Xử lý dữ liệu với một số mô hình và thuật toán trong NLU
Bài đăng này đã không được cập nhật trong 6 năm
Giới thiệu
Tiền xử lý dữ liệu là bước cơ bản nhưng đóng vai trò rất quan trọng trong xử lý ngôn ngữ tự nhiên. Thành phần NLP nói chung hay cụ thể là NLU có nhiệm vụ chuyển đổi dữ liệu thô dạng văn bản sang dạng dữ liệu có cấu trúc, hay ánh xạ ngôn ngữ thành vector số để máy tính có thể hiểu được. Từ việc tiền xử lý dữ liệu ta mới có thể lựa chọn mô hình và phương pháp tốt nhất để phân loại hành động, ý định, gán nhãn dữ liệu cho văn bản. Trong bài viết này, tôi sẽ giới thiệu một số mô hình và thuật toán được sử dụng rộng rãi ứng dụng cho xử lý dữ liệu.
Word Embedding
Word Embedding là tên gọi chung của một tập hợp mô hình hóa ngôn ngữ và các kỹ thuật học tập đặc trưng trong xử lý ngôn ngữ tự nhiên trong đó các từ hoặc cụm từ từ vựng được ánh xạ tới vector số thực. Các phương pháp được sử dụng nhiều nhất là Word2vec và GloVe.
Word2vec
- Word2vec là kĩ thuật để tạo từ nhúng tốt hơn so với các thuật toán khác vì nó nắm bắt được một lượng lớn cú pháp chính xác và các mối quan hệ ngữ nghĩa giữa các từ.
- Word2vec được phát triển bởi nhóm nghiên cứu đứng đầu là Tomas Mikolov tại Google và là sự kết hợp của hai kỹ thuật là CBOW (Continuous Bag Of Words) và Skip-gram. Cả hai kỹ thuật đều sử dụng mạng neural gồm 1 lớp ẩn duy nhất.
CBOW
-
CBOW có xu hướng dự đoán xác suất của một từ được đưa ra theo ngữ cảnh. Trong mô hình này bối cảnh được thể hiện bằng nhiều từ đơn hoặc nhóm từ để nhận định từ mục tiêu. Ví dụ sử dụng từ “con mèo” và “cây” là các từ bối cảnh cho từ “trèo” chính là từ mục tiêu.
-
Lớp đầu vào (input layer) và mục tiêu đều được mã hóa one-hot với kích thước [1xV]. Cách hoạt động của nó như sau:
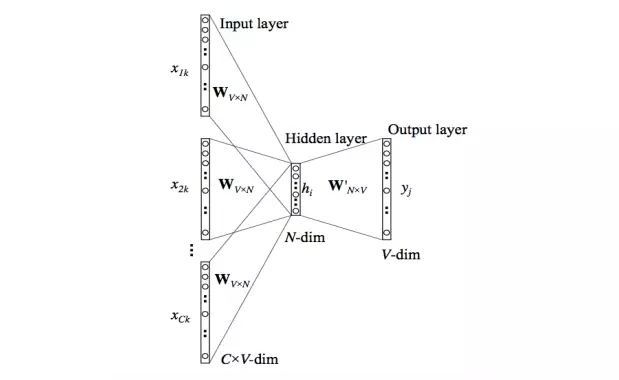
- Ma trận trọng số đầu vào ẩn có kích thước [VxN], đầu ra ẩn có kích thước [NxV], với N là số chiều biểu thị từ, cũng là số tế bào neural trong lớp ẩn.
- Các đầu vào được nhân với trọng số đầu vào ẩn (input-hidden weights) và sau khi lấy trung bình của tất cả các hàng tương ứng của ma trận trọng số đầu vào ẩn trong lớp ẩn, ta được kích hoạt ẩn (hidden activation).
