Machine Learning thật thú vị (4): Tự động tag tên bạn bè với HOG & CNN
Bài đăng này đã không được cập nhật trong 4 năm
Chắc hẳn các bạn đều biết đến tính năng cho phép nhận diện bạn bè thông qua ảnh trên Facebook? Vào thời gian ban đầu, nếu muốn, bạn phải tự tag tên bạn bè của mình vào. Bây giờ, ngay khi bạn tải một bức ảnh lên, Facebook tag tất cả mọi người vào ảnh như một phép thần thông vậy:
 Công nghệ nhận diện mới này có thể nhận diện mọi người ngay sau vài tấm ảnh họ được tag. Điều đáng ngạc nhiên là công nghệ này có độ chính xác đến 98%, gần tương đương với một con người.
Công nghệ nhận diện mới này có thể nhận diện mọi người ngay sau vài tấm ảnh họ được tag. Điều đáng ngạc nhiên là công nghệ này có độ chính xác đến 98%, gần tương đương với một con người.
Bạn tò mò về cách công nghệ này được phát triển? Hãy cùng nhau xây dựng chương trình tương tự thôi nào! Nhưng nhận diện bạn bè thì khá dễ, chúng ta sẽ đương đầu với thử thách khó hơn - phân biệt Will Ferrell (diễn viên nổi tiếng) với Chad Smith (ca sĩ nhạc rock nổi tiếng)

2 nhân vật này đã cùng tham gia chương trình truyền hình và đóng giả làm người đối diện.
Cách học máy giải quyết vấn đề phức tạp
Ở các phần 1, 2 và 3, chúng ta đã sử dụng học máy để giải quyết các vấn đề: dự đoán giá nhà đất, tự động tạo nội dung hay tìm chim trong ảnh. Tất cả các vấn đề này có thể được giải quyết bởi một thuật toán học máy, chỉ cần truyền dữ liệu vào là có kết quả.
Nhưng nhận diện mặt tồn tại một loạt các vấn đề:
- Nhìn vào bức ảnh và tìm tất cả khuôn mặt trong đó
- Tập trung vào mỗi khuôn mặt và hiểu rằng: nếu một khuôn mặt quay đi các hướng khác nhau hay trong ánh sáng kém, đó vẫn là cùng một người
- Tìm ra đặc trưng duy nhất của khuôn mặt để phân biệt mọi người với nhau - mắt to, mặt dài...
- So sánh tất cả đặc trưng của khuôn mặt với tất cả những người bạn biết để tìm tên người đó.
Con người làm tất cả những điều này gần như tức thời, và thậm chí có thể nhận ra khuôn mặt ở bất cứ vật thể nào:

Máy tính không có khả năng tổng quát hóa vật thể như vậy (hoặc ít nhất chưa). Ta cần dạy chúng làm từng bước trong chuỗi quá trình, với kết quả bước này là đầu vào bước tiếp theo. Nói một cách, ta kết nối một vài thuật toán với nhau.

Nhận diện khuôn mặt - tuần tự
Ở mỗi bước, chúng ta sẽ học về những thuật toán khác nhau. Tôi sẽ không giải thích từng thuật toán cụ thể để tránh bài viết dài lê thê, nhưng bạn sẽ hiểu được ý tưởng chính và có thể xây dựng hệ thống nhận diện mặt thông qua Python, sử dụng OpenFace và dlib.
Bước 1: Tìm tất cả khuôn mặt
Ở bước đầu tiên trong chuỗi thuật toán là xác định mặt. Rõ ràng, chúng ta cần xác định vị trí khuôn mặt trước khi nhận diện chúng.
