
Support Vector Machine
Bài đăng này đã không được cập nhật trong 5 năm
Tổng quan
Support Vector Machine (SVM) là một trong những thuật toán mạnh mẽ cũng như được sử dụng phổ biến nhất trong Machine Learning. Ý tưởng chủ đạo của SVM là xây dựng một bộ phân lớp nhằm tối đa khoảng cách tối thiểu từ mỗi lớp tới siêu phằng phân chia. Để hiểu được cách xây dựng bài toán tối ưu cho SVM, chúng ta sẽ cần tới một chút kiến thức về hình học mà ở đây là khoảng cách từ một điểm tới một siêu phẳng, một chút kiến thức về tối ưu lồi, hàm đối ngẫu Lagrange và cách giải bài toán tối ưu có điều kiện ràng buộc tuyến tính. Trong bài viết này, tôi sẽ giới thiệu về thuật toán SVM để phân lớp một bộ dữ liệu là linearly separable ( có thể phân định tuyến tính được ) và để cho đơn giản chúng ta sẽ xem xét nó là một bài toán phân loại nhị phân.
I. Nhắc lại về Logistic Regression:
Có thể nhiều bạn sẽ đạt câu hỏi là: Tại sao lại là Logistic Regression mà không phải một thuật toán phân lớp nào khác ? Thì tôi xin được trả lời là vì ý tưởng của thuật toán này có nhiều điểm chung với SVM. Nhắc lại cho các bạn nào đã quên thì Logistic Regression xây dựng một phân bố xác suất cho mỗi lớp. Giả sử có một tập dữ liệu trong đó và ta sẽ có:
là xác suất để điểm dũ liệu thứ rơi vào class , được gọi là tham số của mô hình còn biểu thi cho hàm sigmoid. Từ đây ta có thể dễ dàng suy ra được ngay.
Để quyết định điểm dữ liệu này rơi vào class nào ta chỉ cần đơn giản chọn ra class mà nó thuộc vào có xác suất lớn hơn. Nói đơn giản hơn, nếu ta chọn threshold = 0.5 thì một điểm dữ liệu sẽ rơi vào class khi:
Ngược lại nó sẽ rơi vào class . Ở đây nếu các bạn để ý một chút, thì sẽ thấy ngay biểu thức xác suất trên xảy ra khi và chỉ khi điều kiện dưới đây được thỏa mãn.
Biểu thức trên nói cho ta biết rằng, nếu một điểm dữ liệu nằm về phía dương của siêu phẳng ( Hyper plane ) được định nghĩa bởi bộ tham số sẽ được nhận class và ngược lại sẽ nhận class . Nói cách khác, Logistic Regression tìm kiếm một siêu phẳng phân cách sao cho, các điểm thuộc class sẽ nằm về phía dương của nó, còn các điểm thuộc class sẽ nằm về phía âm.
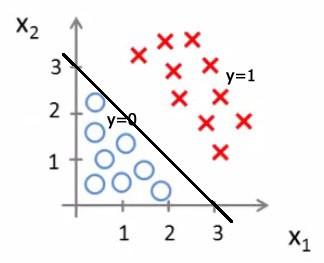
Figure 1: Decision Boundary được sinh ra từ Logistic Regression.
Một quan sát quan trọng nữa là nếu định lượng càng lớn ( một cách hình học mà nói tức là điểm dữ liệu nằm càng xa về phía dương của hyper plane ) thì xác suất để điểm dữ liệu đó rới vào class sẽ càng lớn và ngược lại. Điều này dẫn đến một kết luận rằng, nếu một điểm thuộc class thì ta sẽ muốn chúng cách siêu phẳng về phía dương càng xa càng tốt, tương tự một điểm thuộc class sẽ cần cách về phía âm càng xa càng tốt.
Tương đương với việc chúng ta đang cần tìm một đường phân tách sao cho các điểm thuộc cùng một lớp sẽ nằm về cùng một phía tương ứng và khoảng cách từ điểm gần nhất của mỗi lớp tới đường phân tách đó là lớn nhất có thể. Đó chính là tư tưởng của Support Vector Machine.
II. Khoảng cách từ một điểm tới một siêu phẳng:
Nhắc lại một chút về kiến thức hình học, nếu các bạn đã quên thì khoảng cách từ một điểm đến một mặt phẳng được định nghĩa như sau. Giả sử mặt phẳng (P) có phương trình: và một điểm thì khoảng cách từ điểm A tới mặt phẳng (P) sẽ là:
Tổng quát công thức trên lên không gian có số chiều lớn, ta suy được một công thức tương tự:
trong đó và được gọi là khoảng cách từ điểm tới siêu phẳng (hyper plane) . Ở đây, nếu ta bỏ dấu trị tuyệt đối của tử số đi, ta sẽ xác định được điểm nằm về phía nào của siêu phẳng, nếu tử số là dương, tức là điểm nằm về phía dương của siêu phẳng, ngược lại thì nó sẽ nằm về phía âm.