- Kích hoạt ẩn tiếp tục nhân với trọng số đầu ra ẩn và đầu ra được tính toán
- Độ lệch giữa đầu ra và mục tiêu được tính toán, nếu không khớp sẽ truyền trở lại để điều chỉnh lại các trọng số
- Trọng số giữa lớp ẩn và lớp đầu ra được lấy làm vector từ đại diện. Đầu ra của neural thứ k được tính bằng biểu thức sau trong đó 𝑎𝑐𝑡𝑖𝑣𝑎𝑡𝑖𝑜𝑛(𝑛) biểu thị giá trị kích hoạt ẩn của neural lớp đầu ra thứ n:
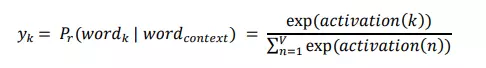
-
Dưới đây mô tả kiến trúc hoạt động của mô hình CBOW dựa trên kiến trúc mạng neural:
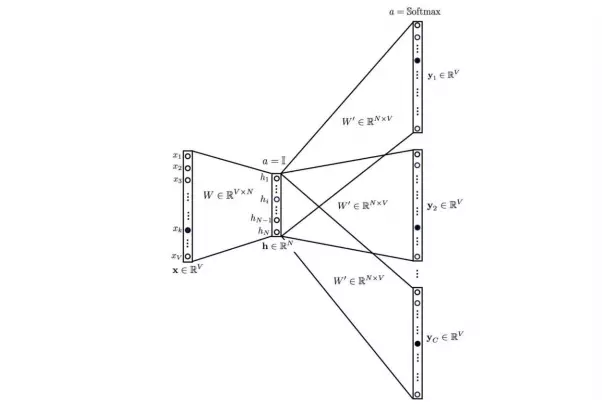
Skip-gram
-
Mô hình Skip-gram đảo ngược việc sử dụng từ mục tiêu và các từ ngữ cảnh. Lúc này từ mục tiêu được cung cấp ở đầu vào, các ma trận trọng số đầu vào ẩn và đầu ra ẩn vẫn giữ nguyên, và đầu ra là mạng neural được sao chép nhiều lần để chứa các từ ngữ cảnh. Việc tính giá trị kích hoạt ẩn giống với mô hình CBOW. Các vector lỗi cho mỗi lớp đầu ra được tổng hợp lại để lan truyền ngược lại cho việc điều chỉnh các trọng số. Trọng số giữa đầu vào và các lớp ẩn được lấy như vector từ đại diện sau huấn luyện. Còn ma trận trọng số của mỗi lớp đầu ra W' vẫn giữ nguyên sau khi huấn luyện.
-
Nếu CBOW lấy trung bình từ các ngữ cảnh của mỗi từ, thì việc nó không thể tính chính xác xác suất của từ mục đích với từ đầu vào có nhiều nghĩa. Mô hình Skip-gram thì có thể nắm bắt hai ngữ nghĩa cho một từ nên giải quyết được vấn đề này. Ví dụ từ Apple có hai vector đại diện cho nó là một cho công ty, một cho trái cây.
GloVe
- GloVe (Global Vector) là một phương pháp mới để vector hóa từ được giới thiệu vào năm 2014 và nó bao gồm các bước sau:
- Thu thập số liệu thống kê về sự xuất hiện của từ dưới dạng một ma trận vuông đối xứng cụ thể là co-occurrence matrix. Mỗi phần tử 𝑋𝑖𝑗 của ma trận đại diện cho tần suất của xuất hiện của từ 𝑖 trong ngữ cảnh của từ 𝑗 hay sự liên quan ngữ nghĩa giữa hai từ 𝑖 và 𝑗. Ví dụ về co-occurrence matrix như sau:

trong đó 𝑤 (words) là các từ, 𝑐 (contexts) là các ngữ cảnh, 𝑓𝑖𝑗 là tần suất xuất hiện là các giá trị trong bảng. GloVe biểu thị xác suất của từ qua công thức:
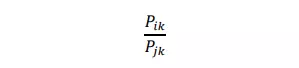
Trong đó: 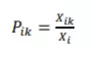 Ở đây 𝑃𝑖𝑘 biểu thị xác suất từ 𝑖 và từ 𝑘 xuất hiện cùng nhau. Với cách chia 𝑋𝑖𝑘 là số lần từ 𝑖 và từ 𝑘 xuất hiện cùng nhau cho 𝑋𝑖 là tổng số lần từ 𝑖 xuất hiện trong toàn văn bản. Ví dụ hai từ 𝑖 và 𝑗 là "mèo" và "hoa", với từ 𝑘 là "chó" thì tỉ số
Ở đây 𝑃𝑖𝑘 biểu thị xác suất từ 𝑖 và từ 𝑘 xuất hiện cùng nhau. Với cách chia 𝑋𝑖𝑘 là số lần từ 𝑖 và từ 𝑘 xuất hiện cùng nhau cho 𝑋𝑖 là tổng số lần từ 𝑖 xuất hiện trong toàn văn bản. Ví dụ hai từ 𝑖 và 𝑗 là "mèo" và "hoa", với từ 𝑘 là "chó" thì tỉ số 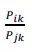 cao (lớn hơn 1) do từ 𝑘 có nghĩa gần với 𝑖 hơn 𝑗. Ngược lại tỉ số sẽ nhỏ (nhỏ hơn 1) với từ 𝑘 là "hương thơm" do 𝑘 gần nghĩa 𝑗 hơn 𝑖. Trong các trường hợp khác thì tỉ số
xấp xỉ 1 do từ 𝑘 gần nghĩa hoặc không gần nghĩa với cả hai từ 𝑖, 𝑗.