Nếu bạn có bất cứ camera trong 10 năm gần đây, bạn chắc hẳn đã nhìn thấy tính năng này:
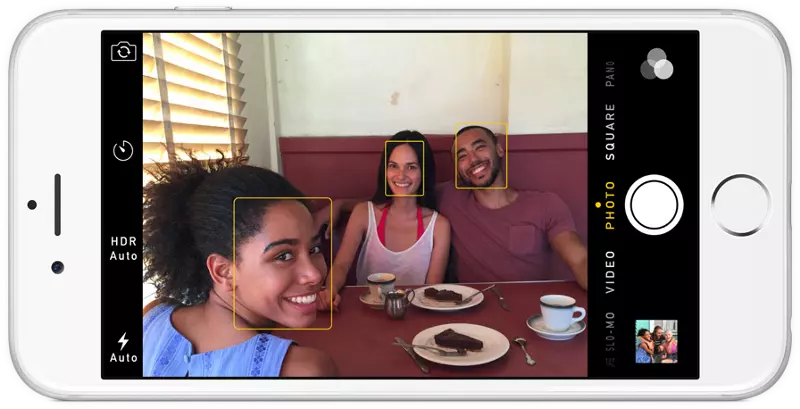 Xác định mặt là tính năng tuyệt vời cho camera. Khi camera có thể chỉ ra khuôn mặt, nó có thể lấy chính xác điểm cần tập trung. Nhưng chúng ta sử dụng tính năng này với mục đích khác - tìm tất cả vùng ảnh mà chúng ta muốn truyền đến bước tiếp theo trong chuỗi thật toán.
Xác định mặt là tính năng tuyệt vời cho camera. Khi camera có thể chỉ ra khuôn mặt, nó có thể lấy chính xác điểm cần tập trung. Nhưng chúng ta sử dụng tính năng này với mục đích khác - tìm tất cả vùng ảnh mà chúng ta muốn truyền đến bước tiếp theo trong chuỗi thật toán.
Chúng ta sẽ sử dụng phương pháp được sáng tạo năm 2005 có tên gọi là Histogram of Oriented Gradients (HOG - tạm dịch là biểu đồ của hướng dốc). Để tìm khuôn mặt, ta bắt đầu bằng chuyển ảnh sang đen trắng, bởi chúng ta không cần màu ảnh trong nhận diện khuôn mặt.
 Sau đó, chúng ta nhìn vào từng pixel trong bức ảnh. Cho mỗi điểm ảnh, chúng ta nhìn vào những pixel xung quanh nó:
Sau đó, chúng ta nhìn vào từng pixel trong bức ảnh. Cho mỗi điểm ảnh, chúng ta nhìn vào những pixel xung quanh nó:
 Mục đích là tìm ra sự thay đổi ánh sắng giữa điểm ảnh và những điểm ảnh xung quanh, và tìm ra hướng mà bức ảnh tối dần:
Mục đích là tìm ra sự thay đổi ánh sắng giữa điểm ảnh và những điểm ảnh xung quanh, và tìm ra hướng mà bức ảnh tối dần:
 Nếu bạn lặp lại quá trình đó cho từng điểm ảnh, thì mỗi điểm ảnh sẽ được thay thế bằng mội mũi tên. Những mũi tên này được gọi là gradients (độ dốc) và chúng chỉ hướng dòng ánh sáng từ sáng sang tối trên toàn bộ bức ảnh.
Nếu bạn lặp lại quá trình đó cho từng điểm ảnh, thì mỗi điểm ảnh sẽ được thay thế bằng mội mũi tên. Những mũi tên này được gọi là gradients (độ dốc) và chúng chỉ hướng dòng ánh sáng từ sáng sang tối trên toàn bộ bức ảnh.
 Điều này tưởng như vô nghĩa, nhưng có một lý do chính đáng để thay giá trị pixel bằng gradients. Nếu chúng ta phân tích pixels trực tiếp, từ những ảnh cực tối hoặc cực sáng của cùng một người, ta sẽ có những giá trị khác nhau. Bằng việc chỉ cân nhắc đến sự thay đổi hướng của ánh sáng, dù sáng hay tối thì đều có chung một đại diện. Điều đó khiến vấn đề dễ giải quyết hơn rất nhiều.
