
Deformable DETR: Phương pháp tiếp cận end-to-end cho bài toán object detection
This post hasn't been updated for 4 years
Bài viết hôm nay là về một bài toán cực lỳ phổ biến mà ai làm việc trong ngành này cũng từng không ít lần thử sức, đó là bài toán object detection. Trên Papers with code, bài toán này ghi nhận 2080 papers, 191 dataset, 61 benchmarks cả thẩy, và số lượng thực tế đương nhiên còn nhiều hơn thế. Ngay bây giờ, kể cả khi rất nhiều SOTA đã được trình bày, các vấn đề xoay quanh bài toán này vẫn đang tiếp tục được mổ xẻ.
Recommend một số bài viết chất lượng về object detection:
- Tác giả Nguyễn Minh Tâm - A discussion of SSD Intuition (from một người chị cực kỳ xuất sắc và đầy cảm hứng)
- Tác giả Phan Huy Hoàng - Thuật toán Faster-RCNN với bài toán phát hiện đường lưỡi bò
- Tác giả Nguyễn Tùng Thanh - Series bài viết về YOLO
Các phần trong bài viết này bao gồm:
(Phần 1)
- Các vấn đề tồn đọng trong bài toán Object detection
- DETR hướng đến giải quyết những vấn đề gì?
- Hạn chế của DETR
(Phần 2)
- Deformable DETR giải quyết nó như thế nào?
- Những vấn đề còn tồn đọng
Trong khuôn khổ bài viết, mình sẽ vừa viết vừa ôn tập. Bởi vì mình cũng chỉ mới tiếp cận thời gian khá ngắn gần đây nên sau bài viết này rất mong nhận được nhiều góp ý từ mọi người. Nếu quá dài, mọi người có thể lướt tới phần mọi người muốn.
1. Các vấn đề tồn đọng trong bài toán Object detection
Các thuật ngữ
-
Bounding box : hình chữ nhật bao quanh vật thể. Bounding box có thể được xác định bằng 4 giá trị coordinates, là (x top left, y top left, x bottom right, y bottom right) hoặc phổ biến hơn là (x center, y center, witdh, height). Bounding box là khung hình bao quanh vật thể trong khi Anchor box là những khung hình có kích thước xác định trước, có tác dụng dự đoán bounding box.
-
Vị trí tuyệt đối (absolute coordinates, directly position) và vị trí tương đối (relative position) : vấn đề này xuất phát từ việc weight sharing của các mạng convolutional, khi đó xảy ra trường hợp trong ảnh có hai vật hoàn toàn giống nhau nhưng ở vị trí khác nhau, nhưng vì input feature map của chúng giống nhau nên khi đi qua filter sẽ cho ra 4 coordinates giống nhau, trong khi sự thật chúng phải khác nhau. Vậy nên absolute coordinates chính là tọa độ vật so với ảnh gốc, trong khi relative position là tọa độ vật so với điểm neo.
-
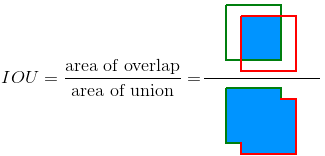
IOU: một chỉ số đánh giá rất thường được dùng trong object detection. IoU được tính bằng tỷ lệ phần diện tích hai box giao nhau trên tổng diện tích hai box. Như vậy, IoU càng cao càng tốt. Nhược điểm là IoU không mang thông tin về hướng.

Các phương pháp Object detection
Để mà nói về các phương pháp tiếp cận object detection từ xưa đến nay, có thể chia làm hai phương pháp chính:
-
Two-stage
Đây là hướng tiếp cận sớm nhất, với tiêu biểu là họ mô hình R-CNN, Fast R-CNN, Faster RCNN. Được gọi là two-stage vì phương pháp này bao gồm hai giai đoạn:
(1) đưa ảnh vào 1 sub-network gọi là RPN - Region Proposal Network để extract các vùng trên ảnh có khả năng chứa đối tượng dựa vào các anchor và
(2) từ các vùng trích xuất được dự đoán vật thể trong ảnh. Ưu điểm là độ chính xác cao, nhưng nhược điểm là rất tốn tài nguyên training và kể cả quá trình inferece cũng chậm.
Đọc chi tiết hơn tại bài viết dài 58 phút: Thuật toán Faster-RCNN với bài toán phát hiện đường lưỡi bò
-
One-stage
Chính là các mô hình đang phổ biến hiện nay như SSD, YOLO. Các mô hình này ko có phần trích chọn đặc trưng (RPN) như các mô hình phía trên, thay vào đó thực hiện song song quá trình tìm kiếm vị trí chứa vật thể cũng như dự đoán đây là vật thể gì.
Các phương pháp thuộc loại này có tốc độ real-time, nhanh hơn nhiều so với two-stage. Đặc biệt YOLO là thuật toán nhanh nhất trong lớp các phương pháp object detection. Tuy vậy cần đánh đổi lại độ chính xác một chút.
