Machine Learning
Bài đăng này đã không được cập nhật trong 4 năm

What is machine learning?
In one sentence, Machine learning is a type of artificial intelligence (AI) that provides computers with the ability to learn without being explicitly programmed.
But this bookish defination is not enough to understand it clearly. So lets clearify it little more.
In order to solve a problem using computer, we need an algorithm. Generally an algorithm is a sequence of instructions that takes some input and gives you your desired output.
For example, one can write an algorithm for sorting. The input is a set of numbers and the output is their ordered list. For the same task, there may be various algorithms and we may be interested in finding the most efficient one.
For some tasks, however, we do not have an algorithm—for example, identifying the spam email from the legitimate emails. We know what the input is: an email document that in the simplest case is a file of characters. We know what the output should be: a yes/no output indicating whether the message is spam or not. But We do not know how to transform the input to the output.
This is the case where Machine Learning comes in. What we lack in knowledge, we make up for in data. We can easily compile thousands of example messages some of which we know to be spam and what we want is to “learn” what consititutes spam from them. In other words, we would like the computer (machine) to extract automatically the algorithm for this task.
Application of machine learning methods to large databases is called data mining. But machine learning is not just a database problem; it is also a part of artificial intelligence. To be intelligent, a system that is in a changing environment should have the ability to learn. If the system can learn and adapt to such changes, the system designer need not foresee and provide solutions for all possible situations.
Where can we use it?
Machine learning can helps us find solutions to many problems in object recognition (Google glass), driverless car, speech recognition (Siri and Google now), and of course robotics.
Let us take the example of recognizing faces: This is a task we do effortlessly; every day we recognize people by looking at their faces or from their photographs, despite differences in pose, lighting, hair style, and so forth.
But we do it unconsciously and are unable to explain how we do it. Because we are not able to explain our expertise, we cannot write the computer program. At the same time, we know that a face has structure. It is symmetric. There are the eyes, the nose, the mouth, located in certain places on the face.

Each person’s face is a pattern composed of a particular combination of these. By analyzing sample face images of a person, a learning program captures the pattern specific to that person and then recognizes by checking for this pattern in a given image. This is one example of pattern recognition.
There are a number of examples like credit card fraud detection, snail mail routing, quantitative trading, market segmentation analysis, demand prediction for inventory control, and other things. It is also used for scientific data analysis in several areas, with bioinformatics being the really big one.
Different Examples of Machine Learning Applications
Learning Associations

Lets think of a supermarket chain—one application of machine learning is basket analysis, which is finding associations between products bought by customers: If people who buy X typically also buy Y, and if there is a customer who buys X and does not buy Y, he or she is a potential Y customer. Once we find such customers, we can target them for cross-selling.
association rule In finding an association rule, we are interested in learning a conditional probability of the form P(Y|X) where Y is the product we would like to condition on X, which is the product or the set of products which we know that the customer has already purchased.
Let us say, going over our data, we calculate that P(chips|beer) = 0.7. Then, we can define the rule: 70 percent of customers who buy beer also buy chips.
We may want to make a distinction among customers and toward this, estimate P(Y|X,D) where D is the set of customer attributes, for example, gender, age, marital status, and so on, assuming that we have access to this information. If this is a bookseller instead of a supermarket, products can be books or authors. In the case of a Web portal, items correspond to links to Web pages, and we can estimate the links a user is likely to click and use this information to download such pages in advance for faster access.
Classification
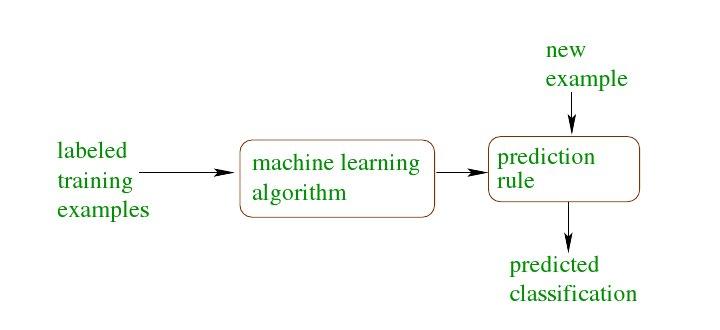
A credit is an amount of money loaned by a financial institution, for example, a bank, to be paid back with interest, generally in installments. It is important for the bank to be able to predict in advance the risk associated with a loan, which is the probability that the customer will default and not pay the whole amount back. This is both to make sure that the bank will make a profit and also to not inconvenience a customer with a loan over his or her financial capacity.
This is an example of a classification problem where there are two classes: low-risk and high-risk customers. The information about a customer makes up the input to the classifier whose task is to assign the input to one of the two classes. After training with the past data, a classification rule learned may be of the form
IF income> θ1 AND savings> θ2 THEN low-risk ELSE high-risk
This is an example of discriminant a discriminant; it is a function that separates the examples of different classes. Once we have a rule that fits the past data, if the future is similar to the past, then we can make correct predictions for novel instances. Given a new application with a certain income and savings, we can easily decide whether it is lowrisk or high-risk.
Regression
Let us say we want to have a system that can predict the price of a used car. Inputs are the car attributes—brand, year, engine capacity, mileage, and other information—that we believe affect a car’s worth. The output is the price of the car. Such problems where the output is a number are regression problems.
Let X denote the car attributes and Y be the price of the car. Again surveying the past transactions, we can collect a training data and the machine learning program fits a function to this data to learn Y as a function of X. So the fitted function is of the form y = wx + w0
Both regression and classification are supervised learning problems where there is an input, X, an output, Y, and the task is to learn the mapping from the input to the output.
Unsupervised Learning
In supervised learning, the aim is to learn a mapping from the input to an output whose correct values are provided by a supervisor. In unsupervised learning, there is no such supervisor and we only have input data. The aim is to find the regularities in the input. There is a structure to the input space such that certain patterns occur more often than others, and we want to see what generally happens and what does not. In statistics, this is called density estimation.
One method for density estimation is clustering where the aim is to find clusters or groupings of input.
An interesting application of clustering is in image compression. In this case, the input instances are image pixels represented as RGB values. A clustering program groups pixels with similar colors in the same group, and such groups correspond to the colors occurring frequently in the image. If in an image, there are only shades of a small number of colors, and if we code those belonging to the same group with one color, for example, their average, then the image is compressed.
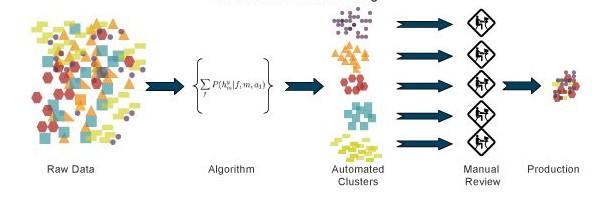
Let us say the pixels are 24 bits to represent 16 million colors, but if there are shades of only 64 main colors, for each pixel we need 6 bits instead of 24. For example, if the scene has various shades of blue in different parts of the image, and if we use the same average blue for all of them, we lose the details in the image but gain space in storage and transmission.
Ideally, one would like to identify higher-level regularities by analyzing repeated image patterns, for example, texture, objects, and so forth. This allows a higher-level, simpler, and more useful description of the scene, and for example, achieves better compression than compressing at the pixel level.
References:
All rights reserved
