
Chúng ta bảo vệ các mô hình Deep learning như thế nào?
Bài đăng này đã không được cập nhật trong 5 năm
Chào mọi người, bài viết này là một bài viết tổng hợp lại những kiến thức cơ sở và một vài nghiên nghiên cứu gần đây về một bài toán mà mình đang tìm hiểu, có thể nó sẽ là một bài toán lạ đối với khá nhiều người và cũng có thể nó không mang lại cho bạn quá nhiều hứng thú, nhưng hãy cùng tìm hiểu xem bài toán đó là gì và để lại bình luận của bạn ở ngay dưới bài viết này. Xin cảm ơn.
Bài viết được lấy cảm hứng từ loạt bài về watermark của tác giả kwkt. Bạn có thể tìm hiểu nhiều hơn trong loạt bài của anh ấy Báo khoa học trong vòng 5 phút.
(wasshoi)
Đặt vấn đề
Như các bạn đã biết, với sự phát triển mạnh mẽ của các nền tảng phần cứng như GPU, TPU đi kèm với sự dồi dào về nguồn dữ liệu, lĩnh vực nghiên cứu trí tuệ nhân tạo (AI) đang có những bước tiến không ngừng, cho thấy sự tuyệt vời của nó trong việc thực hiện các nhiệm vụ khác nhau để thay thế việc xử lí thủ công của con người như các bài toán liên quan tới xử lý ảnh và xử lý ngôn ngữ tự nhiên, phân tích và nhận dạng giọng nói, tín hiệu. Và đứng sau sự thành công tuyệt vời ấy của trí tuệ nhân tạo chính là một lĩnh vực nghiên cứu nhỏ cực kỳ thú vị - Deep learning.
Để xây dựng được một mô hình học sâu hay còn gọi là deep learning model để đưa vào các sản phẩm thực tế không phải là một chuyện đơn giản và dễ dàng. Để có được mô hình tốt, các mô hình đòi hỏi một lượng lớn dữ liệu huấn luyện(do con người gán nhãn, chuẩn bị trước), một tài nguyên tính toán đủ lớn và đủ nhanh(thường là GPU) và những điều đó thôi là chưa đủ, nó còn đòi hỏi chuyên môn, kinh nghiệm thực thi của các nhà phát triển.
Chính vì thế, một bài toán khác lại đặt ra, sau khi huấn luyện xong mô hình, chúng ta phân phối chúng như thế nào để có thể bảo vệ bản quyền, quyền sở hữu của một thứ mà ta không hề dễ dàng có được nó. Liệu sau khi phân phối có phát sinh các trường hợp phân phối lại bất hợp pháp, vi phạm bản quyền và ảnh hưởng tới lợi ích của người/công ty bỏ công sức ra nghiên cứu và phát triển mô hình học sâu đó. Đây là vấn đề quan trọng giúp các nhà phát triển, các doanh nghiệp tự tin hơn khi phân phối mô hình đã huấn luyện của mình cho khách hàng, nhóm các nhà nghiên cứu dễ dàng chia sẻ những kết quả mình đạt được mà không bị lo sợ quyền lợi bị ảnh hướng.
Do đó, để giải quyết vấn đề này, điều cần thiết phải nghiên cứu lúc này là một kỹ thuật để bảo vệ được quyền sở hữu các mô hình Deep learning của tác giả, cho pháp xác minh/trích xuất quyền sở hữu của mô hình.
Và trong bài viết này, chúng ta sẽ nghiên cứu về một kỹ thuật mang tên digital watermarking, một kỹ thuật đã quen thuộc nhằm xác minh quyền sở hữu trí tuệ cho các sản phẩm đa phương tiện nhưng với một đối tượng khác, các mô hình học sâu.
Yêu cầu khi sử dụng Watermark
Việc áp dụng kỹ thuật watermark trong việc bảo vệ các mô hình học sâu sẽ được tìm hiểu sau. Tuy nhiên, như quy trình phát triển, nghiên cứu các dự án phần mềm khác, trước khi bắt tay vào thực hiện, chúng ta nên định nghĩa ra các tiêu chuẩn đánh giá về tính khả thi và hợp lệ của phương pháp trước, để từ đó về sau có thể xác định được luôn phương pháp nào khả thi, phương pháp nào không. Vậy, các yêu cầu khi sử dụng watermark là gì?
