
[Handbook CV with DL - Phần 1] Các khái niệm cơ bản trong Computer Vision và Deep Learning
Bài đăng này đã không được cập nhật trong 7 năm
Computer Vision - thị giác máy tính (CV) là một ngành khoa học làm và ục đích của nó để hiểu hay xử lý các dữ liệu dạng hình ảnh và video. Computer Vision có rất nhiều các ứng dụng trong đó đáng kể có thể kể đến như ô tô tự lái, giám sát giao thông, nhận diện khuôn mặt ... Deep Learning là một trong những xu hướng tiếp cận của trí tuệ nhân tạo cho bài toán Computer Vision và nó có thể được phân loại trong nhiều bài toán như: phân loại ảnh (classification), nhận diện khoanh vùng đối tượng (object detection), phân vùng đối tượng (segmentation) và lớp các bài toán về sinh ảnh (generation).
 Trong series này mình mong muốn sẽ được chia sẻ những bài toán mà mình từng tiếp cận trong quá trình nghiên cứu và ứng dụng Deep Learning cho Computer Vision bao gồm các cách training một mô hình Deep Learning cho các bài toán Computer Vision cũng như các bước triển khai chúng trên môi trường thực tế. Hầu hết các ví dụ trong series này đều sử dụng Tensorflow và Keras để làm ví dụ. Tuy nhiên trong bài đầu tiên chúng ta sẽ đi nhanh qua một vài khái niệm rất cơ bản như sau:
Trong series này mình mong muốn sẽ được chia sẻ những bài toán mà mình từng tiếp cận trong quá trình nghiên cứu và ứng dụng Deep Learning cho Computer Vision bao gồm các cách training một mô hình Deep Learning cho các bài toán Computer Vision cũng như các bước triển khai chúng trên môi trường thực tế. Hầu hết các ví dụ trong series này đều sử dụng Tensorflow và Keras để làm ví dụ. Tuy nhiên trong bài đầu tiên chúng ta sẽ đi nhanh qua một vài khái niệm rất cơ bản như sau:
- Những thuật ngữ cơ bản trong Deep Learnng
- Tổng quan về các bài toán Computer Vision được xử lý bằng Deep Learning
- Hướng dẫn cài đặt môi trường phát triển ban đầu để thực hiện các ví dụ trong series này
- Giới thiệu về Tensorflow và một vài công cụ hỗ trợ của nó như Tensorboard hay Tensorflow Serving
OK không lan man nữa, giờ chúng ta sẽ bắt đầu vào bài viết ngay thôi.
Các khái niệm cơ bản trong Deep Learning
Computer Vision là một lĩnh vực có một lịch sử lâu dài chứ không phải mới xuất hiện gần đây.Tuy nhiên với sự bùng nổ xuất hiện của deep learning trong vài năm trở lại đây , thì các bài toán Computer Vision đã trở nên hữu ích cho các ứng dụng khác nhau. Vậy thì câu hỏi đặt ra là Deep Learning là cái gì mà lại có sức mạnh ghê gớm vậy. Ngày nay có rất nhiều người nói về công nghệ này tuy nhiên số người thực sự hiểu về nó không nhiều. Học sâu là tập hợp các kỹ thuật được xây dựng dựa trên nền tảng của mạng nơ ron nhân tạo - artificial neural network (ANN) mà chúng ta sẽ tìm hiểu kĩ hơn trong các phần tiếp theo. Deep Leanrng là một nhánh của Machine Learning và là một phần nhỏ trong các bài toán của lĩnh vực Trí tuệ nhân tạo - AI. Vậy một câu hỏi nữa các bạn có thể đặt ra - ANN hay mạng nơ ron nhân tạo thực sự là cái gì? Về cơ bản thì ANN được mô hình hóa dựa trên cách thức hoạt động của bộ não của con người (một phần rất nhỏ); với các nút (các nơ ron) liên kết với nhau (dây thần kinh) để truyền thông tin cho nhau. Trong các phần tiếp theo được trình bày sau đây, chúng ta sẽ thảo luận chi tiết về cách mà Deep Learning hoạt động bằng việc đi sâu tìm hiểu các thuật ngữ cơ bản thường được sử dụng nhé.
Perceptron
Một perceptron hay hiểu theo tiếng việt là một tế báo thần kinh là đơn giản là một hàm toán học nhận đầu vào từ một hoặc nhiều số, thực hiện các phép toán và trả về kết quả đầu ra. Các trọng số ẩn (weights) của perceptron - là thứ chúng ta đang đi tìm và chúng sẽ được xác định trong quá trình huấn luyên (training) dựa trên dữ liệu huấn luyện (training data). Có thể hình dung hoạt động của perceptron trong hình vẽ sau:
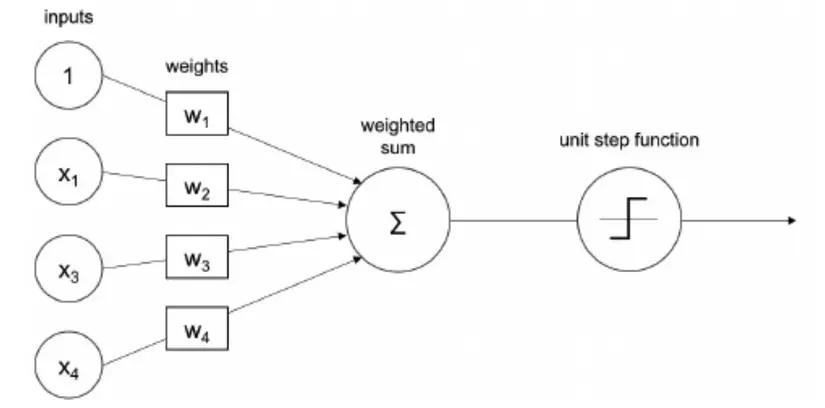
Trong đó chúng ta có thê thấy dữ liệu đầu vào được biểu diễn bởi vector và các trong số cần học được biểu diễn bởi vector , đi qua perceptron và kết quả đầu ra được trả thông qua một hàm gọi là unit step function trong trường hợp trên là binary. Mục đích của hàm này sử dụng để cho perceptron có thể ra được quyết định. Ví dụ bạn đang cần phân biệt khuôn mặt là nam hay nữ thì sau khi đưa khuôn mặt qua perceptron chúng ta sẽ tính toán và thu được một số thực (giả sử là 0.75) và tác dụng của unit step function là đặt ra một ngưỡng cho bạn lựa chọn. Chẳng hạn như lớn hơn 0.75 thì là nam, ngược lại thì là nữ .
Đây dược gọi là bài toán phân lớp nhị phân mà chúng ta sẽ tìm hiểu sâu hơn trong các phần tiếp theo. Tuy nhiên vấn đề quan trọng đó là perceptron chỉ có thể học được các hàm đơn giản bằng cách học các weights từ dữ liệu. Điều này được thực hiện bằng phương pháp gradient-based mà chúng ta cũng sẽ tìm hiểu trong các phần tiếp theo. Cũng như mình đã đề cập ở phía trên dầu ra của perceptron sẽ được đưa qua một hàm kích hoạt activation function hay còn gọi là một hàm chuyển đổi transfer function và phần tiếp theo chúng ta sẽ đi sâu tìm hiểu về chúng.
