[CNN Architecture series #1] MobileNets - Mô hình gọn nhẹ cho mobile applications
Bài đăng này đã không được cập nhật trong 4 năm
Okay, mọi người đều biết Convolutional Neural Networks.
Và thực ra MobileNet cũng không xa lạ lắm, nó ra đời từ 2017.
Nhưng mình vẫn phải viết intro cho đúng format =))))))
CNN là nền tảng siêu siêu quan trọng trong hầu hết các task trong lĩnh vực computer vision trong một thời gian dài. Tất nhiên, từ vanilla CNN, đã có rất nhiều (siêu nhiều) những cải tiến liên tiếp. Nhắc tới CNN Architecture, ta có thể list ra một list dài dằng dặc: LeNet, AlexNet, VGG, GoogLeNet, ResNet...
Có thể xem danh sách các CNN Architecture tại đây:
Mỗi CNN Architecture đều có thể mạnh của riêng nó, được điều chỉnh để phù hợp với các mục đích khác nhau.
Với sự phát triển của sự hỗ trợ về phân cứng, GPU, TPU, thế là ngày ngày CNN của chúng ta càng sâu, càng nhiều tham số, càng phức tạp, để tăng độ chính xác lên cao hơn. Đã có những mô hình khổng lồ từ vài trăm triệu param đến số tỷ param (khiếp =))))). Nếu bạn có bốn con GPU NVIDIA Titan RTX, thì cứ thoải mái thử nghiệm. Nhưng thực tế thì khắc nghiệt hơn thế nhiều.
- Giả thiết:
Giờ mình lại muốn chạy mô hình của mình trên edge device, ví dụ 1 con jeston nano chả hạn, thứ mà mang tiếng có GPU nhưng GPU còn ì ạch hơn cả cpu trên laptop thông thường. Hoặc là, mình muốn chạy mô hình trên thiết bị di dộng thì sao.
Nói tóm lại là, chính cần một mô hình nhỏ, nhẹ, nhanh, và độ chính xác "có thể chấp nhận được".  Yeahh, it's called Lightweight Model.
Yeahh, it's called Lightweight Model.
Và MobileNets được giới thiệu.
Let's start!
1. MobileNets
MobileNets được giới thiệu lần đầu vào năm 2017 (từ rất lâu).
Paper gốc ở đây:
Làm thế nào để MobileNets có thể rút gọn lại vài triệu tham số nhưng vẫn giữ được độ chính xác ổn, đó là nhờ sử dụng một cơ chế gọi là Depthwise Separable Convolutions.
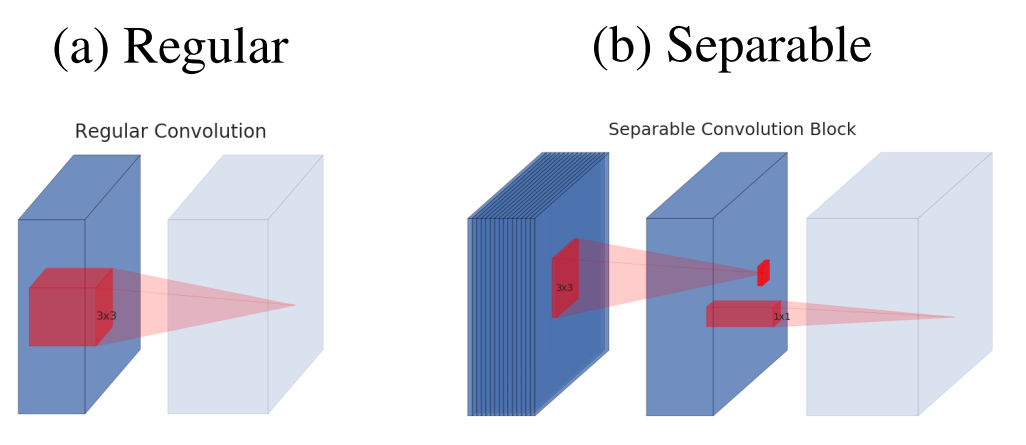
1.1 Standard Convolutions
Đầu tiên, hãy xem lại một chút một Convolution layer thông thường hoạt động như thế nào?
Chúng ta có ví dụ như sau:
(ảnh)
 (cảm ơn những hình ảnh vô cùng tường minh từ tác giả bài viết Medium - MixConv.)
(cảm ơn những hình ảnh vô cùng tường minh từ tác giả bài viết Medium - MixConv.)
