
Tìm hiểu 1 số mô hình Text-To-Speech (P1)
Bài đăng này đã không được cập nhật trong 4 năm
1. Tacotron 2
Tacotron 2 là 1 mô hình tổng hợp tiếng nói trực tiếp từ văn bản đầu vào. Nó dựa trên sự kết hợp giữa convolution neural network (CNN) và recurrent neural network (RNN).
Có 2 thành phần chính trong Tacotron 2:
- 1 mạng seq2seq có tên Spectrogram Prediction Network dùng để dự đoán chuỗi mel spectrogram từ 1 chuỗi kí tự đầu vào.
- 1 phiên bản điều chỉnh của WaveNet tạo ra âm thanh dựa vào phổ Mel được dự đoán ở trên.
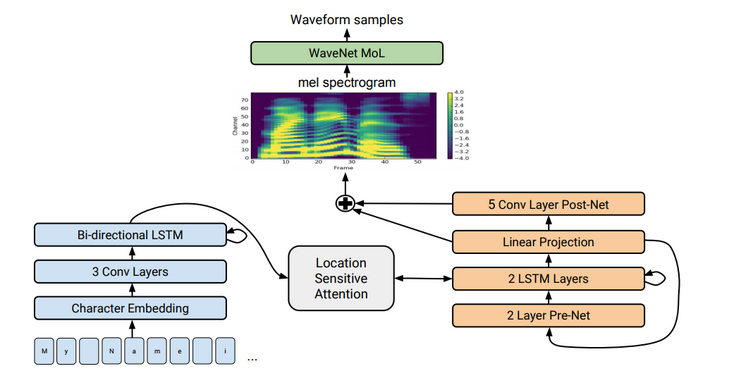
1 cách đơn giản hơn, Tacotron 2 hoạt động theo nguyên lý kết hợp của 2 mạng neural network: 1 cái chuyển đổi text sang Mel Spectrogram, cái còn lại chuyển từ Mel Spectrogram đấy sang các âm thanh tương ứng.
1.1 Spectrogram Prediction Network
Trong Tacotron, Mel Spectrogram được tính thông qua short-time Fourier transform (STFT) với: 50 ms frame size, 12.5 ms frame hop. Sau đó biến đổi sang mel scale bằng mel filterbank 80 channel trải dài 125Hz đến 7.6Khz.
Layer đầu tiên là embedding layer, tạo ra vector 512 chiều từ 1 chuỗi kí tự đầu vào. Sau đó embedding vectỏ được truyền qua 3 lớp 1D Convolution layer, mỗi lớp chứa 512 filter có size 5x1. Đây là filter size hợp lí vì nó giữ được thông tin character hiện tại, và 2 character trước nó và sau nó. Theo sau đó là lớp Mini-Batch Normalization, và activation function ReLU.

Đầu ra của Encoder sau đó được cho qua mạng Attention để tổng hợp lại chuỗi encode thành 1 context vector cố định cho mỗi step tại output Decoder. Trong bài báo sử dụng cơ chế location-sensitive attention để sử dụng trọng số attention tích lũy từ các Decoder time-step trước kết hợp đặc trưng ở vị trí hiện tại để tính toán trọng số. Điều này giúp model luôn tịnh tiến lên phía trước qua các input, loại bỏ các thông tin bị lặp lại hoặc bỏ qua của Decoder. Xác suất chú ý được tính thông qua chiếu inputs và đặc trưng vị trí lên một ma trận đặc trưng có kích thước 128 chiều.
Decoder là 1 mạng RNN tự hồi quy có mục tiêu là sinh ra Mel Spectrogram từ chuỗi input được encode. Prediction từ time-step trước đầu tiên được truyền qua mạng pre-net bao gồm 2 lớp fully connected, mỗi lớp có 256 unit theo sau là ReLU. Bài báo nhận thấy rằng pre-net hoạt động như là 1 information bottleneck rất cần thiết cho việc học các trọng số attention. Đầu ra của lớp pre-net được concatenate với đầu ra của mạng attention và được đưa qua 2 lớp LSTM với 1024 unit. Sau đó concatenate giữa đầu ra của LSTM và attention context vector được chiếu qua phép biến đổi tuyến tính để dự đoán spectrogram frame. Cuối cùng, các Mel Spectrogram vừa được dự đoán đi qua 5-layer convolution post-net để tạo ra thông tin bổ sung vào với Spectrogram ở trên để cải thiện khả năng tái cấu trúc âm thanh. Mỗi post-net layer được cấu thành bởi 512 filter có chiều 5x1 kết hợp với Batch Normalization, theo sau bởi hàm tanh.

Trong đó paper cũng thêm vào 1 lớp để dự đoán stop token để tự động kết thúc trước khi đến kích thước cố định.
