Thảo luận về performance của Pandas: Pandas 2.0 liệu có đột phá?
Bài đăng này đã không được cập nhật trong 3 năm
Đây là bài viết tản mạn.
Bối cảnh mở bài là, hầu hết từ trước đến nay mình đều làm deep learning. Xử lý dữ liệu với Pandas và Numpy là một trong những bài học đầu đời khi bước chân vào con đường machine learning, nhưng cũng bởi vì bài học đầu đời, nó dường như cưỡi ngựa xem hoa. Mình đã thử vọc vạch đủ thứ hàm của Pandas, với bộ dữ liệu vài chục ngàn hàng (lúc đấy thấy thế là nhiều rồi). Bẵng đi một thời gian, à, tự dưng được vào một dự án với "hơi hơi" nhiều dữ liệu một chút. Thực ra là chỉ có vài chục triệu dòng, cũng không ăn thua gì với các bạn Data Scientist, nhưng VÀI CHỤC TRIỆU DÒNG đã đủ để PANDAS BẮT ĐẦU LỘ RA ĐIỂM YẾU CỦA MÌNH.
Bình thường, ngay khi công cụ này có vấn đề, chúng ta liền tìm sang một công cụ khác. Mình cũng vậy. Cái tên được nhắc đến đầu tiên là Dask, có cách sử dụng tương tự như Pandas khi vẫn dựa trên Dataframe, kết hợp kỹ thuật phân tán để tăng tốc độ xử lý vài chục triệu dòng. Spark quá lớn so với dữ liệu hiện tại, như dùng dao mổ trâu chặt thịt gà vậy, nên mình đã bỏ qua nó. Một cái tên khác cũng vô cùng hứa hẹn là Polars (có gấu trúc và giờ là đến gấu trắng bắc cực =))).
Về cơ bản, vấn đề của mình được giải quyết. Nhưng mà, thành thực, mình vẫn rất thích dùng Pandas. Mình mong chờ ngày Pandas được update và cải tiến mạnh mẽ hơn, và cuối cùng, Pandas 2.0 được ra mắt. Liệu nó có đáp ứng được kỳ vọng?
1st March 2023, Pandas 2.0 được release !!!
1. Những vấn đề tồn đọng của Pandas từ trước đến nay
Hãy dành một giây để nhìn lại những cột mốc phát triển của một trong những thư viện xử lý dữ liệu phổ biến nhất thế giới.

Init commit đầu tiên năm 2009, và phải đến năm 2020 mới có version 1.x. Từ v1.5, pandas manh nha bắt đầu support arrow. Liền sau đó ba năm, chúng ta cũng đến được version 2.x. Chủ yếu xoay quanh lần update này là Apache Arrow.
Vậy Pandas trước đó có vấn đề gì, tại sao lại bị vấn đề đấy. Điều gì đã làm số người lắc đầu khi nhắc đến hiệu năng của Pandas nhiều vô kể, đến mức hình thành hệ tư tưởng - Pandas chỉ để chơi chơi dữ liệu nhỏ lẻ trên kaggle =)))
- Một trong những vấn đề đầu tiên của pandas là cách quản lý bộ nhớ. Theo blog của Wes McKinney, founder của pandas, đã thành thực rằng họ không hề nghĩ nhiều đến vấn đề dữ liệu lúc viết nó vào năm 2008. 10GB dữ liệu đã được xem là nhiều vào thời điểm đấy và thậm chí, theo lời của ông, Pandas có một quy tắc: "pandas rule of thumb: have 5 to 10 times as much RAM as the size of your dataset", có nghĩa là nếu muốn dùng pandas hiệu quả thì RAM của bạn nên gấp 5-10 lần tập dữ liệu. Nếu bạn nghĩ rằng tập dữ liệu của bạn chỉ có 8GB, và RAM còn dư tận 10GB, thoải mái, thì suy nghĩ đó là sai lầm. "Nếu datasize của bạn là 10GB, RAM 64GB là ổn." - From founder.
Có thể thấy, nó không ổn chút nào.
- Ngoài việc quản lý memory không hiệu quả, Pandas còn CHẬM. Vậy nguyên nhân chậm của Pandas là do đâu?
Như nhiều người đã biết, Pandas được built trên Numpy, và Numpy được built trên C. Theo lẽ thường, C là một trong những ngôn ngữ có tốc độ thực thi vô cùng nhanh, nên hẳn là Pandas cũng phải nhanh.