Điều này tưởng như vô nghĩa, nhưng có một lý do chính đáng để thay giá trị pixel bằng gradients. Nếu chúng ta phân tích pixels trực tiếp, từ những ảnh cực tối hoặc cực sáng của cùng một người, ta sẽ có những giá trị khác nhau. Bằng việc chỉ cân nhắc đến sự thay đổi hướng của ánh sáng, dù sáng hay tối thì đều có chung một đại diện. Điều đó khiến vấn đề dễ giải quyết hơn rất nhiều.
Nhưng lưu trữ gradients cho mỗi điểm ảnh cho chúng ta quá nhiều thông tin, và khó tổng quá hóa bài toán. Sẽ tốt hơn nếu chúng ta có thể nhìn dòng chảy ánh sáng ở mức độ cao hơn, giúp nhận ra cấu trúc đơn giản dễ dàng hơn.
Để giải quyết vấn đề này, chúng ta tách bức ảnh thành chuỗi vùng nhỏ 16x16 pixels. Ở mỗi ô vuông, ta đếm các sự thay đổi hướng của ánh sáng, và tìm ra hướng thay đổi ánh sáng chủ đạo đại diện cho cả nhóm.
Kết quả cuối cùng, ta chuyển ảnh nguyên gốc sáng sang tập hợp hướng sáng đại diện, thể hiện cấu trúc đơn giản của khuôn mặt.

Để tìm ra khuôn mặt trong hình ảnh HOG, chúng ta cần tìm phần ảnh có cấu trúc giống nhất với cấu trúc HOG được trích lọc từ trong quá trình đào tạo.
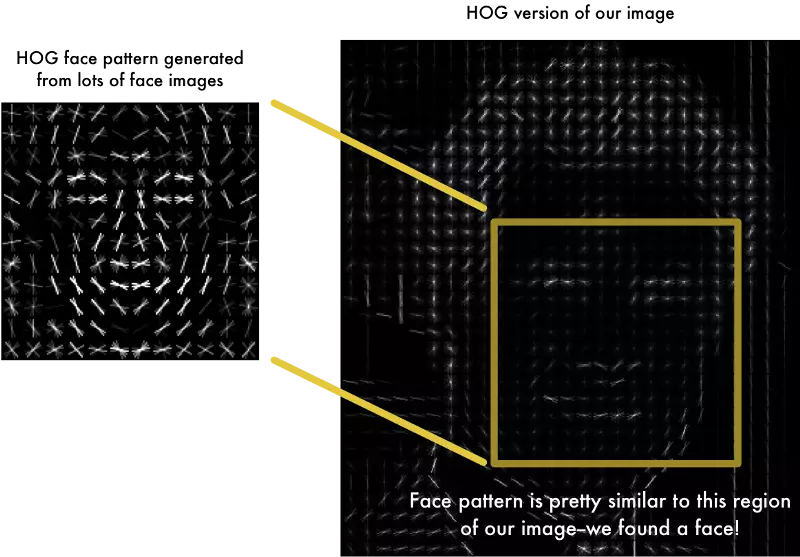
Sử dụng kỹ thuật này, chúng ta có thể dễ dàng tìm khuôn mặt ở bất cứ ảnh nào:
 Nếu bạn muốn thử bước này sử dụng Python và thư viện dlib, đây là dòng mã biểu diễn cách thức tạo và nhận dạng đại diện ảnh theo HOG
Nếu bạn muốn thử bước này sử dụng Python và thư viện dlib, đây là dòng mã biểu diễn cách thức tạo và nhận dạng đại diện ảnh theo HOG
Bước 2: Chỉnh hướng khuôn mặt
Phù, chúng ta cuối cùng cũng tách được mặt ra rồi. Nhưng giờ chúng ta phải đối mặt với vấn đề khác: khuôn mặt với góc chụp khác nhau là hoàn toàn khác nhau với máy tính.
 Để giải quyết vấn đề này, chúng ta cố gắng biến đổi bức ảnh sao cho mắt và môi luôn luôn ở cùng một vị trí đối với ảnh. Điều này cũng khiến việc so sánh khuôn mặt ở bước kế tiếp dễ hơn.
