
[paper explain] Scaling Up Your Kernels to 31x31: Sự trở lại mạnh mẽ của CNN trên đường đua ImageNet
Bài đăng này đã không được cập nhật trong 3 năm
Lời mở đầu
Kể từ khi transformer được áp dụng vào bài toán vision, chúng ta đã được chứng kiến sự nhảy vọt ngoạn mục của họ mô hình này khi liên tục những SoTA trên tập ImageNet được xô đổ bởi , ,... Trong khi đó, người anh em CNN lại có vẻ khá im ắng khi chưa có mô hình nào đạt được nghiên cứu mang tính nhảy vọt để có thể sánh vai với transformer. Thế nhưng năm 2022 này lại mở ra một bức tranh mới khi một số nghiên cứu đã có thể "hồi sinh" CNN, đưa nó trở lại cuộc đua song mã : CNN - Transformer. Đặc điểm chung của những paper này là đều tập trung vào Large Kernel Convolution (đưa kích thước kernel convolution vượt lên con số 3), kết hợp với một số kỹ thuật hiện đại nhằm tăng hiệu năng mô hình. Một số paper tiêu biểu có thể kể đến như : SegNext, Visual Attention Network, A ConvNet for the 2020s , Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs và More ConvNet for the 2020s: Scaling Up Kernel Beyond 51 × 51 Using Sparsity. Trong số này thì Scaling Up Your Kernels to 31x31 theo như mình thấy cách dẫn dắt vấn đề dễ hiểu và giải thích chúng khá tường tận nên hôm nay chúng ta sẽ tìm hiểu xem paper này có gì nhé.
Know yourself, know your enemy
Vision Transformers (ViTs) kể từ khi được đưa sang visual tasks đã cho thấy những kết quả đáng nể không chỉ ở tác vụ image classification hay representation learning mà còn ở rất nhiều downstream task như object detection, segmentation và image restoration.
Vậy sức mạnh của ViTs đến từ đâu ? Một số nghiên cứu cho rằng cơ chế multi-head self-attention (MHSA) là key feature trong ViTs, họ đưa ra một số kết quả cho thấy rằng MHSA khá linh hoạt, mạnh mẽ (ít inductive bias hơn), và có khả năng bắt được long-range dependencies. Nhưng một số paper gần đây lại chỉ ra rằng sức mạnh của ViTs không phải từ MHSA mà từ những điều khác, ví dụ như cách xây dựng các block hợp lý (Metaformer),... Trong ViTs, MHSA được thiết kế theo kiểu global, hoặc local nhưng có thêm kernel với kích thước lớn, từ đó mỗi MHSA layer có thể bắt được thông tin từ một vùng rất rộng. Tuy nhiên large kernel lại có vẻ không phổ biến lắm trong các thiết kế của SoTA CNNs, thay vào đó người ta thường ghép nối tiếp nhiều để mở rộng receptive field. Chỉ một số mạng cũ như AlexNet, InceptionNet có sử dụng kernel có thích thước lớn hơn 5 trong block chính. Từ quan sát trên, nhóm tác giả đã tự đặt ra câu hỏi : Model sẽ hoạt động như thế nào nếu chúng ta sử dụng một ít lớp convolution có kernel size lớn, thay vì sử dụng nhiều lớp có kernel size nhỏ? Large kernel và cách xây dựng receptive field lớn, cái nào sẽ là key feature giúp CNNs bắt kịp ViTs?
RepLKNet
Để trả lời câu hỏi trên, nhóm tác giả đã đào sâu vào vấn đề thiết kế mạng CNN với kernel size lớn bằng cách thức khá đơn giản: thêm large depth-wise convolutions vào mạng CNN truyền thống, với kích thước của kernel biến thiên từ . Qua nhiều lần thí nghiệm, tác giả đã tóm tắt lại kinh nghiệm của mình qua 5 điều:
1. Kernel size lớn vẫn rất hiệu quả trong thực nghiệm
2. kết nối tắt (identity shortcut) cực kỳ quan trọng trong mô hình có các lớp convolution với kernel size lớn
3. Re-parameterize kernel nhỏ giúp giải quyết vấn đề tối ưu hóa mô hình.
4. Large kernel buff cho downstream task như object detection và semantic segmentation nhiều hơn là main task như ImageNet.