Hàm kích hoạt - activation functions
Hàm kích hoạt hay activation functions được sinh ra với mục đích bẻ gãy sự tuyến tính của mạng nơ ron. Các hàm này có thể hiểu đơn giản như một bộ lọc để quyết định xem thông tin có được đi qua nơ ron hay không. Trong quá trình huấn luyện mạng nơ ron, các hàm kích hoạt đóng vai trò quan trọng trong việc điều chỉnh độ dốc của đạo hàm. Một số hàm kích hoạt giống như sigmoid, tanh hay ReLU sẽ được bàn bạc kĩ hơn trong các phần tiếp theo. Tuy nhiên chúng ta cần hiểu rằng tính chất của các hàm phi tuyến này giúp cho mạng nơ ron có thể học được biểu diễn của các hàm phức tạp hơn là chỉ sử dụng các hàm tuyến tính. Hầu hết các activation functions là các continuous và khả vi differentiable functions Các hàm này là các hàm liên tục (continuous), tức là có sự thay đổi nhỏ ở kết quả đầu ra nếu như đầu vào có sự thay đổi nhỏ và khả vi (differentiable) tức là có đạo hàm tại mọi điểm trong miền xác định của nó. Tất nhiên rồi, như đã đề cập ở phía trên thì việc tính toán được đạo hàm là rất quan trọng và nó là một yếu tố quyết định đến nơ ron của chúng ta có thể training được hay không
NOTE: Đừng lo lắng nếu bạn không hiểu quá sâu về các thuật ngữ như liên tục và khả vi. Nó sẽ trở nên rõ ràng hơn qua các bài viết trong series này
Sau đây chúng ta sẽ tìm hiểu một số hàm kích hoạt thông dụng nhé
Sigmoid function
Sigmoid có thể được coi là một hàm được sử dụng để làm trơn dữ liệu và nó là một hàm khả vi. Sigmoid rất hữu ích để chuyển đổi bất kỳ giá trị nào thành xác suất và có thể được sử dụng để phân lớp nhị phân - binary classification. Hàm Sigmoid ánh xạ dữ liệu đầu vào thành giá trị trong khoảng 0..1. Chúng ta có thể viết công thức toán học của nó như sau
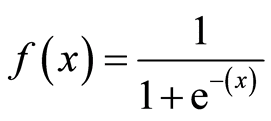
Kết quả đầu ra được thể hiện trong biểu đồ sau:
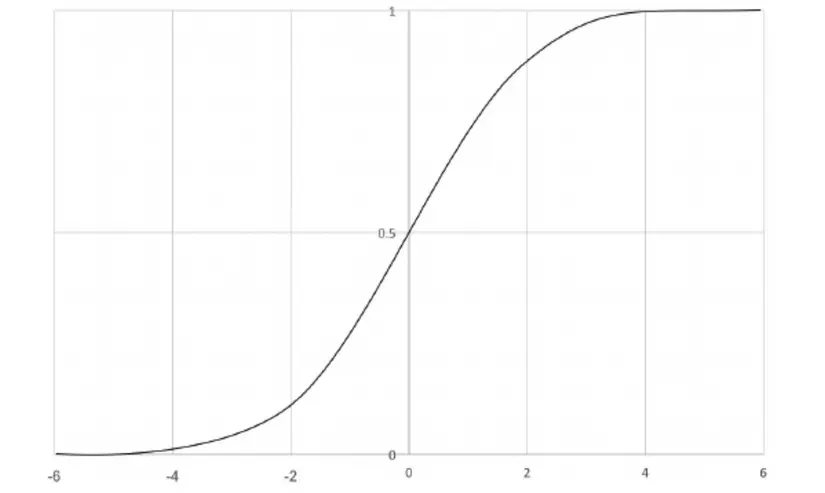
Giống như đã bàn luận ở trên việc thay đổi một giá trị nhỏ của X không làm thay đổi quá nhiều giá trị của Y điều này dẫn đến một hiện tượng mà trong Deep Learning gọi là biến mất đạo hàm hay vanishing gradients. Hiểu đơn giản thế này, chúng muốn tìm ra được các tham số của mạng nơ ron thì bắt buộc phải sử dụng đạo hàm và thay đổi tham số của mạng theo một chiều hướng nào đó giúp kết quả đạt được cao nhất. Tuy nhiên nếu như khi thay đổi tham số mà giá trị của đầu ra của mạng cũng thay đổi không đáng kể hay đạo hàm không có sự thay đổi nhiều và điều đó sẽ dẫn đến hiện tượng mạng của chúng ta không thể học được gì tốt hơn. Chúng ta sẽ bàn luận về vấn đề này khi tìm hiểu sâu hơn về cách training một mô hình Deep Learning. Còn bây giờ chúng ta sẽ tìm hiểu một hàm kích hoạt khác gọi là tanh được xem như là một biến thể của sigmoid để tránh vấn đề vanishing gradient
Tanh function
Hàm tiếp tuyến hyperbol, hay còn gọi là hàm tanh là một phiên bản thu nhỏ của sigmoid. Giống như người anh em của nó, tanh là một hàm liên tục và khả vi. Hàm này sẽ ánh xạ dữ liệu input vào trong khoảng từ -1 đến 1. Các bạn có thể hình dung trong hình sau:
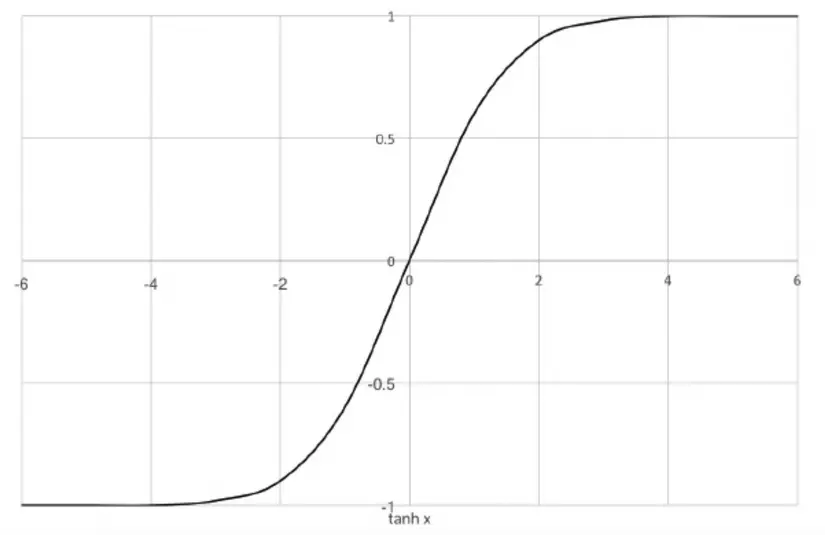
Đạo hàm của hàm này ổn định hơn hàm sigmoid và do đó nó tránh được một chút về vấn đề biến mất đạo hàm. Tuy nhiên cũng giống như sigmoid, hàm tanh được kích hoạt tại mọi điểm trong khoảng và chính vì điều đó làm cho mạng của chúng ta có số lượng tham số khủng và rất nặng khi training. Để khắc phục vấn đề đó người ta đưa ra một hàm kích hoạt khác có tên là Rectified Linear Unit (ReLU) sẽ được đề cập đến ngay sau đây.
