
Encoding categorical features in Machine learning
Bài đăng này đã không được cập nhật trong 5 năm
Khi tiếp cận với một bài toán machine learning, khả năng cao là chúng ta sẽ phải đối mặt với dữ liệu dạng phân loại (categorical data). Khác với các dữ liệu dạng số, máy tính sẽ không thể hiểu và làm việc trực tiếp với categorical variable. Do vậy nhiệm vụ của chúng ta là phải tìm cách "encode" dữ liệu dạng category, đưa nó về dạng khác để có thể đưa vào mô hình của mình.
Bài viết này là một ghi chú nơi mình tóm tắt lại các cách thức để xử lý categorical data cũng như lưu lại code cần thiết để sau này có thể dễ bề tham khảo lại.
1. Categorical data là gì
Dữ liệu phân loại, không giống với dữ liệu dạng số (numerical data), là loại dữ liệu chỉ nhận một số lượng hữu hạn các giá trị cố định. Ví dụ trong một dataset về user, giới tính là một feature dạng categorical ví nó chỉ nhận 1 trong 2 giá trị: Nam hoặc Nữ. Hoặc dữ liệu về các sản phẩm của một siêu thị sẽ có trường phân loại là một categorical feature vì nó nhận một số các giá trị nhất định như đồ uống, đồ ngọt, rau quả, đồ dùng cá nhân, vv. Các dữ liệu dạng phân loại thường được biểu diễn dưới dạng text.
Categorical data thường được chia làm 2 loại: nominal và ordinal data:
- Nominal data (dữ liệu dạng định danh): dữ liệu được label hoàn toàn không theo một thứ tự hay thứ bậc trước sau nào. Ví dụ Nam/ Nữ - thời tiết nắng/ mưa/ nhiều mây/ - tên các nước, các thành phố, vv.
- Ordinal data (dữ liệu dạng thứ bậc): ngược với nominal data, là dữ liệu được sắp xếp/ phân loại theo một thứ tự nhất đinh. Ví dụ tình hình kinh tế tốt/ trung bình/ xấu - kích cỡ quần áo XS/ S/ M/ L/ XL, vv.
Việc sử dụng categorical data trong bài toán ML có các thách thức như sau:
- Nhiều model machine learning thường chỉ nhận input là các giá trị numerical. Để dùng các model này, categorical data buộc phải được đưa về dạng number. Một số ML package có auto hỗ trợ categorical data nhưng không nhiều.
- High cardinality: dữ liệu có thể bao gồm một lượng rất lớn các giá trị khác nhau, trong đó mỗi giá trị chỉ xuất hiện rất ít lần
- Máy tính không nhìn nhận dữ liệu dạng phân loại và mối quan hệ giữa chúng như cách con người nhận thức. Ví dụ với tên các quốc gia chẳng hạn. Khi nhìn vào Việt Nam, Nhật Bản và Canada, ta có thể dễ dàng thấy được Việt Nam và Nhật Bản sẽ tương đồng với nhau, gần nhau hơn về mặt địa lý so với Canada. Nhưng với máy tính thì 3 category này cũng chỉ như nhau mà thôi nếu ta không cung cấp thêm thông tin nào khác.
Vậy điều cần thiết là phải tìm cách biến đổi các category này về dạng numerical để máy tính có thể xử lý, cũng như tìm cách extract được các thông tin "hữu ích" trong mối quan hệ giữa chúng.
2. Các cách thức làm việc với categorical data
Python có một package khá hữu dụng để giúp transform dữ liệu dạng phân loại là category_encoders, đây là package mình sẽ sử dụng chính trong bài này
!pip install category_encoders
import category_encoders as ce
Mình cũng sẽ generate một cách random ra một bảng dữ liệu dạng categorical.