1.2 Vocoder
Vocoder - hiểu đơn giản là bộ phát âm, được dùng để biến đổi dữ liệu từ định dạng Mel-spectrogram sang waveform (miền thời gian) mà con người có thể nghe được.
Âm thanh dạng waveform sau khi biến đổi STFT (Short time furier transform), ta tách thành 2 loại thông tin: magnitude và phase (cường độ và pha). Spectrogram chỉ là thông tin về magnitude. Điều đó đồng nghĩa với việc cần cả magnitude và phase mới có thể khôi phục lại âm thanh ban đầu. Như vậy, spectrogram mà model trả ra chưa đủ để phục dựng lại âm thanh dạng waveform.
Trước đây, tacotron sử dụng thuật toán Griffin-Lim để ước lượng ra phase dựa vào spectrogram. Sau đó khôi phục lại âm thanh dựa vào spectrogram (magnitude) và phase. Tuy nhiên cách này cho chất lượng âm thanh chưa hoàn hảo, âm thanh không trong, đôi khi xuất hiện nhiều nhiễu.
Trong tacotron2, nhóm tác giả đã tận dụng WaveNet - mô hình sinh âm thanh được nghiên cứu trước đó vài năm (và tất nhiên vẫn là của Google). WaveNet hoạt động dựa trên các dilation convolution. Nhìn vào hình minh họa, bạn có thể thấy rằng 1 điểm dữ liệu được sinh ra dựa trên các điểm dữ liệu trong quá khứ. Và với dilation convolution, phạm vi bao phủ được trải rộng ra hơn rất nhiều so với convolution thông thường.
1.3 Nguồn tham khảo
- https://viblo.asia/p/text-to-speech-with-tacotron-2-L4x5x6DOZBM
- https://viblo.asia/p/tim-hieu-kien-truc-text2speech-noi-danh-mot-thoi-tacotron-phan-2-4P856r9A5Y3
- https://arxiv.org/abs/1712.05884
2. FastSpeech
Tiếp tục tìm hiểu về mô hình tiếp theo về bài toán TTS. Mô hình Tacotron là mô hình autoregressive (mô hình dự đoán giá trị tương lai dựa vào các giá trị trong quá khứ). Nhược điểm của mô hình này chính là tốc độ chậm do kiến trúc tuần tự seq2seq, các từ khi sinh ra gặp hiện tượng bỏ qua hoặc lặp lại, âm thanh khi sinh ra không kiểm soát được tốc độ giọng nói.
Chính vì thế 1 số mô hình non-autoregressive ra đời nhằm khắc phục yếu điểm này. Chúng ta cùng tìm hiểu 1 đại diện là FastSpeech được đề xuất bởi Microsoft vào 2019 với tên FastSpeech: Fast, Robust and Controllable Text to Speech. FastSpeech sử dụng 1 kiến trúc độc đáo cải thiện performance trong 1 số lĩnh vực khi so sánh với các mô hình TTS khác.
Một số ưu điểm đáng kể của FastSpeech:
- fast: FastSpeech tăng tốc độ sinh ra mel-spectrogram lên 270 lần và tốc độ sinh giọng nói lên 38 lần.
- robust: FastSpeech tránh được lỗi lặp từ và bỏ qua từ do error propagation và wrong attention alignment.
- controllable: FastSpeech có thể điều chỉnh tốc độ giọng mượt và kiểm soát được sự ngắt nghỉ của từ.
- high quality: FastSpeech có chất lượng rất tốt, khá tương đương các mô hình autoregressive như Tacotron mà tốc độ nhanh hơn rất nhiều.
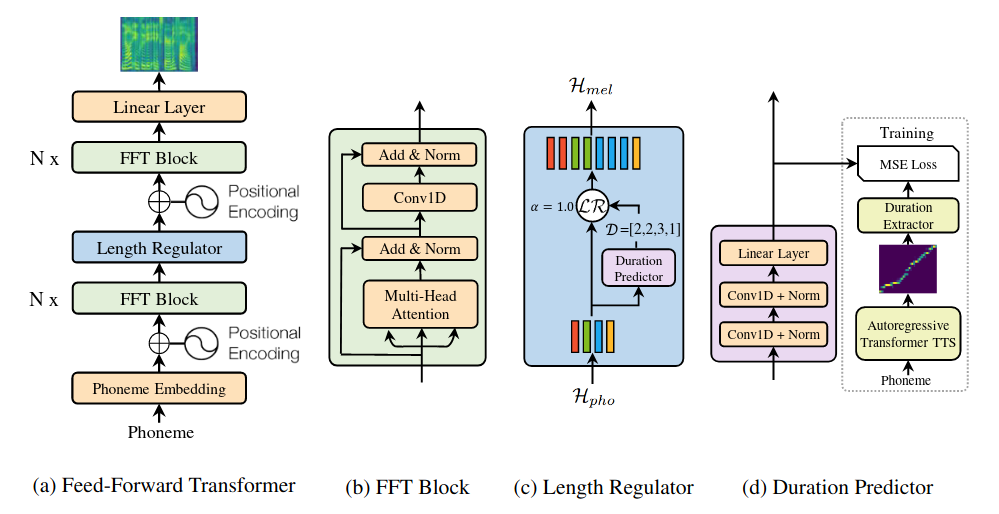
Kíến trúc tổng quan của FastSpeech gồm có 3 module chính:
- Feed-Forward Transformer: giúp sinh mel-spectrogram song song thay vì sinh mel-spectrogram một cách tuần tự như các mô hình autogressive.