Chú thích: (5, 10, 10) = (số channel, width, height)
- Nhìn vào hình, ta có thể thấy:
Giả sử, đầu vào của chúng ta là 1 feature map 5x10x10. Bộ lọc của chúng ta có kích thước 5x3x3. Như vậy, sau khi thực hiện phép nhân tích chập trên toàn bộ feature map (padding = 1, stride=1) ta thu được kết quả 1x10x10. (Nếu bạn đã quên cách nhân tích chập, có thể search các bài viết về CNN cơ bản, đây là một chủ đề phổ biến).
Với mỗi điểm trên feature map, vì filter là 3x3, nên cần thực hiện 3x3 = 9 phép tính nhân.
Số tính toán đã thực hiện là 5 x (3 x 3 x 10 x 10) = 4500.
Sau khi thực hiện phép nhân, ta cộng nó lại. Nhưng đừng lo về phép cộng. Với máy tính 64-bit, thời gian thực hiện phép nhân có thể gấp 64 lần thời gian thực hiện phép cộng, well, có nghĩa là không đáng kể ở đây.
Trong một lớp convolutional, ta sẽ sử dụng nhiều bộ lọc. Ở đây ta có 64 bộ lọc, vậy tổng số tính toán cần thực hiện là: 64 x 4500 = 288000 phép tính nhân.
Như vậy, với:
- là số input, output channels.
- là chiều của input feature map ().
- là chiều của kernel.
Thì tổng số phép nhân cần thực hiện là .
Hãy thử tưởng tượng với ảnh độ phân giải lớn hiện nay 3x1024x1024, số lượng tính toán có thể lớn bao nhiêu.
Hơi nhiều tính toán quá rồi. Phải giảm lại một chút. 
Cùng xem MobileNets cải tiến như thế nào?
1.2 Depthwise Separable Convolutions
-
Depthwise Separable Convolutions được giới thiệu lần đầu tại paper:
Xception: Deep Learning with Depthwise Separable Convolutions
Khá nhiều kiến trúc CNN với mục đích gọn nhẹ áp dụng cơ chế này, có thể kể đến MobileNets, ShuffleNet, EffNet...
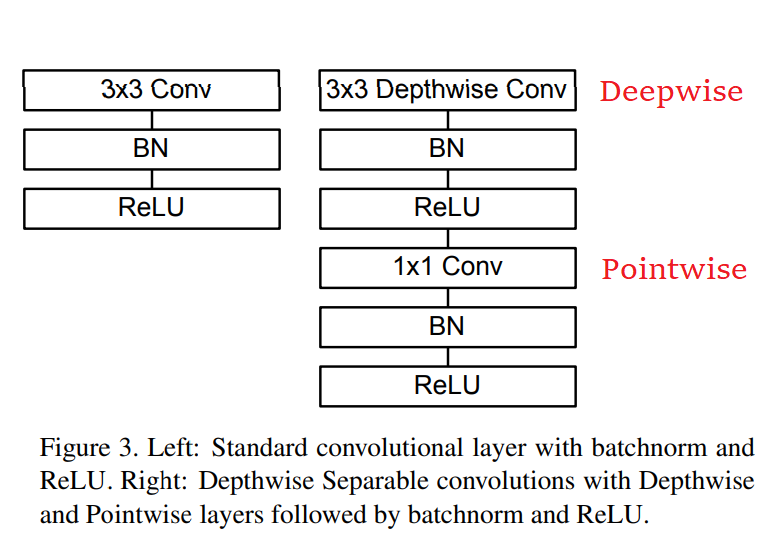
Depthwise Separable Convolutions chia CNN cơ bản ra làm hai phần: Deepwise Convolution và Pointwise Convolution.
May mắn, chúng ta có thêm một cái ảnh vô cùng tường minh nữa.
