Top machine Learning algorithms
Bài đăng này đã không được cập nhật trong 4 năm
Bài viết này sẽ như là 1 tour đơn giản giới thiệu 1 vòng về cuộc hành trình trong khoa học về dữ liệu và machine learning. Xuyên qua bài viêt này, bạn sẽ có thể làm việc với các vấn đề trong các thuật toán của machine learning với code Python.
Bài viết có lược bỏ các phần có liên quan đến toán thống kê, thực sự nó quá rối rắm để hiểu lúc đầu. Mình đã chán nản khi nhìn vài công thức thống kê khi tìm hiểu về machine learning  .
.

Đầu tiên, bạn cần nắm rõ.
Có 3 loại thuật toán trong Machine Learning
Dưới đây mình sẽ nói về tư tưởng của từng thuật toán.
1. Supervised Learning
Cách thức vận hành : Đây là thuật toát bao gồm một biến mục tiêu / kết quả (hoặc biến phụ thuộc). biến này được dự đoán từ 1 tập hợp các nhân tố ( biến độc lập) . Sử dụng những tập hợp của các biến, chúng ta tạo được một hàm có thể cho phép các kết quả output đúng với dự đoán tương ứng với kết quả input. Quá trình "training" này sẽ tiếp tục cho đến các chúng ta đạt được một độ chính xác mong muốn liên quan đến việc "traing dữ liệu".
Ví dụ của các thuật toán Supervised Learning : Regression, Decision Tree, Random Forest, KNN, Logistic Regression v.v.v…
2. Unsupervised Learning
Cách thức vận hành : Trong thuật toán này, chúng ta không có bất kì biến mục tiêu / kết quả để dự đoán / đánh giá . Nó được sử dụng để phân nhóm các tập dữ liệu vào các nhóm khác nhau. Các nhóm này được sử dụng cho việc phân khúc các "khách hàng' vào các nhóm khác nhau nữa cho mục tiêu cụ thể.
Ví dụ của Unsupervised Learning : thuật toán Apriori, K-means.
3. Reinforcement Learning
Cách thức vận hành : Sử dụng thuật toán này, máy sẽ được luyện tập để ra các quyết định. Máy sẽ được tiếp xúc với một môi trường nơi mà nó được tự luyện tập liên tục sử dụng với phương thức "thử và sửa sai" cho đến khi "sai" đạt đến ngưỡng chấp nhận được hoặc là sẽ bằng 0 trong điều kiện tuyệt đối. Máy sẽ học từ các "kinh nghiệm trong quá khứ" và "học các kiến thức" tốt nhất có thể được để tạo nên các quyết định chính xác về mặt logic business.
Ví dụ của Reinforcement Learning: Markov Decision Process
Dưới đây là danh sách các thuật toán Machine Learning phổ biến. Những thuật toán này có thể được áp dung cho bất kì vấn đề nào về dữ liệu :
- Linear Regression
- Logistic Regression
- Decision Tree
- SVM
- Naive Bayes
- KNN
- K-Means
- Random Forest
- Dimensionality Reduction Algorithms
- Gradient Boost & Adaboost
1. Linear Regression
Line Regression được sử dụng để ước tính giá trị thực (giá nhà, số lượng cuộc gọi, doanh thu bán hàng v.v.v.. dựa trên các biến thay đổi liên tục). Ở đây, chúng ta thiết lập mối quan hệ giữa các biến độc lập và biến phục thuộc bằng cách lắp 1 line tốt nhất.
line này được biết đến như một dòng đệ qui và được biểu diễn bằng công thức Y = a*X + b
Cách tốt nhất để hiểu linear regression là nhớ laị kinh nghiệm tuổi thơ. Hãy xem, bạn yêu cầu một đứa bé lớp 5 sắp mọi người của nó trong lớp bằng thứ tự tăng dần cân năng mà không hỏi cả lớp về cân năng gì cả. Đứa bé sẽ làm gì ? Khả năng cao nó sẽ nhìn vào chiều cao và kết cấu cơ thể để sắp xếp cả lớp sử dụng sự kết hợp các thông số mà nó có thể nhìn thấy. Đây chính là Linear Regression trong đời sống thực. Đứa bé thực tế đã quan sát được chiều và kết cấu cơ thể sẽ có sự tương quan với trọng lượng, đây chính là điều giống như công thức ở trên.
