩ là:
- Khó quản lý ?? nếu gộp chúng thành 1 sẽ có thể bị nhầm lẫn giữa các bộ nhớ và việc tách riêng chúng sẽ dễ dàng quản lý thì là sai nha
- Phí tài nguyên ?? Dù gộp hay tách ra thì chúng ta cũng chỉ có nhiêu đó bộ nhớ thì phí chỗ nào??
Nếu các bạn đều có suy nghĩ như vậy thì mình xin phép nhắc đến khái niệm prefetch ( cực kì hiệu quả trong việc tối ưu hóa hiệu suất truy cập dữ liệu và được áp dụng cho Cache )
Prefetch là quá trình tải trước dữ liệu từ bộ nhớ chính vào bộ nhớ cache hoặc bộ nhớ trung gian trước khi nó cần dùng nhằm tối ưu hóa hiệu suất truy cập dữ liệu.
Ví dụ:
int a[100], b[100], c[100];
for(int i = 0; i < 100; i++) {
c[i] = a[i] + b[i];
}
trong đoạn code trên, chúng ta đang thực hiện phép cộng giữa hai mảng a và b để lưu kết quả vào mảng c. Tuy nhiên, theo cách thực hiện truy cập thông thường, chương trình sẽ duyệt từng phần tử một, và mỗi lần truy cập, nó sẽ điều chỉnh con trỏ đến bộ nhớ chính để lấy dữ liệu từ a và b. Điều này có thể dẫn đến thời gian chờ đợi khi truy cập dữ liệu từ bộ nhớ chính.
Cơ chế prefetching (tiên đoán truy cập) đề xuất một cách thông minh để giảm thời gian chờ đợi này. Thay vì chờ cho đến khi cần truy cập từng phần tử riêng lẻ, nó dự đoán trước các truy cập dữ liệu tiếp theo mà chương trình có thể thực hiện dựa trên các mẫu truy cập trước đó. Sau đó, nó tải trước (prefetch) các dữ liệu này vào bộ nhớ cache, giúp giảm thời gian chờ đợi và tối ưu hóa hiệu suất tổng thể của chương trình.
Đó là lý do tại sao cache còn gọi là bộ nhớ tạm thời. Khi ta đẩy dữ liệu lên cache tức là nó chỉ dùng để chứa tạm thời cho đến khi dữ liệu đó thật sự được truy cập thì lúc này dữ liệu nằm trên cache sẽ được đẩy lên xử lí và vùng nhớ đó lại được thay thế bởi dữ liệu kế tiếp.
Quay lại vấn đề của chúng ta là Khó quản lý - Phí tài nguyên :
- Khó quản lý: Nếu shared memory và L1 nằm riêng thì chúng ta sẽ tốn thêm 1 bước map ( ánh xạ ) lẫn nhau để xem liệu dữ liệu nào sẽ được truy cập tiếp theo. Khi chúng nằm chung trong một cơ chế bộ nhớ thì các dữ liệu có thể được chia sẻ một cách hiệu quả giữa shared memory và L1 cache
- Phí tài nguyên: Theo các nhà nghiên cứu thì nếu tách riêng ra thành 2 bộ nhớ riêng biệt thì khi ta triển khai code thì phần lớn sẽ không dùng hết shared memory hoặc là cache ( sẽ còn dư 1 phần ). Còn nếu gộp chung thì chúng ta chỉ cần chỉ ra dùng bao nhiêu cho shared thì phần còn lại sẽ được cấp cho cache vì vậy hiệu quả hơn.
Và cũng vì lý do đó nên chúng ta chỉ cần sử dụng shared memory thôi chứ không cần động đến cache ( và thực ra nếu muốn chúng ta cũng không động được vì NVIDIA không viết các thư viện để thao tác trực tiếp trên cache mà chỉ là gián tiếp được thôi ).