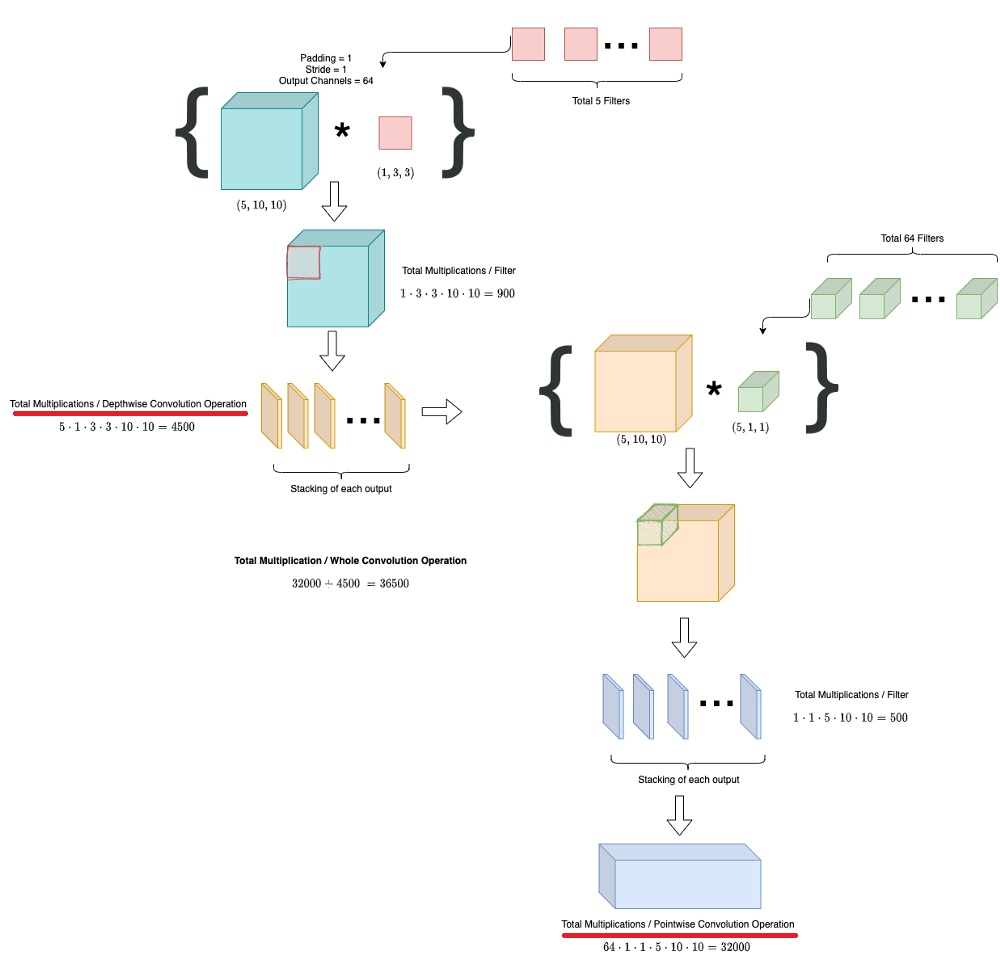
1.2.1 Deepwise Convolution:
Thay vì nhân một mớ tất cả ( ) thì ta tách ra một chút.
Đầu tiên, ta vẫn thực hiện như standard CNN, thực hiện nhân tích chập 5x10x10 với bộ filter giờ chỉ còn là 1x3x3 , tương tự với 5 filters như thế, stack nó lại, kết quả thu được output là 5x10x10.
Số phép nhân đã thực hiện vẫn là = 5 x 10 x 10 x 3 x 3 = 4500 phép nhân.
Tuy nhiên, có thể thấy khác với standard CNN, ở deepwise convolutions, số lượng channel của chúng ta vẫn giữ nguyên, nghĩa là vẫn 5x10x10. (thực hiện phép tích chập một cách rời rạc (separable) trên từng channel)
1.2.2 Pointwise Convolution:
Tiếp theo chúng ta sử dụng kết quả từ bước deepwise convolution. Ở bước pointwise này, ta chỉ sử dụng bộ có kích thước là 1x1. Đồng thời số lượng bộ lọc bằng số channel mà ta muốn thu được. Ta muốn tăng lên 64 channel, vậy hãy sử dụng 64 bộ filters.
Kích thước ko đổi, chỉ số channels đổi.
Như vậy, số phép nhân cần tính chỉ là = 5 x 64 x 10 x 10 = 32000 phép nhân.
Vậy tổng số phép nhân cần tính là : 4500 + 32000 = 36500 phép nhân.
Như vậy, số lượng tính toán đã giảm 8 lần so với standard CNN.
Vậy tổng kết, số lượng tính toán đã giảm được là:
Okey, hình dưới cho thấy sự khác biệt giữa standard CNN và kiến trúc MobileNet
Ngoài ra, paper implement MobileNets còn giới thiệu 2 hypeparameter là: Width Multiplier và Resolution Multiplier.
1.3 Width Multiplier: Thinner Models
Width Multiplier được thêm vào 1 layer, giờ đây số input channels và output channels là và , thay vì và .
Như vậy, chi phí tính toán của một phép tích chập là:
với , có nghĩa là càng nhỏ thì chi phí tính toán càng giảm.