Trong công thức trên :
Y - Biến phục thuộc
a - Slope
X - Biến độc lập
b - Intercept
Các hệ số a và b đều bắt nguồn từ việc giảm thiếu các khoảng chênh lệch bình phương giữa khoảng cách của các điểm dữ liệu và regression line.
Tham khảo ví dụ dưới đây. Ở đây chúng ta đã xác định rõ được line tốt nhất có công thức là y=0.2811x+13.9. Bây giờ, sử dụng công thức này, chúng ta có thể tìm được cân năng, nếu chúng ta biết được chiều cao của một người nào đó.
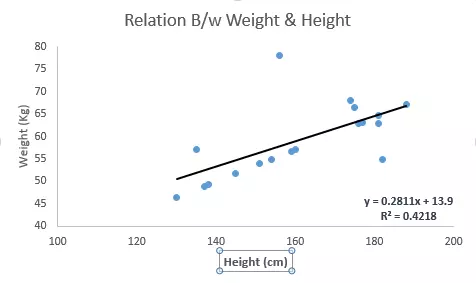
Linear Regression được phân làm 2 loại chính : Simple Linear Regression và Multiple Linear Regression. Simple Linear Regression được đặc trưng bởi một biến đọc lập. Multiple Linear Regression được đặc trung bởi nhiều hơn 1 biến độc lập. Trong khi tìm kiếm line tốt nhất, bạn có thể sẽ tìm được một hôi qui đa thức hoặc đường cong.
#Import Library
#Import other necessary libraries like pandas, numpy...
from sklearn import linear_model
#Load Train and Test datasets
#Identify feature and response variable(s) and values must be numeric and numpy arrays
x_train=input_variables_values_training_datasets
y_train=target_variables_values_training_datasets
x_test=input_variables_values_test_datasets
# Create linear regression object
linear = linear_model.LinearRegression()
# Train the model using the training sets and check score
linear.fit(x_train, y_train)
linear.score(x_train, y_train)
#Equation coefficient and Intercept
print('Coefficient: \n', linear.coef_)
print('Intercept: \n', linear.intercept_)
#Predict Output
predicted= linear.predict(x_test)
2. Logistic Regression
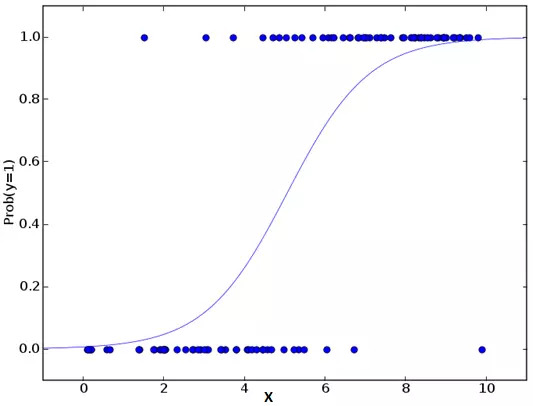
Đừng nhầm lẫn bởi tên của nó ! Đây là một sự phân loại, khoogn phải là một thuật toán hồi qui. Nó được sử dụng để ddanhs giá ước tính các giá trị ời rạc (các giá trị nhị phân) dựa trên tập hợp các biến độc lập. Một cách đơn giản, nó dự đoán xác suất xảy ra của một sử kiện bằng việc khớp dữ liệu với một hàm logit. Do đó, nó còn được gọi là hồi qui logit. Và cũng vì lì do vậy, nó dự đoán xác suất, output của nó luôn nằm giữa 0 và 1.
