Ứng dụng Convolutional Neural Network trong bài toán phân loại ảnh
Bài đăng này đã không được cập nhật trong 4 năm
Tiếp nối series về Machine Learning, hôm nay sẽ là 1 bài viết về Convolutional Neural Network. Nếu mọi người theo dõi series Machine Learning của mình, thì sẽ thấy nó khá ... lủng củng, bởi tự dưng đang Supervised Learning, Unsupervised Learning, rồi đến ứng dụng Machine Learning trong các bài toán thực tế. Thực chất mình cũng rất mong muốn làm thành 1 series đầy đủ, kiểu như khóa Machine Learning của Andrew Ng =)) Nhưng kiến thức bản thân có hạn, đồng thời các bài toán mình đưa ra bị ảnh hưởng khá nhiều bởi 1 khóa Deep Learning mà mình đang theo học, và hôm nay cũng là 1 bài toán như thế: Ứng dụng CNN trong bài toán phân loại ảnh (Image Classification).
Nếu các bạn làm việc với Deep Learning nhiều thì chắc không còn xa lạ gì với CNN. Đây là một Structure rất phổ biến và quen thuộc trong Deep Learning. CNN được ứng dụng nhiều trong Computer Vision, Recommender System, Natural Language Processing, ... Ví dụ như tự động nhận diện khi chúng ta up một ảnh lên Facebook, hay khi tôi search một từ bất kì lên google search, ví dụ "Mèo" thì trong tab "Hình ảnh", google sẽ hiển thị rất nhiều ảnh có mèo trong đó. Làm thế nào mà họ làm được điều đó. Vâng, tất nhiên là tôi không biết họ làm thế nào. Nhưng chúng ta hoàn toàn có thể làm được như họ với CNN. Ứng dụng của tôi ngày hơn này thì đơn giản hơn khá nhiều, đó là phân loại khuôn mặt, hiểu đơn giản là nhìn vào 1 bức ảnh thì nó phải "biết" đây là ai.
Kiến Thức Liên Quan
Mình sẽ tóm tắt một vài kiến thức mình sử dụng trong bài. Và để hiểu được các kiến thức này thì bạn nên có một quá trình làm việc với machine learning, deep learning hay CNN, bởi nếu nhắc lại tất cả các kiến thức trên thì bài viết này sẽ rất dài, mà lý thuyết lại không phải cái mà mình muốn tập trung ở đây. Đầu tiên, với Convolutional Neural Network, đây là một deep neural network artritecture. Hiểu đơn giản, nó cũng chính là một dạnh Artificial Neural Network, một Multiplayer Perceptron nhưng mang thêm 1 vài cải tiến, đó là Convolution và Pooling.
Convolution
Thực chất mình không biết phải giải thích khái niệm mới này trong CNN thế nào cho chính xác nhất. Theo ý hiểu của mình, convolution gồm 2 khái niệm khác là Convolution Filter và Convolutional Layer. Trong mạng neural network thông thường, từ input, ta cho qua các hidden layer rồi ra được output. Với CNN, Convolutional Layer cũng chính là hidden layer, khác ở chỗ, Convolutional Layer là một tập các feature map và mỗi feature map này là một bản scan của input ban đầu, nhưng được trích xuất ra các feature/đặc tính cụ thể. Scan như thế nào thì lại dựa vào Convolution Filter hay kernel. Đây là một ma trận sẽ quét qua ma trận dữ liệu đầu vào, từ trái qua phải, trên xuống dưới, và nhân tương ứng từng giá trị của ma trận đầu vào mà ma trận kernel rồi cộng tổng lại, đưa qua activation funciton (sigmoid, relu, elu, ... ), kết quả sẽ là một con số cụ thể, tập hợp các con số này lại là 1 ma trận nữa, chính là feature map.