cao (lớn hơn 1) do từ 𝑘 có nghĩa gần với 𝑖 hơn 𝑗. Ngược lại tỉ số sẽ nhỏ (nhỏ hơn 1) với từ 𝑘 là "hương thơm" do 𝑘 gần nghĩa 𝑗 hơn 𝑖. Trong các trường hợp khác thì tỉ số
xấp xỉ 1 do từ 𝑘 gần nghĩa hoặc không gần nghĩa với cả hai từ 𝑖, 𝑗.
-
Công thức ràng buộc mềm giữa các cặp từ:
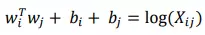 với 𝑤𝑖 là vector cho từ chính, 𝑤𝑗
là vector cho từ ngữ cảnh, 𝑏𝑖, 𝑏𝑗 là các bias vô hướng cho từ chính và từ ngữ cảnh. Ta xác định tối ưu cho hàm số cụ thể hay là cost function:
với 𝑤𝑖 là vector cho từ chính, 𝑤𝑗
là vector cho từ ngữ cảnh, 𝑏𝑖, 𝑏𝑗 là các bias vô hướng cho từ chính và từ ngữ cảnh. Ta xác định tối ưu cho hàm số cụ thể hay là cost function:
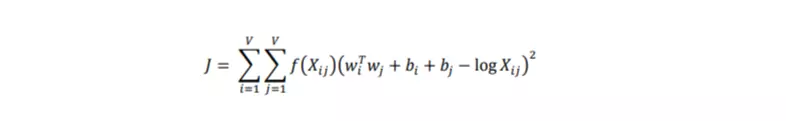
-
Ở đây hàm f là một hàm trọng số để giảm thiểu việc xuất hiện các cặp từ cực kỳ phổ biến. Các chuyên gia về GloVe chọn hàm sau:
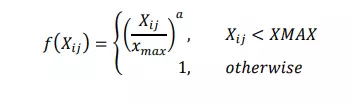
-
Ưu điểm của mô hình GloVe là huấn luyện nhanh, có khả năng mở rộng với một tập dữ liệu lớn các văn bản, cho hiệu suất nhanh ngay cả với tập dữ liệu hay các vector nhỏ.
Trích xuất thực thể với mô hình CRF
-
CRF là một khung để xây dựng các mô hình xác suất giúp phân đoạn và gán nhãn dữ liệu tuần tự hay các thực thể định danh. Các thực thể đó biểu thị cho các từ trong câu đại diện cho các đối tượng như tên người, tổ chức, địa điểm,…CRF là thuật toán xác suất có điều kiện 𝑃(𝑦|𝑥) với xác suất của vector đầu ra y của một biến ngẫu nhiên được cung cấp bởi một vector đặc trưng x.
-
Để dự đoán chuỗi thích hợp thì ta phải tối đa hóa xác suất có điều kiện và ta lấy chuỗi với xác suất lớn nhất:
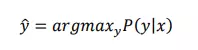
-
Trong CRF, dữ liệu đầu vào là tuần tự và chúng ta phải dựa vào ngữ cảnh trước đó để đưa ra dự đoán về một điểm dữ liệu. Ta sử dụng hàm tính năng (feature functions) có nhiều giá trị đầu vào:
- Tập hợp các vector đầu vào 𝑋
- Vị trí 𝑖 của điểm dữ liệu chúng ta đang dự đoán
- Nhãn của điểm dữ liệu 𝑖 − 1 trong 𝑋
- Nhãn của điểm dữ liệu 𝑖 trong 𝑋
-
Feature functions 𝑓𝑗 được định nghĩa như hình bên dưới:
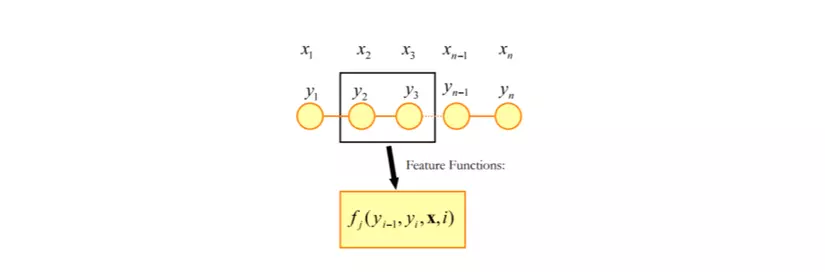
-
Mỗi hàm tính năng dựa trên nhãn của từ trước đó và từ hiện tại, có giá trị 0 hoặc 1. Chúng ta gán cho mỗi hàm một tập các trọng số (giá trị lambda), thuật toán sẽ học:
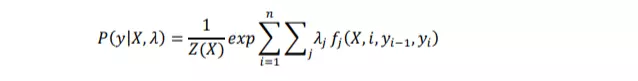
trong đó 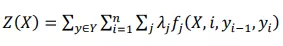 là hàm chuẩn hóa.