Bảo toàn chất lượng
Các kỹ thuật watermark đã được sử dụng rất nhiều cho các loại dữ liệu đa phương tiện như hình ảnh, video, audio. Và tương tự như với các loại dữ liệu này, với việc áp dụng với các mô hình học sâu cũng có một yêu cầu tương tự Sau khi gắn thêm watermark, chất lượng của dữ liệu phải được bảo toàn. Ở đây, với hình ảnh, chất lượng dữ liệu được bảo toàn có nghĩa là sự cảm nhận của con người về hình ảnh vẫn còn nguyên vẹn, không hoặc ít bị thay đổi. Còn đối với các mô hình DNNs, chất lượng, hiệu năng của model cũng vẫn phải được bảo toàn, mà độ đo ta hay nhắc đến nhất chính là độ chính xác - accurancy.
Độ mạnh mẽ của watermark
Luôn nhớ rằng, mục đích của chúng ta khi giấu watermark là để bảo vệ quyền sở hữu của mình với dữ liệu. Vậy nên, một trong những yêu cầu bắt buộc đối với bài toán này là độ mạnh mẽ của watermark, liệu watermark có được duy trì với các phương thức xử lý, tấn công khác nhau của kẻ thứ 3. Đối với các mạng DNN, các phương thức xử lý gây tác động nhiều nhất là fine-tuning hay transfer learning. Watermark cần phải được duy trì ngay cả khi mô hình DNNs phải chịu tác động của các phương xử lý này.
Ngoài ra, một vài yêu cầu không bắt buộc khác đối với các phương pháp watermark là các phương pháp phải nhúng được một lượng lớn thông tin(đủ để xác thực bản quyển và khó giả mạo), các watermark phải khó bị truy cập và sửa đổi, ghi đè, quá trình nhúng và trích xuất watermark phải nhanh, không quá phức tạp.
Các trường hợp có thể áp dụng watermark
Vậy ta có thể sử dụng watermark trong những trường hợp nào trong các giai đoạn phát triển mô hình, điều này cũng cần được định nghĩa và làm rõ. Có 3 giai đoạn được đặt ra có thể trở thành 3 giai đoạn nhúng watermark:
Train-to-embed: Đây là trường hợp tiêu chuẩn nhất, khi dữ liệu có nhãn được cung cấp, các nhà phát triển sẽ nhúng watermark vào model ngày từ giai đoạn đầu tiên huấn luyện mô hình.
- Fine-tune-to-embed: Đối với các trường hợp model đã được huấn luyện sẵn, các phương pháp gán watermark cũng cần được xây dựng để có khả năng gán watermark vào mô hình trong quá trình fine-tune model. Việc nhúng watermark trong quá trình fine-tune model cũng có một ứng dụng tốt hơn Train-to-embed là nhà phát triển có thể nhúng các watermark khác nhau và cùng một model gốc, từ đó dễ dàng kiểm soát được hoạt động phân phối của từng model.
- Distill-to-embed: Đây là cũng là một trường hợp cực kỳ hay khi nhúng watermark. Trong hai trường hợp ở trên, tác giả hay nhà phát triển mô hình chính là người gán watermark cho mô hình và họ đã phải có một lượng dữ liệu có nhãn nhất định cho việc huấn luyện mô hình. Còn trong trường hợp này, chúng ta giấu watermark vào trong mô hình khi hoàn toàn không có một chút dữ liệu có nhãn nào. Đây cũng là ứng dụng có thể nhìn thấy được như một trung tâm bảo vệ bản quyền cho model, thay mặt các tác giả model gán watermark cho các DNNs của họ.
