Zero-shot Object Detection with Detic
Bài đăng này đã không được cập nhật trong 3 năm

Gần đây chúng ta đã quá quen thuộc với từ khóa "zero-shot", một trong những ví dụ điển hình của nó chính là ChatGPT của OpenAI đang làm mưa làm gió trên khắp các diễn đàn (kể cả không liên quan tới trí tuệ nhân tạo). Tuy nhiên "zero-shot" đã xuất hiện từ khá lâu, nó được dùng để đại diện cho các mô hình cho phép dự đoán các lớp (classes) không xuất hiện trong quá trình huấn luyện. Vào đầu năm 2022, Facebook Research đã công bố bài báo có tên "Detecting Twenty-thousand Classes using Image-level Supervision", bài báo đưa ra một phương pháp mới giúp tận dụng lượng dữ liệu về classification để cải thiện mô hình object detection và đồng thời cho phép mô hình object detection thực hiện "zero-shot". Chúng ta cùng tìm hiểu chi tiết về bài báo này tại đây.
Motivation
Object Detection là một bài toán khá quen thuộc và đã được nghiên cứu từ lâu trong lĩnh vực Computer Vision.
Hiện nay, các mô hình Object Detection đã được áp dụng rất nhiều trong cuộc sống. Tuy nhiên, các mô hình object detection hiện nay đều bị hạn chế về số lượng phân lớp có thể dự đoán, do các bộ dữ liệu còn khá hạn chế. Để tạo ra một bộ dữ liệu chất lượng thì khá mất thời gian và công sức.
Trong khi đó, bài toán Image Classification có rất nhiều bộ dữ liệu khá lớn và việc thu thập dữ liệu mới cũng dễ dàng hơn so với Object Detection. Vậy có cách nào tân dụng lượng data khổng lồ của classification để cải thiện mô hình Object Detection không?
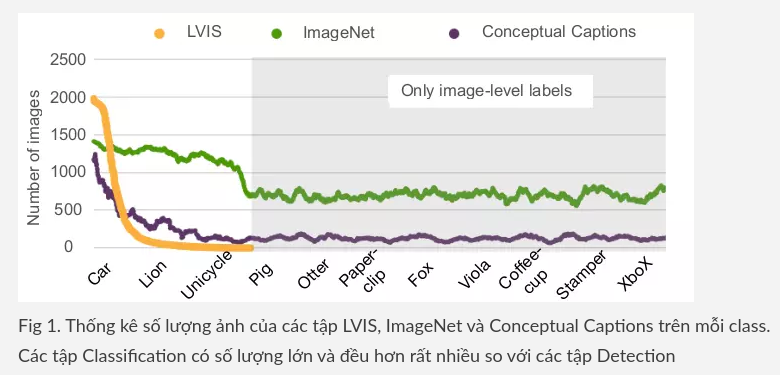 Trước đó cũng đã có nhiều bài báo đặt ra vấn đề này và cố gắng giải quyết nó. Tuy nhiên hầu hết các hướng tiếp cận đều dựa trên phương pháp weekly supervised learning (ban đầu cho mô hình học supervised trên một tập dữ liệu nhỏ, sau đó dựa vào mô hình đó để sinh ra các nhãn giả cho các ảnh chưa được gán nhãn, từ đó thu được tập dữ liệu mới và tiếp tục học supervised trên tập dữ liệu đó). Hướng tiếp cận này làm chúng ta liên tưởng tới câu chuyện con gà và quả trứng: muốn có được các nhãn giả tốt thì mô hình được train trước đó cũng phải tốt. Điều này làm mô hình không có tính ổn định khi hoàn toàn có thể sinh ra các nhãn nhiễu.
Trước đó cũng đã có nhiều bài báo đặt ra vấn đề này và cố gắng giải quyết nó. Tuy nhiên hầu hết các hướng tiếp cận đều dựa trên phương pháp weekly supervised learning (ban đầu cho mô hình học supervised trên một tập dữ liệu nhỏ, sau đó dựa vào mô hình đó để sinh ra các nhãn giả cho các ảnh chưa được gán nhãn, từ đó thu được tập dữ liệu mới và tiếp tục học supervised trên tập dữ liệu đó). Hướng tiếp cận này làm chúng ta liên tưởng tới câu chuyện con gà và quả trứng: muốn có được các nhãn giả tốt thì mô hình được train trước đó cũng phải tốt. Điều này làm mô hình không có tính ổn định khi hoàn toàn có thể sinh ra các nhãn nhiễu.