Để giải quyết vấn đề này, chúng ta cố gắng biến đổi bức ảnh sao cho mắt và môi luôn luôn ở cùng một vị trí đối với ảnh. Điều này cũng khiến việc so sánh khuôn mặt ở bước kế tiếp dễ hơn.
Chúng ta thực hiện điều đó với thuật toán face landmark estimation (ước lượng cột mốc trên mặt), được tạo ra bởi Vahid Kazemi và Josephine vào năm 2014.
Ý tưởng đơn giản là chúng ta xác định 68 điểm (gọi là cột mốc - như trong châm cứu) tồn tại trên mỗi khuôn mặt, điều này sẽ được thực hiện bằng cách huấn luyện một thuật toán học máy.

Đây là kết quả sau khi xác định 68 điểm mốc trên bức ảnh:

Bây giờ, mắt và môi đã được xác định. Chúng ta cố gắng quay, phóng to, thu nhỏ hay cắt ảnh để mắt và môi nằm chính giữa nhất có thể. Chúng ta không cần biến đổi 3D bởi có thể khiến ảnh bị méo. Chúng ta chỉ sử dụng biến đổi đơn giản như quay, phóng để duy trì các đường thằng song song (gọi là chuyển đổi affine)
 Dù quay mặt theo hướng nào, chúng ta cũng có thể chuyển mắt môi về trung tâm. Dưới đây là đoạn mã tìm điểm mốc mặt và biến đổi ảnh dùng Python và dlib.
Dù quay mặt theo hướng nào, chúng ta cũng có thể chuyển mắt môi về trung tâm. Dưới đây là đoạn mã tìm điểm mốc mặt và biến đổi ảnh dùng Python và dlib.
Bước 3: Mã hóa khuôn mặt
Giờ chúng ta cố gắng phân biệt khuôn mặt với nhau. Mọi thứ đã bắt đầu trở nên thú vị hơn rồi!
Cách tiếp cận đơn giản nhất với nhận diện khuôn mặt là trực tiếp so sánh khuôn mặt tìm được ở bước 2 với ảnh của tất cả mọi người đã được tag. Khi chúng ta tìm được một bức ảnh được tag gần giống, ta tìm được tên người trong ảnh. Có vẻ là một ý tưởng tốt, phải không?
Nhưng nảy sinh một vấn đề: một trang như Facebook có hàng tỉ người sử dụng và hàng nghìn tỉ ảnh. Việc tìm kiếm qua từng ảnh tốn quá nhiều thời gian. Chúng ta cần nhận diện mặt trong 1/1000s chứ không phải hàng giờ.
Điều chúng ta cần là trích đo lường cơ bản từ mỗi khuôn mặt. Sau khi đo lường với khuôn mặt chưa biết, ta tìm đo lường gần nhất. Ví dụ, chúng ta có thể đo độ lớn mỗi tai, khoảng cách 2 mắt, độ dài của mũi... Nếu bạn xem phim tội phạm truyền hình Mỹ, bạn sẽ hiểu tôi đang nói điều gì:
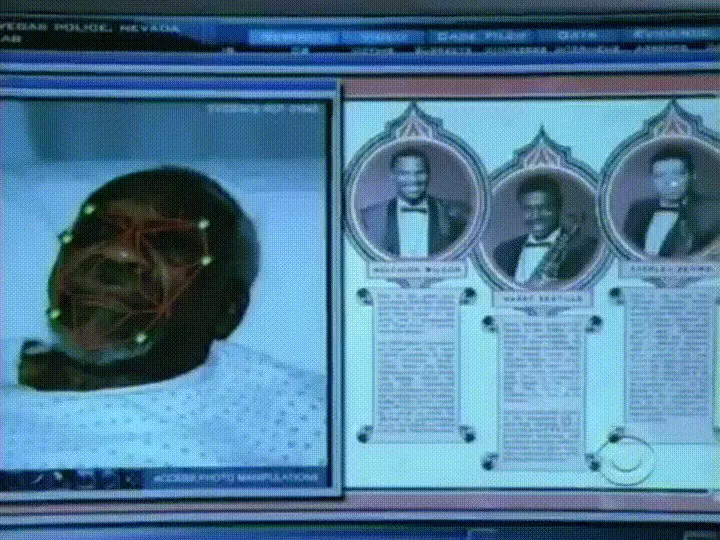
Cách đáng tin cậy nhất để đo lường khuôn mặt
Việc đo lường có vẻ dễ dàng với con người (như màu mắt, mặt tròn méo...) thực sự không có ý nghĩa với máy tính, bởi nó chỉ nhìn thấy từng điểm ảnh. Các nhà nghiên cứu đã phát hiện ra rằng: cách chính xác nhất giúp máy tính đo lường hiệu quả chính là để nó tự tìm. Deep Learning - mạng nơron đa lớp làm tốt hơn con người trong việc tìm ra yếu tố đo lường quan trọng.