Bảo vệ watermark khỏi tấn công
Tiếp đến một vấn đề ta phải quan tâm tới trước khi đi sâu vào chi tiết kỹ thuật của bài toán này đó là cách bảo vệ watermark trước những tấn công xấu của đối thủ. Ở đây, chúng ta định nghĩa ra các kiểu tấn công chính/ các phương pháp phá watermark có thể có với các mô hình DNNs. Hai phương pháp pháp watermark chính có thể kể đến như fine-tuning và model compression.
- Fine-tuning: Đây là phương pháp tấn công khả thi nhất khi đối thủ có một phần dữ liệu có nhãn. Fine-tune sẽ làm cho các tham số của mô hình thay đổi và watermark phải đủ mạnh mẽ để duy trì sau những biến đổi này.
- Model compression: Đây là bước vô cùng quan trọng khi ta triển khai các mô hình DNNs vào các hệ thống thực tế đặc biệt là các hệ thống phần cứng yếu vì nó có thể làm giảm đáng kể bộ nhớ và chi phí tính toán. Tuy nhiên, điều này cũng là các tham số của mô hình có sự biến đổi và dĩ nhiên điều này làm ảnh hưởng không nhỏ đến các watermark. Để hiểu hơn về model compression, mời bạn đọc lại bài viết trước đây của mình Compression model.
Vậy là chúng ta đã tìm hiểu sơ qua và có cái nhìn khái quát về về yêu cầu kỹ thuật cũng như đặc điểm của bài toán này. Tiếp theo, chúng ta sẽ cùng lần lượt tìm hiểu các bài báo nghiên cứu về watermark gần đây, để xem quá trình phát triển, xây dựng các kỹ thuật bảo vệ quyền sở hữu cho các mô hình Deep learning như thế nào?
Các paper nghiên cứu về kỹ thuật watermarking được nghiên cứu gần đây
Embedding Watermarks into Deep Neural Networks (2017)
(paper)
Năm 2017, Yusuke Uchida và cộng sự đã đề xuất việc sử dụng kỹ thuật watermarking để bảo vệ quyền sở hữu trí tuệ và phát hiện vi phạm sở hữu trí tuệ trong việc sử dụng các mô hình được đào tạo và phân phối bằng việc cố gắng nhúng watermark vào trong các mạng DNNs.
Trong bài báo, nhóm đã đề xuất 1 framework để nhúng watermark vào trong chính tham số của mô hình, sử dụng parameter regularizer. Framework này đã được public tại đây.
Watermark được nhúng vào tham số của mạng trong quá trình đào tạo, do đó nó không làm ảnh hưởng tới hiệu suất của mô hình. Theo như kết quả được công bố tại bài báo, framework mà họ cung cấp đã có khả năng nhúng được các watermark vào trong các mạng DNNs cả trong 3 giai đoạn, training from scratch, fine-tuning và distilling mà không làm ảnh hướng đến hiệu suất của mô hình. Watermark không bị biến mất ngay cả khi bị tinh chỉnh hay 65% tham số bị cắt tỉa khi bị tấn công pruning.
Bài toán:
Cho một mô hình neural network có hoặc không có pre-trained weights. Nhiệm vụ cần thực hiện là nhúng vào trong các tham số của mô hình đó ở một hoặc nhiều layer khác nhau mà trong bài báo này, nhóm tác giải tập trung vào các layer CNNs.
Chi tiết về phương pháp
Trong nghiên cứu này, một watermark được giả định sẽ nhúng vào một convolutional layers của mạng DCNN.
Giả định lớp convolution này có kernel size là , input đầu vào cho layer này có số channel là là số filters của layer hiện tại là . Khi đó, số parameters của layer này sẽ là một tensor (không xét đến ). Watermark ở đây sẽ là một vector , , vector này sẽ cố gắng để nhúng vào .
Có thể nhúng watermark vào bằng cách sửa đổi luôn giá trị các phần tử trong , điều này là khả thi tuy nhiên nó ảnh hưởng nghiêm trọng tới độ chính xác cũng như hiệu năng của mạng DCNN ban đầu. Thay vào đó, nhóm tác giả quyết định nhúng vào không gian trong quá trình training model thông qua parameter regularizer- là một thuật ngữ bổ sung cho cost function của nhiệm vụ training bạn đầu. Hàm lỗi hay còn gọi là cost function được xác định với regularizer như sau:
Trong đó, có thể là L2 regularization.