Vậy hướng tiếp cận của các tác giả ở đây có gì khác biệt, phức tạp hơn chăng? Không, nó sẽ vô cùng đơn giản, nhưng các bạn sẽ phải bất ngờ khi thấy được kết quả mà nó đem lại. Hãy cùng tìm hiểu tiếp nhé.
Tổng quan về Object Detection
Bài toán Object Detection thường được chia làm 2 trường phái: one-stage và two-stage. Đại diện cho one-stage là các mô hình như RetinaNet hay phổ biến hơn là Yolo. Đại diện cho lớp two-stage đó chính là Faster RCNN. Giữa 2 trường phái trên không có bên nào là vượt trội hoàn toàn cả. Trong khi one-stage thiên về tốc độ thì two-stage lại đem lại độ chính xác cao hơn.
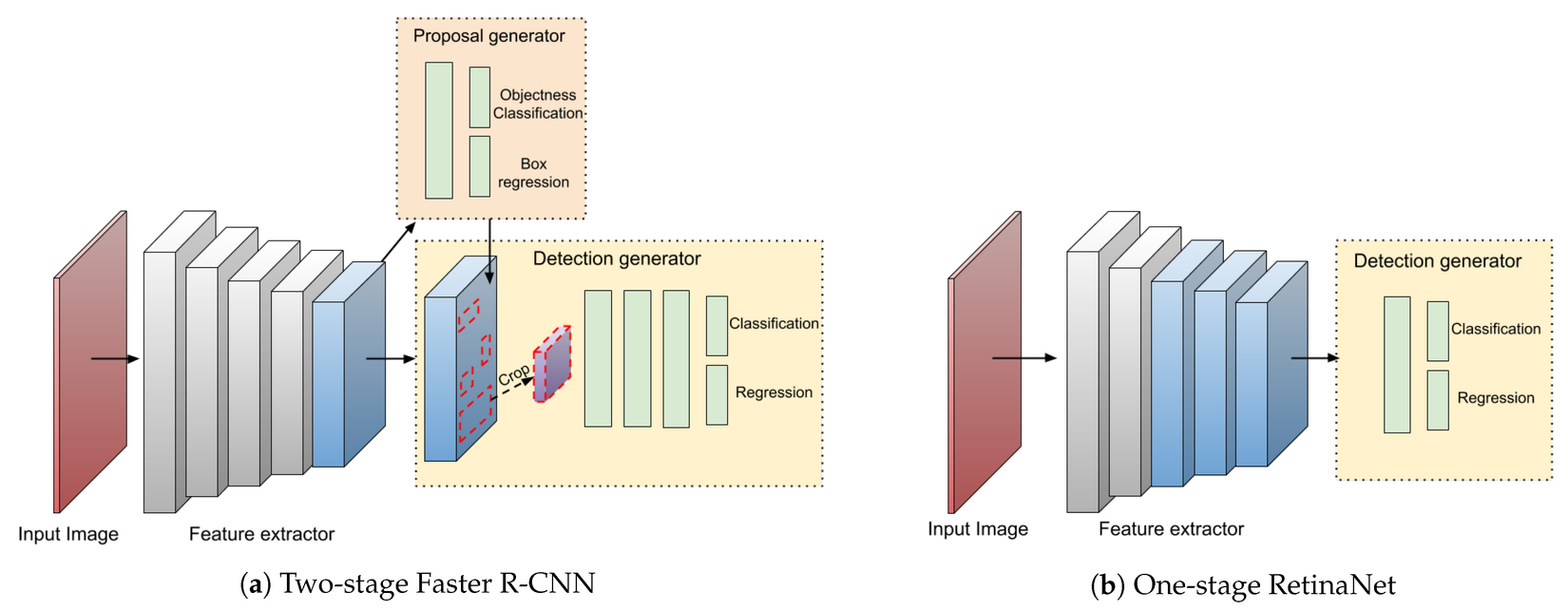
Tại sao gọi là two-stage và one-stage?
Đối với one-stage, hình ảnh khi được đưa qua lớp backbone sẽ trả về các feature map, từ các feature map đó sẽ predict trực tiếp ra các object bounding box.
Trong khi đó, two-stage phức tạp hơn 1 chút. Hình ảnh sau khi đưa qua lớp backbone sẽ thu được các feature map, tại mỗi feature map, ta sử dụng 1 module nữa gọi là Region Proposal Network (RPN) để tìm ra các box tạm thời có khả năng cao sẽ chứa object (số lượng thường rất lớn, thường là 2000 proposals), rồi ta sẽ đưa từng proposal đó qua 1 lớp CNN nữa để predict ra class và bounding box cuối cùng.