Một lần nữa, chúng ta hãy cố gắng hiểu thuật toán này thông qua một ví dụ đơn giản .
Hãy giả sử bạn của bạn cho bạn 1 bài toàn để giải. Chỉ có 2 kịch bản kết quả - bản giải được or ko giải được. Bây giờ thử tưởng tượng rằng ban đang được đưa 1 giải các câu đố/toán/quizz để có thể hiểu được bản thân là bạn phù hợp với types câu đố nào. Kết quả của việc nghiên cứu bản thân này sẽ trông như thế này - nếu bạn được đưa một vấn đề kiểu giải đố toán lớp 10, bạn có 70% xác suất giải được nó. Nếu nó là câu hỏi lịch sử của lớp 5, xác suất chỉ còn 30%. Đây chính là Logistic Regression.
Quay trở về với toán, các tỷ lệ log kết quả được mô hình hóa bằng sự kết hợp tuyến tính của các biến dự đoán.
odds= p/ (1-p) = probability of event occurrence / probability of not event occurrence
ln(odds) = ln(p/(1-p))
logit(p) = ln(p/(1-p)) = b0+b1X1+b2X2+b3X3....+bkXk
Ở trên, p là xác suất của các sự hiện diện của các đặc tính cần quan tâm. Nó chọn các param có thể tối đa hóa sự chuẩn xác của các giá trị mẫu hơn là việc giảm thiểu bình phương lỗi (giảm thiểu bình phương lỗi là cách tiếp cận của hồi qui thông thường)
Bây giờ, bạn có thể hỏi, tại sao phải log ? Để không đi sâu quá nhiều vào toán học trong bài viết này, tôi sẽ nói một cách đơn giản là việc log là một trong số những cách tốt nhất của toán học để mô phỏng lại một step function.
#Import Library
from sklearn.linear_model import LogisticRegression
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create logistic regression object
model = LogisticRegression()
# Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)
#Equation coefficient and Intercept
print('Coefficient: \n', model.coef_)
print('Intercept: \n', model.intercept_)
#Predict Output
predicted= model.predict(x_test)
3. Decision Tree
Đây là một trong những thuật toán yêu thích của tôi và tôi sử dụng nó khá thường xuyên. Nó là một loại thuật toán supervised learning được sử dụng chủ yếu cho các vấn đề phân loại. Đáng ngạc nhiên, nó hoạt động cho cả hai biến phụ thuộc phân loại và biến phụ thuộc liên tục. Trong thuật toán này, chúng ta chia "population" thành hai hoặc các nhóm tập hợp. Điều này được thực hiện dựa trên các biến thuộc tính quan trọng nhất / các biến độc lập để phân loại các groups có thể được. Để biết thêm, bạn có thể đọc: Decision Tree Simplified.
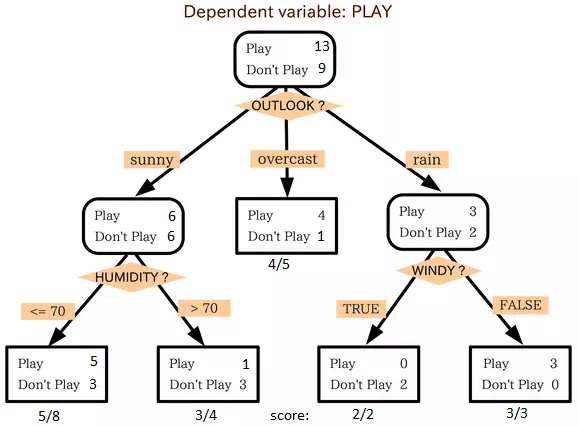
Trong hình trên, bạn có thể thấy "population" được phân thành bốn groups khác nhau dựa trên nhiều thuộc tính để xác định 'Liệu họ sẽ chơi hay không ? ". Để chia "population" thành các nhóm đồng nhất khác nhau, chúng ta sử dụng các kỹ thuật khác nhau như Gini, Information Gain, Chi-square, entropy.