Tuy nhiên, hãy cùng nghía qua bài viết này, một số bài test được thực hiện để đo tốc độ trên Pandas và Numpy.
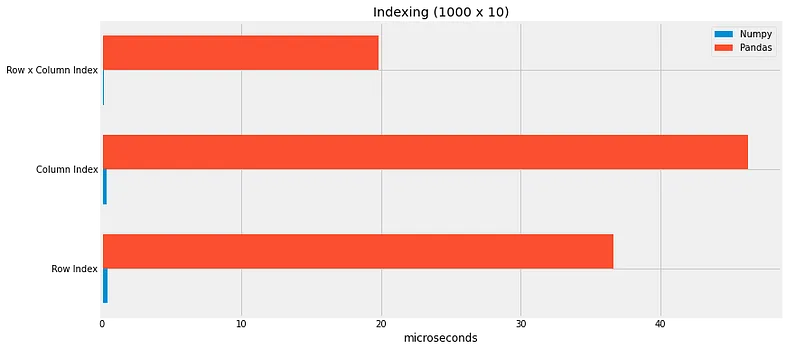
Thật ngạc nhiên, là Numpy nhanh hơn, nhưng nhanh hơn hẳn. Tất nhiên có một số trường hợp tính toán dạng vectorize Pandas tỏ ra vượt trội hơn (đây cũng là một trong những trick hiệu quả nhất để faster pandas lên 100x lần), nhưng nhìn chung, Numpy out trình Pandas.
Một trong những lý do lớn nhất của việc này là Pandas không hoàn toàn là một Python package, như Numpy. Pandas được viết bằng Cython và C, nhanh hơn đáng kể so với python và chủ yếu sử dụng python làm API. Do đó, việc coi Pandas Dataframe như một cấu trúc dữ liệu python thông thường sẽ bỏ qua các lợi thế của mã C được tối ưu hóa của nó.
Các cách tiếp cận thông thường như vòng lặp for và vòng lặp while khi dùng Pandas không hề hiệu quả vì chúng liên tục phải chuyển đổi giữa mã Python và mã C. Pandas chậm truy xuất dữ liệu, Python chậm cả tính toán. Liên tục truy xuất dữ liệu từ Pandas và tính toán dữ liệu đó bằng Python có nghĩa là bạn đang sử dụng pandas ngay tại điểm yếu của nó.
Pandas không yếu, nếu chúng ta sử dụng nó đúng cách hơn. Bằng cách đừng có lôi element của nó ra mà hãy viết hàm và để nó tự xử lý. Đây chính là lý do đừng bao giờ dùng for/loop với pandas, hãy chuyển nó qua apply, chuyển nó qua vectorize, hay viết thẳng hàm xử lý bằng Cython.
- Thứ ba, hạn chế về biểu diễn dữ liệu.
Một trong những cách dễ nhất khi mới bắt đầu sử dụng Pandas là load dữ liệu vào một cái Dataframe. Có thể thấy, đối với dữ liệu đơn giản như integer, float, rất đơn giản. Nhưng vấn đề là các dữ liệu strings, datetimes, và categories. Python rất linh hoạt đối với dữ liệu, nhưng không thể phủ nhận các Python data structures như lists, dictionaries, tuples khá chậm, và trong trường hợp này, không giúp được Pandas, khiến nó phải nhờ hỗ trợ từ các bên thứ ba như mã C, mã Rust.
Và còn một vấn đề nữa, mặc dù Pandas được build trên Numpy và trở nên rất phổ biến, Numpy, chưa bao giờ được xây dựng để tối ưu cho backend Dataframe của Pandas. Đó cũng là một hạn chế.
2. Pandas 2.0 có gì mới
Pandas 2.0 đã thay đổi, từ Numpy, qua Apache Arrow. Thay đổi này đã đem lại những gì?
- Tốc độ nhanh hơn
- Support nhiều hơn cho các dạng data khác ngoài numerical data.