Các phương pháp SSD, YOLO sử dụng anchor box (anchor based). Về cơ bản, ý tưởng là chia ảnh thành các ô lưới (grid cell). Trọng tâm của một vật thuộc cell nào thì sẽ được dự đoán bởi các bounding box gắn liền với cell đấy. Kích thước các bounding box sẽ thay đổi dựa trên tỷ lệ sacle và ratio. Như vậy khi xác định một vật thể ta sẽ cần xác định 2 thành phần gắn liền với nó là (cell, anchor box) chứ không chỉ riêng mình cell hoặc chỉ mình anchor box. Mỗi cell phụ trách một vật. Có thể thấy ngay, nếu xảy ra trường hợp hai vật bị trùng middle point (hai vật đè lên nhau, ví dụ người đứng chắn giữ ô tô), thuật toán có thể khó xác định class.
Đồng thời, SSD, YOLOv3 dự báo trên nhiều feature map. Những feature map ban đầu có kích thước nhỏ giúp dự báo được các object kích thước lớn. Những feature map sau có kích thước lớn hơn trong khi anchor box được giữ cố định kích thước nên sẽ phần nào giúp dự báo các vật thể kích thước nhỏ. Dù vậy vẫn chưa thể đạt đến mức độ well.
Kết quả là ta có mạng YOLO siêu nhanh. SSD cũng tương tự, nhưng kết quả được tính toán trên nhiều feature map khác nhau nên có khả năng adapt object với kích thước đa dạng hơn.
Hạn chế của các phương pháp hiện tại
Vậy về cơ bản, nhìn chung các hạn chể của các phương pháp trên có thể kể đến:
-
Hạn chế khi detect vật nhỏ. Thường vấn đề này xuất phát từ một số nguyên nhân như bộ train không có label small object, độ phân giải ảnh train ảnh test khác nhau làm small object không còn small nữa, hoặc khi các vật nhỏ bị chep lấp một phần bởi các vật lớn hơn. Một case nữa là khi chúng ta lấy xuống các layẻ quá sâu, nơi feaaure map sẽ bóc tách các biểu diễn cực chi tiết như các phần mái ngói, ống khói của một ngôi nhà (vật thể lớn) mà bỏ quên mất các vật thể nhỏ như tảng đá cạnh ngôi nhà, thứ đáng ra phải được phát hiện từ nhiều layer trước nhưng thông tin của chúng không còn nhiều ý nghĩa khi xuống các layer sau.
-
Khó khăn trong implement và huấn luyện. Đơn cử như YOLO sử dụng một backbone Darknet được viết trên nền C và CUDA mới có thể đạt được hiệu suất tốt, như vậy chúng ta đang bị phụ thuộc vào bên thứ ba. Hay việc huấn luyện YOLO cũng yêu cầu lượng memory khá lớn (do việc lưu trữ kết quả tăng dần theo số lượng bounding box dựa trên sự thay đổi scale và ratio), đồng thời như vậy cũng không thể thiết lập batch size quá lớn (thường thì package darknet của YOLO đã chia nhỏ một batch thành các subdivisions cho vừa với RAM). Kể cả như vậy cũng không nên nghĩ giảm số lượng bouding box xuống là được, vì giảm nó đồng nghĩ việc giảm khả năng tìm kiếm, kéo theo accuracy giảm theo.
-
Imbalance data khi số lượng empty object lớn hơn rất nhiều so với non-empty object (object có chứa vật thể). Để giải quyết vấn đề này, có một số phương pháp phổ biến như Hard negative mining hay Focal Loss, phạt thật nặng với những class predict sai. Focal Loss rất thường xuyên được sử dụng trong object detection và hiện tại nó vẫn tỏ ra rất hiệu quả, bạn có thể đọc thêm về nó tại đây:
-
Vấn đề khi nhiều box cùng predict một vật và overlap lẫn nhau. Để giải quyết vấn đề này, ta phải dùng đến thuật toán NMS để giữ lại box đúng nhất. Thuật toán NMS trải quả 2 steps: (1) giảm bớt số lượng các bounding box bằng cách lọc bỏ toàn bộ những bounding box có xác suất chứa vật thể nhỏ hơn một ngưỡng threshold do chúng ta đặt ra, và (2) Đối với các bouding box giao nhau, lựa chọn ra một bounding box có xác xuất chứa vật thể là lớn nhất. Sau đó tính toán chỉ số giao thoa IoU với các bounding box còn lại. Nếu chỉ số này lớn hơn ngưỡng threshold thì điều đó chứng tỏ 2 bounding boxes đang overlap nhau rất cao. Ta sẽ xóa các bounding có có xác xuất thấp hơn và giữ lại bouding box có xác xuất cao nhất. Cuối cùng, ta thu được một bounding box duy nhất cho một vật thể.
(Ảnh) Predict sau khi qua xử lý.

(source) Toward DataScience - Non-maximum Suppression
**Nhưng NMS có gì không tốt?
Có thể thấy ngay, đó là việc đây là một hand-craft stage, khi các threshold sẽ do ta cài đặt và quy định, và thres hold đó sẽ được áp dụng với mọi vật thể bất kể kích thước, mật độ object trong ảnh, độ phân giải. Chỉ số threshold này không thu được qua quá trình training mà là do ta xem xét output của tập test để lựa chọn. Như vậy, nó bị phụ thuộc vào dữ liệu và không mang tính tổng quan. Điều này là không tốt.