Cách tốt nhất để hiểu làm thế nào cây quyết định hoạt động, là chơi trò Jezzball - một trò chơi cổ điển từ Microsoft (hình dưới đây). Về cơ bản, bạn có một căn phòng với những bức tường di chuyển và bạn cần tạo ra bức tường mà diện tích tối đa được xóa đi với các quả bóng.
Vì vậy, mỗi khi bạn chia phòng với một bức tường, bạn đang cố gắng để tạo ra 2 "population" khác nhau trong cùng một phòng. Decision trees làm việc bằng cách chia một "population" vào các nhóm khác nhau trong khả năng có thể.
#Import Library
#Import other necessary libraries like pandas, numpy...
from sklearn import tree
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create tree object
model = tree.DecisionTreeClassifier(criterion='gini') # for classification, here you can change the algorithm as gini or entropy (information gain) by default it is gini
# model = tree.DecisionTreeRegressor() for regression
# Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)
#Predict Output
predicted= model.predict(x_test)
4. SVM (Support Vector Machine)
Đây là một phương pháp phân loại. Trong thuật toán này, chúng ta sẽ vẽ mỗi mục dữ liệu như là một điểm trong không gian n-chiều (n là số tính năng) với các giá trị của mội tính năng là các giá trị của một trục tọa độ cụ thể.
Ví dụ, nếu chúng ta có 2 tính năng là Chiều cao và Độ dài tóc của một cá nhân, đầu tiên chúng ta sẽ có 2 biến với 2 chiều không gian nơi một điểm có 2 tọa độ.
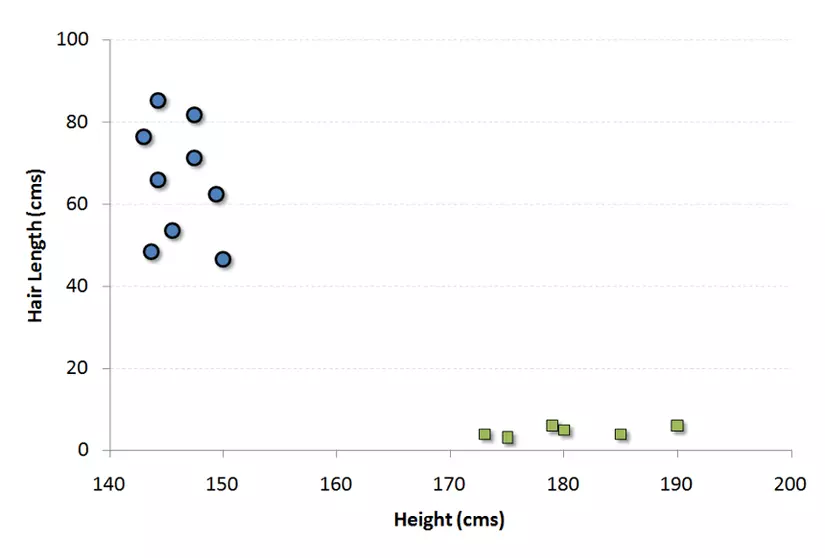
Bây giờ, chúng ta sẽ tìm một vài lines mà phân tách dữ liệu giữa 2 nhóm dữ liệu khác nhau đã được phân loại. Line này sẽ có tinh chaatgs là khoảng cách từ điểm gần nhất đến line trong mỗi groups sẽ là xa nhất.