Với kiến trúc được chia ra làm 2 phần, output của stage 1 là các proposal có thể được chọn lọc để đưa vào stage 2, two-stage cho phép chọn ra các proposal tốt và loại đi các proposal kém chất lượng, điều này phù hợp với mục đích tận dụng bộ data từ domain khác như Classification để cải thiện khả năng của Object detection. Do đó, mô hình two-stage đã được sử dụng trong bài báo này.
Detic: Detector with Image Classes
Khi đọc đến đây, hãy đảm bảo rằng các bạn đã có hiểu 1 chút về mô hình two-stage object detection. Hãy thử trả lời một số câu hỏi sau nhé:
- Tại sao lại gọi là two-stage?
- Vì là two-stage, vậy output của stage thứ nhất là gì?
- Ở stage thứ 2, đầu vào của nó lấy từ đâu?
Nếu bạn đã trả lời được các câu hỏi trên, hãy cùng tìm hiểu về Detic nào!
Trước tiên hãy cùng dành một chút thời gian để nhìn ngắm hình vẽ dưới đây về DETIC và xem nó khác gì so với two-stage thông thường hay không?
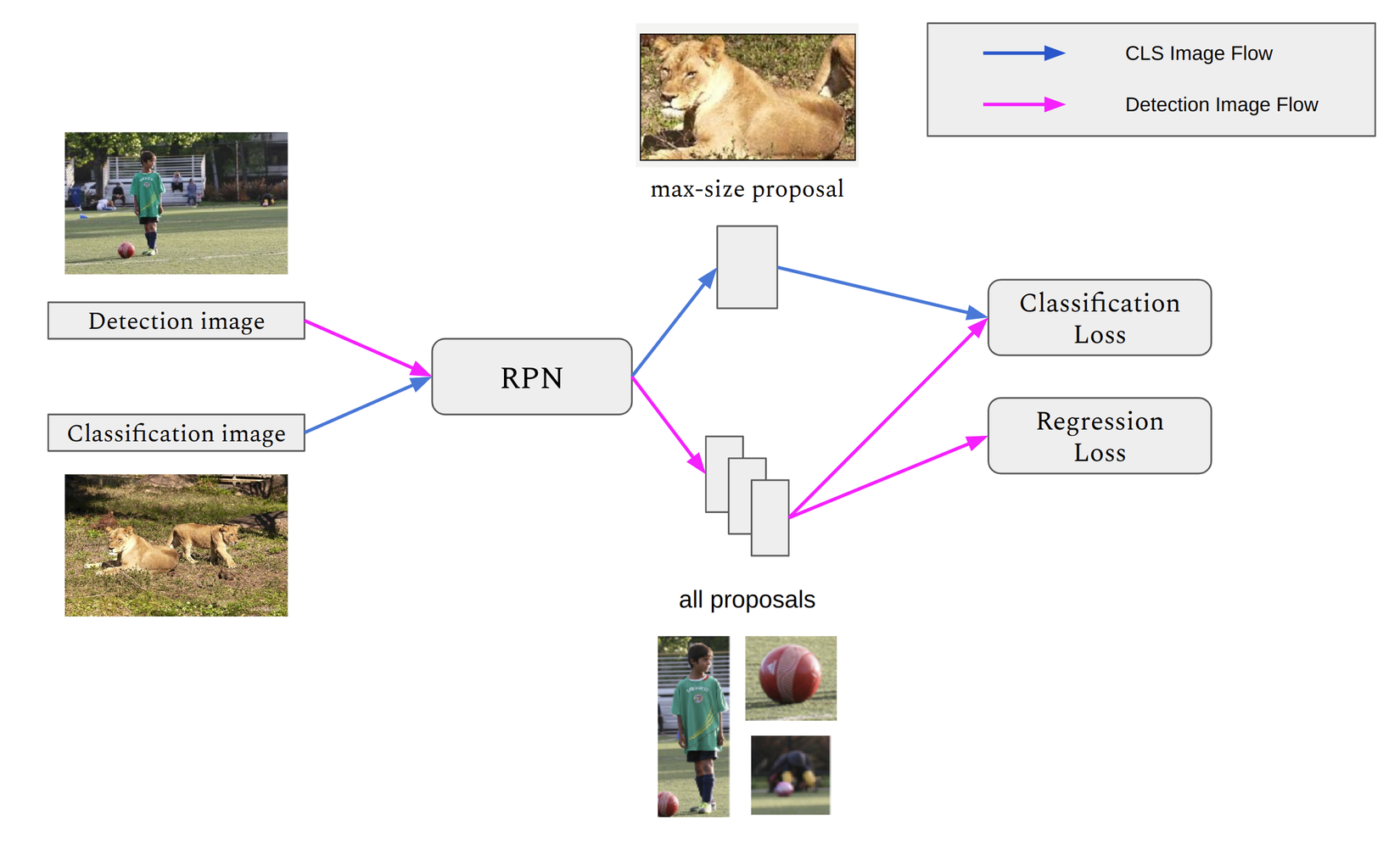
Sự khác biệt ở đây đó chính là flow có các mũi tên màu xanh phải không nào? Ngoài việc train mô hình với bộ data về detection thông thường, như đã đề cập, ta sẽ sử dụng thêm các bộ data của bài toán classification. Để tôi tập trung phân tích kĩ hơn về Flow màu xanh này nhé:
- Đầu tiên, ảnh sẽ được đưa vào stage thứ nhất, tức là qua lớp Backbone + RPN để thu được các proposal.