- Bàn luận thêm về vai trò của NMS bạn có thể ghé thăm bài viết này của một đàn anh team mk: Sau khi bỏ được anchor, trong tương lai object detection sẽ bỏ được hoàn toàn NMS?
Vậy trong những hạn chế trên, DETR hướng tới giải quyết vấn đề nào?
- Loại bỏ anchor (anchor-free)
- Implement dễ dàng hơn
- Loại bỏ bước postpocessing như NMS.
Đề xuất giải quyết
- Bipartite matching với Hungarian Algorithm
- Sử dụng Transformer
Paper gốc:
Official code github:
2. Phương pháp tiếp cận DETR
DETR là viết tắt của Detection Transformer.
Hãy cùng nhìn lại những mục tiêc mà DETR hướng đến và xem nó giải quyết thế nào.
Mục tiêu thứ nhất: loại bỏ anchor
Có thể nói anchor-based đã gắn liền với các phương pháp OD một quãng thời gian rất dài. Loại bỏ anchor chính là quay trở lại với bài toán nguyên thủy, predict trực tiếp dựa ngay trên nhãn ban đầu. Lúc này, các bounding box sẽ chạy loạn trên toàn bộ ảnh.
Vậy vấn đề khi đó là gì?
Thứ nhất, khi chạy loạn như vậy, làm sao cái box nào biết nó cần so sánh với grounth truth nào. Làm sao để nó biết nên đi về hướng nào thì tốt, khi mà phải song song kèm theo predict class.
DETR đã cố gắng chuyển hướng nó sang bài toán direct set prediction problem. Trong bài toán này, tạo ra objects ứng với class và vị trí . Trong N có một phần là các object có trong ảnh, và phần còn lại được đánh nhãn empyt object. N thường lớn hơn số lượng object có trong ảnh, như code implement của DETR là N = 100, một số paper sử dụng N = 300. Có thể thấy, con số này là nhỏ hơn rất nhiều so với số lượng bounding box của một mạng YOLO.
