[Lập trình song song] Bài 11: Data Hazard
Bài đăng này đã không được cập nhật trong 2 năm
Khi chúng ta nhắc đến song song chúng ta sẽ nhắc tới hiện tượng data hazard, 1 bug khiến chúng ta khá là đau đầu khi fix vì đây là lỗi về mặt logic NHƯNG bây giờ chúng ta đã có công cụ NVIDIA Compute Sanitizer nên việc fix bug này cũng trở nên đỡ hơn 1 phần nào. Bài viết này mình sẽ nói về data hazard là gì và minh họa nó
Sẽ tuyệt hơn nếu các bạn đọc bài Synchronization - Asynchronization trước khi đọc bài này
Data Hazard
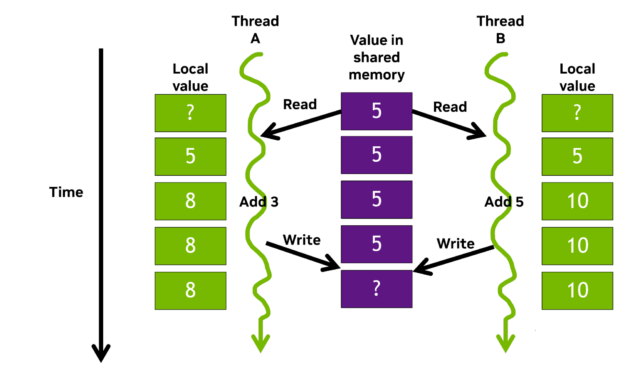
Hiện tượng các thread read và write 1 value nào đó thì sẽ dẫn đến xung đột và hiện tượng đó gọi là data hazard
Khi nói về data hazard chúng ta sẽ đụng đến 2 vấn đề:
- Data Race: Thường liên quan đến việc "write after read" hoặc "read after write", nhưng nó chủ yếu tập trung vào việc đồng thời truy cập (đọc và/hoặc ghi) một biến lưu trữ mà không có sự đồng bộ hóa. Điều này có thể dẫn đến việc 1 thread ghi đè lên dữ liệu mà thread khác đang đọc hoặc chuẩn bị ghi ==> dẫn đến conflict data value
- Race condition: Khái niệm này rộng hơn và không chỉ giới hạn ở truy cập dữ liệu. Race condition xảy ra khi kết quả cuối cùng của một hệ thống xuất hiện sự kiện không xác định hay còn gọi là "undefined behavior"
Tóm lại các bạn chỉ cần nhớ: khi code cuda cần lưu ý hiện tượng các thread cùng truy cập vào cùng 1 value để xử lí
Minh họa
#include <stdio.h>
#include <cuda_runtime.h>
#define ARRAY_SIZE 4
__global__ void sum(int *d_array)
{
int id = blockIdx.x * blockDim.x + threadIdx.x;
for (int stride = 1; stride < 4; stride *= 2)
{
// __syncthreads(); -----> barrier
if (threadIdx.x % (2 * stride) == 0)
{
d_array[id] += d_array[id + stride];
}
}
printf("blockIdx.x=%d --> %d\n", blockIdx.x, d_array[id]);
}
int main()
{
int h_array[4] = {1, 2, 3, 4};
int *d_array;
cudaMalloc((void **)&d_array, sizeof(int) * ARRAY_SIZE);
cudaMemcpy(d_array, h_array, sizeof(int) * ARRAY_SIZE, cudaMemcpyHostToDevice);
sum<<<1, 4>>>(d_array);
cudaFree(d_array);
return 0;
}
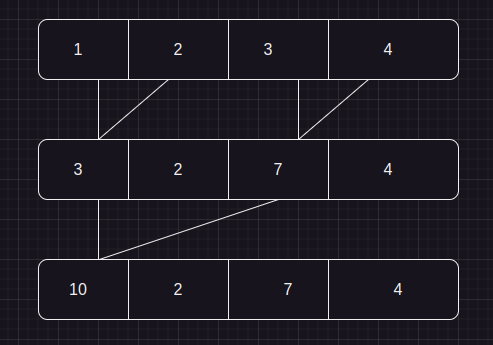 Đây là hình ảnh nguyên lí code hoạt động
Đây là hình ảnh nguyên lí code hoạt động
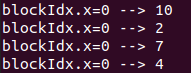
Ở đây chúng ta không đồng bộ các thread dẫn tới data race ( vào step 1: khi 3+4 chưa xong thì đã qua step 2 nên 3 + 3 =6 chứ không phải 3+ 7 =10 )
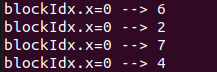
Để giải quyết vấn đề này thì chúng ta chỉ cần đặt 1 barrier để cho các thread đợi lẫn nhau cho đến khi các thread chậm nhất xong bằng câu lệnh __syncthreads()
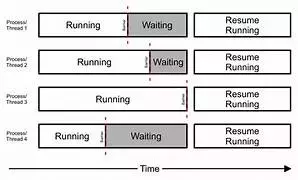
và output khi thêm syncthreads
All rights reserved