- Tiếp theo, tác giả chỉ chọn proposal có kích thước lớn nhất để đưa vào stage 2.
- Ở stage 2, thông thường ta sẽ đưa proposal ở trên vào các module classification và regression để predict ra cả class và bouding box. Tuy nhiên ta lại chỉ có label về class, lựa chọn an toàn ở đây của tác giả là ta chỉ tối ưu module classifcation dựa trên label tương ứng đó.
Tại sao chỉ lấy proposal có kích thước lớn nhất?
Để trả lời được câu hỏi này, đầu tiên chúng ta phải nhận định rằng bộ data của bài toán classification có tính chất object centric (object thường được xuất hiện ở trung tâm của hình ảnh và thường có kích thước khá lớn so với khung hình). Do đó, khi lấy max-size proposal, khả năng rất cao ta sẽ lấy được proposal chứa thông tin nhiều về object trong hình.
Thực tế, tác giả cũng đã thử nhiều cách chọn ra 1 proposal trong đống proposals mà RPN sản sinh ra:
- Image-box: Lúc này proposal là toàn bộ bức ảnh đầu vào
- Box with max object score: Lựa chọn proposal box có object score cao nhất.
- Box with max size: Lựa chọn proposal box có kích thước lớn nhất.
Bằng thực nghiệm, tác giả thấy rằng max-size proposal cho kết quả tốt nhất.
Inference
Quá trình inference của Detic có một số khác biệt so với các mô hình khác, đặc biệt là trong việc phát hiện lớp. Giống như các mô hình khác, Detic cũng đưa các đề xuất (proposals) qua các lớp Fully Convolutional Network (FCN) để tạo ra một feature vector . Ở các mô hình classification thông thường, vector sẽ được đưa qua các lớp Linear rồi tính Softmax để được kết quả xác suất thuộc về từng class. Tuy nhiên, Detic sử dụng feature vector để so sánh với feature vector được tạo ra từ nhãn thứ sau khi đưa vào mô hình CLIP để đo độ tương thích giữa Image - Label.
Cụ thể mô hình sẽ tính với từng class rồi tính softmax trên chúng để thu được đơn vị xác suất.
CLIP là gì?
CLIP là viết tắt của "Contrastive Language-Image Pre-Training". Đây là một mô hình pre-training cho các bài toán liên quan đến xử lý ngôn ngữ và hình ảnh. Mục tiêu của CLIP là tạo ra một khả năng hiểu biết bề ngoài của thế giới từ việc đào tạo một mô hình học sâu trên tập dữ liệu lớn của văn bản và hình ảnh.
 Điều đặc biệt về CLIP là nó không giới hạn việc đào tạo chỉ trên một ngôn ngữ cụ thể hoặc chỉ trên một loại hình ảnh cụ thể. Thay vào đó, CLIP sử dụng một phương pháp "đối lập" (contrasting) để đào tạo trên cả hai loại dữ liệu. Điều này có nghĩa là CLIP đào tạo một mô hình có khả năng hiểu được các mối liên hệ giữa văn bản và hình ảnh trên cả hai ngôn ngữ và loại hình ảnh khác nhau.
Điều đặc biệt về CLIP là nó không giới hạn việc đào tạo chỉ trên một ngôn ngữ cụ thể hoặc chỉ trên một loại hình ảnh cụ thể. Thay vào đó, CLIP sử dụng một phương pháp "đối lập" (contrasting) để đào tạo trên cả hai loại dữ liệu. Điều này có nghĩa là CLIP đào tạo một mô hình có khả năng hiểu được các mối liên hệ giữa văn bản và hình ảnh trên cả hai ngôn ngữ và loại hình ảnh khác nhau.