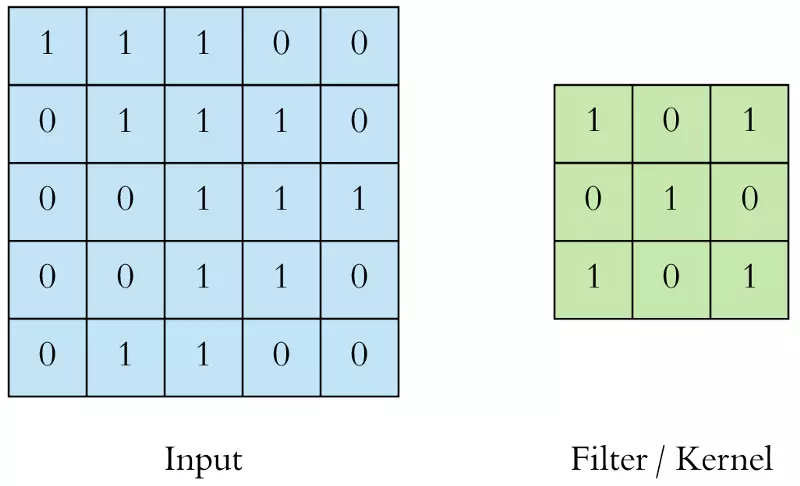
Hãy nhìn vào ví dụ sau cho dễ hiểu:
Tôi có 1 ma trận đầu vào input và 1 kernel
Tôi sẽ quét kernel qua từng phần tử của input. Và tính toán như trên: nhân tương ứng, rồi cộng tổng kết quả, đưa qua activation function (ta bỏ qua bước này trong ảnh động biểu diễn dưới đây), ta thu được một giá trị tại feature map
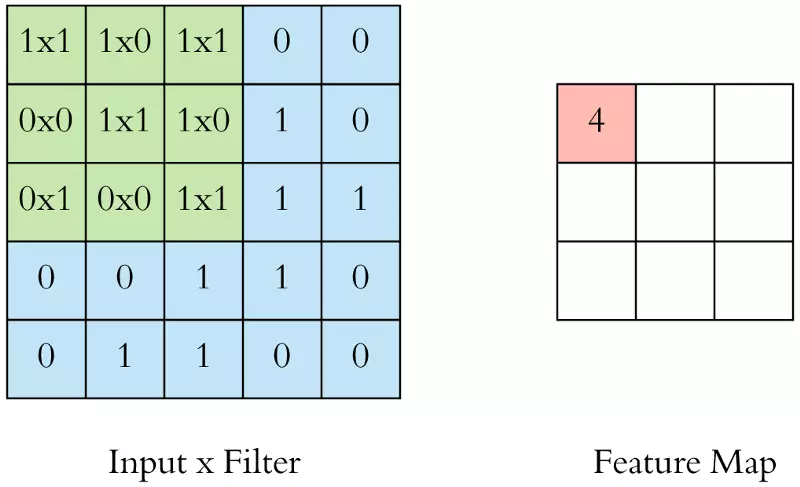
Thực hiện lần lượt cho đến hết.

Ở đây nhiều người sẽ thắc mắc: các giá trị của kernel lấy ở đâu ra. Vâng, tôi cũng không biết là lấy ở đâu ra, nhưng sở dĩ sinh ra các giá trị này là bởi ta muốn trích xuất một đặc tính / feature nào đó của input. Dựa vào đó sẽ thu được kernel tương ứng. Ví dụ, tôi apply 3 kernel để thu được 3 feature riêng biệt từ input ban đầu:
Convolution Sharpen

Convolution Edge Enhance

Convolution Edge Detect

Và cũng đừng lo việc phải tìm bao nhiêu kernel hay lưu các kernel về để dùng dần. Đó là việc của CNN, nó sẽ tự động tìm các kernel, tự dò ra các feature, It's cool ha 
Stride and Padding
Stride là khoảng cách giữa 2 kernel khi quét. Với stride = 1, kernel sẽ quét 2 ô ngay cạnh nhau, nhưng với stride = 2, kernel sẽ quét ô số 1 và ô số 3. Bỏ qua ô ở giữa. Điều này nhằm tránh việc lặp lại giá trị ở các ô bị quét.
