
[Paper Explain] Deformable DETR: Transformer kiểu mới cho bài toán Object Detection
Bài đăng này đã không được cập nhật trong 3 năm
1. Giới thiệu chung
Trong bài viết lần trước mình đã giới thiệu về DETR một hướng tiếp cận mới cho bài toán Object Detection để hiểu một cách chọn vẹn Deformable DETR mình khuyến nghị mọi người nên đọc bài viết về DETR của mình trước https://viblo.asia/p/object-detection-with-transfromer-detr-eW65GpmjKDO. Mặc dù hướng tiếp cận khá hay nhưng DETR vẫn còn một số vấn đề như:
- DETR có kết quả khá tệ trong việc phát hiện các đối tượng nhỏ. Các mô hình object detection gần đây sử dụng high-resolution feature map sẽ tốt hơn cho việc phát hiện đối tượng nhỏ. tuy nhiên, high-resolution feature map sẽ làm độ phức tạp của self-attention trong DETR encoder tăng rất nhiều (self-attention DETR encoder có độ phức tạp là bình phương của feature map size).
- DETR tốn khá nhiều epochs để hội tụ. Lý do chính bởi vì attention module xử lý image features khá khó để train.
2. Transformer và DETR
2.1. Multi-Head Attention trong Transformer
Giả sử ta có một query element (cụ thể là một từ ở trong câu output) và một tập các key element (là các từ ở câu input), multi-head attetion mudule tổng hợp các key contents tương ứng với key element theo một trọng số attention weight (được học trong quá trình training). Multi-head attetion được tác giả viết lại bằng công thức dưới đây.
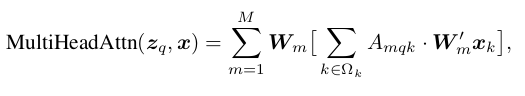
Trong đó:
- là một query element và là feature tương ứng với nó, trong đó là feature dimmension (tương tự như trong Attetion is All you need);
- M là số attention head;
- là một key element và là feature tương ứng, ;
- là attention weight của query thứ tới key thứ tại head; và , là những tham số được học trong quá trình training.
Giả sử số query elements và số key elements lần lượt là . Độ phức tạp của thuật toán là . Số query element và số key element đều là số pixel trên feature map, vậy nên . Cuối cùng, độ phức tạp của thuật toán sẽ là . Độ phức tạp của thuật toán sẽ là bình phương của feature map size.
2.2. DETR
Như bài trước mình cũng đã giới thiệu thì DETR được xây dựng dựa trên kiến trúc của Transformer. Sự dụng bipartite matching và thuật toán Hungrarian để map giữa prediction box và ground-truth box.
Với Transformer encoder, thì số key elements và số query elements đều là số pixel trên feature map. giả sử chiều dài và chiều rộng của feature map lần lượt là . Độ phức tạp của thuật toán self attention là . Độ phức tạp của thuật toán có độ phức tạp là bình phương của spatial size.
Với Transformer decoder, đầu vào là feature map từ encoder và N object query (learnable positional embeddings). Có 2 kiểu attention trong transformer decoder là cross-attention và self-attention. Trong cross-attention , độ phức tạp của thuật toán là độ phức tạp là tuyến tính của feature map size. Trong self-attention, object query tương tác với nhau độ phức tạp của thuật toán là .
3. Deformable Transformer
Transformer attention thông thường thực hiện attention trên toàn bộ feature map nó dẫn đến độ phức tạp của thuật toán tăng cao khi spatial size của feature map tăng. Tác giả đưa ra một kiểu attention mới mà chỉ attend vào một số sample locations (sample locations này cũng không cố định mà được học trong quá trình training tương tự như trong deformable convolution) qua đó giúp giảm độ phức tạp của thuật toán và làm giảm thời gian training mô hình.