import pandas as pd
import numpy as np
np.random.seed(2)
data =pd.DataFrame({"Product" : ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J'],
"Category" : np.random.choice(['drink', 'food', 'vegetable', 'spice'], 10, replace=True)})
Như vậy ta sẽ có 10 sản phẩm và mỗi sản phẩm nhận một giá trị dạng caterogical thể hiện phân loại của chúng:
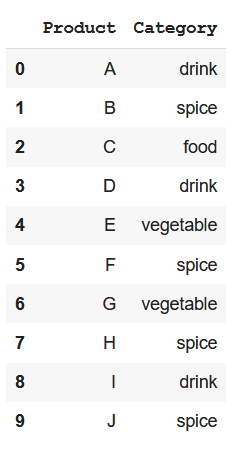
2.1. Integer encoding/ Ordinal encoding
Cách làm bản năng nhất là đưa giá trị dạng category đó về số, tức là map mỗi category với một số nguyên. Ví dụ: sản phẩm đồ uống là số 0, gia vị là 1, đồ ăn là số 2, rau quả là 3 và tương tự.
data['IntEnc'], _ = pd.factorize(data['Category'])
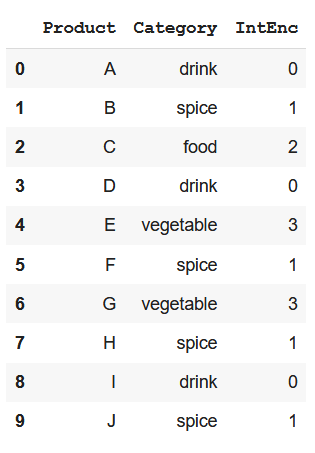
Tuy nhiên, điều này vô hình trung đã gán cho các category này một giá trị, một thứ bậc nào đó mà thực tế thì không phải lúc nào cũng như thế (nominal features), do vậy có thể dẫn đến việc thiếu chính xác khi tính toán trong mô hình.
2.2. One-hot encoding vs Dummy encoding
One-hot encoding là một trong những cách thức encode giá trị categorical phổ biến nhất. Theo đó, mỗi giá trị category sẽ tương ứng với một one-hot vector với k phần tử (k là số lượng các giá trị khác nhau).
Cách làm như sau: với mỗi một giá trị khác nhau của categorical feature, chúng ta sẽ tạo ra một feature mới, như trong ví dụ của bài này sẽ lần lượt là Category_drink, Category_food, vv. Mỗi category mới này sẽ được gán cho một giá trị là 0 hoặc 1. Nếu sản phẩm thuộc category nào thì giá trị ở đó sẽ là 1. Những features mới được tạo ra này được gọi là Dummy variables.
import category_encoders as ce
encoder=ce.OneHotEncoder(cols='Category', return_df=True,use_cat_names=True)
data_encoded = encoder.fit_transform(data)
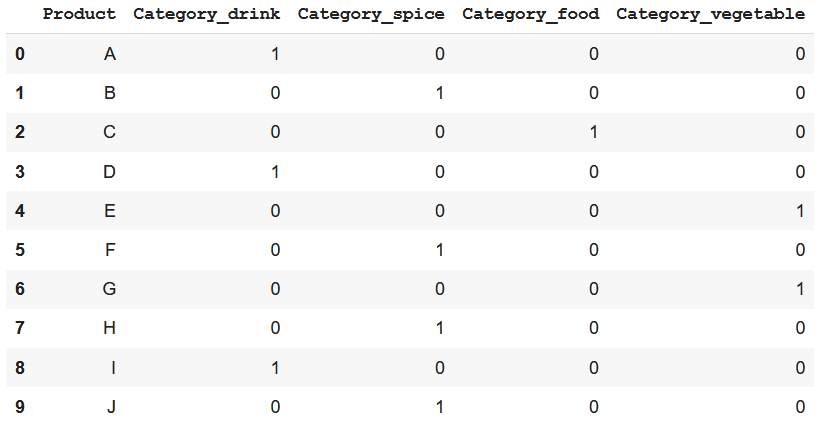
Dummy encoding cũng tương tự như One-hot encoding nhưng thay vì có k dummy variables mới cho k category khác nhau thì ta chỉ cần k-1 thôi. Một category còn lại sẽ được biểu diễn bằng 0 ở tất cả các cột (trong ví dụ này chính là Category_drink).
