
Tìm hiểu bài toán OCR với CRNN và CTC loss - OCR from scratch with PyTorch (P1)
Bài đăng này đã không được cập nhật trong 5 năm
Bài viết bao gồm những kiến thức cơ bản của bản thân mình trong bài toán OCR. Hi vọng có thể cung cấp cho các bạn beginner một tutorial khởi đầu dễ hiểu và đầy đủ nhất. Bắt đầu nhé.
Kiến thức cần có trước khi đọc bài: CNN, RNN.
1. OCR là gì ?
OCR (Optical Character Recognition) là bài toán nhận dạng kí tự quang học.
Yêu cầu đặt ra là phải chuyển những hình ảnh văn bản kỹ thuật số hoặc văn bản viết tay thành dữ liệu lưu trong tệp văn bản (text). Hình ảnh ở đây có thể là biển số xe, biển hiệu, các loại văn bản, giấy tờ, hóa đơn, căn cước công dân cần đến OCR, và việc chúng ta là trích xuất thông tin văn bản từ nó..
Đại khái là, input của chúng ta là một cái ảnh chứa text. Output là những đoạn text xuất hiện trong cái ảnh đó.
Về cơ bản, có 2 thuật toán deep learning chủ yếu để giải quyết bài toán này, một là Attention OCR và hai là CRNN with CTC loss. Nhìn chúng, chúng ta sẽ cần một CNNs để trích xuất các đặc trưng của ảnh, và bởi vì đầu ra là chuỗi, nên ta nghĩ ngay đến cần RNN để xử lí.
Trong bài viết này, mình sẽ đào sâu hơn về phương pháp thứ hai.
2. CRNN with CTC loss
Bài viết được dựa trên bài báo An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition. Bạn đọc có thể tham khảo tại đây.
Theo bài báo, các kết quả của mô hình này đạt được bao gồm:
- End to end
- Xử lý các chuỗi với độ dài tùy ý, chỉ yêu cầu giới hạn chiều cao.
- Đạt hiệu suất tốt kể cả khi từ vựng đó không xác định trước (không có trong bộ từ vựng)
- Gọn nhẹ
Mô hình gồm 3 thành phần chính:
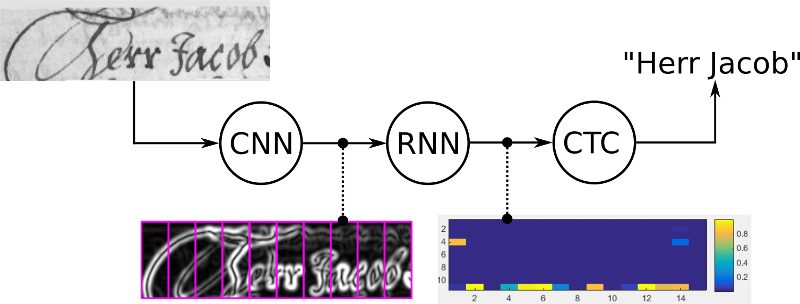
1. Feature Sequence Extraction với Convolution layers
Đầu tiên, ta cần đưa mọi input image về cùng một height, sau đó đưa qua một mạng CNN. (Input size = batch size x channel x width x height) Ở phần này, ta thường sử dụng một số model CNN chuẩn như VGG, ResNet làm backbone (cắt bỏ lớp fully connected).
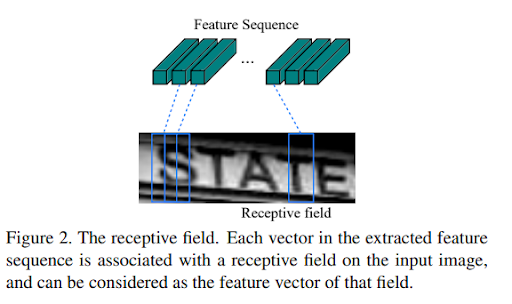
Mục đích của phần này là trích chọn các đặc trưng của ảnh. Output sẽ là các feature maps. Từ feature maps, ta tạo ra một chuỗi các features vector. bằng cách reshape matrix thành vector, trong đó, vector thứ i là concat của các column i trên tất cả các maps. Độ rộng của mỗi column được cố định là 1 pixels. Như vậy, output cuối cùng là chuỗi các feature vector, là một tensor 3 chiều có kích thước batch size x 1 x f.