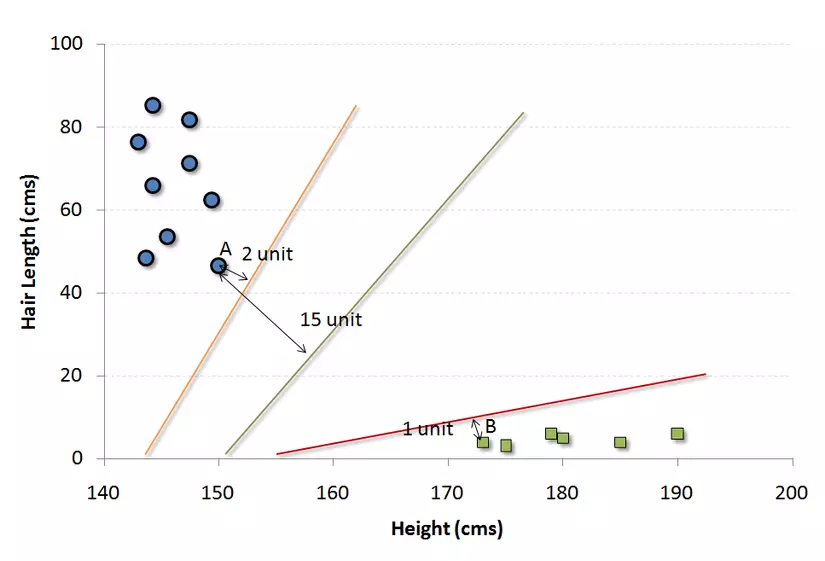
Trong ví dụ ở trên, line phân tách dữ liệu thành 2 nhóm là line đen vì khoảng cách của điểm gần nhất đến line là xa nhất. Line này chính là "phân loại". Sau đó, tùy thuộc vào dữ liệu tiếp theo sẽ nằm ở phía nào của line, chúng ta lại thực hiện việc phân tách dữ liệu mới.
#Import Library
from sklearn import svm
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create SVM classification object
model = svm.svc() # there is various option associated with it, this is simple for classification. You can refer link, for mo# re detail.
# Train the model using the training sets and check score
model.fit(X, y)
model.score(X, y)
#Predict Output
predicted= model.predict(x_test)
5. Naive Bayes
Đây là một ký thuật phân lọa dựa trên định lý Bayes với một giả định độc lập giữa các dự đoán. Nói một cách đơn giản, một phân loại Naive Bayes giả định rằng sự hiện diện của một tính năng cụ thể trong class không liên quan đến sự hiện hiện của tính năng khác. Ví dụ, một trái cây có thể đc coi là quả táo nếu not màu đỏ, tròn và đường kính khoảng 3 inch. Thậm chí, nếu các tính năng đó phụ thuộc vào nhau hoặc sự tồn tồn tại của các tính khác, một phân loại naive Bayes sẽ cân nhắc tất cả mọi tính chất để tính toán một cách độc lập xác suât lại trái cây này quả táo hay ko ?
Mô hình Naive bayesian khá dễ để xây dựng và hữu dụng cho tập dữ liệu lớn. Cùng với sự đơn giản của nó, mô hình này được biết đến với việc outperform các phương pháp phân loại tinh vi hơn khác.
Định lý Bayes cung cấp một cách để tính toán xác suất P(c|x) từ P(c), P(x) và P(x|c). Hãy nhìn công thức dưới

Ví dụ: Dưới đây tôi có một tập dữ liệu training của thời tiết và biến mục tiêu tương ứng 'Play'. Bây giờ, chúng ta cần phải phân loại cho dù người chơi sẽ chơi hay không dựa trên điều kiện thời tiết. Hãy làm theo các bước dưới đây để thực hiện nó.
Bước 1: Chuyển đổi các dữ liệu thành bảng tần số
Bước 2: Tạo bảng "Khả năng" bằng cách tìm các xác suất như "khả năng trời u ám ám" = 0,29 và "khả năng PLAY" = 0,64.