Còn lý do tại sao phạm vi truy cập của L1 là các Thread trong cùng 1 block nhưng của L2 lại là toàn bộ các Thread là vì global memory cũng cần cơ chế prefetch nên buộc chúng ta phải tách cache thành 2 phần: 1 cho shared(L1), 1 cho global(L2)
Bây giờ chúng ta sẽ tới code
Global memory
Chúng ta sẽ code cộng 2 vector ( 100 phần tử/vector ) và sử dụng global memory - bộ nhớ lớn nhất cũng là chậm nhất ở trong GPU
h_: là các giá trị ở host
d_: là các giá trị ở device
các kí hiệu h_ và d_ bạn sẽ thấy rất nhiều ở trên các guide hay document về cuda nên mình sẽ dùng theo để các bạn quen.
#include <stdio.h>
#include <stdlib.h>
// Kích thước của vector
#define N 100
// Kernel CUDA để cộng hai vector
__global__ void vectorAdd(int *a, int *b, int *c) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid < N) {
c[tid] = a[tid] + b[tid];
}
}
int main() {
int *h_a, *h_b, *h_c; // Vector trên CPU
int *d_a, *d_b, *d_c; // Vector trên GPU
// Khởi tạo vector trên CPU
h_a = (int *)malloc(N * sizeof(int));
h_b = (int *)malloc(N * sizeof(int));
h_c = (int *)malloc(N * sizeof(int));
// Khởi tạo vector ngẫu nhiên
for (int i = 0; i < N; i++) {
h_a[i] = rand() % 10;
h_b[i] = rand() % 10;
}
// Khởi tạo vector trên GPU
cudaMalloc((void **)&d_a, N * sizeof(int));
cudaMalloc((void **)&d_b, N * sizeof(int));
cudaMalloc((void **)&d_c, N * sizeof(int));
// Sao chép dữ liệu từ CPU sang GPU
cudaMemcpy(d_a, h_a, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, N * sizeof(int), cudaMemcpyHostToDevice);
// Gọi kernel CUDA để thực hiện phép cộng
vectorAdd<<<2, 50>>>(d_a, d_b, d_c);
// Sao chép kết quả từ GPU sang CPU
cudaMemcpy(h_c, d_c, N * sizeof(int), cudaMemcpyDeviceToHost);
// In kết quả
for (int i = 0; i < N; i++) {
printf("h_a[%d] %d + h_b[%d] %d = %d\n", i, h_a[i], i, h_b[i], h_c[i] );
}
// Giải phóng bộ nhớ
free(h_a);
free(h_b);
free(h_c);
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
return 0;
}
Phân tích kernel
__global__ void vectorAdd(int *a, int *b, int *c) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
if (tid < N) {
c[tid] = a[tid] + b[tid];
}
}
Kernel này khá là giống với code C bình thường chỉ có điều thêm vài chỗ là:
-
int tid = blockIdx.x * blockDim.x + threadIdx.x;
-
if (tid < N)
Đối với code C bình thường thì để cộng 2 vector thì chúng ta sẽ duyệt qua từng phần tử rồi cộng thì ở cuda-C chúng ta 1 lần duyệt hết các phần tử NHƯNG để duyệt thì chúng ta phải xác định được index ( vị trí của các phần tử ) vì vậy int tid là để xác định index

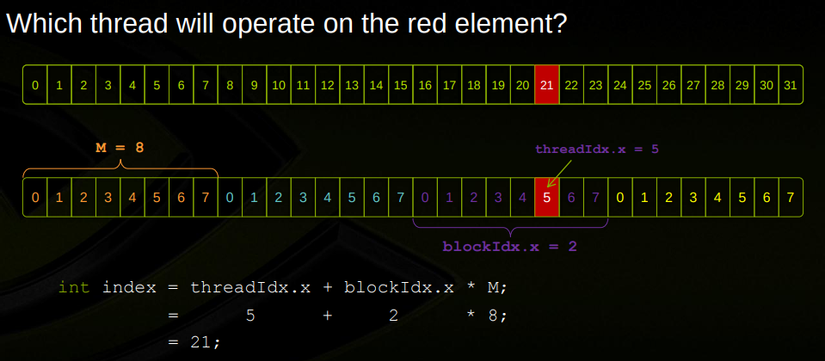
Trong 2 bức hình đã minh họa khá rõ ràng rồi, ở đây M là số thread trong 1 block hay còn gọi là blockDim
Kế đến là if (tid < N) thì cái này như 1 barrier ( rào chắn ) để chỉ định thread nào được tham gia vào quá trình cộng 2 vector. Ở đoạn code trên, mình chỉ cần dùng 100 thread ứng với 100 phần tử là đủ rồi NHƯNG máy tính có tới 1024 thread/block thì nếu không chỉ ra if thì sẽ không ổn lắm
Thực ra không cần chỉ ra cũng được tại vì ở vectorAdd<<<2, 50>>> mình đã quy định sẵn chỉ dùng 100 thread rồi nhưng sau này code sẽ phức tạp hơn nên dòng if này khá quan trọng và các bạn nên thêm vào như 1 thói quen sẽ hay hơn
Khởi tạo giá trị trên GPU
cudaMalloc((void **)&d_a, N * sizeof(int));
cudaMalloc((void **)&d_b, N * sizeof(int));
cudaMalloc((void **)&d_c, N * sizeof(int));
malloc có lẽ các bạn quá quen thuộc khi code C rồi, nó dùng để cấp phát động thì ở đây cudaMalloc cũng có chức năng như vậy nhưng là cấp phát động trên GPU.