Khi các bạn học về Machine learning, ý nghĩa của biểu thức trên là gì và nó có ảnh hưởng như thế nào với quá trình đào tạo thì các bạn đã quá quen thuộc rồi, mình không giải thích lại. Bạn có thể đọc lại tại đây.
Khác với các chức năng regularizer tiêu chuẩn như L1/L2 regularization, nhóm tác giả đề xuất một khái niệm gọi là . được gọi là một embedding loss function kết hợp với loss function ban đầu là để trở thành loss function mới của mạng.
Để có thể nhúng vector , vào mô hình, chúng ta cần định nghĩa một ma trận embedding gọi là . Ma trận này là cố định và được khởi tạo một lần duy nhất và cần được lưu lại cho quá trình trích xuất watermark khi muốn xác định chủ sở hữu mô hình. được định nghĩa như sau:
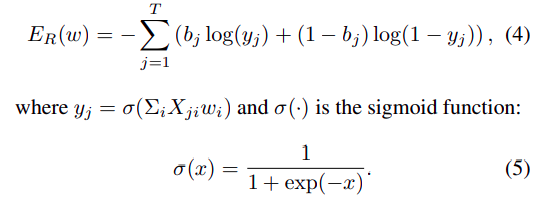
Khi đó, bằng việc mô hình được học dựa trên loss function mới, mô hình sẽ cố gắng cập nhật các trọng số cần học của mạng là sao cho - giá trị bit thứ j của vector nhúng và các giá trị là tiệm cận về mặt giá trị với nhau vì các giá trị được thiết kế cơ bản là đầu ra của một mạng perceptron đơn giản với tham số học được chính là với tham số cố định là .
Như vậy, khi mô hình được tối ưu dựa trên loss mới, dựa vào bộ trọng số của mô hình và ma trận định trước, ta dễ dàng xác định lại được vector watermark như cách tính của ở trên.
Nếu nhìn sơ qua, cách xây dựng này có thể làm giảm hiệu suất của mạng do thay vì chỉ cập nhật trọng số của mạng để đạt được nhiệm vụ ban đầu mà còn phải biến đổi sao cho phù hợp với watermark. Đôi khi vì quá tập trung vào cập nhật cho phù hợp với watermark mà mạng mất đi hiệu suất cho nhiệm vụ ban đầu. Tuy nhiên, bằng việc thực nghiệm của mình, nhóm nghiên cứu đã chỉ ra rằng đề xuất này không làm giảm hiệu suất của nhiệm vụ ban đầu mà còn giúp mô hình dễ dàng chống được overfit- một hiện tượng thường gặp của các mạng DNNs.
This approach does not impair the performance of the host network in the original task as confirmed in experiments, because deep neural networks are typically overparameterized. It is well-known that deep neural networks have many local minima, and that all local minima are likely to have an error very close to that of the global minimum [9, 6]. Therefore, the embedding regularizer only needs to guide model parameters to one of a number of good local minima so that the final model parameters have an arbitrary watermark.
Trong bài báo, nhóm tác giả của đề xuất và thí nghiệm 3 phương pháp sinh ma trận embedding . Đây là có thể coi là một secret key với có vai trò để nhúng và phát hiện lại watermark. ở đây có thể là các ma trận bất kì, được sinh ngẫu nhiên, tuy nhiên, vì nó sẽ ảnh hưởng đến quá trình nhúng watermark và có thể ảnh hưởng đến hiệu suất của mạng ban đầu nên một số đề xuất đã được xem xét bao gồm , và . Kết quả thí nghiệm các bạn có thể xem chi tiết tại bài báo. Toàn bộ code cho thử nghiệm được public tại đây dnn-watermark.
Nhìn chung, với cảm nhận cá nhân mình thấy cách nhúng watermark của nhóm tác giả này khá hay và có phần mới lạ. Nhóm tác giả cũng chứng minh được rằng watermark này mạnh mẽ trước các loại tấn cấn như fine-tuning hay model compression. Tuy nhiên, nếu ma trận bị lộ sẽ dễ dàng bị tấn công ghi đè để xóa watermark.