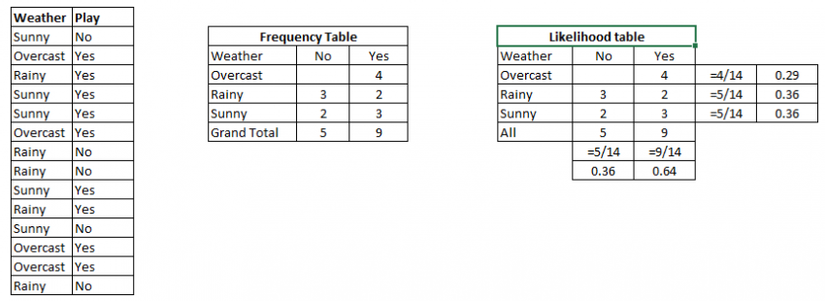
Bước 3: Bây giờ, sử dụng phương trình Bayesian Naive để tính toán xác suất hậu nghiệm cho mỗi lớp. Các nhóm với xác suất hậu nghiệm cao nhất là kết quả của dự đoán.
Vấn đề: Liệu người chơi sẽ PLAY nếu thời tiết nắng, là tuyên bố này là đúng?
Chúng tôi có thể giải quyết nó bằng phương pháp thảo luận ở trên, do đó P (Yes | Sunny) = P (Sunny | Yes) * P (Yes) / P (Sunny)
Ở đây chúng ta có P (Sunny | Yes) = 3/9 = 0.33, P (Sunny) = 5/14 = 0,36, P (Yes) = 9/14 = 0,64
Bây giờ, P (Yes | Sunny) = 0,33 * 0,64 / 0,36 = 0,60, với xác suất cao hơn.
Naive Bayes sử dụng một phương pháp tương tự để dự đoán xác suất của các nhóm khác nhau dựa trên các thuộc tính khác nhau. Thuật toán này được sử dụng chủ yếu trong phân loại văn bản text có nhiều class.
#Import Library
from sklearn.naive_bayes import GaussianNB
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create SVM classification object model = GaussianNB() # there is other distribution for multinomial classes like Bernoulli Naive Bayes, Refer link
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
6. KNN (K- Nearest Neighbors)
Thuật toán này được sử dụng cho cả viecj phân loại và hồi qui. Tuy nhiên, nó được sử dụng nhiều hơn trong vấn đề phân loại. kNN là một thuật toán khá đơn giản : tìm kiếm k hàng xóm gần nhất (gần nhất trong một khái niệm nào đó ) so với vị trí đang xét đến.
Các hàm tính khoảng cách có thể là các hàm Euclidean, Manhattan, Minkowski và Hamming. Đầu tiên, 3 hàm ở đầu đều được sử dụng cho các hàm liên tục và hàm thứ 4 (Hamming) thì cho các biến phân loại.
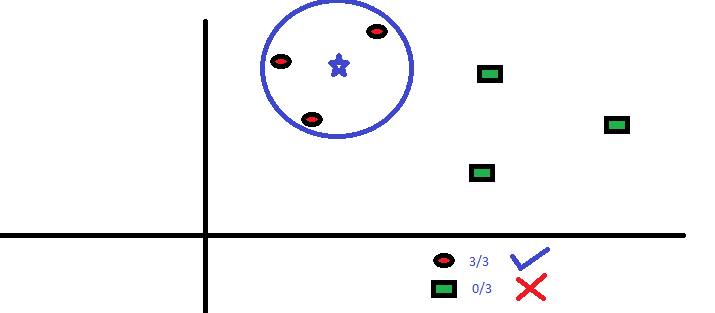
kNN có thể dễ dàng được liên tưởng đến trong cuộc sống đời thực. Nếu bạn muốn tìm hiểu về một người - người mà bạn ko có tí thông tin nào, bạn sẽ tìm hiểu hiểu đó bằng cách tiếp cận bạn bè của người đó và vòng tròn circle xung quanh ng đó để đạt thông tin mà bạn muốn.