Rectified Linear Unit (ReLU)
RELU được dựa trên tư tưởng của việc loại bỏ bớt những tham số không quan trọng trong quá trình training và điều đó là cho mạng của chúng ta trở nên nhẹ hơn và việc training cũng nhanh chóng và có hiệu quả hơn. Hàm này thực hiện một việc rât đơn giản như sau: giữ nguyên những giá trị đầu vào lớn hơn 0, nếu giá trị đầu vào nhỏ hơn 0 thì coi là 0. Chúng ta có thể hình dung kĩ hơn trong hình sau:
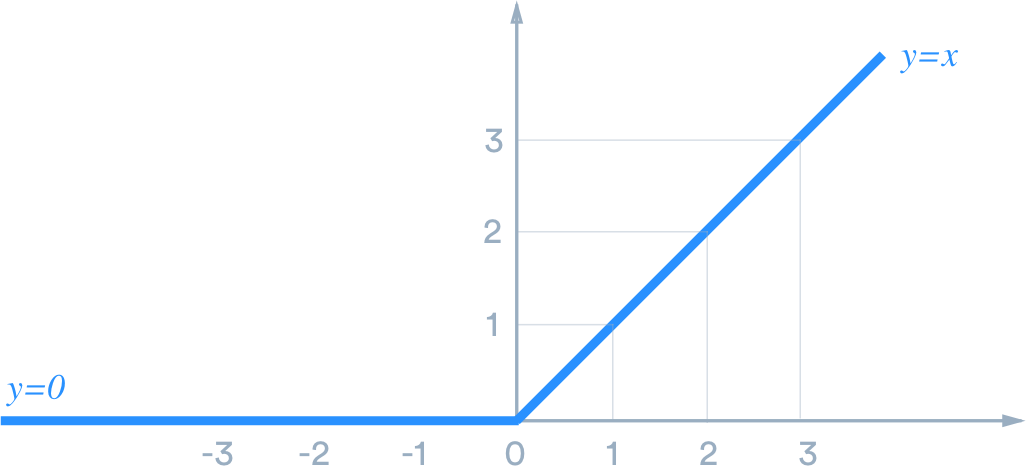 Bởi vì hàm ReLU trả về dữ liệu khác 0 trong mọi trường hợp nên điều đó làm mạng chúng ta đỡ phải training những dữ liệu không cần thiết và hơn nữa công thức của ReLU rất đơn giản khiến cho việc tính toán cũng trở nên dễ dàng hơn. Việc lựa chọn hàm kích hoạt đôi khi là kinh nghiệm của người xây dựng mạng và nó còn phụ thuộc khá nhiều ở bài toán mà chúng ta đang giải quyết. Tuy nhiên hàm ReLU hoạt động khá tốt cho phần lớn các bài toán trong Deep Learning. Chúng ta cũng có một vài biến thể của hàm này như ELU hay LeakyReLU các bạn cũng có thể tìm hiểu thêm. Trong phần tiếp theo, chúng sẽ tìm hiểu làm thế nào để xếp chồng một số perceptron lại với nhau để có thể học các hàm phức tạp hơn so với một perceptron đơn giản. Và đây chính là lý thuyết của mạng nơ ron nhân tạo - Artificial neural network (ANN).
Bởi vì hàm ReLU trả về dữ liệu khác 0 trong mọi trường hợp nên điều đó làm mạng chúng ta đỡ phải training những dữ liệu không cần thiết và hơn nữa công thức của ReLU rất đơn giản khiến cho việc tính toán cũng trở nên dễ dàng hơn. Việc lựa chọn hàm kích hoạt đôi khi là kinh nghiệm của người xây dựng mạng và nó còn phụ thuộc khá nhiều ở bài toán mà chúng ta đang giải quyết. Tuy nhiên hàm ReLU hoạt động khá tốt cho phần lớn các bài toán trong Deep Learning. Chúng ta cũng có một vài biến thể của hàm này như ELU hay LeakyReLU các bạn cũng có thể tìm hiểu thêm. Trong phần tiếp theo, chúng sẽ tìm hiểu làm thế nào để xếp chồng một số perceptron lại với nhau để có thể học các hàm phức tạp hơn so với một perceptron đơn giản. Và đây chính là lý thuyết của mạng nơ ron nhân tạo - Artificial neural network (ANN).
Artificial neural network (ANN)
Artificial neural network (ANN) có thể coi là một tập hơn của các perceptron và các hàm kích hoạt. Các perceptron đơn lẻ sẽ được kết hợp với nhau thành các lớp ẩn hidden layers hay units. Các lớp ẩn sử dụng các hàm kích hoạt phi tuyến ánh xạ các lớp đầu vào thành các lớp đầu ra trong một không gian có số chiều thấp hơn và được gọi chung là mạng nơ ron nhân tạo. ANN có thể hiểu là một hàm biến đổi (ánh xạ) từ đầu vào đến đầu ra. Ánh xạ này được tính bằng cách thêm và các ma trận trọng số của các đầu vào với các độ lệch biases. Các giá trị của ma trận trong số weights và giá trị của độ sai lệch biases tương ứng với kiến trúc được gọi là mô hình hay model
Quá trình training model là quá trình xác định các giá trị của các weights và biases. Các giá trị của chúng được khởi tạo với các giá trị ngẫu nhiên khi bắt đầu training. Muốn training chúng ta cần phải định nghĩa bằng hàm lỗi của mạng. Lúc này chúng ta sẽ nhắc đến hai giá trị đó là ground truth - tức là giá trị thực tế có trong tập dữ liệu huấn luyện và predict_output là giá trị mà mô hình dự đoán. Lỗi được tính bằng cách sử dụng hàm loss định nghĩa dựa trên sự khác nhau giữa hai giá trị này. Có nhiều kiểu định nghĩa hàm loss khác nhau mà chúng ta sẽ thực hiện trong series này. Làm đến phần nào chúng ta sẽ nói rõ hơn ở phần đó. Dựa trên gíá trị của hàm loss được tính toán, các trọng số weights được điều chỉnh tại mỗ bước trong quá trình training . Việc huân luyện mô hình được dừng lại khi lỗi không thể giảm thêm được nữa. Quá trình training thực chất là tìm ra các đặc trưng features trong dữ liệu đầu vào.. Các features này là một đại diện tốt hơn so với dữ liệu thô. Sau đây là sơ đồ của mạng nơ ron nhân tạo ANN hay perceptionron nhiều lớp