là hàm chuẩn hóa.
- Để ước tính các tham số lambda, chúng ta sử dụng ước tính hợp lý cực đại (Maximum likelihood estimation). Đó là một phương pháp trong thống kê để ước lượng giá trị tham số của mô hình xác suất CRF. Chúng ta áp dụng với hàm log âm tuyến tính của hàm trên:
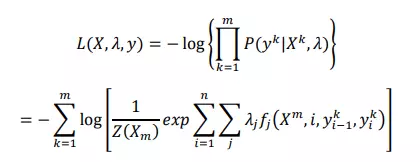
- Tính đạo hàm riêng với 𝜆 để tìm giá trị tối thiểu của riêng hàm log vì do là tìm ra giá trị argmin sẽ đạt được giá trị tối đa cho toàn hàm log âm:
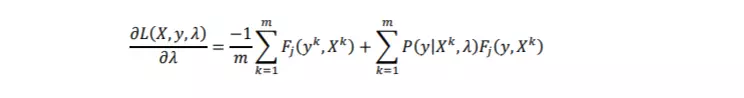
trong đó
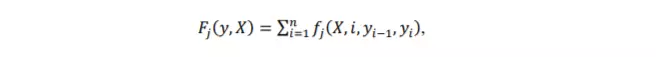
là giá trị tính năng trung bình được quan sát,
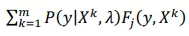
là giá trị tính năng kì vọng theo mô hình.
-
Chúng ta sử dụng đạo hàm riêng như một bước trong phương pháp gradient descent. Gradient descent là thuật toán tối ưu lặp để cập nhật các giá trị tham số cho đến khi tìm được giá trị hội tụ của lambda. Phương trình cập nhật gradient descent cuối cùng cho mô hình CRF là:
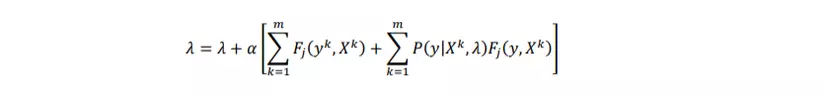
-
Tóm lại, mô hình CRF sử dụng cho việc gán nhãn thực thể, giải quyết nhược điểm sai lệch nhãn do các nhãn độc lập với nhau của mô hình Markov ẩn. CRF trước tiên xác định các hàm tính năng cần thiết, khởi tạo trọng số lambda cho các giá trị ngẫu nhiên và sau đó áp dụng phương pháp gradient descent lặp đi lặp lại cho đến khi các giá trị tham số hội tụ.
Phân loại ý định với mô hình mạng neural
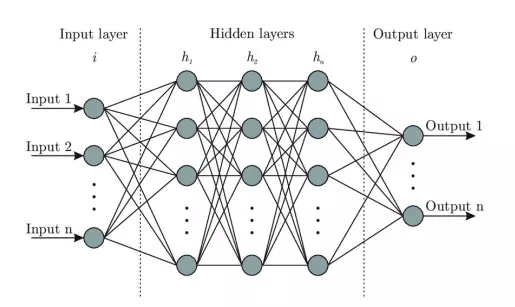
- Neural Network là mô hình một mô hình tính toán được xây dựng dựa trên mạng neural sinh học gồm một số lượng lớn các neural kết nối với nhau. Một mạng neural có cấu trúc sau:
- Input layer hay lớp dữ liệu đầu vào
- Hidden layers hay các lớp ẩn nhận các dữ liệu đầu vào và biến đổi cho các quá trình xử lý, trích xuất về sau.