#Import Library
from sklearn.neighbors import KNeighborsClassifier
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create KNeighbors classifier object model
KNeighborsClassifier(n_neighbors=6) # default value for n_neighbors is 5
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
7. K-Means
Đây là một loại thuật toán unsupervised algorithm giải quyết các vấn đề về phân nhóm. Cách thức của nó khá đơn giản : phân tách dữ liệu thành một nhóm các cluster ( giả sử k cái) . Các điểm dữ liệu bên trong cluster là đòng nhất và không đồng nhất với các điểm dữ liệu của các nhóm khác.
Bạn có để ý vết mực bị đổ ra trên bàn không ? k means khá tương tự với việc này. Bạn nhìn vào vết mục và hình dạng lan rộng để giã mã có bao nhiêu cluster khác nhau / có bao nhiêu nhóm "population"

Cách mà K-Means tạo nên các cluster
*k-means chọn k điểm cho mỗi clustervà được gọi là trọng tâm.
- Mỗi điểm dữ liệu tạo thành một
clustervới trọng tâm gần nhất - Tìm kiếm trọng tâm của mỗi
clusterdựa trên các thành viên bên trong mỗicluster. Ở đây chúng ta sẽ có các trọng tâm mới. - Khi có các trọng tậm mới, lặp lại bước 2 và bước 3. Tìm kiếm khoanrgcacsh gần nhất của mỗi điểm dữ liệu tạo nên bởi các trọng tâm mới và được liên kết với
k-clustermới. Lặp lại quá trình này cho đến khi các trọng tâm hội tụ thành một điểm.
Cách thức tìm kiếm giá trị k :
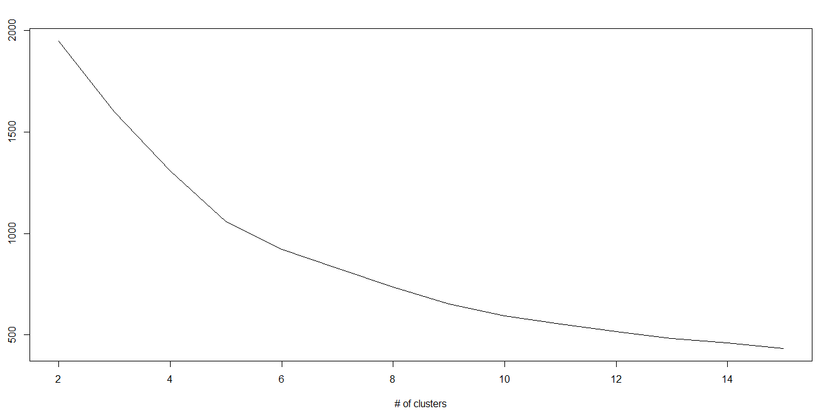
Trong k-means, chúng ta có các cluster và mối cluster có trọng tâm của nó. Tổng bình phương khác biệt giữa trọng tâm và các điểm dữ liệu trong cluster tạo nên tổng giá trị bình phương chocluster đó.
Chúng ta biết rằng khi số lượng cluster được tăng lên, giá trị sẽ giảm đi nhưng nếu bạn quan sát kết qua, bạn sẽ thấy rằng tổng bình phương khoảng cách sẽ giảm mạnh đến một giá trị k, sau đó nó sẽ giảm chậm đi. Tại đây, bạn có thể tìm kiếm số lượng tối ưu của cluster - giá trị k.
#Import Library
from sklearn.cluster import KMeans
#Assumed you have, X (attributes) for training data set and x_test(attributes) of test_dataset
# Create KNeighbors classifier object model
k_means = KMeans(n_clusters=3, random_state=0)
# Train the model using the training sets and check score
model.fit(X)
#Predict Output
predicted= model.predict(x_test)
8. Random Forest
Random Forest là một thuật ngữ nổi tiến cho một tập hợp các cây quyết định (decision trees). Trong Random Forest, chúng ta tập hợp các desicion trees (được gọi là Forest). Để phân biệt một đối tượng mới dựa trên các thuộc tính, mỗi tree được cho một phân loại và chúng ta sẽ nói rằng mỗi tree sẽ vote cho loại đó. Forest sẽ chọn các phân lọai có nhiều votes nhất (thông qua toàn thể tree trong forest).