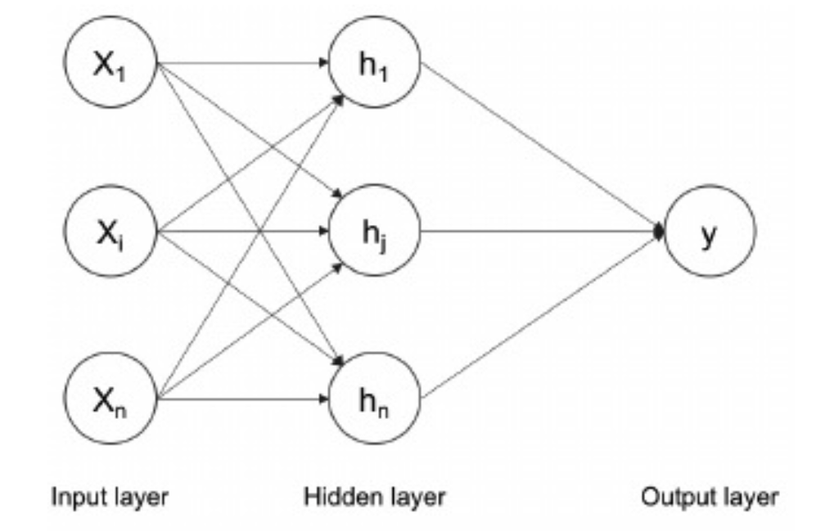
Một số đầu vào của dữ liệu x được chuyển qua một tập hợp các perceptron và xuất hiện ở đầu ra. Theo lý thuyết xấp xỉ vũ trụ - universal approximation theorem thì một mạng nơ ron có thể xấp xỉ mọi hàm phi tuyến. Tất nhiên là tuỳ thuộc vào số lượng các layers và số nodes của mạng. Lớp ẩn - the hidden layer hay thường gọi là dense layer - thường đi kèm với mỗi activation function để giúp giải quyết một số vấn đề về đạo hàm được bàn luận phía trên. Số lượng các tham số của mạng như số nơ ron trên mỗi layers, số layers trong mỗi mạng được lựa chọn tuỳ thộc vào bài toán. Ngoài ra để mạng nơ ron nhân tạo có thể hoạt động trên một bài toán phân loại nhiều lớp (lớn hơn 2 lớp) thì chúng ta cần có thêm một vài lý thuyết nữa sẽ được bàn luận trong phần tiếp theo.
Onehot Encoding
One-hot encoding là một cách để biểu diễn các biến hoặc các lớp đầu ra (target class) trong trường hợp các bài toán phân loại. Chúng ta có thể convert lớp đầu ra từ một chuỗi (string), một số (integer) thành dạng one-hot encoding. Một vectơ one-hot có chiều dài đúng bằng số lượng class cần phân loại và được fill 1 tại vị trí (index) của target class và 0 ở tất cả các vị trí khác. Ví dụ: nếu các lớp đầu ra của chúng ta là mèo và chó, chúng có thể được biểu thị bằng hai vector và tương ứng. Nếu chúng ta có 1000 class đầu ra thì vector one-hot sẽ có độ dài là 1000 với duy nhất 1 vị trí mang giá trị 1. Điều này làm cho one-hot encoding không đưa ra cho chúng ta giả định nào về sự tương quan của các biến đầu ra. Vậy một câu hỏi là tại sao chúng ta lại cần phải có one-hot encoding. Với hàm softmax được bàn luận trong phần tiếp theo thì one-hot encoding kết hợp với softmax sẽ khiến cho bài toán phân loại đa lớp (multi-class classification) trở nên khả thi trong mạng nơ ron nhân tạo. Chúng ta có thể xem xét một ví dụ sau trong sklearn
# Onehot encoding
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
label_enc = LabelEncoder()
values = ['dog', 'cat', 'fish']
label_enc.fit(values)
integer_encoded = label_enc.fit_transform(values)
print(integer_encoded)
onehot_encoder = OneHotEncoder(sparse=False)
integer_encoded = integer_encoded.reshape(len(integer_encoded), 1)
onehot_encoded = onehot_encoder.fit_transform(integer_encoded)
print(onehot_encoded)
Softmax
Softmax là một cách ràng buộc đầu ra của các mạng nơ ron phải có tổng bằng 1. Qua đó, các giá trị đầu ra của hàm softmax có thể được coi như là một phân phối xác suất của các biến đầu ra. Nó rất hữu ích trong bài toán phân loại đa lớp. Softmax là một loại của hàm kích hoat - activation function chúng ta đã bàn luận ở phần phía trên với điều đặc biệt đó là kết quả đầu ra của nó sẽ có tổng bằng 1. Để làm được điều này hàm softmax sẽ chuyển đổi giá trị đầu ra của mạng nơ ron bằng cách chia cho tổng giá trị. Lúc này đầu ra có thể coi là một vector của xác suất dự đoán của các class. Chúng ta có thể thấy rõ hơn trong công thức sau

Chúng ta có thể sử dụng khoảng các Euclid để so sánh khoảng cách giữa one-hot encoding và softmax nhằm phục vụ cho việc xây dựng hàm loss và tối ưu các tham số của mạng nơ ron. Tuy nhiên hàm cross entropy được bàn luận sau đây là một trong những hàm loss được sử dụng rất phổ biến và chứng minh được hiệu quả rõ rệt trong những bài toán phân loại đa lớp.