5. Large kernel hữu ích với cả những feature map nhỏ.
Mô hình được thiết kế theo Swin Transformer và thay MHSA với large depth-wise convolution. Nhóm tác giả chủ yếu đánh giá mô hình cỡ trung bình và cỡ lớn bởi đối tượng được so sánh - ViTs chỉ vượt CNNs khi được train với dataset và model size lớn.
Guidelines of Applying Large Convolutions
Guideline 1: large depth-wise convolutions can be efficient in practice
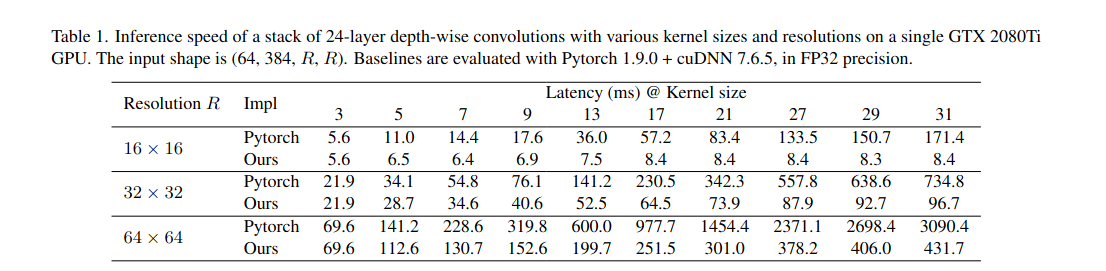
Như chúng ta đã biết thì phép convolution với kernel lớn thường tốn rất nhiều tài nguyên tính toán bởi vì tăng kích thước kernel sẽ làm tăng lượng tham số và FLOPS theo cấp số nhân. Tuy nhiên nhược điểm này có thể vượt qua với depth-wise convolution, minh chứng cho việc này là khi tăng kernel size trong mô hình từ lên thì chỉ làm tăng FLOPS và lượng tham số lên và , đánh đổi này vẫn có thể chấp nhận được.
Một vấn đề nữa là DW convolution như chúng ta biết thì không đạt được hiệu quả tính toán song song trên các thiết bị như GPU. Điều này là đúng với DW conv có kernel bởi vì phép toán DW tạo ra tỷ lệ bất cân xứng giữa hiệu quả tính toán so với chi phí truy cập bộ nhớ. Tuy nhiên nhóm tác giả đã phát hiện một điều là khi tăng kernel size thì mật độ tính toán cũng sẽ tăng lên, từ đó lợi dụng đc tính toan song song trong GPU hiện đại: ví dụ như trong một phép DW có kernel sẽ sử dụng nhiều nhất 121 phép nhân, trong khi với kernel chỉ là 9. Do đó, độ trễ thật sự của mô hình sẽ không tăng nhiều như FLOPs khi kernel size tăng.
Remark 1. Tuy nhiên, không may là Pytorch không có những thuật toán hộ trợ tốt cho DW convolution có kernel size lớn nên nhóm tác giả đã áp dụng thuật toán block-wise (inverse) implicit gemm để tối ưu hóa CUDA kernel. Với sự cải tiến này, độ trễ của DW conv trong RepLKNet đã giảm từ 49% xuống 12.3%, tương đương với tỷ lệ của FLOPs.
Guideline 2: identity shortcut is vital especially for networks with very large kernels.
Để chứng minh rõ điều này, nhóm tác giả thực hiện thí nghiệm trên MobileNet V2 bởi mạng này sử dụng nhiều lớp DW và đã công bố 2 biến thể (có / không có shortcut), sau đó thay toàn bộ lớp DW bằng . Bảng 2 dưới đây cho thấy large kernel cải thiện độ chính xác của MobileNet V2 với shortcut khoảng 0.77%. Tuy nhiên, khi không có shortcuts, large kernel lại làm giảm độ chính xác xuống còn 53.98%.