Để thuận tiện khi thực hiện các phép toán trong SVM, tôi xin được phép sửa lại một chút về ký hiệu, việc sửa đổi này không gây ảnh hưỡng tới kết quả của các biểu thực đã nêu ở trên. Tiếp theo, thay vì dùng ký hiệu để biểu thị cho tham số của siêu phẳng, tôi sẽ đổi nó thành 2 vector khác là và với và và loại bỏ thành phần ra khỏi vector . Biểu thức ở trên có thể viết lại dưới dạng sau đây.
III. Margin:
Xem xét một tập dữ liệu với và ( ở đây để thuận tiện cho các phép tính sau này, tôi xin phép đổi domain của từ về ) và một linear classifier được tham số hóa bởi 2 vector và có dạng sau:
trong đó nếu và nếu . Ta xét khoảng cách từ một điểm trong tập dữ liệu tới siêu phẳng được định nghĩa bởi và .
Từ các giả thiết trên, ta thấy có một quan sát quan trọng: một điểm sẽ được phân lớp đúng nếu.
Như đã thảo luận ở phần trên, ta muốn các điểm dữ liệu cách đường phân cách xa càng tốt, cụ thể hơn, nếu một điểm thuộc lớp ta sẽ muốn là một số dương càng lớn càng tốt, còn nếu thuộc lớp ta sẽ cần là một số âm càng nhỏ càng tốt. Điều này có thể được đảm bảo nếu điểm gần nhất của mỗi lớp, cách xa đường phân cách nhất có thể.
Margin của tập dữ liệu được định nghĩa là khoảng cách từ điểm gần nhất ( bất kỳ lớp nào ) trong tập dữ liệu đó tới siêu phẳng phân cách.
IV. Bài toán tối ưu Margin:
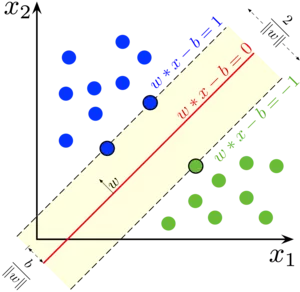
Figure 2: Biễu diên hình học của SVM. (Nguồn: Wikipedia)
Ta cần cực đại hóa margin của bộ dữ liệu, thỏa mãn điều kiện khoảng cách từ mọi điểm trong bộ dữ liệu tới siêu phẳng phân cách tối thiểu phải bằng margin này. Nói cách khác, bài toán tối ưu của chúng ta có dạng sau đây.
Tuy nhiên, chúng ta sẽ không giải trực tiếp bài toán này vì nó rất phức tạp, thay vào đó chúng ta sẽ biến nó về dạng đơn giản hơn để có thể giải được. Trước hết, có một điều quan trọng nữa tôi muốn các bạn hiểu. Cùng xem xét lại công thức khoảng cách từ một điểm dữ liệu tới đường phân cách.
Nếu tôi thay và ( với là một số thực dương bất kỳ ) thì không thay đổi. Ngoải ra việc nhân và với một số nguyên dương bất kỳ không làm ảnh hưởng tới dự đoán của linear classifier ta xem xét ở trên i.e . Sử dụng tính chất bất biến trên ta có thể giả sử các điểm gần nhất với siêu phẳng phân cách thỏa mãn.
Như vậy, với mọi điểm trong bộ dữ liệu, ta sẽ cần điều kiện sau được đảm bảo:
Bài toán tối ưu của chúng ta có thể được viết lại dưới dạng sau:
Hàm norm ở mẫu trông không hề đẹp tí nào phải không, vì vậy thay vì tối đa biểu thức kia ta sẽ chuyển về tối thiểu bình phương biểu thức nghịch đảo của nó, ngoài ra ta sẽ nhân thêm hệ số để nó đẹp hơn khi đạo hàm.
Bài toán tối ưu trên có hàm mục tiêu là một hàm convex ( tôi sẽ không giải thích ở đây, bạn nào muốn tìm hiểu thêm hãy vào phần trích dẫn bên dưới ) với điều kiện ràng buộc là tuyến tính. Ta có thể giải nó bằng quy hoạch toàn phương ( Quadratic Programming), tuy nhiên trong bài viết này, thay vì giải trực tiếp bài toán tối ưu trên, chúng ta sẽ đi giải bài toán đối ngẫu của nó, cũng vì bài toán đối ngẫu có những tính chất đẹp, mà trong đó có thể giúp chúng ta áp dụng được SVM hiệu quả với những bộ dữ liệu là non-linearly separable (không thể phân định tuyến tính).