Cross entropy
Cross-entropy sử dụng để so sánh khoảng cách giữa các giá trị đầu ra của softmax và one-hot encoding. Cross-entropy là một hàm loss và giá trị của nó có thể được cực tiểu hoá (minimized). Điều này giúp cho một neural networks đánh giá được xác suất (độ chắc chắn) của phép dự đoán một mẫu dữ liệu tương ứng với một class. Xác suất sẽ là lớn nhất đối với biến mục tiêu của chúng ta. Cross entropy là tổng của các xác suất logarit âm. Chúng ta có thể định nghĩa nó theo công thức sau:
Hay triển khai bằng Python như sau:
# Cross entropy
import numpy as np
def cross_entropy(y_pred, y_target):
if y_target == 1:
return -np.log(y_pred)
else:
return -np.log(1 - y_pred)
Hàm logarit với giá trị âm được sử dụng để minimize hàm loss (maximize hàm logarit trong công thức tương ứng với việc minimize giá trị âm của nó). Trong phần tiếp theo chúng ta sẽ tìm hiểu một vài công thức để tránh về Overfitting trong ANN bao gồm:
- Dropout
- Batch normalization
- L1 and L2 normalization
Dropout
Dropout là một cách hiệu quả để thường được sử dụng để tránh tình trạng overfitting trong ANN. Hiện tượng Overfitting có thể được hiểu như mạng ANN của chúng ta học rất tốt trên tập training nhưng lại dự đoán rất kém trên tập test (dữ liệu chưa biết). Điều này còn gọi là hiện tượng học vẹt. Về cơ bản tư tưởng của Dropout đó chính là loại bỏ đi một vài units ẩn trong mạng nơ ron (một cách ngẫu nhiên) trong quá trình training. Nó có thể dược thể hiện trong hình sau:
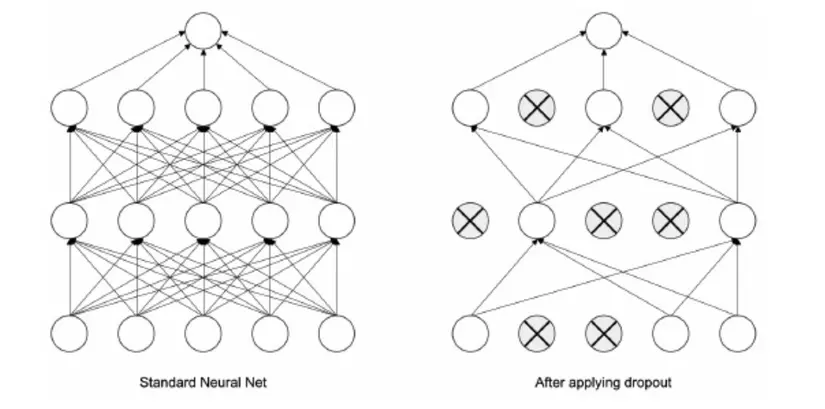
Trong quá trình training mô hình, dropout sẽ bỏ qua một số lượng neural được quy đinh bởi xác suất . Chúng ta có thể biểu diễn một mạng nơ ron truyền thẳng 2 lớp ẩn và 2 lớp dropout như sau:
p = 0.5 # probability of keeping a unit active. higher = less dropout
def train_step(X):
""" X contains the data """
# forward pass for example 3-layer neural network
H1 = np.maximum(0, np.dot(W1, X) + b1)
U1 = np.random.rand(*H1.shape) < p # first dropout mask
H1 *= U1 # drop!
H2 = np.maximum(0, np.dot(W2, H1) + b2)
U2 = np.random.rand(*H2.shape) < p # second dropout mask
H2 *= U2 # drop!
out = np.dot(W3, H2) + b3
# backward pass: compute gradients... (not shown)
# perform parameter update... (not shown)
Một lưu ý là Dropout không được sử dụng trong quá trình dự đoán của mạng vì không cần thiết. Tuy nhiên trong quá trình dự đoán chúng ta cần phải scale giá trị đầu ra của các hidden layers đã dropout với xác suất . Ví dụ trong trường hợp này tức là xác suất để một neural được training (giá trị đầu ra khác 0) là . Chúng ta xét riêng một neural x bất kì thì giá trị đầu ra của neural đó khi áp dụng dropout là bởi vì đầu ra nơ ron sẽ được đặt thành 0 với xác suất . Chính vì trong quá trình test chúng ta đã sử dụng toàn bộ các neural nên giá trị đầu ra của nó phải được scale từ thành . Lúc này chúng ta có hàm predict như sau:
def predict(X):
# ensembled forward pass
H1 = np.maximum(0, np.dot(W1, X) + b1) * p # NOTE: scale the activations
H2 = np.maximum(0, np.dot(W2, H1) + b2) * p # NOTE: scale the activations
out = np.dot(W3, H2) + b3
L2 regularization
Đây có lẽ là hình thức phổ biến nhất của regularization. Nó có thể được thực hiện bằng cách thêm vào bình phương giá trị của tất cả các tham số một đại lượng phạt . Theo đó với mỗi giá trị weight trong mạng sau khi được tính toán chúng ta sẽ add thêm một đại lượng vào giá trị đầu ra và được gọi là đại lượng phạt lỗi regularization strength. L2 sẽ phạt rất nặng các vector trọng số có giá trị lớn giúp cho các weight ở trong mạng không có sự phân tán quá nhiều. Cả dạng chuẩn L2 và L1 mà chúng ta sẽ tìm hiểu dưới đây đều đựa trên một giả thuyết rằng một mô hình với các gía trị weights nhỏ hơn thì tốt hơn trong thực tế.
L1 regularization
Đây cũng là một dạng chuẩn khác thi thoảng cũng được sử dụng trong các bài toán Deep Learning. Nó được thực hiện bằng cách thêm vào giá trị tuyệt đối của các tham số một đại lượng phạt tức là mỗi giá trị đầu ra của mạng sẽ được thêm vào một lượng . Một điểm tốt của L1 đó là nó sẽ biến các thuộc tính rất noise ban đầu trở nên sparse trong quá trình tối ưu. Và do đó giúp chúng ta giữ lại được các thuộc tính quan trọng của dữ liệu. Có nhiều mạng sử dụng kết hợp cả hai dạng chuẩn L2 và L1 các bạn có thể tham khảo tại Elastic net regularization. Tuy nhiên, trên thực tế, nếu không quan tâm đến việc lựa chọn thuộc tính thì, việc chuẩn hóa L2 kì vọng sẽ mang lại hiệu suất vượt trội so với L1.