2. Sequence Labeling với Recurrent layers
Mục tiêu: đưa ra dự đoán phân bố nhãn cho từng frame một.
Bạn có thể đọc lại kiến thức về RNN tại link này.
Trong phần này, từ các feature vector x1, x2, … xT, ta sẽ output ra một phân phối nhãn yt cho từng frame xt.
Tại sao phải sử dụng RNN mà không dùng classify đơn giản cho từng frame ? Sử dụng RNN ở đây có 3 lợi ích:
-
Một là, RNN tốt trong việc nắm bắt thông tin theo dạng chuỗi. Quan sát hình 2, ta có thể thấy một số kí tự yêu cầu nhiều frame liên tiếp mới có thể mô tả đầy đủ. Đồng thời, một số ký tự khó có thể phân biệt nếu không dựa vào ngữ cảnh của chúng. Ví dụ, “i” và chữ “l”, “o” và “O” thường dễ nhầm với nhau, lúc này, RNN có thể nắm bắt được thông qua đối chiếu chiều cao các kí tự. Nếu nhận dạng từng ký tự riêng biệt thì điều này không thể thực hiện được.
-
Hai là, cho phép train cả conv layers và recurrent layers trong một mạng thống nhất.
-
Thứ ba là, hoạt động trên chuỗi có độ dài tùy ý. (chỉ yêu cầu trong cùng một batch phải cùng độ dài)
Vì RNN cơ bản gặp một số vấn đề như vanishing gradient khi câu quá dài, exploding gradient, vấn đề speed khi phải xử lý tuần tự, vấn để structured bias.
Để xử lý nó, người ta thay thế bằng LTSM hoặc BiLSTM tùy theo dữ liệu chúng ta cần nhận dạng. (dù vẫn chưa giải quyết được triệt để vấn đề, ví dụ LSTM có thể giảm vanishing gradient nhưng lại làm chậm tốc độ xử lí). Đối với nhận dạng câu, văn bản ngữ cảnh, xem xét câu từ trái sang phải hay phải sang trái đều có thể mang lại thông tin hữu ích, lúc này sẽ cần đến BiLSTM.
3. Transcription layers
Mục tiêu là chuyển per-frame prediction của RNN thành final predicted sequence.
Sau khi dùng mạng CNN để trích xuất đặc trưng và RNN để lấy thông tin chuỗi, cuối cùng ta thu được một ma trận. Giả sử ở đây là X = x1, x2.. xT. Ta cần mapping nó với output Y = y1, y2,.. yU. Dễ thấy, X và Y có thể có độ dài khác nhau, và đối với Y (text), ta hoàn toàn không biết từng ký tự nằm ở đâu trong ảnh. Việc dán nhãn chính xác đến từng ký tự là một công việc quá tiêu tốn time và không cần thiết.
Ta sẽ giải quyết nó bằng CTC. CTC loss., tức Connectionist Temporal Classification. Đúng vậy, CTC network chẳng qua chỉ là một network classify thông thường có output theo thời gian. Và CTC cũng phù hợp cho cả hai task sau:
- train: tính toán loss để huấn luyện mạng
- predict (inference): decode ma trận này để lấy output text. Bằng sách tính Y* = argmax p(X|Y)
Training
Đầu tiên, hãy xem CTC được dùng trong training như thế nào?
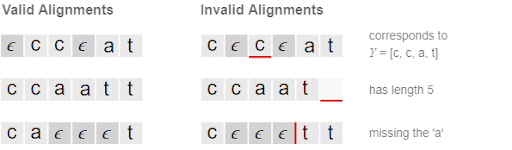
Ở ví dụ dưới, đầu vào của chúng ta (tức output của RNN) có độ dài 6 (6 time step). Y của chúng ta có độ dài 3, Y = [c,a,t]. Một cách đơn giản, ta có thể align X và Y như sau:

Tuy nhiên, cách tiếp cận trên có 2 vấn đề:
- Điều này buộc đầu ra của RNN phải ứng với 1 trong kí tự. Tuy nhiên, đôi khi trong 1 frame lại không chứa ký tự nào. (background)
- Output sai. Ví dụ như “ggooodd” , output sẽ là “god” trong khi nó có thể là “good”, hoặc ví dụ như “ttoo”, output sẽ là “too” hay “to”?