- Output layer hay lớp dữ liệu đầu ra
- Mô hình đánh giá mức độ chính xác của dữ liệu đầu ra 𝑦 sẽ như sau:
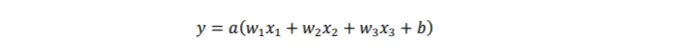
trong đó 𝑤 là các trọng số và 𝑏 là bias có ảnh hưởng trực tiếp đến kết quả đầu ra. Các mô hình mạng neural cơ bản được ứng dụng phổ biến trong việc nhận diện văn bản là mạng neural hồi quy (RNN), mạng neural bộ nhớ ngắn hạn dài (LSTM).
Mạng neural hồi quy (RNN)
- Điểm mạnh nhất của RNN là nó có khả năng xử lý dữ liệu tuần tự. Đây có lẽ là mô hình đơn giản nhất để huấn luyện và thực hiện. Tuy nhiên dù là mô hình nhớ nhưng trong việc nắm bắt thông tin của một chuỗi dài, nó cũng chỉ nhớ được thông tin một vài bước trước đó. RNN được gọi là hồi quy bởi vì nó duy trì bộ nhớ dựa trên thông tin lịch sử, cho phép mô hình dự đoán đầu ra hiện tại dựa trên các tính năng đường dài. Dưới đây là kiến trúc hoạt động điển hình của RNN:
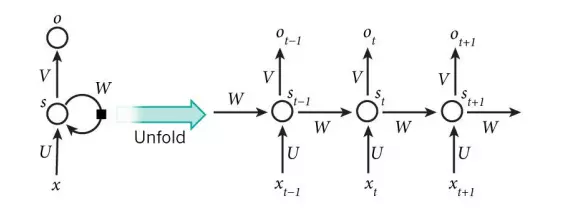
- Mạng có lớp đầu vào 𝑥, lớp ẩn 𝑠 (còn được gọi là lớp ngữ cảnh hoặc trạng thái) và lớp đầu ra 𝑦. Đầu vào của mạng trong thời gian 𝑡 là 𝑥(𝑡), đầu ra được kí hiệu là 𝑦(𝑡), 𝑠(𝑡) là trạng thái của lớp ẩn. Một vector đầu vào 𝑥(𝑡) được hình thành bằng cách nối vector 𝑤 đại diện cho từ hiện tại và đầu ra từ các neural trong lớp ngữ cảnh 𝑠 tại thời điểm 𝑡 − 1. Lớp đầu vào, lớp ẩn và lớp đầu ra được tính toán như sau:
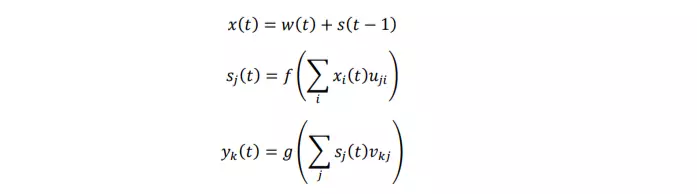
trong đó 𝑓(𝑧) là hàm kích hoạt sigmoid:
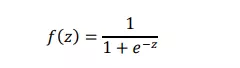
và 𝑔(𝑧) là hàm softmax:
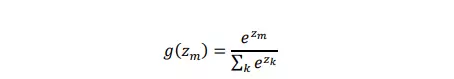
- Giá trị lớp ẩn 𝑠(0) được khởi tạo có thể là giá trị của các giá trị nhỏ, như 0.1. Đối với việc xử lý một lượng lớn dữ liệu thì giá trị khởi tạo là không cần thiết. Tại thời điểm 𝑡 + 1, vector đầu vào 𝑥(𝑡) đại diện cho từ ở thời điểm 𝑡 được mã hóa bằng 1-of-N và lớp bối cảnh trước đó. Kích thước của vector 𝑥 bằng tổng kích thước của từ vựng V (thường là 30000-200000) và kích thước lớp ẩn 𝑠 (thường là 30-500 đơn vị ẩn). Lớp đầu ra 𝑦(𝑡) thể hiện đại diện cho phân phối xác suất của từ tiếp theo dựa trên từ 𝑤(𝑡) được cho trước đó và giá trị bối cảnh 𝑠(𝑡 − 1). Hàm softmax đảm bảo rằng một phân phối xác suất là hợp lệ với 𝑦𝑚(𝑡) > 0 cho bất kỳ từ 𝑚 nào và tổng các phân phối xác suất là 1: ∑ 𝑦𝑘(𝑡) 𝑘 = 1.