- Length Regulator: giúp điều chỉnh độ dài ngắn của trường âm thông qua đó xác định độ dài mel-spectrogram.
- Duration Predictor: đảm bảo hard-alignment giữa phoneme và mel-spectrogram, từ đó giảm tỷ lệ mất, lặp từ.
2.1 Feed-Forward Transformer
Kiến trúc FastSpeech được dựa trên self-attention trong Transformer và 1D convolution, ta gọi khối này là Feed-Forward Transformer (FFT). FFT stack nhiều khối FFT lại để biến đổi âm vị sang mel-spectrogram, với N khối ở phía âm vị và N khối ở phía mel-spectrogram, được kết nối qua Length Regulator. Mỗi khối FFT bao gồm self-attention (cụ thể là multi-head attention) và 1D Convolution. Khác với kiến trúc gốc trong Transformer, chúng ta sử dụng 2 lớp 1D convolution kết hợp hàm kích hoạt ReLU. Tác giả giải thích rằng các trạng thái ẩn kề nhau sẽ có liên kết chặt chẽ hơn ở trong âm vị và mel-spectrogram. Cùng với đó residual connection, layer normalization và dropout được thêm vào lần lượt phía sau mạng self-attention và Convolution 1D.
2.2 Length Regulator
Length Regulator dùng để giải quyết vấn đề về sự không đồng nhất giữa chuỗi âm vị và chuỗi spectrogram trong FFT (do độ dài của chuỗi âm vị ngắn hơn độ dài chuỗi mel-spectrogram, 1 âm vị tương ứng với vài spectrogram). Số lượng mel-spectrogram ứng với âm vị gọi là phoneme duration. Dựa vào phoneme duration d, length regulator mở rộng hidden state của chuỗi âm vị lên d lần, để thu được tổng độ dài của hidden state bằng độ dài của mel-spectrogram.
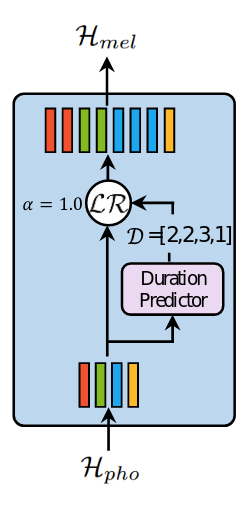
Kí hiệu trạng thái ẩn của chuỗi âm vị là , với n là độ dài của chuỗi. Kí hiệu chuỗi phoneme duration là , với và m là độ dài của chuỗi mel-spectrogram. Ta kí hiệu length regulator là:
với là 1 hyperparameter để xác định độ dài của chuỗi mở rộng , từ đó kiểm soát được tốc độ đọc. Ví dụ, với và chuỗi phoneme duration tương ứng , khi đó chuỗi mở rộng $\mathcal{H}_{mel} trở thành: nếu = 1 (tốc độ bình thường).
Với = 1.3 (tốc độ chậm) và 0.5 (tốc độ nhanh), chuỗi duration trở thành
khi đó chuỗi mở rộng trở thành
Ta cũng có thể điều chỉnh sự ngắt nghỉ giữa các từ bằng cách điều chỉnh duration của các kí tự cách trong câu giúp cho giọng đọc giống với người thật hơn.