Mỗi tree được trồng và phát triển. Vì tính phức tạp khá lằng nhằng nên mình xin phép không đề cập trong bài viết này.
#Import Library
from sklearn.ensemble import RandomForestClassifier
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create Random Forest object
model= RandomForestClassifier()
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
9. Dimensionality Reduction Algorithms
Trong 4-5 năm qua, có có khá nhiều sự gia tăng mạnh mẽ trọng việc thu giữ các stage có thể được. Cơ quan / Chính phủ các doanh nghiệp / tổ chức nghiên cứu cũng đang thực hiện thụ thập dữ liệu khá chi tiết.
Ví dụ : Các công ty thương mại điện tử đang nắm bắt thêm thông tin chi tiết về khách hàng như nhân khẩu học của họ, lịch sử crawl web, những gì họ thích hay không thích, lịch sử mua hàng, thông tin phản hồi và nhiều thứ khác để cung cấp cho họ sự quan tâm cá nhân hơn.
Dữ liệu bao gồm khá nhiều tính năng, điều này có vẻ tốt cho việc xây dựng một mô hình ổn điịnh vững chắc nhưng thực sự rất thách thức. Làm cách nào bạn có thể xác định các biến có độ quan trọng cao trong khoảng 1000 or 2000 biến ? Trong các trường hợp này, thuật toán Dimensionality Reduction Algorithms sẽ hỗ trợ chúng ta kết hợp với các thuật toán khác như Decision Tree, Random Forest, PCA, Factor Analysis, Identify based on correlation matrix, missing value ratio v.v.v....
#Import Library
from sklearn import decomposition
#Assumed you have training and test data set as train and test
# Create PCA obeject pca= decomposition.PCA(n_components=k) #default value of k =min(n_sample, n_features)
# For Factor analysis
#fa= decomposition.FactorAnalysis()
# Reduced the dimension of training dataset using PCA
train_reduced = pca.fit_transform(train)
#Reduced the dimension of test dataset
test_reduced = pca.transform(test)
10. Gradient Boosting & AdaBoost
GBM & AdaBoost đang thúc đẩy các thuật toán được sử dụng khi chúng ta đối phó với rất nhiều dữ liệu để đưa ra dự đoán với công suất dự đoán cao. Boosting là một thuật toán "học quần thể" kết hợp với các dự báo của một vài estimator để cải thiện mạnh mẽ hơn một estimator duy nhất. Nó kết hợp nhiều yếu tố dự báo yếu hoặc trung bình để tạo nên một yếu tố dự báo mạnh mẽ. Các thuật toán Boosting luôn thể hiện tốt trong các cuộc thi khoa học dữ liệu như Kaggle, AV Hackathon, CrowdAnalytix.
#Import Library
from sklearn.ensemble import GradientBoostingClassifier
#Assumed you have, X (predictor) and Y (target) for training data set and x_test(predictor) of test_dataset
# Create Gradient Boosting Classifier object
model= GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1, random_state=0)
# Train the model using the training sets and check score
model.fit(X, y)
#Predict Output
predicted= model.predict(x_test)
End Notes
Bây giờ , hẳn bạn đã có một chút tư duy về các thuật toán cơ bản được sử dụng rộng rãi trong machine learning. Mục đích duy nhất của bài viết này là cung cấp tư tưởng của các thuật toán - cách tư duy và code Python để các bạn hiểu hơn về nó.
Nguồn dịch
https://www.analyticsvidhya.com/blog/2015/08/common-machine-learning-algorithms/
Tham khảo
http://machinelearningmastery.com/a-tour-of-machine-learning-algorithms/
http://www.kdnuggets.com/2016/08/10-algorithms-machine-learning-engineers.html
All rights reserved