Remark 2. Guideline thứ 2 cũng có thể áp dụng cho ViTs. Một nghiên cứu mới đây chỉ ra rằng, khi không có identity shortcut thì mạng transformer sẽ giảm performance khá nhiều. Cũng tương tự cho CNN, khi không có shortcut, mạng sẽ rất khó để bắt được local information. Shortcuts có tác dụng tương tự như việc ensemble vô số model với receptive field khác nhau, từ đó khiến model có thể đạt được ERF (effective receptive field) lớn hơn trong khi vẫn không làm mất khả năng bắt local pattern của mô hình.
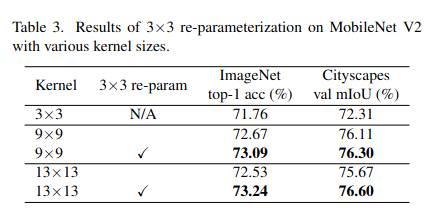
Guideline 3: re-parameterizing with small kernels helps to make up the optimization issue.
Tiếp tục thí nghiệm với MobileNet V2 như ở guideline 2 nhưng ở lần này sẽ có thêm phương pháp Structural Re-parameterization. Đây là phương pháp chuyển đổi cấu trúc mô hình thông qua biến đổi các tham số, nhằm tăng hiệu suất. Ví dụ như mô hình RepVGG sử dụng phương pháp này để nhắm đến việc có được thời gian inference ngắn như VGG trong khi training lại dễ hội tụ như ResNet :v người ta thực hiện phương pháp này bằng cách thêm shortcuts song song với các lớp như ResNet trong quá trình training, sau đó shortcut sẽ được gộp vào kernel thông qua một chuỗi biến đổi tuyến tính. Do đó lúc training mô hình sẽ có kiến trúc tương tự ResNet còn lúc inference thì lại có kiến trúc branch-free như VGG giúp tăng tốc độ infer.
Với RepLKNet, người ta thực hiện phương pháp này bằng cách tạo một nhánh song song với nhánh có kernel lớn rồi cộng output của 2 nhánh sau khi đi qua BatchNorm. Kết thúc quá trình training, kernel nhỏ và BN param sẽ được gộp vào kernel lớn để ngắt branch giúp giảm thời gian infer. Nếu muốn tìm hiểu nhiều hơn về phương pháp Re-parameterization thì các bạn có thể đọc qua bài này. Các bước thực hiện được mô tả ở hình dưới:

Với downstream task như semantic segmentation, chúng ta cũng chứng kiến kết quả tương tự như với ImageNet: re-param cải thiện mIoU của model khoảng 0.19 và model khoảng 0.93. Kết quả được ghi ở bảng dưới đây.
Remark 3. một số thực nghiệm đã chỉ ra ViTs khó hội tụ khi train from scratch với dataset nhỏ và người ta đưa ra hướng giải quyết cho vấn đề này là thêm DW convolution vào mỗi block self-attention. Phương pháp này sẽ giúp gia cố tính chất translational equivariance (tính chất này giúp performance của mạng không bị ảnh hưởng nhiều nếu object trong ảnh bị dịch chuyển) và có thêm thông tin locality, giúp model học dễ hơn với các tập dataset nhỏ mà không mất đi tính tổng quát. Tương tự như ViTs, người ta thấy rằng khi pretrained với tập dữ liệu 73 triệu ảnh (RepLKNet-XL) thì có thể bỏ re-param mà không làm giảm hiệu năng.
Guideline 4: large convolutions boost downstream tasks much more than ImageNet classification.
Bảng 3 ở trên cho thấy khi tăng kernel từ lên thì tỉ lệ chính xác trên ImageNet tăng 1.33% và mIoU trên Citiscapes tăng 3.99%. Điều tương tự cũng xảy ra khi tăng kernel từ lên thì kết quả ImageNet chỉ cải thiện 0.96% nhưng mIoU trên ADE20K tăng 3.12%. Từ hiện tượng trên ta có thể kết luận rằng nhiều model có kết quả giống nhau trên ImageNet nhưng hiệu năng trên downstream task có thể sẽ khác nhau.