Vậy, mục tiêu của DETR là xây một cái backbone để output ra tầm 100 outputs cuối, mỗi output sẽ là bounding box cùng với class tương ứng. Sau đó, ghép cặp 100 output này và so sánh với 100 objects được gen từ nhãn thật.
Vậy so sánh ở đây, hay nói chính xác là tính loss giữa predict và grounth truth như thế nào. Paper sử dụng Hungarian Algorithm.
Hungarian Algorithm
Hungarian Algorithm là một thuật toán đối sánh được sử dụng để tìm trọng số lớn nhất trong đồ thị hai bên (bipartite graphs).
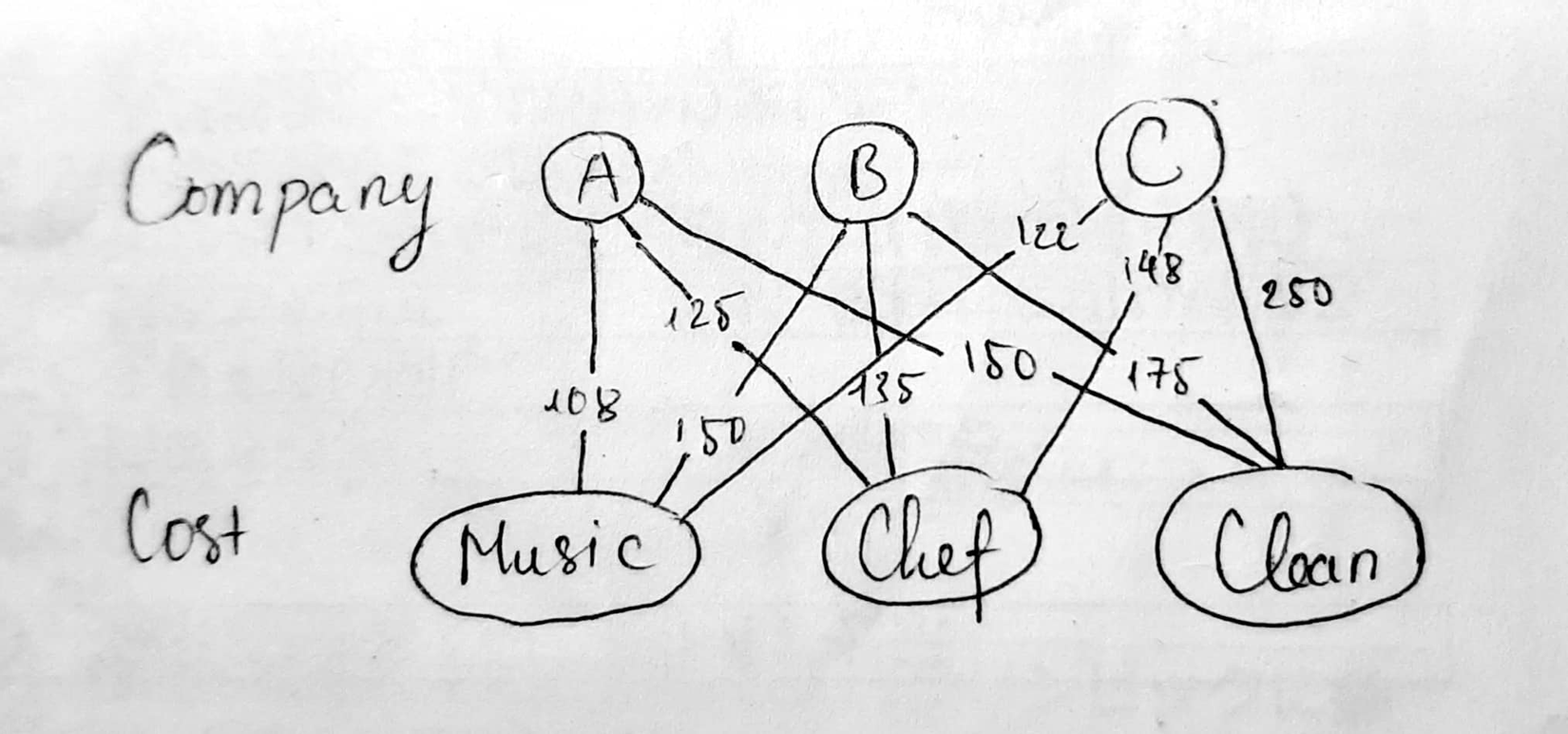
Hãy cùng xét một bài toán đơn giản như thế này. Một ngày nọ, bạn cần tổ chức một buổi tiệc. Có 3 việc bạn cần làm, thuê đầu bếp, thuê nhạc công, và thuê người dọn dẹp sau bữa tiệc nữa. Bạn tìm tới các công ty cung cấp 3 dịch vụ này, nhưng ngặt nỗi các công ty lại đưa ra mức giá cho mỗi dịch vụ khác nhau như sau:

Với mục tiêu tối ưu hóa chi phí xuống mức thấp nhất có thể, chúng ta sẽ phải chọn 1 dịch vụ ở mỗi 1 công ty và không được trùng lại. Vậy chọn như nào? Theo thuật toán, ta có thể xây dựng một đồ thị hai bên.
Chi tiết về các bước của thuật toán, bạn có thể tìm thấy tại đây:
Sau khi áp dụng thuật toán, ta có được kết quả:
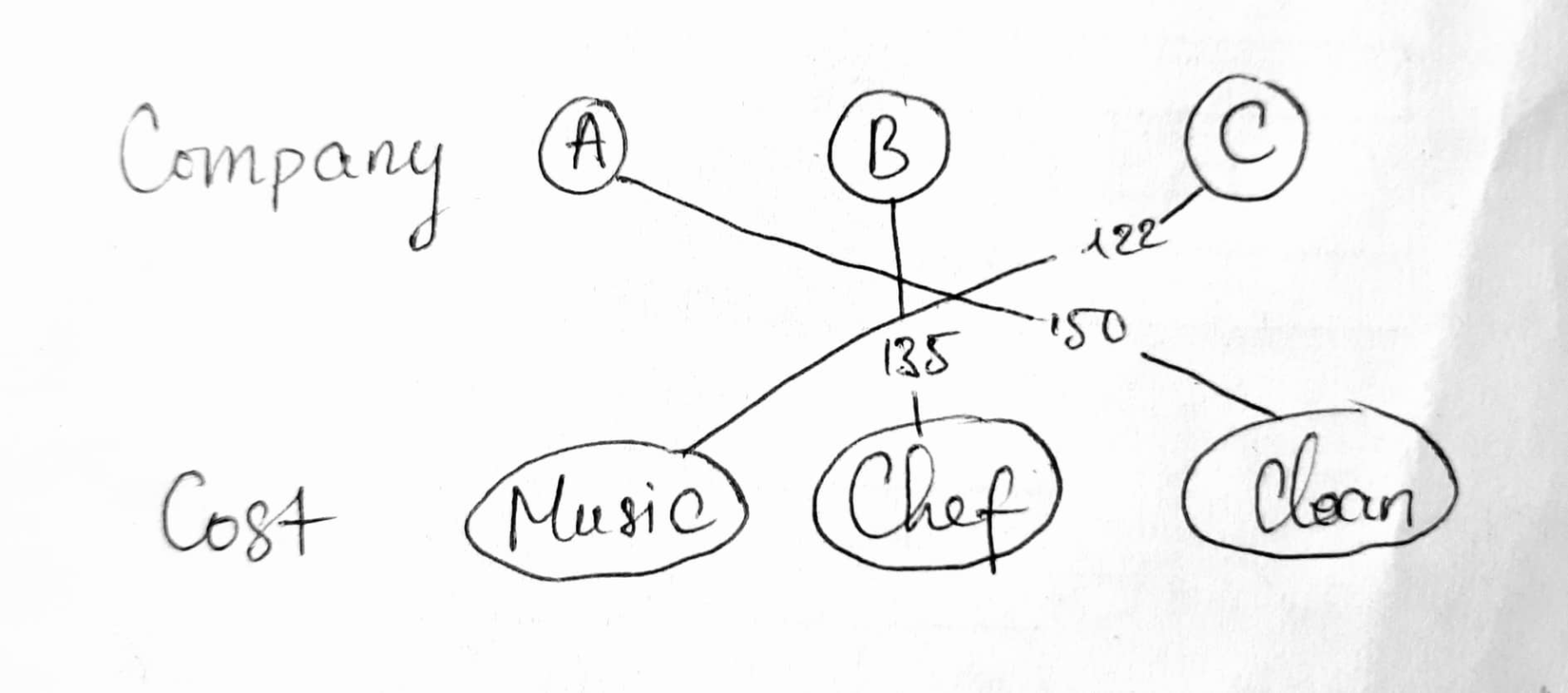
Chúng ta có thể check lại kết quả:
- 108 + 135 + 250 = 493
- 108 + 148 + 175 = 431
- 150 + 125 + 250 = 525
- 150 + 148 + 150 = 448
- 122 + 125 + 175 = 422
- 122 + 135 + 150 = 407
Như vậy, 407 chính là đáp án cuối cùng, chi phí nhỏ nhất (loss) mà chúng ta cần tìm, phù hợp với đáp án tìm ra bởi thuật toán Hungarian Algorithm.