- Thay đổi cách biểu diễn "None" value
- Interoperability tốt hơn
Install
Hiện nay, tại thời điểm viết bài là 3/2023, phiên bản release chính thức của pandas vẫn là 1.5.3. Nên cần chỉ định phiên bản khi cài đặt ver 2.
python -m pip install pandas==2.0.0rc0
Đồng thời, pandas cung cấp cả hai loại backend là numpy và arrow. Nếu muốn dùng arrow, bạn cần chỉ định nó.
import pandas
pandas.options.mode.dtype_backend = 'pyarrow'
pandas.read_csv(filename, engine='pyarrow', use_nullable_dtypes=True)
2.1. Tăng tốc độ
Đầu tiên, mình test tốc độ đọc file với backend arrow. File mình test là một file csv chứa một triệu dòng dữ liệu.
%timeit df = pd.read_csv("result_2023-03-30T02_40_15.971821Z.csv", engine="pyarrow")
%timeit df = pd.read_csv("result_2023-03-30T02_40_15.971821Z.csv")
# 1.24 s ± 145 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# 5.45 s ± 620 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Kết quả nhận được, tốc độ đọc file đã tăng gấp tận 5 lần.
Tiếp theo, mình sẽ test thử tốc độ tính toán một chút:
arr = pd.Series([random.choice(range(1000)) for i in range(1000)], dtype='int64')
arr_arrow = arr.astype(dtype='int64[pyarrow]')
%timeit arr.mean()
%timeit arr_arrow.mean()
Kết quả nhận được:
45.2 µs ± 1.79 µs per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
17.8 µs ± 1.32 µs per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
Pyarrow vừa giúp tăng tốc độ lên gấp 3 lần, vượt hơn cả mong đợi. Mình tiếp tục tăng lượng dữ liệu lên với 10.000.000 bản ghi.
arr = pd.Series([random.choice(range(1000)) for i in range(1000000)], dtype='int64')
arr_arrow = arr.astype(dtype='int64[pyarrow]')
%timeit arr.mean()
%timeit arr_arrow.mean()
Và kết quả nhận được:
11.2 ms ± 1.4 ms per loop (mean ± std. dev. of 7 runs, 100 loops each)
5.79 ms ± 497 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Tốc độ tính toán tăng gấp đôi, một tín hiệu tốt lành. Mình tiếp tục thử test tiếp với kiểu dữ liệu float:
arr = pd.Series([random.uniform(0, 1000) for i in range(10000000)], dtype='float64')
arr_arrow = arr.astype(dtype='float64[pyarrow]')
%timeit arr.mean()
# 27.1 ms ± 4.93 ms per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit arr_arrow.mean()
# 7.58 ms ± 484 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit arr - arr * 0.5
# 142 ms ± 52.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
%timeit arr_arrow - arr_arrow * 0.5
# 41.6 ms ± 4.77 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
Test thử một số hàm khác như merge, aggregate trong pandas:
%timeit df_post[['Vote Score', 'Views Count']].aggregate('sum')
%timeit df_post_arrow[['Vote Score', 'Views Count']].aggregate('sum')
# 1.13 ms ± 125 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
# 937 µs ± 135 µs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
Test Merge
%timeit df.merge(df_post, left_on="id", right_on="ID", how="inner")
%timeit df_arrow.merge(df_post_arrow, left_on="id", right_on="ID", how="inner")
# 14.7 ms ± 9.71 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
# 7.98 ms ± 339 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Test Groupby
%timeit df_time.groupby(["user_id", "post_id"])['read_time'].aggregate('sum')
%timeit df_time_arrow.groupby(["user_id", "post_id"])['read_time'].aggregate('sum')
# 1.22 s ± 124 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# 1.07 s ± 42.4 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Có sự cải thiện, nhưng không rõ rệt.
Bạn có thể tìm thấy Bảng convert giữa Numpy Dtype và Arrow Dtype tại đây.
2.2. Biểu diễn missing value
Missing value, hay thường được biểu thị bởi giá trị None. Thông thường, nếu bạn có một cột data thuộc dạng int8, giá trị các bản ghi trong cột sẽ trải dài từ 0 đến 255. Sẽ ra sao nếu có giá trị None trong cột này. Nó nên được biểu diễn thế nào để đồng nhất với các giá trị trong cùng cột. Ta có thể dùng 255 để chỉ định cho nó chẳng hạn, nhưng như thế là vừa vượt ra khỏi dải dữ liệu của cột. Và liệu tất cả các missing value ở tất cả các cột đều được chỉ định biểu diễn giống nhau có ổn không. Cuối cùng, Pandas đã đưa tất cả về NaN.