Về cơ bản, CLIP sử dụng một kiến trúc mạng học sâu đa nhiệm (multitask) để học cách ghép nối văn bản và hình ảnh lại với nhau. Mô hình được đào tạo trên hai tác vụ chính: dự đoán hình ảnh được mô tả bởi một câu văn mô tả, và dự đoán câu văn mô tả được đại diện bởi một hình ảnh. Một cách tổng quát, mô hình này học cách biểu diễn các khái niệm trong văn bản và hình ảnh dưới dạng các vector số, sau đó so sánh chúng để tìm ra các cặp khái niệm tương đồng nhau.
Với các vector biểu diễn hình ảnh và văn bản này, CLIP có thể được sử dụng để giải quyết nhiều bài toán liên quan đến xử lý ngôn ngữ và hình ảnh, bao gồm cả phân loại hình ảnh và phát hiện đối tượng.
Zero-shot Detection
Zero-shot detection là một kỹ thuật trong đó một mô hình được đào tạo để phát hiện các đối tượng không xuất hiện trong tập dữ liệu huấn luyện.
Detic sử dụng kỹ thuật zero-shot detection thông qua việc sử dụng mô hình CLIP để tạo ra các vector biểu diễn cho các lớp đối tượng. Như vậy, Detic có thể phát hiện các đối tượng mà không xuất hiện trong tập dữ liệu huấn luyện bằng cách so sánh các vector biểu diễn đối tượng với các vector biểu diễn được tạo ra từ các miêu tả đối tượng không xuất hiện trong tập dữ liệu huấn luyện.
Trong bài báo, để thể hiện khả năng nhận diện đa dạng của Detic, tác giả đã sử dụng baseline như sau:
- Đầu tiên train supervised với bộ data COCO 2017
- Sau đó tiếp tục train với bộ data 21M ImageNet
- Sử dụng mô hình trên để benchmark trên nhiều tập dataset khác nhau.
![image.png]() Kết quả cho thấy răng Detic outperform cả những mô hình train supervised trên tập dataset tương ứng.
Kết quả cho thấy răng Detic outperform cả những mô hình train supervised trên tập dataset tương ứng.

Kết quả
Bằng khả năng sử dụng bộ dataset của bài toán Classification, nó có thể giúp cho Detic mở rộng vốn kiến thức về các loại object của mình. Theo như tên bài báo, nó có thể dự đoán tới 21M class, có lẽ khá trùng hợp với bộ dataset ImageNet 21M. Ngoài ra các bạn cũng có thể thử trực tiếp khả năng của mô hình tại đây: https://huggingface.co/spaces/taesiri/DeticChatGPT
Ở dưới đây có 1 số kết quả khá ấn tượng mà mô hình này đem lại
Working desk

Construction machinery

Cows and ear tags

Underwater animals

Tại sao Detic có thể dự đoán nhiều class thế?
Mặc dù chỉ dùng bộ dữ liệu classifcation để improve module classification, nhưng tại sao module regression cũng cho thấy nó có thể bắt được đúng bounding box của chúng. Điều này có thể giải thích như sau: thông thường, với bộ dataset object detection, cả 2 module trên đều chỉ tập trung vào các class mà bộ dataset có. Còn với Detic, dường như qua quá trình training mixing cả 2 bộ data cùng một lúc, module classification đã cung cấp thông tin cho module regression rằng "ở đó có object đấy" và nhiệm vụ của module regression là phải refine lại bounding box của proposal sao cho bắt đúng được một vật thể, tách biệt với background.
Conclusions
Tác giả đã đề xuất Detic - một cách đơn giản tận dụng Image Classification dataset để cải thiện bài toán Large-vocabulary object detection so với các nghiên cứu trước đó. Tuy nhiên, việc mô hình cho thấy kết quả tốt trên open vocabulary không khẳng định được rằng nó sẽ tốt khi thực hiện trên các domain có sự khác biệt lớn. Điều đó nhóm tác giả sẽ nghiên cứu thêm ở tương lai. Nhìn chung, đây là một baseline tốt, nó cải thiện large-vocabulary detection với đa dạng các data sources, classifiers, detector architectures, training recipes khác nhau. Sự đơn giản của phương pháp này hứa hẹn sẽ được áp dụng nhiều trong production để cải thiện các SOTA trước đó.
References
- Detecting Twenty-thousand Classes using Image-level Supervision
- Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
- CLIP: Connecting text and images
🔗 Tìm hiểu về Pixta Vietnam:
Cập nhật tin tức mới nhất của Pixta Vietnam 👉 http://bit.ly/3kdkzvW
All rights reserved