1 lưu ý nhỏ là khi xem các guide hoặc document các bạn sẽ thấy có thể người ta viết như vậy
cudaMalloc(&d_a, N * sizeof(int));
cudaMalloc(&d_b, N * sizeof(int));
cudaMalloc(&d_c, N * sizeof(int));
2 đoạn code là như nhau nha. cái có void là kiểu viết thời xưa còn bây giờ người ta bỏ void ra cho gọn.
Transfer data
Ở đây mình dùng từ Transfer data là để chỉ ra copy data từ Host về Device và ngược lại ( và sau này mình sẽ viết tắt là Transfer data hoặc là H2D - D2H)
cudaMemcpy(d_a, h_a, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, h_b, N * sizeof(int), cudaMemcpyHostToDevice);
vectorAdd<<<2, 50>>>(d_a, d_b, d_c);
cudaMemcpy(h_c, d_c, N * sizeof(int), cudaMemcpyDeviceToHost);
cudaMemcpy nhận 3 tham số:
- tham số 1: Nơi nhận giá trị copy ( giống như Ctrl + V )
- tham số 2: Nơi copy giá trị ( giống như Ctrl + C )
- tham số 3: chỉ ra chiều data di chuyển ( H2D hay là D2H )
1 lưu ý là khi dùng cudaMemcpy tức là data sẽ auto copy vào global memory nha
Local memory and registers
Local memory và Register files là 2 bộ nhớ độc nhất cho mỗi thread. Bộ nhớ Register files là loại bộ nhớ nhanh nhất có sẵn cho mỗi thread. Khi các biến của kernel không thể nằm trong Register files, chúng sẽ sử dụng bộ nhớ local.
tức là mỗi thread sẽ sở hữu cho mình register files và local memory, khi dùng hết register files thì data sẽ được đẩy xuống local memory giống như kiểu tràn bộ nhớ ở mức độ register và khái niệm này gọi là register spilling
#include <stdio.h>
#include <stdlib.h>
__global__ void kernel() {
int temp = 0;
temp = threadIdx.x;
printf("blockId %d ThreadIdx %d = %d\n",blockIdx.x,threadIdx.x,temp);
}
int main() {
kernel<<<5,5>>>();
cudaDeviceSynchronize();
return 0;
}
đoạn code khá là bình thường, chúng ta tạo biến temp và cho biến temp nhận các giá trị là threadIdx.x . Theo tư duy thông thường thì temp sẽ nhận giá trị là threadIdx.x cuối cùng NHƯNG cuda-C không hoạt động như vậy
mỗi thread được thực thi độc lập, vì vậy biến temp là biến cục bộ cho mỗi thread.Nên trong mỗi thread, biến temp sẽ nhận giá trị của threadIdx.x
Nếu các bạn xem lại global memory thì
int tid = blockIdx.x * blockDim.x + threadIdx.x;
Biến int tid là local memory á
Constant memory
Như mình đã đề cập: Constant memory là Read only nên mục tiêu là lưu các giá trị là hằng số. Mình sẽ ví dụ code 1 phương trình y =3x + 5 với x là 1 vector còn giá trị 3 và 5 là hằng số ( sẽ được lưu ở constant memory )
#include <stdio.h>
__constant__ int constantData[2]; // Khai báo mảng Constant memory
__global__ void kernel(int *d_x, int *d_y, int N) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < N) {
int x = d_x[idx];