Xem thêm:
- https://en.wikipedia.org/wiki/Convex_function
- https://machinelearningcoban.com/2017/03/12/convexity/
V. Lagrange duality:
Tạm thời bỏ qua SVM, tôi sẽ nói một chút về bài toán tối ưu có ràng buộc tổng quát và cách giải các bài toán dạng này sử dụng phương pháp nhân tử Lagrange. Phần này sẽ không đi sâu vào lý thuyết mà chúng ta sẽ chỉ cố gắng hiểu các concept quan trọng và các kết quả đã được chứng minh trước đó. Xem xét một bài toán tối ưu có dạng sau đây.
Trong đó được gọi là biến tối ưu ( điều cực kỳ quan trọng khi làm việc với các bài toán tối ưu là bạn biết chúng ta cần tối ưu hàm mục tiêu theo biến nào), được gọi là hàm mục tiêu, được gọi là tập các ràng buộc bất phương trình và là các ràng buộc phương trình. Ta định nghĩa Lagrangian của bài toán trên có dạng như sau.
Trong đó và được gọi là các nhân tử Lagrange. Ta xem xét định lượng sau:
Với tương ứng với hàm Supremum. Ta thấy một quan sát quan trọng sau, nếu có giá trị vi phạm các ràng buộc của bài toán ( hoặc ) thì giá trị , ngược lại nếu giá trị thỏa mãn các ràng buộc của bài toán thì .
Có hơi khó hiểu phải không, để tôi giải thích thêm một chút nhé, giả sử là giá trị thỏa mãn càng ràng buộc ( và , thì với mọi giá trị bất kỳ ta luôn có:
Lấy của biểu thức trên ta sẽ thu được giá trị . Ngược lại nếu giá trị vi phạm các ràng buộc, thì tồn tại giá trị sao cho.
Lấy của biểu thức trên ta sẽ thu được giá trị . Tiếp theo ta xem xét định lượng sau đây.
Với tương ứng với hàm Infimum. Biểu thức trên nói cho ta biết rằng, ta cần tìm giá trị cận dưới của hàm , tức là tại đó giá trị w mà thỏa mãn các ràng buộc của bài toán ban đầu và giá trị của là nhỏ nhất tương ứng với giá trị của là nhỏ nhất. Thêm nữa nếu lầy argument của hàm này sẽ cho ta nghiệm của bài toán ban đầu.
Ta định nghĩa bài toán đối ngẫu của bài toán trên như sau. Giả sử:
Khác với ở trên thay vì lấy theo 2 biến thì ta lấy theo biến . Biểu thúc này nói cho ta biêt rằng, ta cần chọn giá trị w sao cho tại đó giá trị của là nhỏ nhất. Sau đó ta tiếp tục lấy theo 2 biến của hàm trên.
Từ đây ta suy ra được rằng, ta cần chọn giá trị sao cho là lớn nhất, nói cách khác chính là giá trị sao cho ( giá trị tối đa cùa mà tại đó w thỏa mãn các ràng buộc của đề bài ) hay chính là giá trị tối ưu của bài toán đầu tiên. Nếu lấy argument hàm trên, ta cũng thu được nghiệm của bài toán đối ngẫu.
Theo bất đẳng thức Max-Min ta có:
Giấu xảy ra khi và chỉ khi đối ngẫu mạnh xảy ra ( Strong Duality).
Tiêu chuẩn Slater (Slater conditions): Nếu tồn tại một điểm strictly feasible (và bài toán gốc là lồi), thì strong duality xảy ra.
Nói cách khác, nếu hàm mục tiêu và ràng buộc là hàm lồi (convex), là tuyến tính và tồn tại một tập hợp các giá trị nào đó làm cho là strictly feasible ( thõa mãn chặt hay ) thì đối ngẫu mạnh xảy ra. Khi đói ngẫu mạnh xảy ra, việc giải bài toán đối ngẫu sẽ cho chúng ta kết quả của bài toán ban đầu.
Tiêu chuẩn KKT (Karush-Kuhn-Tucker conditions) : Nếu đối ngẫu mạnh xảy ra, thì nghiệm của hệ bài toán ban dầu và đối ngẫu sẽ thỏa mãn tiêu chuẩn KKT
Với là nghiệm của bài toán tối ưu ban đầu và là nghiệm của bài toán đối ngẫu thỏa mãn hệ điều kiện sau:
Nếu tồn tại các giá trị thỏa mãn hệ điều kiện KKT, thì đó cũng là nghiệm của bài toán ban đầu và bài toán đối ngẫu. Ngoài ra các bạn hãy chú ý tới điều kiện thứ 3 trong hệ điều kiện KKT, điều kiện này có tên là: KKT dual complementarity condition. Chúng ta sẽ thấy điều kiện này có tác dụng ra sao ở mục dưới.