Implement Hungarian Algorithm bằng Pytorch và Numpy:
Ta có thể thấy sự tương quan ở đây. Đồ thị hai bên ứng với predict và ground truth, trong đó ta cần ghép cặp one-to-one sao cho chi phí là thấp nhất, tức tối ưu hàm loss. Trọng số cạnh giữa các đỉnh đồ thị cũng chính là score giữa predict và ground truth. Trong DETR, score này được định nghĩa như sau.
Note: bài toán object detection gần đây đang chuyển dịch dần từ one-to-many sang one-to-one.
Hàm Loss
Loss của DETR sử dụng cả classification loss và localization loss.
Trong đó là xác suất mà predict này chứa class c, trong đó c chính là nhãn của vật thể của ground truth mà predict này đang ghép cặp cùng. Có thể thấy, thay vì lưu một vecto xác suất của tất cả các class như YOLO, output của DETR chỉ lưu xác suất của class mà nó ghép cặp cùng. DO số lượng Ø thường lớn 🡪 paper đặt thêm trọng số empty_weitght 1/10 khi box nhãn thuộc lớp này để tránh mất cân bằng.
Đồng thời, localization loss được tính bằng là L1 loss và GIoU Loss.
GIoU
GIoU là một phiên bản cải thiện của IoU. Việc sử dụng GIoU xuất phát từ việc giờ đây predict box sẽ ko gắn liền một anchor nào nữa. Việc ở những bước khởi tạo đầu tiên các box không hề giao nhau là chuyện hoàn toàn có thể xảy ra. Lúc này, IoU không thể hiện được box nào tốt hơn. (tỷ lệ overlap luôn bằng 0). Bạn có thể nhìn rõ qua ví dụ sau.
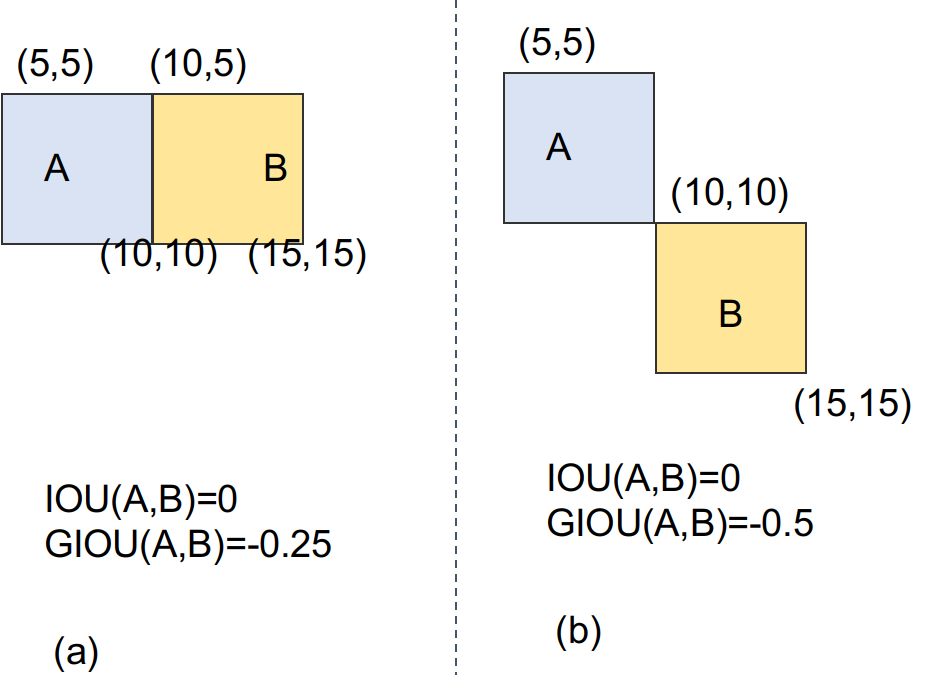
Như vậy, GIoU được tính bằng cách bổ sung tham số mới là diện tích của hình chữ nhật nhỏ nhất (C) bao phủ cả A và B.