CTC giải quyết bằng cách đề xuất 1 loại ký tự là ký tự khoảng trắng, kí hiệu “-”, để tạo ra các alignment. Khi encoding text, chúng ta sẽ thêm rất nhiều ký tự trắng tùy ý vào các vị trí bất kỳ trong câu. Đồng thời, giữa 2 ký tự liền nhau và giống nhau, bắt buộc phải thêm khoảng trắng. Ví dụ: “good” → “--ggoo-oo--dd--”,không được là “--g--oodd--” “god” → “--ggoooo--dd” hoặc “-god”
Hình dưới cho thấy thế nào là alignment đúng là alignment không đúng.
Lúc này, score của 1 đường đi qua tất cả các từ (hay còn gọi là 1 alignment) bằng tích score các điểm trên đường. Ở giai đoạn encode, ta sẽ tính toán tất cả các alignment có thể xảy ra, sau đó cộng chúng lại. Cuối cùng, chúng ta có được hàm loss.
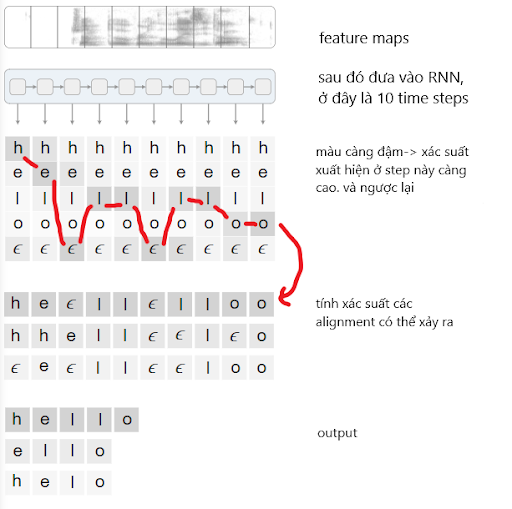
Sau khi có được hàm loss, chúng ta có thể tính toán gradient như thông thường. Tham số sẽ được điều chỉnh để minimize hàm negative log-likelihood.
Quá trình Decoder
Khá đơn giản với 2 steps:
-
Tìm alignment nào đi qua các ký tự có xác suất cao nhất trong từng time step.
-
Bỏ đi ký tự giống nhau liên tiếp, rồi sau đó mới bỏ đi các ký tự trắng.
Ví dụ, thu được chuỗi “--g-oo-odd-”, bỏ ký tự liên tiếp, thu được “-g-o-o-d-”, tiếp tục bỏ ký tự trắng, vậy từ thu được là “good”. Còn nếu chuỗi thu được là “--goo--dd”, chuỗi thu được là “god”. Giờ ta có thể nhận diện được “god” hay là “good” rồi.. Ngoài ra có nhiều bộ decoder nâng cao hơn như beam search decoding, prefix-search decoding hay token passing.
Để hiểu rõ hơn nữ về CTC, bạn đọc có thể đọc tại đây
Theo bài báo, mô hình của họ sử dụng stochastic gradient descent. Đồng thời để optimization, họ sử dụng ADADELTA. Lí do là vì AdaDelta không yêu cầu cài đặt thủ công và thí nghiệm cho thấy hội tụ nhanh hơn các phương pháp momentum.
3.Kết
Phần lý thuyết tạm thời kết thúc ở đây. Bài viết còn nhiều thiếu sót, mong nhận được góp ý quá gmail: ngthanhhuyen1707@gmail.com.
Trong bài viết tiếp theo, mình sẽ hướng dẫn cách implement code từ đầu với PyTorch. Cảm ơn các bạn đã theo dõi.
4. Reference
All rights reserved