data_encoded=pd.get_dummies(data=data,prefix = 'Category', columns = ['Category'], drop_first=True)
data_encoded
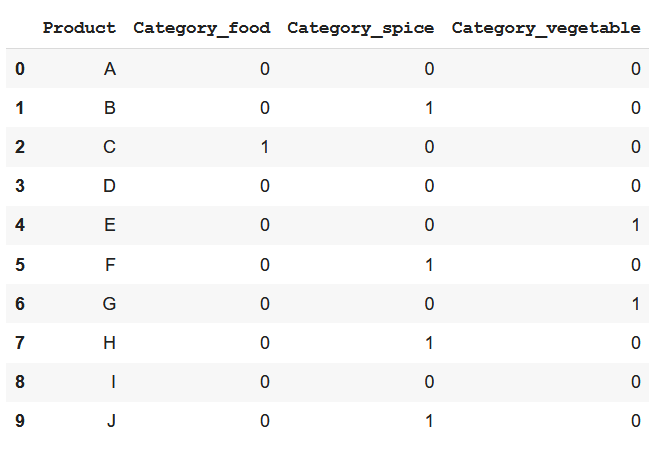
Nhược điểm của One-hot và Dummy encoding:
- Khi categorical features có một số lượng lớn các giá trị khác nhau, hoặc trong dataset có nhiều categorical features, chúng ta sẽ cần đến rất nhiều dummy variables để encode data. Ví dụ một feature có 30 giá trị khác nhau sẽ tương đương với 30 biến mới.
- Trong trường hợp trên, hai cách encode này sẽ gây ra sparsity cho dataset (rất nhiều côt 0 và rất ít cột 1). Nói cách khác, quá nhiều biến dummy được tạo ra trong dataset mà lại không thêm được nhiều thông tin.
=> not memory-efficient, dễ gây tràn bộ nhớ, làm chậm và giảm hiệu quả quá trình learning
- Không hiệu quả khi sử dụng tree-based model
2.3. Hashing encoding
Hashing là quá trình biến đầu vào là một nội dung có kích thước, độ dài bất kỳ rồi sử dụng những thuật toán, công thức toán học để biến thành đầu ra tiêu chuẩn có độ dài nhất định. Quá trình đó sử dụng những Hàm băm (Hash function)
Cũng giống như one-hot encoding, hashing cũng biểu diễn các giá trị dạng categorical trên các dimension mới (bằng các features mới). Chúng ta có thể cố định số features mới này. Tức là một feature A có 5 giá trị khác nhau có thể được biểu diễn bằng 10 features mới, và features B có 100 giá trị cũng có thể được biểu diễn bằng 10 features. Hàm băm mặc định được sử dụng là MD5 nhưng người dùng cũng có thể tùy chọn các hàm băm khác.
encoder=ce.HashingEncoder(cols='Category',n_components=3)
encoder.fit_transform(data)
=========> 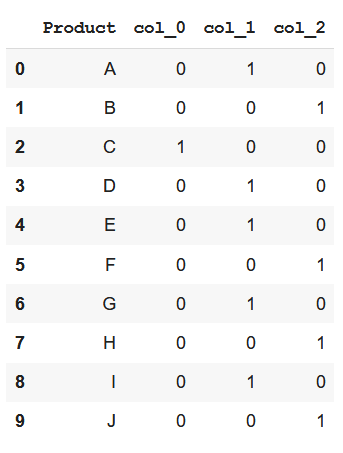
Như chúng ta có thể thấy từ hình trên, vì hashing đưa dữ liệu về số chiều thấp hơn, nó có thể làm mất mát thông tin hoặc gây ra collision (2 giá trị khác nhau được biểu diễn giống nhau). Tuy nhiên đây vẫn là một kỹ thuật đáng thử với những features có cardinality cao.