Với Pandas 2.0, giờ đây chúng ta có thể chỉ định dtype cho missing value. Pandas đã thực hiện bằng cách sử dụng hai mảng thay vì một. Mảng chính đại diện cho dữ liệu như thể không có giá trị nào bị thiếu, đồng thời một mảng boolean bổ sung cho biết giá trị nào từ mảng chính hiện có và cần được xem xét, giá trị nào không và phải bỏ qua.
2.3. Support các dạng datatype khác
Ta cũng biết Numpy mạnh nhất với tính toán số, xử lý rất tốt với integer, float. Nhưng nếu dữ liệu của bạn có nhiều loại data khác, hãy cân nhắc lên pandas 2.0 với support mạnh mẽ cho string.
Mình có một column string chứ tên các bài viết. Hãy thử tìm danh sách các bào viết bắt đầu bằng chữ 'a'.
%timeit df['title'].str.startswith("a")
%timeit df_arrow['title'].str.startswith("a")
# 3.85 ms ± 406 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
# 153 µs ± 8.85 µs per loop (mean ± std. dev. of 7 runs, 10,000 loops each)
Và đúng như trong documentation đề cập, tốc độ xử lý giờ đã gấp lên 25-30 lần, một con số đáng nể.
Tuy nhiên, một điểm trừ đáng kể là, có lẽ do mới public nên rất nhiều hàm trong "string[pyarrow]" chưa được support mạnh mẽ như trên numpy. Danh sách số lượng rất lớn các hàm string support vectorize bạn có thể tìm thấy tại PythonDataScienceHandbook.
2.4 Interoperability - Khả năng tương tác với các thư viện khác
Nhiều nhất khi dùng pandas có lẽ là chúng ta đọc các file csv. Khi chuyển qua sử dụng các thư viện khác, file csv vẫn là một định dạng phổ biến, nên việc di chuyển khá dễ dàng. Việc ép kiểu qua Arrow có làm thay đổi nó?
Câu trả lời là không. Arrow, không phải định dạng file, mà là một định dạng về các lưu trữ trong bộ nhớ. Từ đây, việc chia sẻ dữ liệu giữa các chương trình khác nhau ngày càng dễ dàng và tiêu chuẩn hơn. Và nó có thể được thực hiện một cách cực kỳ nhanh chóng và hiệu quả về bộ nhớ, vì hai chương trình có thể chia sẻ cùng một dữ liệu theo đúng nghĩa đen (cùng một bộ nhớ mà không cần phải tạo một bản sao cho mỗi chương trình).
Tất cả những điều trên Pandas 2.0 đạt được nhờ thay đổi cơ chế ở backend, từ Numpy, sang Apache Arrow. Vậy rốt cuộc, cơ chế này là gì.
3. Cơ chế backend Arrow của Pandas
Số liệu so sánh được đưa ra trong bài viết release pandas 2.0

Apache Arrow là gì?
Có thể bạn đã biết, một trong những thách thức lớn nhất khi làm việc với dữ liệu lớn là chi phí của việc di chuyển dữ liệu giữa các công cụ và hệ thống khác. Đây là một trong những vấn đề luôn được cân nhắc khi xây dựng Data Pipeline.
Các ngôn ngữ lập trình, định dạng tệp và giao thức mạng khác nhau đều có những cách khác nhau để biểu diễn cùng một dữ liệu trong bộ nhớ. Quá trình tuần tự hóa (serialization) và giải tuần tự hóa (deserialization) cùng một dữ liệu thành một biểu diễn khác nhau ở mỗi step trong Data Pineline có thể làm cho việc xử lý một lượng lớn dữ liệu trở nên chậm hơn và tốn kém hơn về mặt phần cứng.
Giải pháp cho vấn đề này là tạo ra thứ có thể được coi là ngôn ngữ chung cho dữ liệu. Và một trong số đó, là Apache Arrow.
Apache Arrow là một nền tảng phát triển cho in-memory analytics. Phải nói thêm, cụm từ in-memory dùng để chỉ tập các phương pháp xử lý dữ liệu trong đó các dữ liệu được tải vào bộ nhớ chính (RAM) để thực hiện các phân tích và truy vấn, thay vì lưu trữ dữ liệu trên đĩa cứng. Theo đó, Apache Arrow bao gồm một tập hợp các công nghệ cho phép các hệ thống dữ liệu lớn xử lý và di chuyển dữ liệu nhanh chóng. Apache Arrow giúp kết hợp hiệu quả hơn việc sử dụng CPU và GPU, giúp làm việc với các tập dữ liệu lớn dễ dàng hơn và ít tốn kém hơn. Định dạng kiểu Arrow cũng hỗ trợ các lần đọc zero-copy để truy cập dữ liệu cực kỳ nhanh mà không cần chi phí tuần tự hóa.