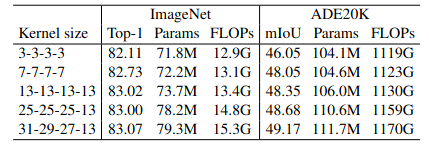
Remark 4. Điều gì đã tạo ra hiện tượng này ? Đầu tiên, cách thiết kế model với large kernel đã mở rộng Effective Receptive Fields (ERFs). Rất nhiều nghiên cứu đã chứng minh rằng "contextual information" (thông tin ngữ cảnh) hay nói cách khác là ERFs lớn, rất quan trọng với downstream task như object detection và semantic segmentation. Thứ hai, large kernel mang thêm thông tin về shape cho model. Một vài paper đã chỉ ra rằng, ảnh trong ImageNet có thể được phân loại chính xác thông qua thông tin về kết cấu hoặc hình dạng. Tuy nhiên con người nhận diện vật thể thường là thông qua hình dạng của chúng hơn là kết cấu, do đó model có thiên hướng mạnh về shape có thể sẽ đạt được performance tốt hơn trên downstream task. Một nghiên cứu gần đây cũng chỉ ra rằng ViTs có thiên hướng về shape rất mạnh, điều này cũng một phần lý giải tại sao ViTs lại khá mạnh cho các task phụ. Ngược lại, CNN truyền thống lại có thiên hướng về kết cấu, nhưng cũng rất may là việc tăng kích thước kernel hoàn toàn có thể giúp CNN tăng cường thông tin về hình dạng.
Guideline 5: large kernel (e.g., 13×13) is useful even on small feature maps (e.g., 7×7).
Để chứng minh điều này, nhóm tác giả đã mở rộng kernel của lớp DW convolution ở stage cuối trong MobileNet V2 lên và , từ đó kích thước kernel thậm chí ngang bằng hoặc lớn hơn kích thước feature map (theo mặc định là ). Kết quả ở bảng 4 cho thấy rằng mặc dù những lớp convolution ở stage cuối đã có receptive field rất lớn rồi, thế nhưng việc tăng kernel size lên lớn hơn hoặc bằng kích thước feature map vẫn có thể cải thiện performance, đặc biệt là với downstream task như Citiscapes