- Trong mỗi bước huấn luyện thì giá trị vector lỗi được tính dựa theo tiêu chuẩn entropy chéo và nếu giá trị đầu ra không phù hợp với giá trị mong muốn của mô hình thống kê thì trọng số sẽ được cập nhật bằng thuật toán lan truyền ngược (backpropagation):
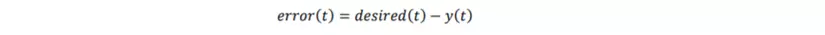
trong đó 𝑑𝑒𝑠𝑖𝑟𝑒𝑑(𝑡) là vector sử dụng 1-of-N đại diện cho giá trị từ đó nên được dự đoán trong bối cảnh cụ thể tại thời điểm 𝑡, 𝑦(𝑡) là giá trị đầu ra thực tế tại thời điểm 𝑡 đã được tính ở trên. Trong các năm qua, các nhà nghiên cứu đã phát triển các loại mô hình RNN tối ưu hơn so với mô hình truyền thống.
RNN hai chiều
- Kết quả đầu ra tại thời điểm 𝑡 không chỉ phụ thuộc vào các từ được cho trước đó mà còn phụ thuộc các từ trong tương lai hay được tính dựa trên trạng thái của hai mô hình RNN xếp chồng lên nhau. Khi dự đoán từ còn thiếu trong một chuỗi chúng ta có thể quan sát bối cảnh hai phía trái phải.
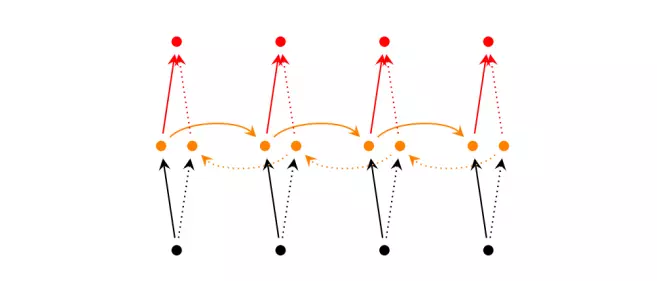
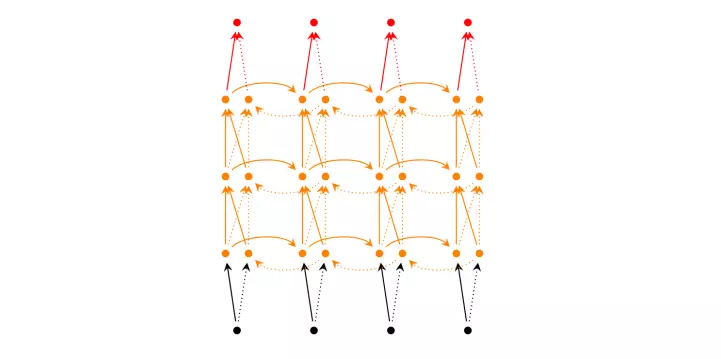
RNN (2 chiều) sâu
- Mô hình này tương tự như mô hình RNN hai chiều, chỉ có điều chúng có nhiều lớp cho mỗi thời điểm nên nhìn chung RNN sâu đòi hỏi khối lượng dữ liệu huấn luyện lớn để đảm bảo kết quả đầu ra thích hợp hơn.
Mạng LSTM
- Thực tế RNN chỉ học và truy cập thông tin qua một số trạng thái nhất định, với các trạng thái càng xa với việc tính toán tại thời điểm hiện tại thì nó không thể học được các thông tin đó. Hiện tượng này được gọi là biến mất đạo hàm (vanishing gradient).
- Mô hình mạng LSTM khá phổ biến ngày nay và chúng ta sẽ nói cụ thể ở phần sau. LSTM có một cách tính khác cho trạng thái ẩn. Bộ nhớ trong LSTM được gọi là các cells và khi nhận dữ liệu đầu vào cùng trạng thái trước đó, nó sẽ quyết định nên giữ thông tin nào và xóa thông tin nào khỏi bộ nhớ. Nhờ đó mà nó có thể lưu trữ thông tin dài hơn, dễ dàng truy cập lại để giải quyết vấn đề vanishing gradient của RNN.