3.1 Deformable Attention Module
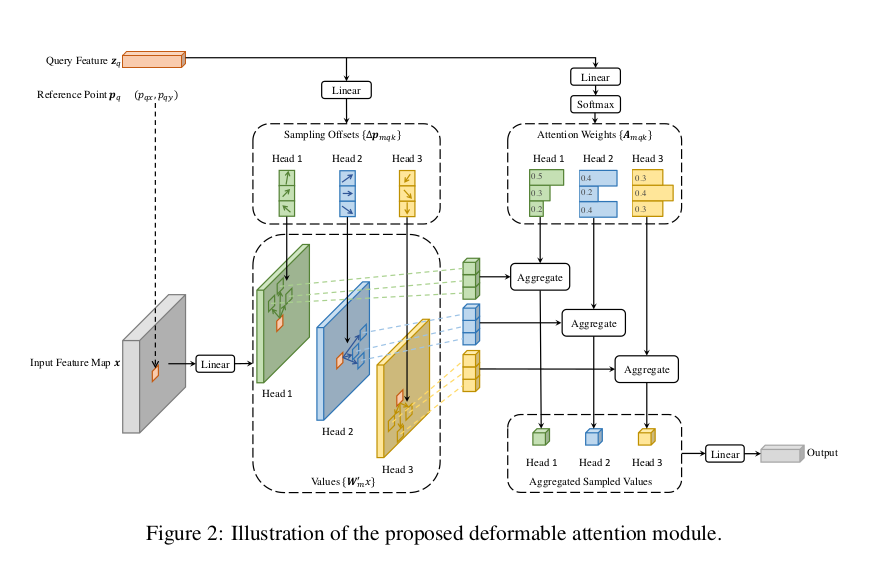 Giả sử đầu vào là feature map là , là 1 query element và là content feature tương ứng với và là 2-d reference point, deformable attention được tính bởi công thức dưới đây
Giả sử đầu vào là feature map là , là 1 query element và là content feature tương ứng với và là 2-d reference point, deformable attention được tính bởi công thức dưới đây
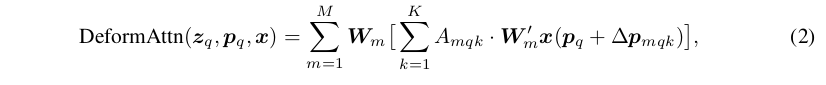
là sampling ofset. Cả và đều được tính thông qua lớp linear từ .
Hình minh họa phía trên giúp ta dễ hiểu hơn, ở giữa là quá trình dự đoán ra sampling offsets (), và bên phải cùng là quá trình dự đoán ra attention weight () cho từng sampling points và .
Độ phức tạp của thuật toán deformable attention là
3.2 Multi-scale Deformable Attention Module.
 là số layers multi-scale feature map, là tọa độ đã được chuẩn hóa, và hàm sẽ chuẩn hóa tương ứng với feature map thứ l. Multi-scale deformable attention khá tương đồng so với deformable attention ngoại từ việc nó lấy ra điểm từ multi-scale feature map thay vì điểm từ single-scale feature map.
là số layers multi-scale feature map, là tọa độ đã được chuẩn hóa, và hàm sẽ chuẩn hóa tương ứng với feature map thứ l. Multi-scale deformable attention khá tương đồng so với deformable attention ngoại từ việc nó lấy ra điểm từ multi-scale feature map thay vì điểm từ single-scale feature map.
 Khi và là ma trận đơn vị ta có thể coi multi-scale deformable attentio
n là phép deformable convolution trên mỗi attention head.
Khi và là ma trận đơn vị ta có thể coi multi-scale deformable attentio
n là phép deformable convolution trên mỗi attention head.