Đồng thời có thể thấy nếu A và B ở một số vị trí đặc biệt hàm lỗi có xu hướng tối thiểu hóa diện tích của C trước khi hội tụ. Do đó người ta tiếp tục đề xuất thêm độ đo mới gọi là DIoU (distance intersection over union). Đúng như tên gọi, DIoU không sử dụng diện tích mà sử dụng khoảng cách Euclid giữa hai tâm của A và B chuẩn hóa với đường chéo của C. Do đó hàm mất mát DIoU hội tụ nhanh hơn so với GIoU.
Đồng thời có thêm một phiên bản cải tiến nữa là CIoU được tính bằng công thức:
trong đó là tham số cân bằng tỉ lệ giữa A và B, giúp đo lường tính nhất quán tỉ lệ giữa chiều rộng và chiều cao giữa hai bounding box. Dù mang nhiều ý nghĩa nhưng công thức tính CIoU khá phức tạp, bạn đọc có thể cân nhắc thử nghiệm nếu muốn.
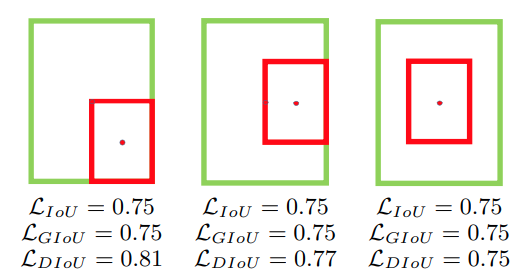
Trong khuôn khổ paper, DETR chỉ sử dụng GIoU.
Vậy, cuối cùng chúng ta được hàm loss là:
Trong đó, là hyper parameter, tùy thuộc vào việc bạn ưu tiên phần nào hơn.
Mục tiêu thứ hai: loại bỏ NMS
DETR đã loại bỏ NMS như thế nào. Làm sao để trán trường hợp duplicated predict. Đầu tiên, việc xảy ra các box trùng nhau đó là vì nhiều head cùng tranh nhau detect một vật. Vậy làm sao để chúng ko tranh nhau nữa 🡪 chúng có thông tin của nhau và lần này, mỗi predict sẽ chịu trách nhiệm về một vật khác nhau. 🡪 Chúng có thông tin của nhau, nghe có vẻ quen quen, như thể đang pay attention lẫn nhau. Chính xác, DETR đã đưa cơ chể attention vào trong mô hình của mình. Nó đã đưa như thế nào. Trước đó, hãy nhìn vào kiến trúc end-to-end của mô hình này.
Note, đến đoạn này, mong bạn đọc có hiểu biết cơ bản về vai trò của Key, Query và Value trong mạng Transformer. Nếu không, bạn có thể tìm kiếm nhanh trên mạng. Thời điểm hiện tại có rất nhiều blog chất lượng viết về nó. (Recommend: Tìm hiểu mô hình Transformer - Quái Vật Nhiều Đầu. hoặc Transformers - "Người máy biến hình" biến đổi thế giới NLP)
Kiến trúc tổng quan
 Có thể thấy, DETR dùng một mạng backbone (the official code là ResNet) để trích xuất ra các feature map. Sau đó, feature map được flatten, (1 x 512) tiếp tục được đưa vào mạng encoder, và output sẽ ra được vecto, với N đã chọn ở phần trên. Sau đó output của encoder cùng với spatial positional embeddings được đưa vào multihead encoder-decoder attention ở mỗi layer của decoder. (chú ý là mỗi layer, sau này Deformabel DETR sẽ chỉ rõ phần này). Và cuối cùng ra đc predict output để so sánh ghép cặp (bipartite matching) với nhãn như đã giới thiệu ở phần trên.
Có thể thấy, DETR dùng một mạng backbone (the official code là ResNet) để trích xuất ra các feature map. Sau đó, feature map được flatten, (1 x 512) tiếp tục được đưa vào mạng encoder, và output sẽ ra được vecto, với N đã chọn ở phần trên. Sau đó output của encoder cùng với spatial positional embeddings được đưa vào multihead encoder-decoder attention ở mỗi layer của decoder. (chú ý là mỗi layer, sau này Deformabel DETR sẽ chỉ rõ phần này). Và cuối cùng ra đc predict output để so sánh ghép cặp (bipartite matching) với nhãn như đã giới thiệu ở phần trên.
Note: Có chút thay đổi là positional embedding của Transformer, ở đây sẽ là spatial positional embedding (bởi vì cần embedding 2 chiều nên sẽ có riêng posional embeddings cho row và column position ở mỗi vị trí trên feature maps), đồng thời chúng được add vào mỗi layer của encoder chứ không chỉ của layer thứ 1 như Transformer nguyên bản.