- Note: Zero-copy là gì (Mọi người có thể bỏ qua phần này =)))
Zero-copy là một trong những kỹ thuật tối ưu việc chuyển dữ liệu. Thông thường, khi bạn muốn chuyển dữ liệu từ nơi này sang nơi khác, bạn phải đi qua 4 lần copy: (1) đọc nội dung từ đĩa nguồn và lưu trữ chúng trên không gian địa chỉ kernel, (2) Dữ liệu sẽ được sao chép từ kernel buffer tới user buffer, (3) sao chép dữ liệu từ user buffer tới một kernel buffer khác liên kết với socket đích, và cuối cùng là (4) chuyển dữ liệu tới đĩa đích. Cách tiếp cận này có một “bottleneck” khi kích thước của dữ liệu được yêu cầu lớn hơn kích thước của kernel buffer. Dữ liệu sẽ phải được chia nhỏ và sao chép nhiều lần giữa đĩa, kernel buffer, user buffer trước khi hoàn thành, chi phí sao chép sẽ rất lớn. Từ đó, zero-copy ra đời giúp loại bỏ những thao tác thừa ở bước (2) và (3), tối ưu công việc data transfer.
Mục tiêu chung cho Apache Arrow đối với OLAP (các hệ thống lớn và mạnh để phân tích và lưu trữ tổng dữ liệu lớn) cũng giống như những gì ODBC/JDBC đã làm đối với OLTP (các hệ thống ổn định và nhanh chóng để làm việc với dữ liệu realtime, đó là cố gắng tạo giao diện chung cho các hệ thống khác nhau làm việc với dữ liệu phân tích. Một trong những lưu ý là cách OLAP nhận thông tin. OLAP không thu thập thông tin từng chút một trong từng lần cập nhật giao dịch, mà được lấp đầy bởi các truy vấn theo lô, quét toàn bộ model nguồn (thường là một hệ thống OLTP) và nhập dữ liệu vào mô hình OLAP. Rõ ràng, quá trình nhập dữ liệu này có thể cực lớn và chậm. Theo đó, Apache Arrow cũng được thiết kế để tối ưu cho việc này.
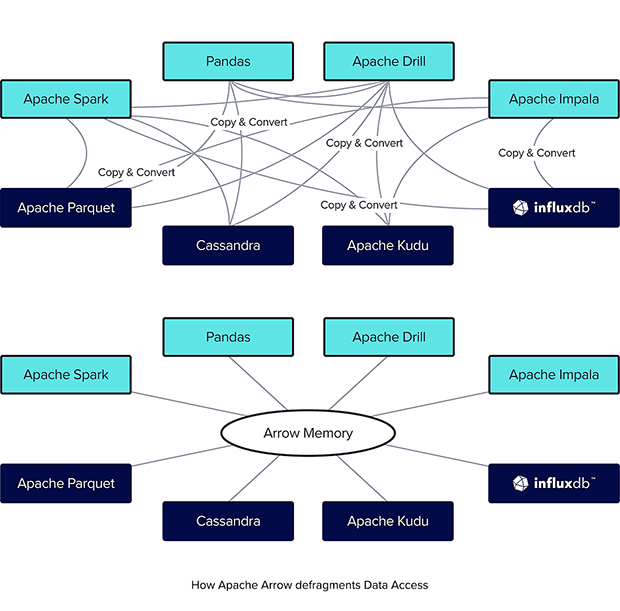
Bằng việc chuyển sang built trên Apache Arrow, Pandas đang ngày cang tham gia nhiều hơn vào hệ sinh thái "arrow" mạnh mẽ này.
Bạn có thể đọc chi tiết về những cải tiến mà Arrow đóng góp cho Pandas qua bài viết của Founder Pandas dưới đây:
So sánh Pandas và Dask
Nhiều người có thể nghĩ về Dask là một sự cải thiện hiệu quả về performance và khả năng mở rộng của Pandas. Dask tối ưu hóa tốc độ bằng cách song song hóa các tập dữ liệu lớn thành nhiều phần và làm việc với chúng trong các luồng hoặc quy trình riêng biệt. Nhờ đó, Dask giúp khác phục hạn chế về memory của Pandas.