Stride = 1

Stride = 2

Chúng ta chọn stride và size của kernel càng lớn thì size của feature map càng nhỏ, một phần lý do đó là bởi kernel phải nằm hoàn toàn trong input. Có một cách để giữ nguyên kích cỡ của feature map so với ban đầu. Đấy là Padding. Khi ta điều chỉnh padding = 1, tức là ta đã thêm 1 ô bọc xung quanh các cạnh của input, muốn phần bọc này càng dày thì ta cần phải tăng padding lên. Hãy nhìn vào ví dụ sau, ta xét padding = 1:
 Phần màu xám chính là phần bọc thêm vào input
Phần màu xám chính là phần bọc thêm vào input
Với stride=1 và padding=0, từ bức ảnh input ban đầu, ta sẽ quét kernel qua và tạo thành các ô như sau để map thành feature map

Pooling
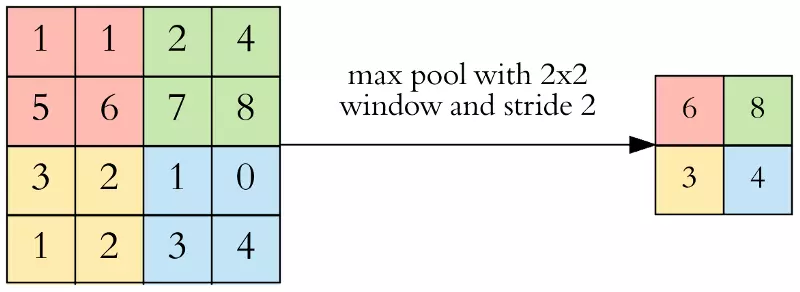
Mục đích của pooling rất đơn giản, nó làm giảm số hyperparameter mà ta cần phải tính toán, từ đó giảm thời gian tính toán, tránh overfitting. Loại pooling ta thường gặp nhất là max pooling, lấy giá trị lớn nhất trong một pooling window. Pooling hoạt động gần giống với convolution, nó cũng có 1 cửa sổ trượt gọi là pooling window, cửa sổ này trượt qua từng giá trị của ma trận dữ liệu đầu vào (thường là các feature map trong convolutional layer), chọn ra một giá trị từ các gía trị nằm trong cửa sổ trượt (với max pooling ta sẽ lấy giá trị lớn nhất).
Hãy cùng nhìn vào ví dụ sau, tôi chọn pooling window có kích thước là 2 * 2, stride = 2 để đảm bảo không trùng nhau, và áp dụng max pooling:
Fully Connected
Nếu bạn hiểu thế nào là 1 Neural Network thì có lẽ nhắc lại khái niệm Fully Connected có vẻ hơi thừa. Bởi layer này cũng chính là 1 fully connected ANN. Thường thì sau các lớp Conv+Pooling thì sẽ là 2 lớp Fully connected, 1 layer để tập hợp các feature layer mà ta đã tìm ra, chuyển đổi dữ liệu từ 3D, hoặc 2D thành 1D, tức chỉ còn là 1 vector. Còn 1 layer nữa là output, số neuron của layer này phụ thuộc vào số output mà ta muốn tìm ra. Giả sử với tập dữ liêu MNIST chẳng hạn, ta có tập các số viết tay từ 0 -> 9. Vậy output sẽ có số neuron là 10.
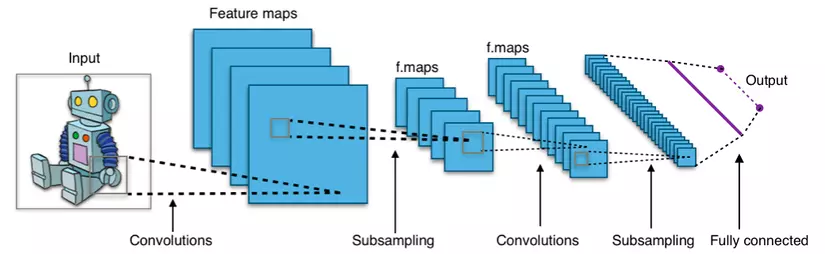
CNN Structure
Hình vẽ dưới đây đã biểu diễn rất rõ ràng kiến trúc của 1 mạng CNN
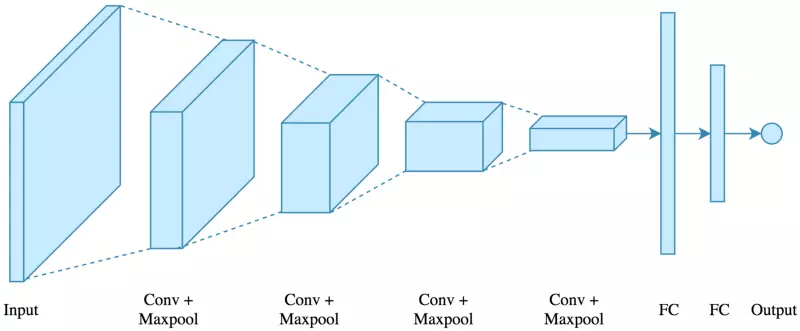 Ta có ảnh input đầu vào.
Qua hàng loạt các Convolutional Layer cùng Max Pool Layer (thường pooling sẽ theo ngay sau 1 convolutional layer), cuối cùng là 2 fully connected.
Ta có ảnh input đầu vào.
Qua hàng loạt các Convolutional Layer cùng Max Pool Layer (thường pooling sẽ theo ngay sau 1 convolutional layer), cuối cùng là 2 fully connected.