VI. Giải bài toán tối ưu cho SVM:
Xem xét bài toán tối ưu Margin:
Dạng bài toán này chưa đúng với dạng mà chúng ta đã xem xét ở mục V ( phần ràng buộc ). Cho nên Chúng ta sẽ biến đổi nó lại một chút để trông nó quen thuộc hơn.
Chúng ta có thể nhận thấy rằng chính là ràng buộc của bài toán chúng ta đã làm. Một quan sát quan trọng ở đây là với các điểm gần nhất với mặt phân cách ( thỏa mãn ) thì (xem lại điều kiện 3 KKT). Mô ta bẳng hình học, các điểm nằm trên đường nét đứt dưới đây chính là các điểm tại đó , người ta còn gọi chúng là các support vectors. Các bạn sẽ thấy ngay sau đây các support vector này đóng vai trò quan trọng trong việc tính của siêu phẳng phân cách.
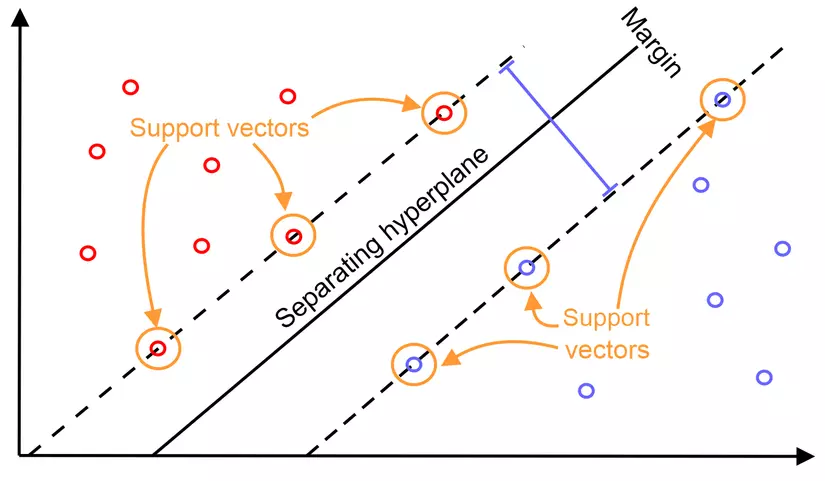
Figure 2: Các suport vectors của SVM. (Nguồn: Wikipedia)
Xét Largarian của bài toán tối ưu trên:
Ở đây chúng ta chỉ có các vì chúng ta chỉ có ràng buộc bất phương trình mà không có ràng buộc phương trình. Chúng ta sẽ tối ưu trong khi giữ cố định , để tạo ra . Đạo hàm theo biến ta thu được.
Giải phương trình đạo hàm bằng 0, ta thu được.
Như đã thấy ở phần trên, hệ số chỉ khác 0 đối với những điểm là support vectors, đối với những điểm không phải support vector, hệ số này sẽ bằng theo điều kiện 3 của tiêu chuẩn KKT. Nói cách khác, vector của siêu phẳng phân cách chỉ phụ thuộc vào các support vectors có trong tập dữ liệu, và số lượng support vector này thường rất nhỏ so với kích thước của tập dữ liệu.
Xét đạo hàm theo biến ta thu được.
Thé ngược vào Largarian ban đầu ta thu được:
Cuối cùng bài toán đối ngẫu với bài toán ban đầu sẽ có dạng sau đây:
Ở đây tôi sẽ không tiếp tục giải tiếp nữa, thay vào đó nếu bạn muốn đưa ra dự đoán cho một điểm dữ liệu mới, chúng ta chỉ cần xét dấu biểu thức , nếu thì , ngược lại . Sử dụng các kết quả đã thu được ở trên, ta có:
Trong đó hãy chú ý inner product của điểm dữ liệu mới với các điểm dữ liệu trong tập dữ liệu, đây là một phần quan trọng nếu sau này bạn muốn hiểu cách áp dụng Kernel Method với SVM, giúp chúng ta làm việc với các dữ liệu không thể phân định tuyến tính được. Ngoải ra nếu bộ dữ liệu là gần phân định tuyến tính, chúng ta sẽ phải thay đổi hàm mục tiêu một chút, các kỹ thuật này tôi sẽ giới thiệu trong các bài sau, cảm ơn các bạn đã theo dõi.
VII. Tham khảo:
- https://machinelearningcoban.com/2017/04/09/smv/#-xay-dung-bai-toan-toi-uu-cho-svm
- http://cs229.stanford.edu/notes/cs229-notes3.pdf
- https://www-cs.stanford.edu/people/davidknowles/lagrangian_duality.pdf
- https://en.wikipedia.org/wiki/Support_vector_machine
- https://machinelearningcoban.com/2017/04/02/duality/
All rights reserved