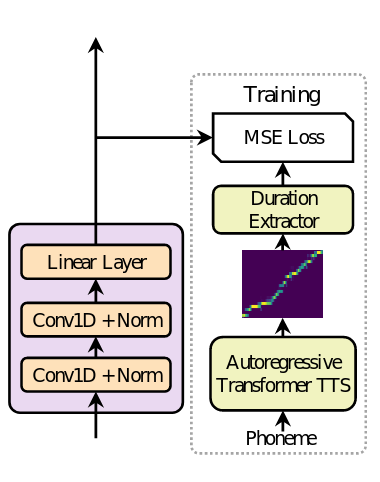
2.3 Duration Predictor
Một phần không thể thiếu của length regulator chính là phoneme duration prediction. Duration predicotr bao gồm 2 lớp 1D convolution cùng với hàm ReLU, theo sau là layer normalization và dropout. Cuối cùng là 1 lớp tuyến tính ở cuối để đầu ra là 1 số, hay chính là predict phoneme duration. hú ý rằng kiến trúc này nằm trên các khối FFT được stack lại với nhau ở phía âm vị và được train đồng thời với mô hình FastSpeech để dự đoán độ dài mel-spectrogram với mỗi âm vị.
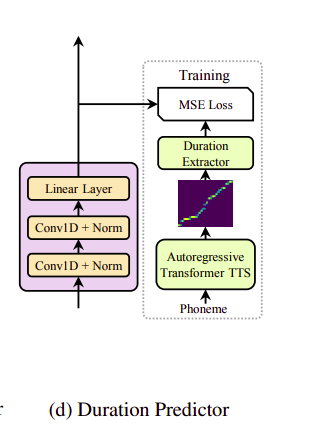
Để huấn luyện duration predictor, tác giả sử dụng 1 mô hình autoregressive teacher TTS để trích xuất duration của mỗi âm vị. Cụ thể như sau:
- Huấn luyện mô hình Autogressive encoder-attention-decoder based Transformer TTS.
- Với mỗi cặp dữ liệu, trích xuất các giá trị decoder-to-encoder attention alignment từ teacher model đã được huấn luyện. Có rất nhiều attention alignment do mô hình sử dụng multi-head attention. Tuy nhiên, không phải tất cả các head đều được sử dụng mà tác giả đưa ra 1 tỉ lệ focus rate F:
với S và T là độ dài ground truth của spectrogram và phoneme, là phần tử ở hàng s-th cột t-th trong ma trận attention. Chúng ta tính focus rate cho mỗi head và chọn head có giá trị F lớn nhất.
Cuối cùng thu được chuỗi thời lượng âm vị với
Và cuối cùng chúng ta đã có được ground-truth của thời lượng âm . Giá trị này sau đó được tính lỗi bằng MSE và được cập nhật các tham số của Duration Predictor.
2.4 Kết quả
Audio Quality: FastSpeech đạt 3.84 MOS xấp xỉ với các phương pháp như Tacotron 2 hay Transformer TTS model.
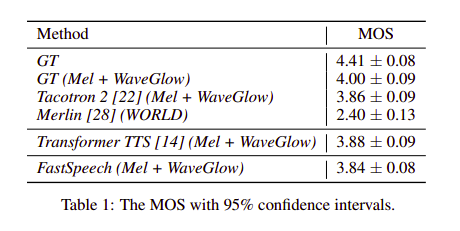
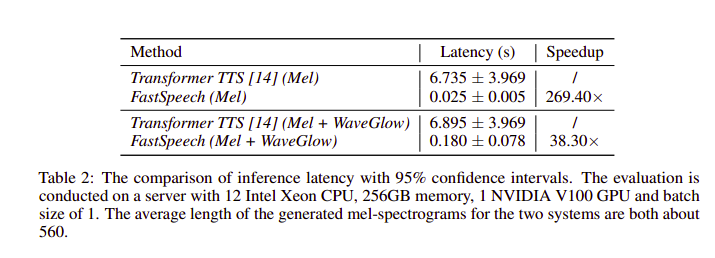
Inference Speedup: Tốc độ sinh mel-spectrogram của Fast Speech nhanh gấp 269.4 lần so với mô hình Transformer TTS. Kể cả có dùng vocoder WaveGlow, tốc độ sinh audio của FastSpeech vẫn hơn 38.3. lần so với Transformer TTS.
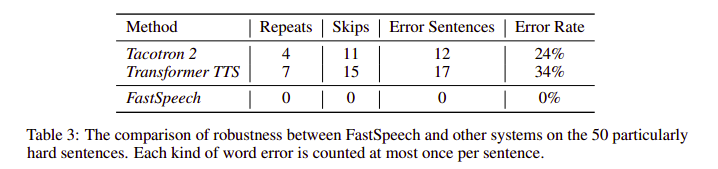
Robustness: FastSpeech đã hạn chế được các vấn đề lặp hay mất từ ở các autogressive model.
Length Control: FastSpeech có thể điều chỉnh tốc độ âm thanh bằng cách điều chỉnh độ dài phoneme duration, cũng như thêm ngắt nghỉ giữa các từ bằng cách kéo dài thời lượng của các ký tự cách (space).
2.5 Nguồn tham khảo
All rights reserved