Phương pháp training một mạng nơ ron
Như chúng ta đã thảo luận phía bên trên, mục đích của việc training môt mạng nơ ron nhân tạo tức là chúng ta sẽ tìm ra được một tập các tham số tối ưu cho bài toán của mình từ các dữ liệu đầu vào. Việc đó tương đương với các thao tác tính toán và cập nhật các trong số - weights. Công việc tính toán và cập nhật các trọng số đó được gọi là lan truyền ngược - backpropagation. Thủ tục để cực tiểu hóa hàm lỗi - loss function được gọi là tối ưu hóa - optimization.. Chúng ta sẽ cùng nhau tìm hiểu từng khái niệm này nhé:
Backpropagation
Thuật toán lan truyền ngược - Backpropagation là một trong những thuật toán cốt lõi của mạng nơ ron hiện đại. Như chúng ta đã biết từ trước thì việc huán luyện và tối ưu một mạng MLP được thực hiện bằng giải thuật Gradient Descent tức là tối ưu dựa trên đạo hàm. Muốn như vậy chúng ta sẽ cần phải tính toán được đạo hàm của từng ma trận trọng số trong quá trình training. Tuy nhiên việc tính toán trực tiếp giá trị đạo hàm ngay từ các layer đầu là một việc cực kì khó khăn bởi vì hàm mất mát sẽ không phụ thuộc đơn lẻ vào trọng số của layer đó. Backpropagation là một thuật toán lấy tư tưởng bằng việc tính đạo hàm từ cuối sau đó lan truyền giá trị này dần vào trong các layers phía trên của mạng nơ ron thông qua quy tắc của chain rule - đạo hàm hàm hợp. Chúng ta có thể hình dung bước cập nhật trong số như sau:
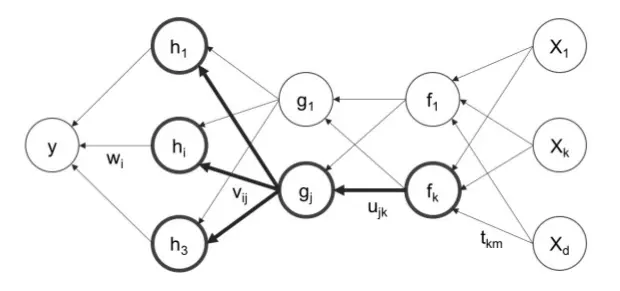
Sau khi tính toán được hàm lỗi thì giải thuật gradient descent có thể được sử dụng để cập nhật lại các trọng số của mạng sao cho cực tiểu hóa giá trị hàm lỗi. Chúng ta sẽ nói về phần này tiếp sau đây
Gradient descent
Đây là một giải thuật sử dụng trong tối ưu trong không gian nhiều chiều - multidimensional optimization. Mục đích của nó là có thể đạt đến tối ưu toàn cục - global maximum (dù trên lý thuyết là như vậy nhưng thực tế chúng ta không bao giờ có thể biết được đâu là tối ưu toàn cục). Đây là một giải thuật sử dụng rất nhiều trong các bài toán về Machine Learning và đặc biệt hữu ích khi training neural network. Một trong những phiên bản của GD đó chính là stochastic gradient descent (SGD) và trở nên rất phổ biến trong neural network. Quá trình tối ưu sẽ tính toán giá trị của hàm lỗi và cập nhật các trọng số để đạt được hàm lỗi nhỏ nhất hay đi ngược lại với dấu của đạo hàm sẽ dẫn đến điểm tối ưu. Quá trình đó được mô phỏng trong hình sau:
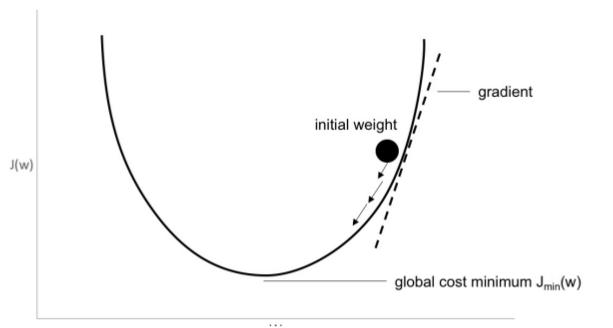
Trong GD có một đại lượng rất quan trọng đó chính là tốc độ học - learning rate. Đại lượng này quy định xem việc thuật toán của chúng ta sẽ học nhanh hay chậm và ảnh hưởng đến khả năng chúng ta có thể tìm kiếm được điểm tối ưu nhất hay không. Nếu learning rate quá nhỏ thì thuật toán có thể học chậm và đôi khi không thể vượt qua được điểm tối ưu cục bộ. Nếu quá lớn thì thuật toán có thể thoát khỏi tối ưu cục bộ nhưng lại rất khó có thể đạt được điểm tối ưu do đạo hàm bị thay đổi quá lớn. Chúng ta có thể hình dung quá trình đó trong hình sau:

Dựa trên tư tưởng của Gradient descent tuy nhiên SGD chỉ sử dụng một phần của dữ liệu gọi là mini-batch để thực hiện tối ưu trong quá trình training. Điều này làm cho quá trình tối ưu được nhanh hơn và làm cho mạng dễ dàng hội tụ hơn so với việc tính toán trên toán bộ dữ liệu. Trong phần tiếp theo chúng ta sẽ tìm hiểu về các kiến trúc mạng phổ biến được sử dụng trong Deep Learning.
Các kiến trúc mạng phổ biến trong Deep Learning
Convolutional neural network
Convolutional neural networks (CNN) cũng tương tự như các kiến trúc mạng MLP được mô tả phía trên của bài viết tức là cũng bao gồm các weights, biases, và các activation function được sử dụng để biến đổi dữ liệu tuyến tính về dạng phi tuyến. Trong các kiến trúc mạng chính thống thì mỗi neural trong một layer được kết nối theo kiểu fully connected - kết nối đầy đủ đến các neural của layers tiếp theo. Tất cả các nơ ron thuộc cùng một layers không share bất kì một kết nối nào. Một nhược điểm của mạng này là số lượng kết nối sẽ trở nên khổng lồ nếu như kích thước của từng layers là lớn và nó không phù hợp cho các dữ liệu giống như ảnh. Điều đó dẫn đến khái niệm overfitting trên toàn bộ dữ liệu học. Nếu như ảnh chúng ta có kích thước lớn thì việc sử dụng mô hình mạng chính thống lại càng làm cho số lượng các tham số trở nên lớn hơn. Với đặc thù của dữ liệu ảnh, một image có thể chứa giá trị thuộc 3 thuộc tính là height, width, và depth. Trong đó Depth được gọi là channel của image có thể là red, blue, và green. Mạng CNN được thiết kế với tư tưởng tích chập các input layers để làm đầu vào cho layers tiếp theo. Việc chuyển đổi đó thực hiện trên mỗi layer và được thể hiện trên hình sau:
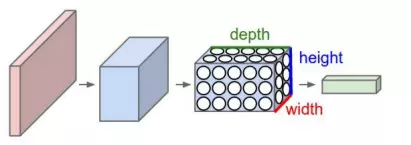
Các lớp CNN được sử dụng để trích chọn ra các đặc trưng và partern trong image. Các số lượng tham số được sử dụng trong mạng CNN được chứng minh là nhỏ hơn rât nhiều so với mạng fully connected và hiểu quả mạng lại thường là cao hơn nhiều so với các phương pháp trước đó. Chúng ta sẽ tìm hiểu chi tiết về hai khái niệm cơ bản trong CNN trong phần tiếp theo bao gồm: Kernel, Max pooling:
Kernel
Kernel có thể được coi là tham số của mô hình CNN và được sử dụng để tính toán tích chập - convolve trên ảnh. Chúng ta có thể thấy thao tác tích chập được mô tả trong hình sau:
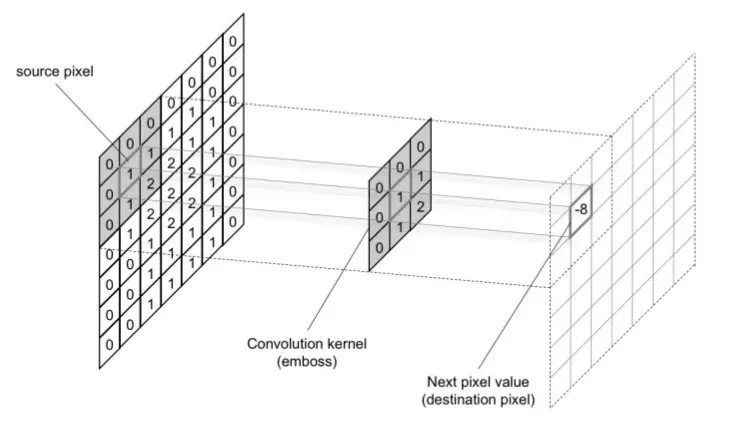 Tức mỗi phần của image sẽ được nhân tích chập với kernel để tạo thành một ma trận mới - làm input cho layer tiếp theo. Một kernel có hai tham số cần quan tâm đến đó là stride và size. Size là kích thước của một kernel (có thể là kích thước của một hình chữ nhật bất kì) và stride là số bước nhảy của kernel. Nếu stride bằng 1 thì gần như toàn bộ pixel trên ảnh sẽ được trượt qua và tính tích chập. Nếu stride bằng 2 chúng ta cứ cách 2 pixel lại tính tích chập một lần và như vậy số lượng pixel của ảnh đầu ra bị giảm đi một nửa so với stride = 1. Padding image có thể giúp số chiêu của ảnh đầu ra giống với ảnh input.