Chúng ta sử dụng Deep Convolutional Neural Network - mạng nơron tích chập đa lớp như phần 3. Nhưng thay vì đào tạo mạng nơron để nhận diện ảnh, chúng ta đào tạo nó để tìm ra 128 đo lường cho mỗi khuôn mặt.
Quá trình đào tạo thực hiện bằng cách để máy tính nhìn 3 bức ảnh cùng 1 thời điểm: 2 ảnh (#1, #2) của cùng 1 người, và 1 ảnh của người khác (#3)
Sau đó, thuật toán sẽ khởi tạo ngẫu nhiên 128 giá trị đo lường. Sau đó nó sẽ thay đổi các trọng số này từ từ để giá trị tìm ra từ ảnh #1 và #2 ngày càng giống nhau, và giá trị từ ảnh #2 ngày càng khác #3

Sau khi lặp lại quá trình này hàng triệu lần với hàng triệu bức ảnh của hàng ngàn người khác nhau, mạng nơron học được cách tạo ra 128 đo lường cho mỗi người. Bất kể 10 ảnh khác nhau nào của 1 người sẽ cho kết quả gần giống nhau.
128 đo lường này được gọi là embedding (mình tạm dịch là gắn mã). Ý tưởng giảm chiều dữ liệu thô sang đại diện đo lường tạo ra từ máy tính xuất hiện rất nhiều trong học máy (đặc biệt là trong dịch thuật).
Mã hóa ảnh khuôn mặt
Quá trình đào tạo Convolutional Neural Network (CNN - mạng nơron tích chập) để gắn mã mặt yêu cầu rất nhiều dữ liệu và năng lượng máy tính. Thậm chí, với một thẻ đồ họa NVida Telsa đắt tiền, bạn cũng cần phải đợi 24h đào tạo liên tục để có một kết quả tốt.
Nhưng một khi mạng đã được đào tạo, nó có thể tạo ra đo lường cho bất kỳ khuôn mặt nào, thật chí khuôn mặt chưa từng nhìn thấy trước đây! Quá trình này chỉ cần làm một lần, và thật may cho chúng ta, OpenFace đã thực hiện điều đó. Họ đã công bố một vài mạng nơron đã được đào tạo và chúng ta có thể sử dụng trực tiếp.
Việc chúng ta cần làm là truyền hình ảnh khuôn mặt vào mạng đã được đào tạo đó để lấy ra 128 đo lường cho mỗi khuôn mặt. Đây là chỉ số hình ảnh mẫu của chúng ta:

Phần nào trong khuôn mặt 128 đo lường này biểu thị? Hóa ra là chúng ta không có bất cứ ý tưởng nào. Đây là những đặc trưng mà con người không hình dung được, và điều đó cũng thật sự không quan trọng. Điều chúng ta quan tâm là mạng này tạo ra những số giống nhau khi nhìn vào 2 hình ảnh khác biệt của cùng một người.