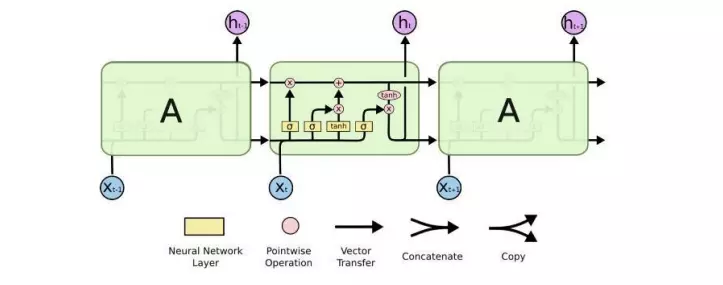
Mạng neural bộ nhớ ngắn hạn dài (LSTM)
- LSTM là một kiến trúc mạng neural hồi quy giống như RNN, ngoại trừ việc cập nhật lớp ẩn được thay thế bởi các ô nhớ được xây dựng có mục đích. Do đó, nó có thể tốt hơn trong việc tìm kiếm và khai thác sự phụ thuộc giữa các dữ liệu trong khoảng dài hơn so với RNN truyền thống.
- Một mạng LSTM điển hình bao gồm các khối nhớ khác nhau được gọi là các cells. Có hai trạng thái được chuyển đến cell tiếp theo là cell state (ô trạng thái) và hidden state (trạng thái ẩn). Các khối nhớ chịu trách nhiệm ghi nhớ và thao tác với bộ nhớ này được thực hiện thông qua ba cơ chế chính đó là các cổng (gates) như hình bên dưới:
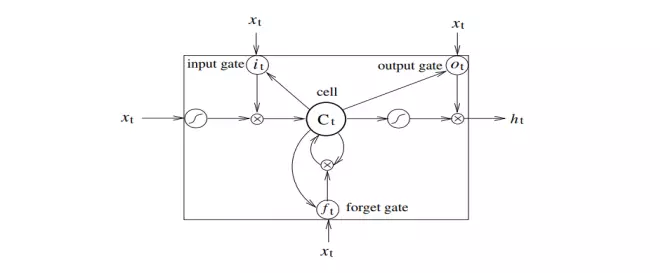
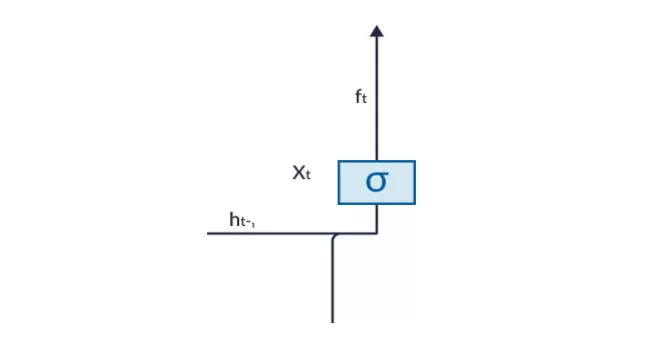
Forget Gate (Cổng quên)
-
Một ví dụ về dự đoán văn bản, giả sử LSTM nhận đầu vào là câu: “Buổi sáng hôm nay trời nắng. Trong khi buổi tối trời lại mưa to”. Ngay sau dấu “chấm” kết thúc câu đầu, forget gate nhận ra có sự thay đổi bối cảnh trong câu tiếp theo. Do đó chủ đề của câu bị bỏ qua và khi bắt đầu câu sau thì chủ đề được đặt cho bối cảnh này. Quá trình loại bỏ thông tin không cần thiết hoặc ít quan trọng này được thực hiện bởi forget gate. Điều này là cần thiết để nâng cao hiệu suất của mạng LSTM.
-
Cổng này có hai đầu vào là ℎ(𝑡 − 1) và 𝑥(𝑡). ℎ(𝑡 − 1) là trạng thái ẩn hoặc đầu ra của cell tại thời điểm 𝑡 − 1, 𝑥(𝑡) là đầu vào tại thời điểm 𝑡. Các đầu vào được nhân với ma trận trọng số và cộng thêm tham số bias. Hàm sigmoid áp dụng cho giá trị đó và trả về một vector với khoảng giá trị trong khoảng [0, 1], tương ứng với mỗi số ở cell state. Hàm sigmoid chịu trách nhiệm nên giữ lại giá trị nào và loại bỏ giá trị nào. Nếu “0” là đầu ra cho một giá trị cụ thể ở cell state nghĩa là forget gate muốn cell state loại bỏ hoàn toàn thông tin đó. Ngược lại nếu đầu ra là “1” nghĩa là forget gate muốn lưu lại thông tin đó. Đầu ra vector này từ hàm sigmoid được nhân với cell state.