Tức mỗi phần của image sẽ được nhân tích chập với kernel để tạo thành một ma trận mới - làm input cho layer tiếp theo. Một kernel có hai tham số cần quan tâm đến đó là stride và size. Size là kích thước của một kernel (có thể là kích thước của một hình chữ nhật bất kì) và stride là số bước nhảy của kernel. Nếu stride bằng 1 thì gần như toàn bộ pixel trên ảnh sẽ được trượt qua và tính tích chập. Nếu stride bằng 2 chúng ta cứ cách 2 pixel lại tính tích chập một lần và như vậy số lượng pixel của ảnh đầu ra bị giảm đi một nửa so với stride = 1. Padding image có thể giúp số chiêu của ảnh đầu ra giống với ảnh input.
Max pooling
Là một layer được thêm vào giữa các lớp convolution với mục đích là giảm kích thước của layers thông qua việc lấy mẫu - sampling. Việc lấy mẫu này thực hiện bằng cách lấy giá trị lớn nhất trong cửa sổ pooling được chọn. Ngoài ra chúng ta cũng có thể bắt gặp khai niệm Average pooling tức là lấy mẫu bằng cách lấy giá trị trung bình của tất cả các giá trị trong cửa sổ pooling. Pooling được xem là một trong những kĩ thuật giúp giảm hiện tượng overfitting trong CNN Chúng ta có thê hình dung hoạt động của nó trong hình sau:
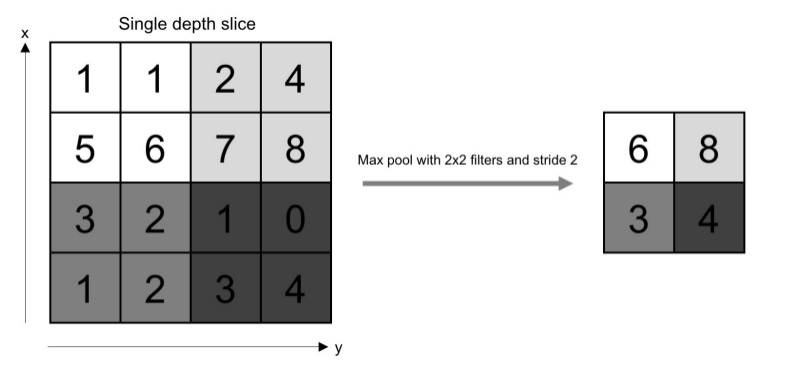
CNN là một trong những mô hình rất quan trọng trong Deep Leanring và đặc biệt hữu dụng đối với các bài toán liên quan đến hình ảnh. Có thể nói rằng nếu không có sự ra đời của CNN thì ngành Computer Vision khó mà có được những thành tựu như ngày hôm nay.
Recurrent neural networks (RNN)
Recurrent neural networks (RNN) là một mô hình đặc biệt hữu ích cho dữ liệu dạng sequential information. Mô hình này không xem xét các đặc trựng dựa trên độ sâu của một điểm dữ liệu mà tập trung vào sự liên kết giữa các điểm dữ liệu để tạo thành một chuỗi - sequence. Mạng RNN thực hiện cùng một nhiệm vụ đối với một chuỗi các điểm dữ liệu. Trong mỗi step của RNN, dữ liệu đầu ra của step trước đó được kết hợp với dữ liệu của step hiện tại. Điều đó giúp cho mỗi step của RNN chứa thông tin hiện tại và thông tin của dữ liệu tại thời điểm trước đó. Nó cũng có thể xem như một hình thức của bộ nhớ tuy nhiên bộ nhớ của RNN không có khả năng ghi nhớ những dữ liệu quá xa. Đây được gọi là vấn đề phụ thuộc xa và được giải quyết bằng những kiến trúc mạng khác chúng ta sẽ tìm hiểu ở các phần tiếp theo trong series này. Mô tả hoạt động của RNN có thể được diễn giải trong hình sau:
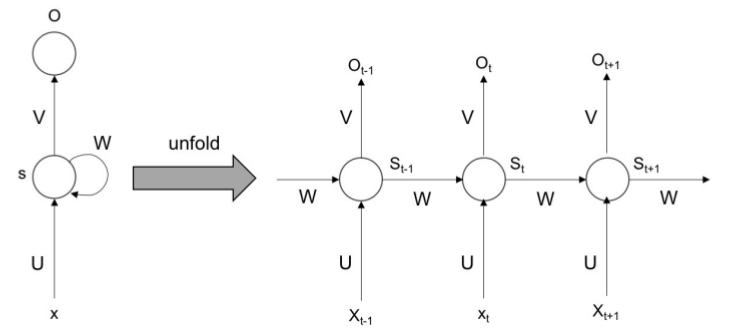
Long short-term memory (LSTM)
Long short-term memory (LSTM) là một kiến trúc dựa trên RNN được sinh ra để giải quyết vấn đề phụ thuộc xa được nêu ra phía trên. Tức là LSTM có thể lưu được thông tin từ những điểm dữ liệu cách xa điểm dữ liệu hiện tại.
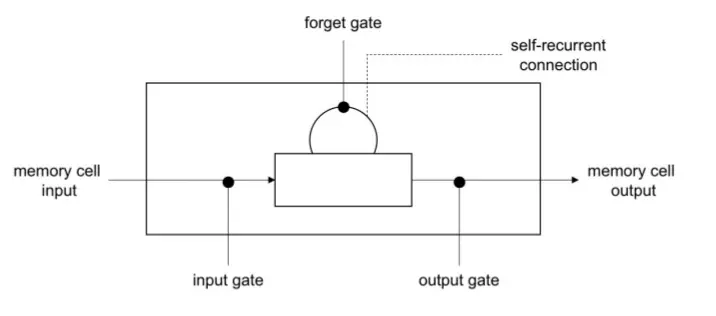
Để làm được điều đó LSTM thực hiện thêm vào mô hình RNN một số cổng bao gồm cổng forget, cổng input, và cổng output. Cổng quên có nhiệm vụ giữ lại các thông tin cần thiết trong các trạng thái trước đó. Cổng input thực hiện cập nhật trạng thái hiện tại với dữ liệu đầu vào hiện tại. Cổng output sẽ quyết định xem dữ liệu nào sẽ được truyền qua mạng cho trạng thái tiếp theo. Chính khá năng lưu trữ lại những thông tin quan trọng và loại bỏ đi những thông tin không cần thiết giúp cho LSTM giải quyết được vấn đề phụ thuộc xa trên dữ liệu.