Protecting Intellectual Property of Deep Neural Networks with Watermarking (2018)
(paper)
Một trong những hướng đi khác để bảo vệ mô hình DNN là tạo fingerprint cho mô hình.
Paper này được viết bởi Jialong Zhang và các cộng sự của mình, nhóm nghiên cứu thuộc IBM research và được công bố tại hội thảo ASIACCS năm 2018.
Trong paper này, nhóm nghiên cứu đã đề xuất một phương pháp nhúng các watermark vào các mô hình DNN sau đó thiết kế một cơ chế xác thực từ xa để xác định quyền sở hữu của mô hình. Với việc giả định rằng điều kiện khi xác định quyền sở hữu của mô hình không cho phép người kiểm tra có thể xem xét toàn bộ kiến trúc cũng như trọng số của mô hình, nhóm nghiên cứu đã xây dựng một phương pháp xác thực từ xa. Điều này hiểu đơn giản như việc bạn nghi ngờ công ty A đang sử dụng mô hình của mình khi chưa được cấp phép nhưng cái bạn có duy nhất chỉ là một web site hay một ứng dụng mà công ty đó public có sử dụng mô hình này. Thực chất bạn chỉ đang nghi ngờ mà không biết họ có đang sử dụng mô hình của mình hay không.
Như chúng ta đã biết, các mạng học sâu DNNs hay như CNN có một đặc điểm cũng là ưu và nhược đó là rất dễ học được và ghi nhớ những mẫu có trong dữ liệu học. Đây chính là hiện tượng khiến cho các mô hình dễ dàng bị overfit vào các bộ dữ liệu huấn luyện khi bị học quá lâu. Điều này cũng gợi ý cho ta về một ý tưởng đó là ta có thể cài một tập các mẫu "nhiễu" có chứa watermark vào mô hình để mô hình có thể học được và ghi nhớ chúng trong quá trình huấn luyện. Khi kiểm tra, xác minh quyền sở hữu, ta chỉ việc kiểm tra xem các mô hình đã có nhận ra được các watermark này nữa hay không. Và đây cũng là đề xuất trong bài báo mà mình đang nói tới.
Nhóm tác giả đã đề xuất việc tạo ra các đầu vào đặc biệt làm watermark để kiểm tra các mô hình như các blackbox của mình. Hình dưới đây chính là work flow được đề xuất trong bài báo.
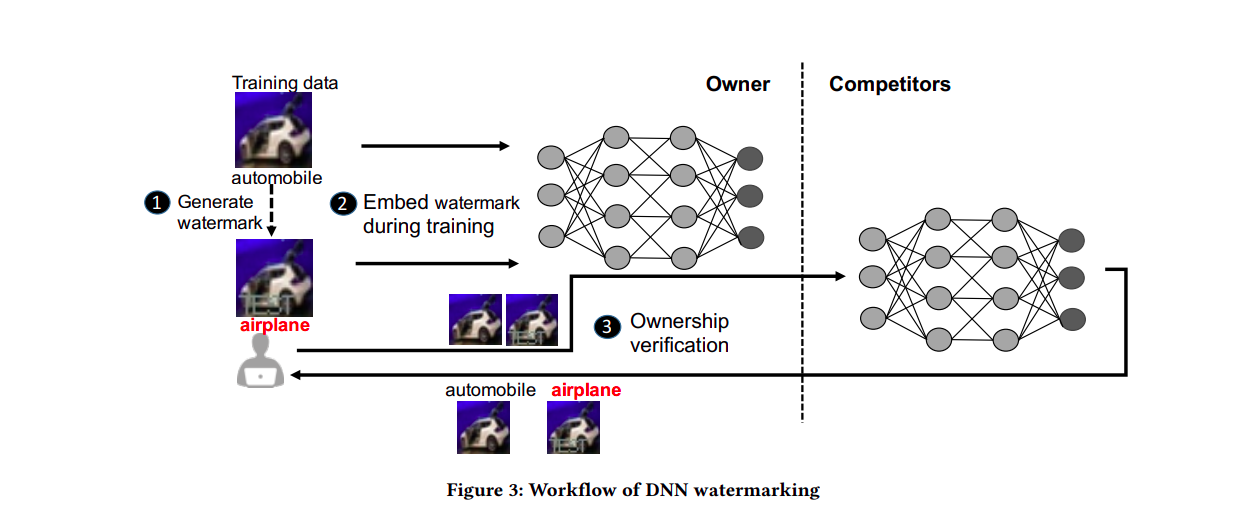
Như hình trên thể hiện rõ cách làm của tác giả, đơn giản và vô cùng dễ thực hiện. Trong dữ liệu training chúng ta có một ảnh là "automobile", chúng ta vẫn cho mô hình học được đó là hình ảnh của một automobile, tuy nhiên, song song với đó ta thực hiện nhúng watermark vào ảnh đó là bảo mô hình đó là một "airplane". Mô hình sẽ học và nhận ra được đâu là hình ảnh có chưa watermark và đưa ra một dự đoán sai.