Nếu bạn muốn thử bước này, OpenFace cung cấp một đoạn mã giúp ta gắn mã cho tất cả ảnh trong thư mục và ghi chúng vào tập csv. Bạn có thể chạy mã như sau.
Bước 4: Tìm tên người từ đoạn mã hóa
Đây là bước cuối cùng và cũng là bước dễ nhất. Tất cả chúng ta cần làm là tìm người trong cơ sở dữ liệu có đo lường gần nhất với ảnh đầu vào.
Bạn có thể thực hiện điều này với một thuật toán phân loại đơn giản như phân loại tuyến tính SVM hoặc rất nhiều thuật toán phân loại khác.
Thuật toán SVM: Hiểu đơn giản là với những bài toán phân nhóm, sẽ tồn tại một đường thằng phân chia các nhóm. Khoảng cách từ điểm gần nhất đến đường thẳng được gọi là margin - độ rộng lề. Một số thuật toán yêu cầu điểm chỉ cần nằm bên trái hay bên phải đường thẳng là sẽ được phân vào các nhóm khác nhau, nhưng thuật toán SVM yêu cầu điểm phải cách đường thẳng phân chia một khoảng lớn hơn độ rộng của lề thì mới được phân vào nhóm để tăng sự tin cậy cho dự đoán.
Tất cả chúng ta cần làm là đào tạo lớp phân chia, sao cho nó có thể lấy đo lường từ ảnh đầu vào và chỉ ra người nào giống nhất. Việc chạy lớp phân chia chỉ khoảng 1/1000s. Kết quả của lớp phân chia là tên người cần tìm.
Hãy thử với hệ thống của chúng ta. Đầu tiên, tôi đào tạo lớp phân chia cùng với mã hóa của 20 bức ảnh của Will Ferrel, Chad Smit và Jimmy Falon:
 .
Sau đó, tôi chạy lớp phân chia trong từng khung hình của đoạn clip nổi tiếng giữa Will Ferrel và Chad Smith, khi 2 người đóng giả làm người kia trong show truyền hình với Jimmy Fallon:
.
Sau đó, tôi chạy lớp phân chia trong từng khung hình của đoạn clip nổi tiếng giữa Will Ferrel và Chad Smith, khi 2 người đóng giả làm người kia trong show truyền hình với Jimmy Fallon:
 Chương trình đã chạy tốt! Dù mặt người ở nhiều hướng khác nhau, thậm chí nửa mặt, ứng dụng vẫn nhận diện được nhân vật.
Chương trình đã chạy tốt! Dù mặt người ở nhiều hướng khác nhau, thậm chí nửa mặt, ứng dụng vẫn nhận diện được nhân vật.
Thử tự chạy xem sao!!!
Cùng nhau ôn lại các bước chúng ta đã đi qua:
- Mã hóa ảnh sử dụng thuật toán HOG để tạo ra phiên bản đơn giản hơn, sau đó tìm đoạn mã chung HOG để nhận diện khuôn mặt.
- Chuẩn hóa mặt người bằng cách tìm các điểm mốc chính trên khuôn mặt, rồi biến đổi ảnh để mắt và môi nằm ở chính giữa khuôn mặt.
- Truyền khuôn mặt đã tìm được vào một mạng nơron để tách lọc ra 128 đo lường.
- Tìm khuôn mặt có đo lường gần nhất trong cơ sở dữ liệu gần nhất với khuôn mặt đầu vào.
Bây giờ bạn đã biết toàn bộ quá trình nhận diện mặt người diễn ra như thế nào. Dưới đây là hướng dẫn chi tiết hơn, hãy cùng nhau xây dựng ứng dụng thôi nào.
Nguồn:
Nếu các bạn thấy hứng thú với series này, các bạn có thể follow mình hoặc clip series để nhận được thông báo khi có bản dịch mới nhất. Series hiện có 8 bài, những bản dịch tiếp theo sẽ được cập nhật dần dần.
All rights reserved