Nói chung là, Dask cũng ổn, nhưng cũng không phải là toàn năng.
Nhưng một vấn đề với Dask là nó sử dụng Pandas làm hộp đen. dask.dataframe không giải quyết được các vấn đề về sử dụng bộ nhớ và hiệu suất vốn có của Pandas. Nó, chỉ đơn giản, trải rộng chúng ra trên nhiều process. Nó giúp giảm thiểu chúng bằng cách cẩn thận không làm việc đồng thời với các phần dữ liệu quá lớn. Về cơ bản, vấn đề thật sự chưa được giải quyết một cách triệt để.
So sánh Pandas và Polars
Một trong những ứng cử viên sáng giá khác được cân nhắc để thay thể Pandas là Polars. Thậm chí, kể từ khi ra mắt, Polars đang phát triển ngày càng nhanh chóng, gây ra sự đe dọa nghiêm trọng đến pandas. Và không ngạc nhiên lắm, nền tảng của Pandas, chính là Arrow Support.
Vậy Pandas 2.0 giờ cũng có arrow rồi, liệu nó có đá bay lại được Polars =))) Câu trả lời là không, nhưng khoảng cách giữa hai thư viện cũng đã được thu hẹp đang kể. Polars được xây hoàn toàn và tối ưu trên arrow. Giờ đây, engineer có thể dễ dàng chuyển đổi giữa polars và pandas để đạt được hiệu quả xử lý dữ liệu cao nhất.
Tuy nhiên, cũng phải lưu ý một chút. Mình có nhắc đến Pandas 2.0 đã nâng cao Interoperability - Khả năng tương tác. Có thể thấy giờ đây Pandas và Polars đã dùng dung arrow structure, việc chuyển đổi dễ hơn, nhưng không hoàn toàn. Arrow của Pandas là PyArrow, được xây dựng trên C++, trong khi Arrow xủa Polars được xây từ Rust, sau cùng cả hai đều được bọc bằng Python, nhưng chắc chắn chúng vẫn sẽ có sự khác biệt. https://www.reddit.com/r/dataengineering/comments/11wc273/code_comparison_between_rust_polars_and_pandas/
4. Kết
Như tiêu đề của bài viết, Pandas 2.0 liệu có thể đột phá không?
Câu trả lời là không, nhưng mình nghĩ sự cải tiến này đang đi đúng hướng. Với tư cách là người rất thích dùng pandas, mình hi vọng pandas sẽ ngày càng có nhiều thay đổi mạnh mẽ hơn nữa.
5. Một vài tips pandas
Dưới đây, mình tổng hợp kha khá tips pandas mà mình đang sử dụng. Mình thường note luôn vào blog để sau này tiện tìm lại  )) Đã có rất nhiều bài chia sẻ về các tips này, mình xin phép dẫn link ở đây. Hi vọng mọi người có thể tìm thấy nhiều tips có ích hơn nữa để cải thiện hiệu suất pandas của mình nhé <33
)) Đã có rất nhiều bài chia sẻ về các tips này, mình xin phép dẫn link ở đây. Hi vọng mọi người có thể tìm thấy nhiều tips có ích hơn nữa để cải thiện hiệu suất pandas của mình nhé <33
-
Convert sang parquet để tăng tốc đọ đọc ghi lên 10x lần. https://www.youtube.com/watch?v=u4_c2LDi4b8
-
Cast sang type khác để tăng tốc độ sử lý và datasize https://www.youtube.com/watch?v=SAFmrTnEHLg
-
Vectorization còn mạnh hơn apply và loop https://pythonspeed.com/articles/pandas-vectorization/
-
Chuyển sang code Cython https://medium.com/@tommerrissin/is-pandas-really-that-slow-cff4352e4f58
-
Improve với code Cython https://pandas.pydata.org/pandas-docs/stable/user_guide/enhancingperf.html
Hi vọng bài viết này có thể đem lại thông tin hữu ích cho mọi người. Ngại gì không để lại một Upvote để góp phần giúp MayFest tháng 5 thêm sôi động nào :>>>
All rights reserved