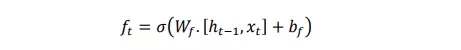
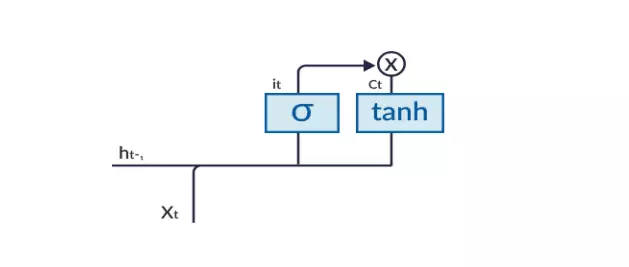
Input Gate (Cổng đầu vào)
-
Cổng đầu vào chịu trách nhiệm bổ sung thông tin vào cell state. Việc thêm thông tin này về cơ bản là quá trình ba bước như sơ đồ sau:
-
Nó điều chỉnh những giá trị nào cần thêm vào cell state bằng hàm sigmoid. Điều này rất giống với forget gate
-
Hàm sigmoid tạo một vector chứa tất cả các giá trị có thể được thêm vào cell state (từ việc 𝑖(𝑡) là hàm sigmoid của ℎ(𝑡 − 1) và 𝑥(𝑡)).
-
Nhân giá trị của bộ lọc điều chỉnh (cổng sigmoid) với vector đã tạo bởi hàm tanh và sau đó thêm thông tin hữu ích này vào cell state.
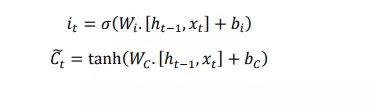
-
Khi quy trình này được thực hiện, thông tin đảm bảo được lưu vào cell state và không có dư thừa.
Output Gate (Cổng đầu ra)
-
Không phải tất cả thông tin đều chạy dọc theo cell state và đều phù hợp để được trích xuất tại cùng một thời điểm nhất định. Output gate có trách nhiệm chọn và xuất ra các thông tin cần thiết từ cell hiện tại.
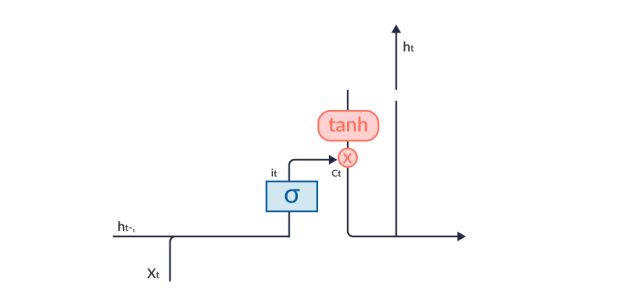
-
Chức năng của một cổng đầu ra cũng được chia thành ba bước:
- Tạo ra một vector sau khi áp dụng hàm 𝑡𝑎𝑛ℎ cho cell state, sau đó chia tỷ lệ các phạm vi trong khoảng [-1, 1].
- Tạo một bộ lọc bằng các giá trị của ℎ(𝑡 − 1) và 𝑥(𝑡), sao cho nó có thể điều chỉnh các giá trị cần lấy ra từ vector được tạo ở trên. Bộ lọc này sử dụng hàm sigmoid.
- Nhân giá trị của bộ lọc điều chỉnh này với vector được tạo ở trên và gửi nó dưới dạng đầu ra và cả cell state của cell tiếp theo.
Kết luận
- Như vậy tôi đã giới thiệu qua một số mô hình và thuật toán NLU thường được sử dụng trong việc tiền xử lý dữ liệu cũng như phân loại ý định, gán nhãn thực thể. Hiện nay, trong Deep Learning, người ta sử dụng kết hợp hai mô hình LSTM + CRF thay cho CRF truyền thống trong việc xử lý dữ liệu đầu vào. Hi vọng bài viết này sẽ đóng góp chút ích cho việc học tập và nghiên cứu của các bạn. Chúc các bạn thành công.
- Tài liệu tham khảo:
- Zhiheng Huang, Wei Xu, Kai Yu”, Bidirectional LSTM-CRF Models for Sequence Tagging, 2015
- John Lafferty, Andrew McCallum, Fernando C.N. Pereira”, Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data, University of Pennsylvania, 2001
- Giovanni Di Gennaro, Amedeo Buonanno, Antonio Di Girolamo, Armando Ospedale, Francesco A.N. Palmieri”, Intent Classification in Question-Answering Using LSTM Architectures, “Universita degli Studi della Campania, Luigi Vanvitelli, Dipartimento di Ingegneria via Roma 29, Aversa (CE), Ilaty”, 2020
All rights reserved