Các được cung cấp bao gồm: 0.25, 0.5, 0.75, 1.
1.4 Resolution Multiplier: Reduced Representation
Tương tự như Width Multiplier , Resolution Multiplier cũng được thêm vào các layer để giảm resolution của ảnh đầu vào và các biểu diễn bên trong giữa các layers.
với , có nghĩa là càng nhỏ thì chi phí tính toán càng giảm.
Các được cung cấp để ảnh đầu vào có các resolutions bao gồm: 224, 192, 160, 128.
Kết luận
MobileNet sử dụng Depthwise Separable Convolutions để giảm số lượng tính toán, giảm số lượng params, đồng thời có thể thực hiện trích xuất đặc trưng một cách tách biệt trên các channel khác nhau.
Toàn bộ chi tiết kiến trúc và implement code của MobileNets có thể được tìm thấy trong Paper.
2. MobileNetV2
Paper MobileNetV2 (published in 2018) :
Tiếp tục một mô hình nữa được giới thiệu, MobileNetV2, rất được ưa chuộng khi triển khai model lên các thiết bị di động.
MobileNetV2 cải tiến những gì với MobileNets v1 ?
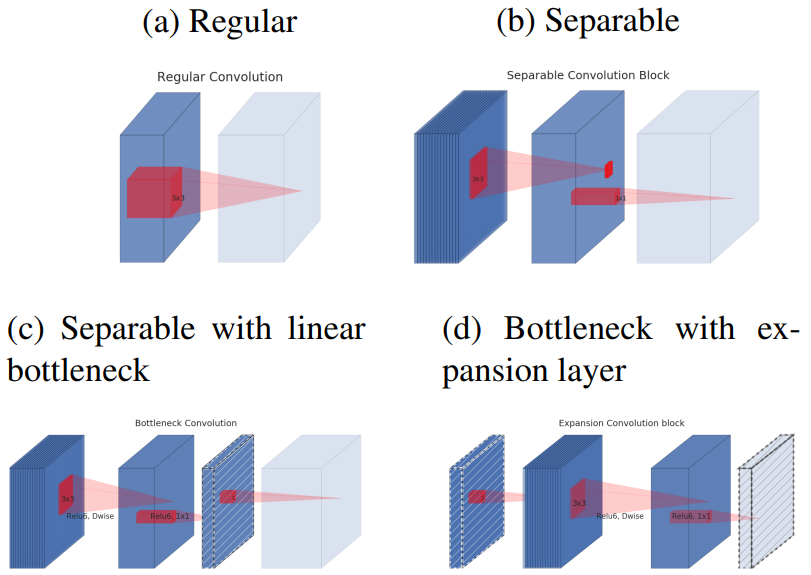
MobileNet v2 tiếp tục sử dụng Depthwise Separable Convolutions, ngoài ra còn đề xuất thêm:
- Linear bottlenecks
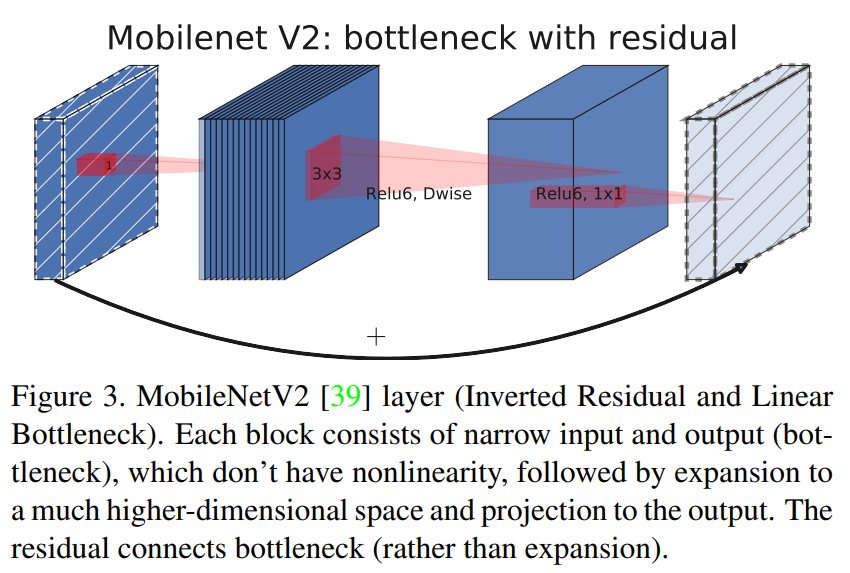
- Inverted Residual Block (shortcut connections giữa các bottlenecks)
Nhìn một chút về sự khác nhau giữa v1 và v2
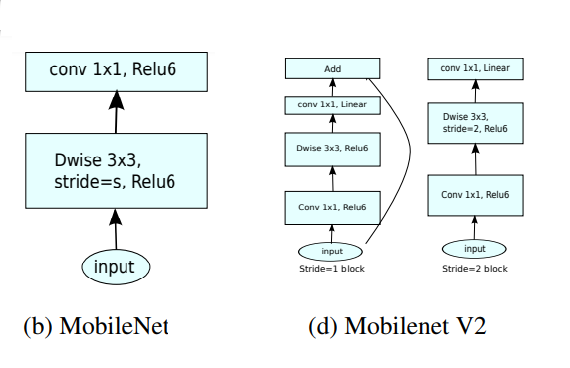 (hình ảnh được cung cấp bởi paper)
(hình ảnh được cung cấp bởi paper)
Hãy phân tích sự khác biệt trong bức ảnh trên:
- MobileNet gồm sử dụng 1 loại blocks gồm 2 phần, Deepwise và Pointwise.