int a = constantData[0]; // Lấy giá trị 3 từ Constant memory
int b = constantData[1]; // Lấy giá trị 5 từ Constant memory
d_y[idx] = a * x + b;
}
}
int main() {
const int N = 10; // Số phần tử mảng
int h_x[N]; // Mảng đầu vào trên host
int h_y[N]; // Mảng kết quả trên host
int *d_x, *d_y; // Mảng trên device
// Khởi tạo dữ liệu trên host
for (int i = 0; i < N; i++) {
h_x[i] = i;
}
// Khởi tạo vector trên GPU
cudaMalloc((void**)&d_x, N * sizeof(int));
cudaMalloc((void**)&d_y, N * sizeof(int));
// Sao chép dữ liệu từ host vào device
cudaMemcpy(d_x, h_x, N * sizeof(int), cudaMemcpyHostToDevice);
// Sao chép giá trị 3 và 5 vào Constant memory
int constantValues[2] = {3, 5};
cudaMemcpyToSymbol(constantData, constantValues, 2 * sizeof(int));
// Gọi kernel với 1 block và N threads
kernel<<<1, N>>>(d_x, d_y, N);
cudaDeviceSynchronize();
// Sao chép kết quả từ device về host
cudaMemcpy(h_y, d_y, N * sizeof(int), cudaMemcpyDeviceToHost);
// In kết quả
for (int i = 0; i < N; i++) {
printf("3(x= %d) + 5 => y = %d\n", h_x[i], h_y[i]);
}
// Giải phóng bộ nhớ trên device
cudaFree(d_x);
cudaFree(d_y);
return 0;
}
Khởi tạo giá trị trên GPU
Khác với global, constant memory không cần phải cudaMalloc mà thay vào đó phải định nghĩa là tôi có sử dụng constant memory bởi _ _ constant _ _
__constant__ int constantData[2]
Transfer data
cudaMemcpyToSymbol(constantData, constantValues, 2 * sizeof(int))
syntaks của constant hơi khác global 1 tí là thay vì cudaMemcpy thì là cudaMemcpyToSymbol còn lại các tham số là y chang nha
1 lưu ý nhỏ là ở đây mình không chỉ ra là H2D hay D2H thì mặc định sẽ là H2D nha
Tóm tắt
Qua bài này các bạn đã biết cách dùng global memory, local memory ( register files), constant memory. Còn về shared memory thì mình sẽ dành riêng 1 bài để nói vì nó khá thú vị và khá là khó, còn về texture memory thì mình sẽ không đề cập vì các loại chip hiện nay của NVIDIA đã tối ưu và loại bỏ texture memory lun rồi.
Bài tập
Khi các bạn chạy code ở ví dụ local memory and register:
#include <stdio.h>
#include <stdlib.h>
__global__ void kernel() {
int temp = 0;
temp = threadIdx.x;
printf("blockId %d ThreadIdx %d = %d\n",blockIdx.x,threadIdx.x,temp);
}
int main() {
kernel<<<5,5>>>();
cudaDeviceSynchronize();
return 0;
}
Tại sao output lại không theo thứ tự các blockId mà lại lộn xộn như trong hình
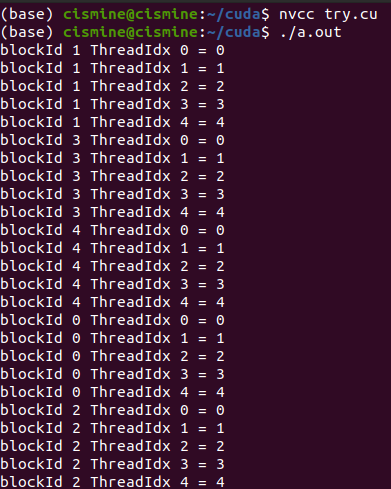
Nếu các bạn thấy bài viết hay thì xin hãy star cho mình ở github nha
All rights reserved