Ứng Dụng
Ok, sau phần kiến thức khá dài dòng thì chúng ta sẽ đến ngay với phần ứng dụng. Mình sẽ đi luôn vào phần code mà mình đã viết. Khởi đầu sẽ là load các thư viện cần thiết.
import sys
import numpy as np
import matplotlib.pyplot as plt
import glob
import math
import tensorflow as tf
import cv2
import os
Tiếp theo là load dữ liệu, mình có 1 tập các ảnh đã được align và cắt phần mặt (thực ra cái này là của thầy giáo đưa cho ). Mình sẽ load tất cả các ảnh này, resize lại kích cỡ là 96 * 96 rồi reshape lại thành 1 vector có 9126 phần tử.
Kết quả ta thu trược x_train, y_train chứa dữ liệu training còn x_test, y_test chứa dữ liệu test.
image_size = 96
def load_sequence(folder):
sequence_folder = glob.glob(os.path.join(folder, '*/*'))
X = []
name = []
for sq in sequence_folder:
#print (sq)
peron_name = sq.split('/')[-2]
list_images_file = glob.glob(os.path.join(sq, '*.jpg'))
for filename in list_images_file:
img = cv2.imread(filename,0)
img = cv2.resize(img, (image_size, image_size))
img=np.reshape(img, image_size*image_size)
X.append(img)
name.append(peron_name)
return np.asarray(X), np.asarray(name)
x_train,y_train=load_sequence('data/Face/Train')
x_test,y_test=load_sequence('data/Face/Test')
print (x_train.shape) #(17102, 9216)
print (x_test.shape) #(9760, 9216)
Có một điều cần lưu ý ở đây, cả y_train và y_test đều chứa dữ liệu dạng text, chính là tên của người có khuôn mặt tương ứng ở tập x_train. Vì vậy mình sẽ viết thêm 1 đoạn code để chuyển đổi các giá trị text của y_train và y_test sang số
from sklearn.preprocessing import LabelEncoder
labelencoder_X=LabelEncoder()
y_train = labelencoder_X.fit_transform(y_train)
y_test=labelencoder_X.transform(y_test)
print (y_train) #[10 10 10 ..., 22 22 22]
Ta sẽ thiết lập các giá trị parameter và hyperparameter cho CNN. Mình sẽ giải thích các tham số và biến này ở phần sau.
# Training Parameters
num_steps = 500
batch_size = 128
display_step = 10
# Network Parameters
num_input = image_size * image_size
num_classes = 27
# tf Graph input
x = tf.placeholder(tf.float32, [None, num_input])
y = tf.placeholder(tf.int32, [None])
Ngoài ra ta sẽ cần thêm 2 hàm hỗ trợ cho việc thực thi mini-batch và tạo neural network
def random_batch(x_train, y_train, batch_size):
rnd_indices = np.random.randint(0, len(x_train), batch_size)
x_batch = x_train[rnd_indices]
y_batch = y_train[rnd_indices]
return x_batch, y_batch
# Create the neural network
def conv_net(x):
with tf.variable_scope('ConvNet'):
x = tf.reshape(x, shape=[-1, image_size, image_size, 1])
conv1 = tf.layers.conv2d(x, 8, 5, activation=tf.nn.relu)
conv1 = tf.layers.max_pooling2d(conv1, 4, 4)
conv2 = tf.layers.conv2d(conv1, 16, 5, activation=tf.nn.relu)
conv2 = tf.layers.max_pooling2d(conv2, 4, 4)
conv3 = tf.layers.conv2d(conv2, 32, 3, activation=tf.nn.relu)
conv3 = tf.layers.max_pooling2d(conv3, 2, 2)
fc1 = tf.contrib.layers.flatten(conv3)
fc1 = tf.layers.dense(fc1, 256)
out = tf.layers.dense(fc1, num_classes)
return out
Ở đây tôi sẽ khởi tạo network với pred = conv_net(x), thiết lập hàm mất mát cost function cost, ném hàm này vào giải thuật AdamOptimizer, AdamOptimizer cũng giống như Gradient Descent, tìm ra bộ tham số mà để minimize cost function cost. Ở đây tôi không truyền learning_rate hay 1 vài tham số khác vào AdamOptimizer, bởi phần tối ưu sẽ được tôi nhắc đến sau.
Phần code phía dưới tìm correct và accuracy để đánh giá độ chính xác của mạng CNN.