- MobileNet v2 sử dụng 2 loại blocks, bao gồm: residual block với stride = 1 và block với stride = 2 phục vụ downsizing.
Có 3 phần đối với mỗi block:
- Layer đầu là 1×1 convolution với ReLU6.
- Layer thứ hai, như cũ, là depthwise convolution.
- Layer thứ 3 tiếp tục là 1×1 convolution nhưng không có activation function. Linear được sử dụng thay vì ReLu như bình thường.
(Bonus một cái ảnh nếu mn quên mất Residual Block cơ bản, tiền đề của mạng ResNet)
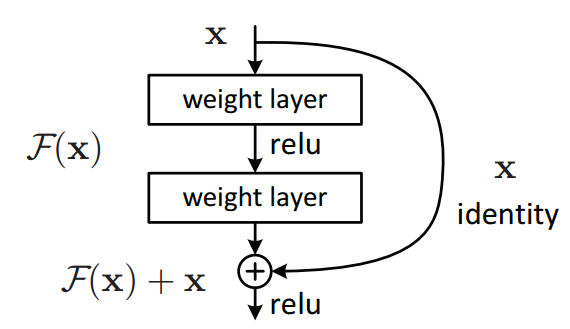
Kết nối tắt ở MobileNetV2 được điều chỉnh sao cho số input và output channels của mỗi block residual được thắt hẹp lại. Chính vì thế nó được gọi là các bottleneck layers.
Residual block của MobileNet v2 ngược lại so với các kiến trúc residual truyền thống, vì kiến trúc residual truyền thống có số lượng kênh ở input và output của một block lớn hơn so với các layer trung gian. Chính vì vậy nó còn được gọi là Inverted residual block.
Paper cho rằng các layer trung gian trong một block sẽ làm nhiệm vụ biến đổi phi tuyến nên cần dày hơn để tạo ra nhiều phép biến đổi hơn. Kết nối tắt giữa các block được thực hiện trên những bottleneck input và output chứ không thực hiện trên các layer trung gian. Do đó các layer bottleneck input và output chỉ cần ghi nhận kết quả và không cần thực hiện biến đổi phi tuyến (linear f.
Ở giữa các layer trong một block inverted residual block chúng ta cũng sử dụng những biến đổi tích chập tách biệt chiều sâu để giảm thiểu số lượng tham số của mô hình. Đây cũng chính là bí quyết giúp họ các model MobileNet có kích thước giảm nhẹ.
MobileNet v2 có 2 đóng góp vô cùng lớn:
- SSDLite+MobileNetV2 cho bài toán object detection.

- DeepLabV3 + MobileNetV2 cho bài toán semantic segmentation.
![image.png]()

3. MobileNetV3
Điểm cải tiến chính là việc bổ sung Squeeze-and-Excite.
- Về vấn đề này, mình xin phép recommend một bài viết rất chi tiết của một senpai trong team:
- Bui Quang Manh - Những mô hình trợ thủ đắc lực trong các mô hình Deep learning [Phần 1]
(sẽ update nội dung trong thời gian tiếp theo)

4. Kết
Here is all about MobileNets.
-
Paper gốc MobileNet : https://arxiv.org/abs/1704.04861
-
Paper MobileNetV2 : https://arxiv.org/abs/1801.04381v4
-
Paper MobileNetV3: https://arxiv.org/abs/1905.02244
Cảm ơn bạn đã theo dõi bài viết ^^
All rights reserved