Object queries
DETR giới thiệu một khái niệm là Object queries.
Mình đã gặp rất nhiều khó khăn tại phần này khi ko hiểu rốt cuộc object queries là cái gì và lấy từ đâu ra. Đồng thời, object queries có bị phụ thuộc vào tập dữ liệu không.
-
Theo mình hiểu, ban đầu, object queries là random. Nó cứ thế pay attention lung tung. Trong mạng transfomer ở đây, object queries đóng vai trò Query, đúng như tên gọi của nó, trong khi đó, các vecto lấy ra từ featuremap đóng vai trò Key. (đọc đến paper này mới biết Key và Query có thể không lấy cùng từ một chỗ =))))) Trong quá trình huấn luyện. mục tiêu từ object queries predict ra N vecto có chiều (thực ra phải đi qua một lớp feed forward network nữa mới ra đến đây, but nevermind). Trong quá trình huấn luyện, 1 cái object query sẽ đưa cái quey của nó ra, tìm cái Key nào match nhất với nó hay chính xác là tìm phần nào trên ảnh match nhất với nó.
-
Ở đây có hai khái niệm là self-attention và cross-attention. Thì self attention chính là quá trình các object query tìm kiếm cái Key match nhất với nó trong số feature map được mạng backbone lấy ra. Còn cross-attetion là quá trình các object query trao đổi thông tin cho nhau. Mục tiêu của việc trao đổi này là: không nhất thiết object queries nào cũng phải tìm cho nó một vùng để attention, thay vào đó, nó chủ trương khi một object queries đã tìm được phần key của nó, các object queries còn lại sẽ né phần đó ra và tìm kiếm những phần khác.
-
Dễ thấy, có những object queries sẽ không tìm được phần tương ứng cho nó và output ra rỗng (background). Đừng lo lắng, vì Hungarian Algorithm ở phần sau sẽ giải quyết giúp nó.
Vậy, về cơ bản, đó là cách DETR hoạt động.
Thêm
-
Auxiliary decoding losses
Đây là một trích nhỏ mà khi implement code được thêm vào, được đề cử giúp mô hình output ra được đúng số lượng vật thể của mỗi lớp. Phương pháp là thêm các FFN dự đoán và Hungary Loss sau mỗi layer của Decoder. Tất cả các FFN dự đoán đều chia sẻ thông số của chúng. Layer-norm cũng được sử dụng để chuẩn hóa đầu vào cho các FFN dự đoán từ các layer encoder khác nhau.
-
Về việc loại bỏ NMS, gần đây cũng nhiều nghiên cứu tiến đến giải quyết vấn đề này. Bàn về vấn đề này mình xin phép recommend một bài viết của đàn anh trong team: Sau khi bỏ được anchor, trong tương lai object detection sẽ bỏ được hoàn toàn NMS?
Kết quả của DETR
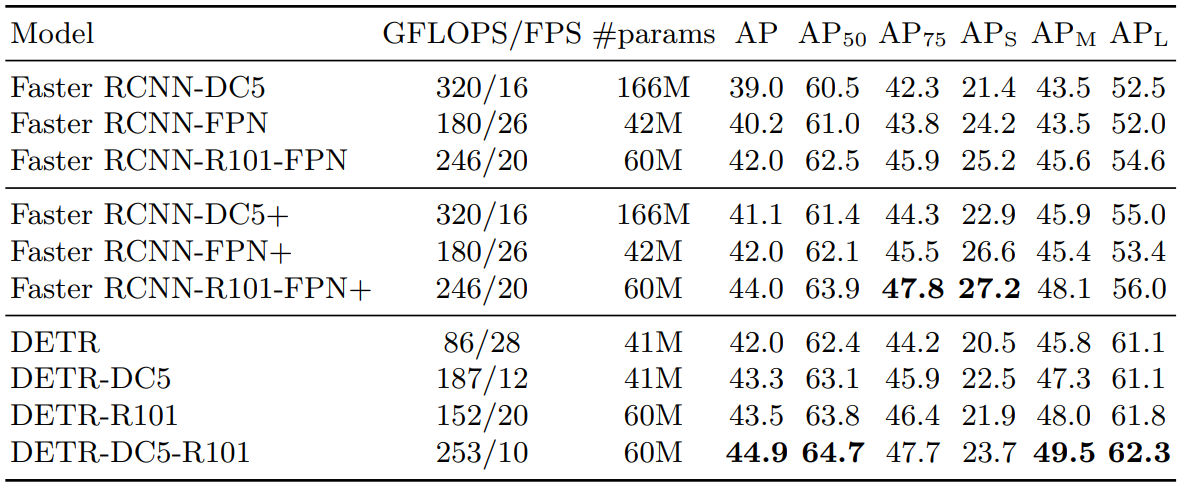
Note: DC5 chỉ backbone Resnet50 cùng với Dilate convolution ở layer C5 , R101 chỉ backbone Resnet101
Một số điểm có thể thấy ra:
- Kết quả của DETR có thể sánh được với FasterRCNN, một phương pháp có độ chính xác tương đối cao như đã giới thiệu ở phần đầu, với một số lượng pấm ít hơn hẳn, và đương nhiên, tố độ inference cũng bé hơn rất nhiều.