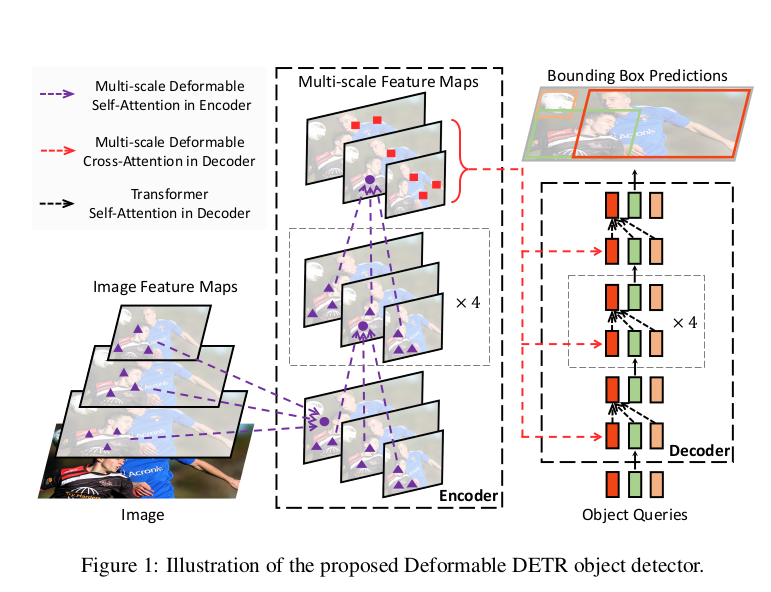
3.3 Deformable Attention Encoder.
Đầu vào và đầu ra của encoder đều là multi-scale feature maps có cùng độ phân giải. Multi-scale deformable attention module được sử dung thay cho transformer attention modules trong DETR. Multi-scale feature map từ đến của ResNet được sử dụng.
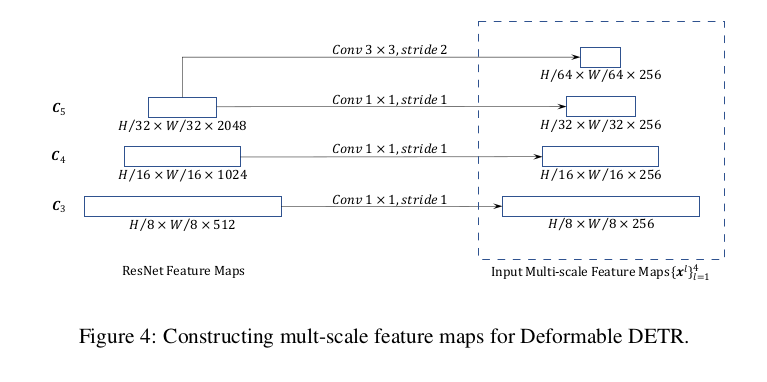
3.4 Deformable Attention Decoder.
Có 2 kiểu attention trong Decoder là cross-attetion và self-attention. Query elements ở trong cả 2 kiểu attention là Object Query. Chỉ có cross-attention module được thay bởi multi-scale deformable attention module và self-attention module vẫn giữ nguyên. Multi-scale deformable attention module sẽ extract image features xung quanh reference points, bounding boxes sẽ được dự đoán dựa vào việc dự đoán offset với reference points. Reference points có thể coi như là dự đoán ban đầu của tâm bounding box.
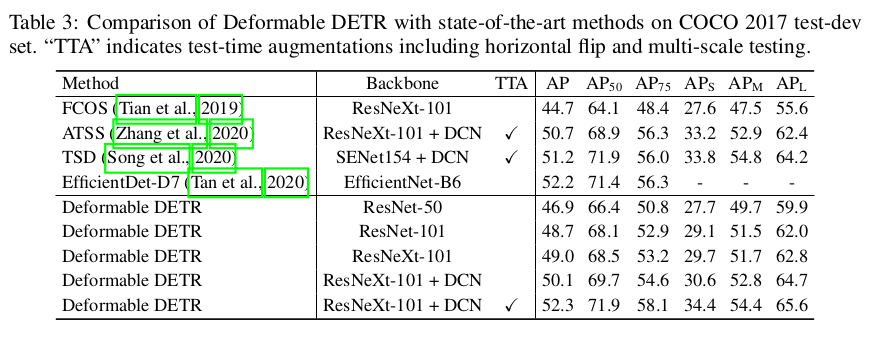
4. Kết quả
 Từ hình minh họa ta có thể thấy là Deformabled DETR để ý vào lề bên phải và lề bên trái để dự đoán tọa độ x và chiều rộng, để ý vào phía trên và dưới để dự đoán tọa độ y và chiều cao, và để ý và pixel phía trong đối tượng để dự đoán class.