Trong paper, nhóm tác giả đề xuất 3 phương pháp nhúng watermark vào dữ liệu huấn luyện.
- Meaningful content embedded in original training data as watermarks: Phương pháp này chính là phương pháp vừa mình trình bày ở trên. Một watermark xác định được nhúng vào trong một vài dữ liệu của một class và cho mô hình học được rằng đó là một class khác. (ô tô + watermark == máy bay)
- Independent training data with unrelated classes as watermarks: Phương pháp này chỉ tận dụng khả năng ghi nhớ dữ liệu của mô hình, không cần mô hình phải nhận ra các pattern watermark có trong dữ liệu vì các watermark độc lập với dữ liệu huấn luyện. Chúng ta cho mô hình học các dữ liệu không liên quan nhưng mô hình vẫn phải dự đoán đó là các class định sẵn. Như việc ta xây dựng một mô hình phân loại cho mèo nhưng cho mô hình huấn luyện trên 10 ảnh con voi mà vẫn bắt nó dự đoán đó là con mèo.
- Pre-specified Noise as watermarks: Phương pháp này thì khá tương tự như phương pháp đầu tiên, nhưng thay vì gán các watermark định sẵn, chúng ta thêm nhiễu vào các sample của 1 class cần mô hình nhận dạng và bắt mô hình dự đoán đó thuộc về một class khác.
3 phương pháp được đề xuất được thể hiện như hình bên dưới đây.

Dễ dàng nhận thấy những đề xuất này hiệu quả ở việc rất khó để mô hình có thể quên đi các mẫu watermark đã được huấn luyện kể cả mô hình bị tấn công watermark bằng fine-tuning hay model compression như pruning, quantization. Một khi mô hình đã học được các mẫu watermark thì không thể xóa chúng trừ khi bên công có được cách thức nhúng watermark và bộ dữ liệu chứa watermark dùng để chứng minh quyền sở hữu. Việc xác thực sở hữu hoàn toàn là việc cho mô hình dự đoán lại các mẫu dữ liệu chứa watermark mà không cần kiểm tra kiến trúc hay trọng số của mô hình.
Turning Your Weakness Into a Strength: Watermarking Deep Neural Networks by Backdooring (2018)
(paper)
How to Prove Your Model Belongs to You: A Blind-Watermark based Framework to Protect Intellectual Property of DNN (2018)
(paper)
DeepSigns: A Generic Watermarking Framework for Protecting the Ownership of Deep Learning Models (2018)
(paper)
References
- Protecting Intellectual Property of Deep Neural Networks with Watermarking
- How to Prove Your Model Belongs to You: A Blind-Watermark based Framework to Protect Intellectual Property of DNN
- Digital Watermarking for Deep Neural Networks
- DeepSigns: A Generic Watermarking Framework for Protecting the Ownership of Deep Learning Models
- Turning Your Weakness Into a Strength: Watermarking Deep Neural Networks by Backdooring
- Embedding Watermarks into Deep Neural Networks
- Báo khoa học trong vòng 5 phút.
All rights reserved