Remark 5. Chú ý rằng khi kích thước kernel đủ lớn thì mạng CNN không còn tính chất translation equivariant. Và điều này lại khá tương đồng với triết lý của ViTs. Nhóm tác giả nhận ra rằng 2D Relative Position Embedding (RPE) được sử dụng trong transformer có thể được xem như là DW conv có kernel size lớn , trong đó và là chiều cao và rộng của feature map. Một nghiên cứu khác cũng chỉ ra kernel lớn không chỉ giúp mô hình học được vị trí tương đối của vật thể mà còn mã hóa được thông tin vị trí tuyệt đối nhờ vào ảnh hưởng của padding
RepLKNet: a Large-Kernel Architecture
Từ 5 guideline bên trên, tác giả đã thiết kế ra model có kiến trúc như hình dưới:
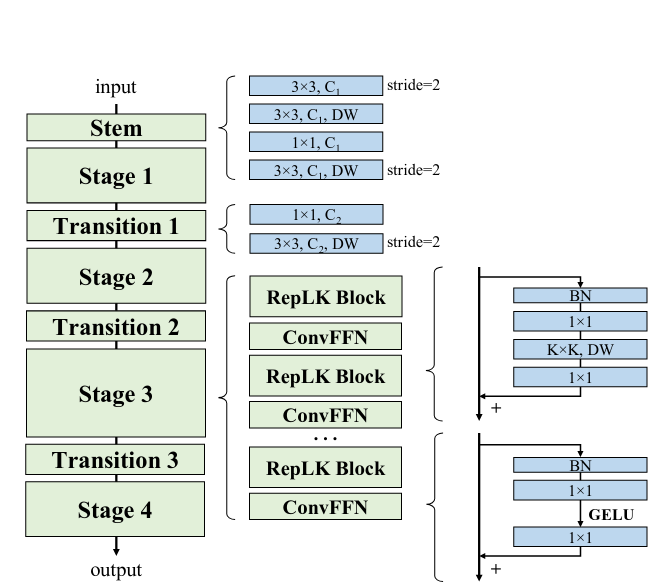
Stem là khối đầu tiên, chứa khá nhiều lớp với mục đích bắt được càng nhiều chi tiết càng tốt ở những layer đầu. Sau lớp đầu tiên với , được thêm vào để lấy low-level pattern. Cuối cùng là trước và sau như thường lệ, sử dụng kernel và để downsampling
Ở stage , mỗi stage chứa nhiều RepLK Block được xây dựng theo các guideline ở trên : trước và sau như thường lệ, sử dụng kernel cho re-param. Để cung cấp thêm tính phi tuyến và sự giao tiếp thông tin giữa các channel, các tác giả chọn sử dụng lớp mở rộng độ sâu của feature map cho nhiệm vụ đó. Ngoại trừ các lớp large conv có nhiệm vụ mở rộng receptive field và thu thập thông tin về không gian thì dung lượng của model chủ yếu đến từ độ sâu của channel. Lấy cảm hứng từ Feed-Forward Network (FFN) được sử dụng rộng rãi trong transformer và MLPs, tác giả thiết kế ra một block tương tự nhưng sử dụng CNN thay vì mlp và gọi nó là ConvFFN block. So sánh với FFN trong transformer sử dụng layer-norm, batchnorm có lợi thế là có thể được gộp vào conv để inference nhanh hơn.
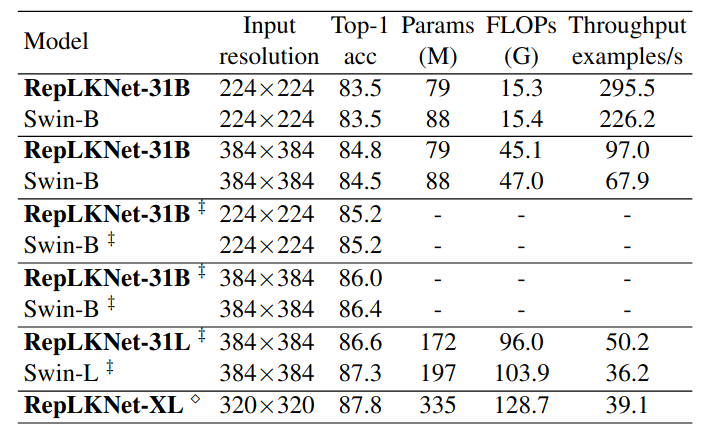
Bảng trên là kết quả tốt nhất của RepLKNet trên ImageNet, vẫn còn chênh lệch một chút với Swin khi so model cùng lượng Params.
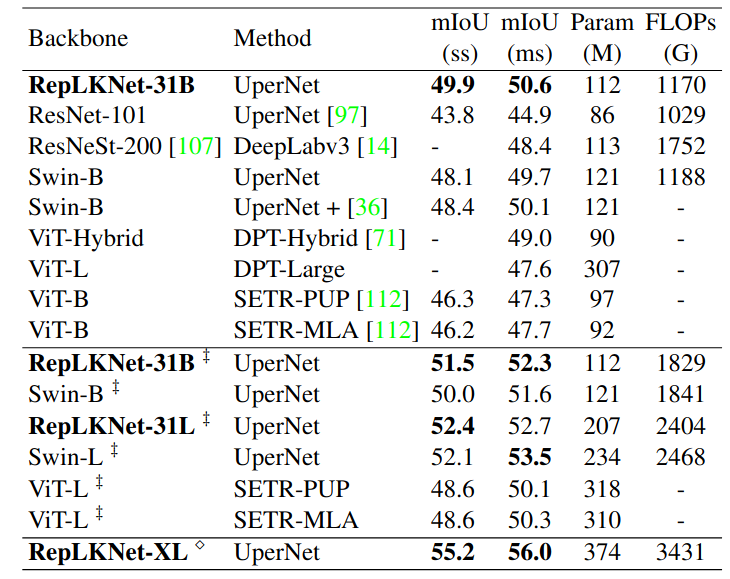
Còn trên downstream task như segmentation thì RepLKNet đã outperform được Swin
Reference
Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
All rights reserved