Từ hình minh họa ta có thể thấy là Deformabled DETR để ý vào lề bên phải và lề bên trái để dự đoán tọa độ x và chiều rộng, để ý vào phía trên và dưới để dự đoán tọa độ y và chiều cao, và để ý và pixel phía trong đối tượng để dự đoán class.
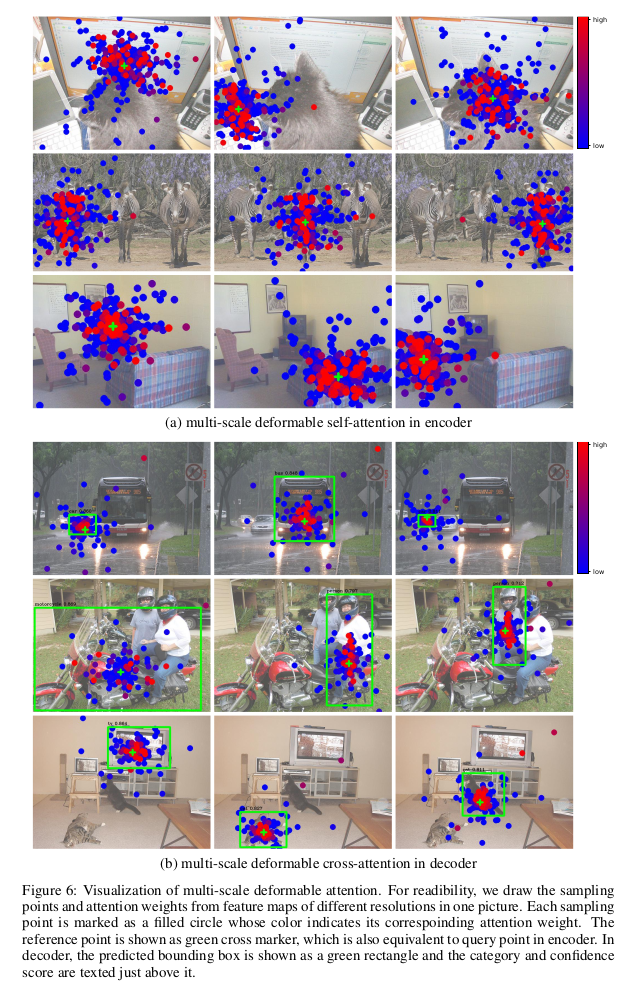
Sampling points và attention weights tương ứng ở lớp cuối cùng trong encoder và decoder cũng được minh họa trong hình phía trên.
5. Personal Comment
Khi tìm hiểu về Deformable DETR cũng giúp mình hiểu hơn về self-attetion, vision transformer cũng như là DETR. Bằng việc đưa ra 2 khái niệm mới là Multi-scale Deformabled Attention và reference point Deformable DETR đã giải quyết được một số vấn đề còn tại của DETR là độ phức tạp thuật toán ở encoder quá cao, đồng thời cũng tăng đáng kể performance và cũng là tiền để tác tác giả phía sau tiếp tục cải tiến. Bài viết phía sau mình sẽ tiếp tục giới thiệu về DAB DETR cũng như là DINO sota của object detection hiện tại.
6. Tham khảo
Deformable DETR https://arxiv.org/pdf/2010.04159.pdf
DETR https://arxiv.org/pdf/2005.12872.pdf
Attention is All You Need https://arxiv.org/pdf/1706.03762.pdf
All rights reserved
