Upscale ảnh với một mạng CNN đơn giản
Bài đăng này đã không được cập nhật trong 4 năm
Bài viết sau đây sẽ trình bày về bài toán upscale ảnh (tăng độ phân giải của ảnh) và một phương pháp upscale ảnh bằng cách sử dụng mô hình deep learning đơn giản có tên là SRCNN (Super Resolution Convolutional Neural Network).
1. Bài toán upscale ảnh
Cho ảnh là một ảnh high-resolution (độ phân giải cao) và là một phiên bản low-resolution (độ phân giải thấp) của . Gọi hàm được dùng để upscale ảnh input là . Bài toán upscale ảnh sẽ hướng đến việc tìm sao cho hay ảnh upscale từ gần giống nhất có thể. Đây là một vài các phương pháp truyền thống phổ biến có thể dùng để upscale ảnh:
- Nearest-neighbor interpolation (nội suy láng giềng gần nhất): là phương pháp đơn giản nhất. Trong phương pháp này, các pixel trong ảnh sẽ dùng giá trị của pixel trong ảnh gần nó nhất.
- Bilinear interpolation (nội suy song tuyến): phương pháp này sẽ nội suy giá trị của một pixel bằng cách tính trung bình có trọng số 4 (2x2) pixel lân cận.
- Bicubic interpolation (nội suy song khối): tương tự như bilinear interpolation nhưng với 16 (4x4) pixel lân cận.
- Lanczos interpolation (nội suy Lanczos): sử dụng thuật toán tính trung bình giá trị pixel bằng hàm sin.
Giả sử với ảnh gốc sau:

- Ảnh low-resolution:
 Sau khi downscale ảnh gốc xuống 4 lần và chạy từng phương pháp upscale về resolution gốc, ta có được kết quả như sau:
Sau khi downscale ảnh gốc xuống 4 lần và chạy từng phương pháp upscale về resolution gốc, ta có được kết quả như sau:
- Nearest-neighbor interpolation:

- Bilinear interpolation:

- Bicubic interpolation:

- Lanczos interpolation:

Tuy nhiên, các thuật toán này lại có nhược điểm là ảnh output khá mờ, bị răng cưa, ringing artifact... Trong đó, nhược điểm khá lớn đó là các thuật toán này không thể restore lại được các chi tiết có trong ảnh gốc. Bằng việc sử dụng deep learning, các chi tiết trên sẽ được các mạng CNN thêm vào bằng cách đoán các giá trị pixel mà nó thấy phù hợp nhất. Để biết được pixel nào là hợp lý nhất, mạng CNN này sẽ phải được train với rất nhiều ảnh. Ngoài ra, các ảnh mà nó được train sẽ cần phải có chung kiểu với ảnh cần predict để model có thể hoạt động tốt. Ví dụ, một mạng CNN được train trên dataset gồm các ảnh có style của anime sẽ predict tốt với ảnh cùng style anime nhưng lại kém với ảnh ngoài đời thật.
2. SRCNN
Bài viết này sẽ tìm hiểu về một mạng CNN đơn giản tên là SRCNN được dùng để upscale ảnh. Đây là mạng CNN sẽ được dùng để học end-to-end mapping giữa ảnh low res và high res. Link bài báo: https://arxiv.org/abs/1501.00092.
Cấu trúc mạng SRCNN rất đơn giản. Nó chỉ có 3 layer tất cả: patch extraction and representation, non-linear mapping và reconstruction.
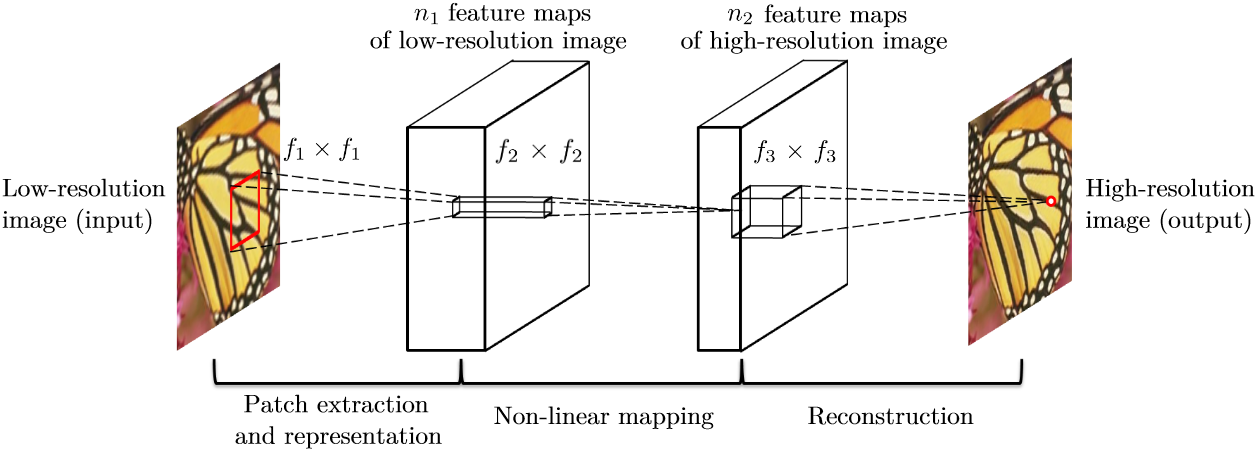
Trong mạng SRCNN, ảnh input () sẽ là ảnh low-resolution nhưng lại được upscale nên bằng phương pháp bicubic interpolation để cho kích thước bằng ảnh groundtruth ().
2.1 Patch extraction and representation
Layer đầu tiên này sẽ có nhiệm vụ lấy các patch (mảnh) overlap nhau ở trên ảnh input bằng cách trượt một kernel có kích thước cố định ở trên ảnh. Sau đó, nó biểu diễn feature map của từng patch dưới dạng một vector nhiều chiều. Số lượng feature map sẽ tương ứng với số chiều của vector. Phép toán được thực hiện ở layer đầu tiên là:
trong đó, là các filter, là các bias và là phép tích chập. sẽ có tất cả filter với kích thước với là số lượng channel của ảnh đầu vào (thường là 3 với ảnh màu, 1 với ảnh grayscale). Hàm có thể coi như là một layer ReLU. Output của layer này là một vector chiều tương ứng với feature map.
2.2 Non-linear mapping
Sau khi lấy được vector feature của ảnh low-resolution, ta sẽ cho nó qua layer tích chập thứ hai. Layer này có nhiệm vụ lấy map (ánh xạ) vector chiều ở layer trước tới một vector chiều. Phép toán được thực hiện ở layer này là:
trong đó, là các filter, là các bias của layer này. sẽ có tất cả filter với kích thước với là số lượng channel của ảnh đầu vào (thường là 3 với ảnh màu RGB và 1 với ảnh grayscale). Output của layer này là một vector chiều ứng với feature map. Mỗi một feature map trong vector này sẽ là biểu diễn của một high-resolution patch được dùng để khôi phục ảnh.
Theo tác giả bài báo, chúng ta có thể thêm nhiều layer hơn ở giữa để tăng tính phi tuyến tính (non-linearity). Tuy nhiên, việc tăng số lượng layer lên sẽ làm mô hình trở nên phức tạp hơn và tốn nhiều thời gian train để mô hình hội tụ. Đồng thời, kết quả trong bài báo cho thấy việc tăng số lượng layer (lớn hơn tổng 3 layer của cả model) cũng không làm tăng đáng kể chất lượng của output nên trong phần cài đặt, bài viết này sẽ chỉ cài đặt một layer ở giữa.
2.3 Reconstruction
Layer cuối này sẽ được dùng để khôi phục ảnh high-resolution từ vector chiều ở layer trước. Phép toán được thực hiện ở layer này là:
gồm filter có kích thước . Kết quả của layer này sẽ là ảnh đã được upscale, có kích thước bằng kích thước ảnh input (do ảnh kích thước đã được upscale từ đầu).
2.4 Hàm loss
Hàm loss được dùng để train mạng SRCNN là MSE:
với là số sample được dùng để train. Việc dùng hàm MSE sẽ giúp tối đa hóa được PSNR (Peak Signal-to-Noise Ratio hay Tỉ số tín hiệu cực đại trên nhiễu). PSNR được dùng để đo chất lượng tín hiệu khôi phục của các thuật toán. PSNR càng cao thì chất lượng dữ liệu khôi phục được càng tốt.
3. Cài đặt và kết quả
Theo như bài báo, phần cài đặt, tác giả để các tham số lần lượt là: , , , và . Tuy nhiên, do size của output khi dùng tham số này lại khác so với size của input (đã được upscale 4x dùng bicubic interpolation), không thuận tiện cho việc training nên trong phần cài đặt, mình sẽ cho tăng lên . Đây là link notebook colab chứa code cài đặt và train model. Model có thể được cài đặt khá đơn giản chỉ với vài dòng code:
class SRCNN(nn.Module):
def __init__(self, num_channels=1):
super().__init__()
# Patch extraction and representation
self.conv1 = nn.Conv2d(num_channels, 64, 9, 1, 4)
self.relu1 = nn.ReLU(inplace=True)
# Non-linear mapping
self.conv2 = nn.Conv2d(64, 32, 5, 1, 2)
self.relu2 = nn.ReLU(inplace=True)
# Reconstruction
self.conv3 = nn.Conv2d(32, num_channels, 5, 1, 2)
# Initialize weight
nn.init.normal_(self.conv1.weight.data, mean=0.0, std=0.001)
nn.init.zeros_(self.conv1.bias.data)
nn.init.normal_(self.conv2.weight.data, mean=0.0, std=0.001)
nn.init.zeros_(self.conv2.bias.data)
nn.init.normal_(self.conv3.weight.data, mean=0.0, std=0.001)
nn.init.zeros_(self.conv3.bias.data)
def forward(self, x):
x = self.relu1(self.conv1(x))
x = self.relu2(self.conv2(x))
x = self.conv3(x)
return x
Do số lượng dataset của tác giả bài báo khá ít (chỉ có 91 ảnh) và việc downscale ảnh xuống 4 lần làm mất mát khá nhiều thông tin nên sau khi train model khoảng 2200 epoch, kết quả upscale 4x sẽ được có PSNR là :

Với model pretrained này, ảnh output trông rõ hơn chút, bớt bị ringing artifacts và phần mỏ trông sharp hơn do model được train lâu hơn với bộ dataset to hơn. PSNR là .

All rights reserved