- Một ý nghĩa thoáng qua là việc bộ encoder và backbone đang làm cũng là tìm những đặc trưng biểu diễn của ảnh, nếu bỏ encoder đi thì sao. Theo paper, bỏ bộ encoder làm AP giảm 3.9, paper chỉ ra rằng encoder giúp phân tách vật thể rõ hơn.
- Bỏ đi lớp FFN bên trong Transformer: Số tham số giảm từ 41.3M xuống 28.7M, AP giảm tương ứng 2.3.
- Nhìn vào bảng trên, có thể thấy ngay: hay chính là độ chính xác trên detect vật thể nhỏ, thấp hơn nhiều so với các vật thể khác. Đúng vậy, Hạn chế khi detect vật nhỏ chính là một trong những hạn chế điển hình của DETR mà các paper tiếp nối cố khắc phục. Điển hình là Deformabel DETR mình sẽ giới thiệu ở phần sau. Một số lý do có thể giải thích cho việc này như (1) ranh giới giữa vật thể nhỏ và nhiễu tương đối mỏng, (2) dữ liệu huấn luyện không tập trung vào vật thể nhỏ, (3) vật nhỏ nằm trong vùng ảnh hưởng của vật lớn, (4) cơ chế tránh predict trung lặp dẫn đến bỏ sót, vân vân
- Theo đó, để cải thiện detect vật nhỏ, paper tìm cách tăng resolution lên để coi như nó là vật lớn. Phương pháp là tăng độ phân giải của feature bằng cách thêm dilation vào stage cuối của backbone và loại bỏ một stride khỏi convolution layer. Kết quả: tăng phân giải lên hệ số hai, hiệu suất cho các đối tượng nhỏ tăng nhẹ, với chi phí cao hơn 16 lần trong quá trình self-attetion của decoder, dẫn đến tổng chi phí tính toán tăng gấp 2 lần. Như vậy, trong khuôn khổ paper, vấn đề này chưa được giải quyết,
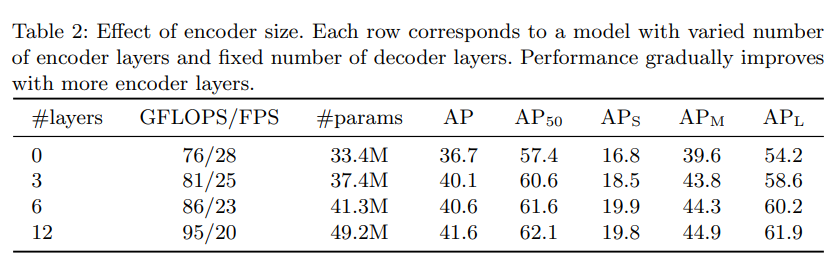
- Trên thực tế, qua thực nghiệm, DETR vẫn chưa hoàn toàn hết phụ thuộc vào NMS. Bảng trên cho thấy càng tăng số layer decoder thì sự phụ thuộc càng giảm đi, nhưng đi kèm chi phí tính toán tăng lên. Đây là một trade-offf.
Kết quả attention trên một số feature map khác nhau.

Paper cung cấp rất nhiều giả định khác nhau trong quá trình thử nghiệm, nếu có thời gian, bạn đọc nên đọc kỹ chi tiết để xem ảnh hưởng của từng thành phần lên toàn bộ mô hình, kể cả thêm bớt một số module và điều chỉnh từng hype-parameter.
Như vậy, DETR là khởi đầu cho lớp mô hình End-to-end object detection, mở ra nhiều nghiên cứu sau này cho bài toán. Kết quả thu được chứng minh rằng anchor box và NMS có thể được lược bỏ mà không làm giảm quá nhiều sự hiệu quả cho mô hình, mang lại nhiều tín hiệu khả quan.
4. Deformable DETR đã giải quyết những gì?
Thừa kế ý tưởng của DETR, Deformable DETR tập trung cải thiện hai điểm hạn chế lớn nhất.
-
Giải quyết rõ ràng vấn đề detect vật thể nhỏ.
-
Quá trình hội tụ quá chậm. Đúng là Transormer mất nhiều thời gian để trainign, nhưng thực nghiệm của DETR đã tiêu tốn 5000 giờ mới hội tụ (bạn không đọc nhầm đâu, chỉ có facebook AI research mới có tài nguyên như này =))). Đồng thời, DETR đang sử dụng module Transformer nguyên bản, ta hoàn toàn có thể cải tiến nó.
Do thời lượng bài viết đã hơi quá dài, mình xin phép tách sang Phần 2 để có thể đào sâu chi tiết hơn về cách Deformable DETR giải quyết những vấn đề trên.
Nếu bài viết hữu ịch, có thể để lại một Upvote giúp mình có thêm động lực, Mình sẽ cố gắng public phần hai càng sớm càng tốt trong tháng này.
All Rights Reserved