Và cuối cùng là dòng code khởi tạo các variable trong tensorflow
pred = conv_net(x)
xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=pred, labels=y)
cost = tf.reduce_mean(xentropy)
optimizer = tf.train.AdamOptimizer()
training_op=optimizer.minimize(cost)
correct = tf.nn.in_top_k(pred, y, 1)
accuracy = tf.reduce_mean(tf.cast(correct, tf.float32))
# Initializing the variables
init = tf.global_variables_initializer()
Ok, về cơ bản là như thế. Giờ ta sẽ truyền giá trị vào x, y và chạy thôi.
sess= tf.Session()
best_accuracy = 0
consecutive_accuracy = []
n_epochs = 50
sess.run(init)
for step in range(1, num_steps+1):
x_batch, y_batch = random_batch(x_train, y_train, batch_size)
sess.run(training_op, feed_dict={x: x_batch, y: y_batch})
if step % 10 == 0:
acc = sess.run( accuracy, feed_dict={x: x_batch,y: y_batch})
print('Step:',step, ', Accuracy:',acc)
print("Optimization Finished!")
Step: 10 , Accuracy: 0.109375
Step: 20 , Accuracy: 0.09375
Step: 30 , Accuracy: 0.132812
Step: 40 , Accuracy: 0.140625
Step: 50 , Accuracy: 0.265625
Step: 60 , Accuracy: 0.25
Step: 70 , Accuracy: 0.289062
Step: 80 , Accuracy: 0.234375
Step: 90 , Accuracy: 0.304688
Step: 100 , Accuracy: 0.476562
Step: 110 , Accuracy: 0.367188
Step: 120 , Accuracy: 0.484375
Step: 130 , Accuracy: 0.476562
...................................................
Step: 440 , Accuracy: 0.640625
Step: 450 , Accuracy: 0.695312
Step: 460 , Accuracy: 0.671875
Step: 470 , Accuracy: 0.734375
Step: 480 , Accuracy: 0.65625
Step: 490 , Accuracy: 0.671875
Step: 500 , Accuracy: 0.703125
Optimization Finished!
Ở đây độ chính xác của dữ liệu training còn khá thấp, một phần bởi dữ liệu ta chưa được train đủ số lần, từ đó nó chưa tìm ra được các feature cần thiết để phân biệt các face. Tôi sẽ apply epoch and batch vào đây xem thế nào:
n_epoch = 50
n_batches = len(x_train) // batch_size
sess.run(init)
for epoch in range(n_epochs):
for step in range(n_batches):
x_batch, y_batch = random_batch(x_train, y_train, batch_size)
sess.run(training_op, feed_dict={x: x_batch, y: y_batch, training: True})
acc = sess.run(accuracy, feed_dict={x: x_batch, y: y_batch})
print('Epoch:', epoch, ', Accuracy:', acc)
print("Optimization Finished!")
Epoch: 0 , Accuracy: 0.83
Epoch: 1 , Accuracy: 0.93
Epoch: 2 , Accuracy: 0.95
Epoch: 3 , Accuracy: 0.96
Epoch: 4 , Accuracy: 1.0
Epoch: 5 , Accuracy: 0.97
Epoch: 6 , Accuracy: 0.99
Epoch: 7 , Accuracy: 1.0
Epoch: 8 , Accuracy: 1.0
Epoch: 9 , Accuracy: 0.98
Epoch: 10 , Accuracy: 1.0
Epoch: 11 , Accuracy: 0.99
............................................
Epoch: 45 , Accuracy: 1.0
Epoch: 46 , Accuracy: 1.0
Epoch: 47 , Accuracy: 0.99
Epoch: 48 , Accuracy: 1.0
Epoch: 49 , Accuracy: 1.0
Optimization Finished!
Best Accuracy: 1.0
Testing Accuracy: 0.744365
Train accuracy đạt 100%, còn test accuracy đạt 0.74, không tệ.
Kết Luận
Độ chính xác được cải thiện khá nhiều, tôi đã tiến hành chạy thử khá nhiều lần, và đa phần test accuracy dao động từ 0.7 -> 0.78 Nhằm cải thiện độ chính xác của tập test hơn nữa. Tôi sẽ áp dụng thêm một vài kĩ thuật nữa: data augmentation, dropout, ... Nhưng do phần data augmentation phải thử và cải thiện khá nhiều, nên hẹn gặp lại các bạn vào phần 2 của bài viết. Xin cám ơn. Nếu có bất cứ câu hỏi gì, hãy post trong phần comment, tôi sẽ trả lời.
Tài liệu tham khảo
https://buzzrobot.com/whats-happening-inside-the-convolutional-neural-network-the-answer-is-convolution-2c22075dc68d https://towardsdatascience.com/applied-deep-learning-part-4-convolutional-neural-networks-584bc134c1e2 https://medium.com/@ageitgey/machine-learning-is-fun-part-3-deep-learning-and-convolutional-neural-networks-f40359318721
All rights reserved