2.4. Binary encoding
Binary encoding là sự kết hợp giữa Hashing và One-hot encoding. Đầu tiên các categorical features sẽ được chuyển thành các số nguyên (ordinal encoding) . Sau đó các số nguyên này được chuyển về dạng nhị phân. Các giá trị nhị phân sẽ được phân thành các cột.
encoder= ce.BinaryEncoder(cols=['Category'],return_df=True)
data_encoded=encoder.fit_transform(data)
===========> 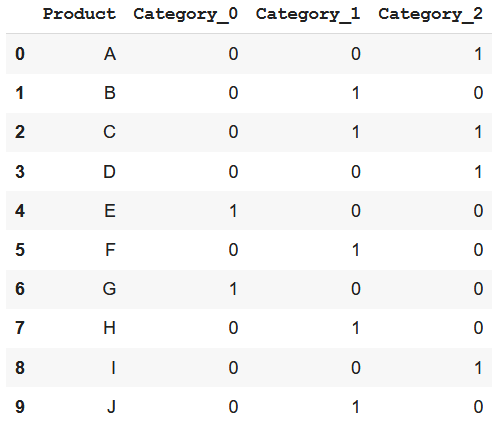
Cách thức này hoạt động rất tốt khi số lượng category lớn, sử dụng bộ nhớ hiệu quả hơn do dùng ít features hơn. Ngoài ra nó còn giúp giảm đáng kể số chiều đối với những data có cardinality cao.
2.5. Base N Encoding
Binary encoding chính là một trường hợp của Base N encoding. Sau khi thực hiện ordinal encoding thì thay vì đổi các số nguyên về hệ nhị phân như binary, ta sẽ đổi các số đó về các hệ cơ số khác như 4 hay 8 chẳng hạn (=> Base N)
encoder= ce.BaseNEncoder(cols=['Category'],return_df=True,base=4)
data_encoded=encoder.fit_transform(data)
=======>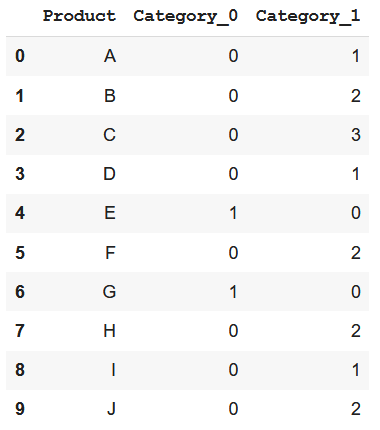
Như vậy Base N encoding giúp giảm lượng features nhiều hơn so với Binary, do vậy nó có thể trở nên càng hữu dụng khi số lượng category càng lớn.
2.6. Learned Embedding
Các cách thức encoding giới thiệu ở trên chủ yếu mới giải quyết được vấn đề về dịnh dạng dữ liệu cũng như cardinality (2/3 thách thức nêu ra ở đầu bài). Vậy làm thế nào để có thể biểu diễn mối tương quan giữa các category để máy tính có thể hiểu được. Câu trả lời là learned embedding, hay gọi ngắn gọn là “embedding”, là một cách biểu diễn phân tán (distributed representation) cho categorical data.
Mỗi category sẽ được map với một vector riêng biệt, và bản thân vector này sẽ được cập nhật/ "học" trong quá trình traning mạng neuron. Nhờ vậy các category gần nhau hoặc có quan hệ với nhau cũng sẽ nằm gần nhau hơn trong không gian vector.
Kỹ thuật này ban đầu được phát triển để dùng trong xử lý ngôn ngữ tự nhiên, với mục đích là cung cấp embedding cho các từ (các từ có ngữ nghía gần nhau sẽ có biểu diễn dạng vector tương đồng).
Lợi ích:
- Mối quan hệ giữa các category có thể được "học" từ data
- Mỗi giá trị category vẫn được biểu diễn dưới dạng vector mà không bị sparse như one-hot encoding
- Vector sau khi được "học" có thể được tách ra và sử dụng làm input cho các model/ ứng dụng khác
Embedding có thể được sử dụng trong Keras qua class tf.keras.layers.Embedding . Ta sẽ thêm một layer Embedding vào trước các lớp của mạng neuron.
Kết luận
Trong bài này mình đã giới thiệu qua một số cách thức encoding dữ liệu dạng phân loại (categorical) để có thể khai thác các dữ liệu này trong machine learning. Trên đây mới chỉ là những hình thức cơ bản nhất và mình sẽ cập nhật thêm các kỹ thuật khác khi có cơ hội. Cảm ơn các bạn đã đọc và mình rất mong nhận được góp ý từ các bạn 
References
https://www.analyticsvidhya.com/blog/2020/08/types-of-categorical-data-encoding/
All rights reserved