Các bài toán Computer Vision trong Deep Learning
Classification - phân loại
Classification là một trong những nhiệm vụ cơ bản nhất của Computer Vision. Mục đích của nó là đưa ra một nhãn (còn gọi là class hay label) tương ứng với mỗi image kèm theo một chỉ số confidence (dộ chắc chắn). Ứng dụng của nó có thể kể đến như phân loại dộng vật (chó mèo, gà vịt, ngan ngỗng...), phân loại giới tính, nhận dạng mặt người.
 Trong series này mình sẽ có một phần viết riêng về bài toán nhận dạng này.
Trong series này mình sẽ có một phần viết riêng về bài toán nhận dạng này.
Detection or localization and segmentation
Detection hay localization là một trong những nhiệm vụ nhằm tìm kiếm đối tượng trong một hình ảnh đồng thời khoanh vùng - localizes - đối tượng đó bằng một hộp chữ nhật gọi là bounding box. Bài toán này có rất nhiều ứng dụng như trong tracking đối tượng, tìm kiếm đối vật, hay xe tự lái. Chúng ta có thể hình dung nó trong hình ảnh sau:
Segmentation lại là một nhiệm vụ khác cho phép thực hiện phân loại dựa trên pixel. Rất hữu dụng trong các bài toán như phân tách làn đường, tìm vật cản trong ô tô tự lái.
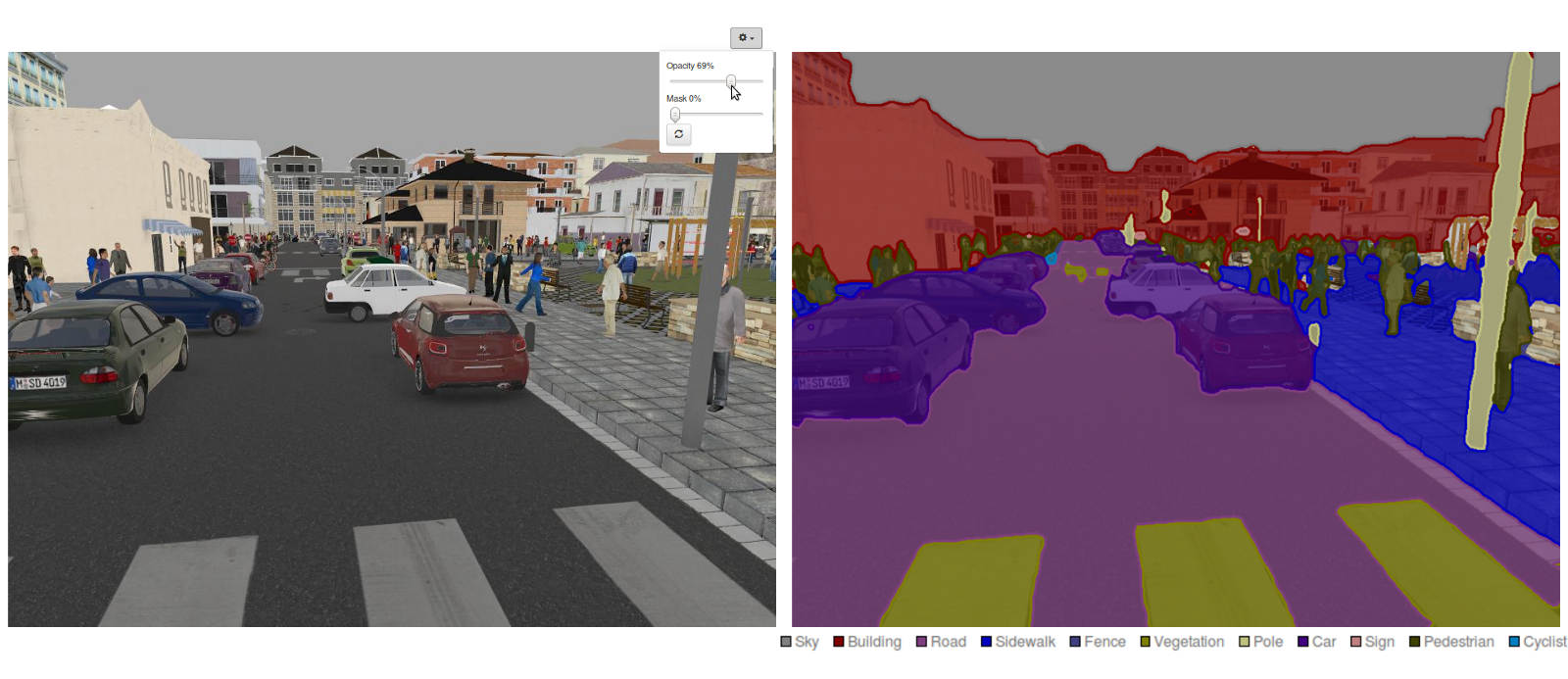 Trong series này mình cũng sẽ có một bài để hướng dẫn chi tiết về Segmentation và Detection sau.
Trong series này mình cũng sẽ có một bài để hướng dẫn chi tiết về Segmentation và Detection sau.
Similarity learning
Là một trong những nhiệm vụ giúp mạng nơ ron học được sự tương đồng giữa hai image. Điểm số có thể được sử dụng để làm độ đo sự tương đồng giữa hai image dựa trên ngữ nghĩa hoặc dựa trên các đặc trưng của hình ảnh. Bài toán này rât hữu dụng trong thực tế giúp tìm kiếm các sản phẩm tương tự hoặc trong nhận dạng mặt người:
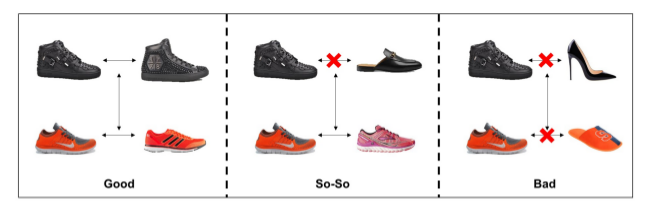
Image captioning
Là một trong những ứng dụng kết hợp Computer Vision và NLP, mục đích của nó là mô tả nội dung của hình ảnh.

Mô hình sinh - Generative models
Mô hình sinh là một trong những ứng dụng hết sức thú vị chúng ta có thể tìm hiểu trong Computer Vission. Mục đích của nó để sinh ra những dữ liệu ảnh mới từ dữ liệu ảnh gốc theo một dạng nào đó. Một trong những ứng dụng nổi tiếng của nó như Style Transfer:

Tổng kết
Trên đây chúng ta đã tiến hành phân tích những khái niệm cơ bản cần phải biết trước khi bước vào qua trình xử lý Computer Vission trong Deep Learning. Các bạn nên nắm chắc các khái niệm cơ bản này để việc follow các bài viết tiếp theo trong series này được dễ dàng hơn. Hẹn gặp lại các bạn trong các bài viết tiếp theo.
All rights reserved
