
Ensemble learning và các biến thể (P1)
Bài đăng này đã không được cập nhật trong 6 năm
I. Khái niệm
"Đoàn kết là sức mạnh". Tôi không biết câu này xuất hiện ở đâu khi nào nhưng nó lại khái quát ý tưởng của phương thức Ensemble trong Machine Learning.
Lấy ví dụ thế này, bạn có 1 model nhưng đầu ra của model đó không tốt nên bạn thử các model khác. Sau khi tìm được model ưng ý và "có lẽ chính xác", bạn lại phải chỉnh chỉnh sửa sửa từ thuật toán đến hyperparameter để mô hình đạt độ chính xác cao nhất. Tất cả những việc kể trên sẽ ngốn của bạn một đống thời gian bởi bạn phải chạy từng model một, thế nên để nhanh hơn bạn kết hợp những model "học yếu" này lại để tạo ra một model "học mạnh" hơn, không những thế kết quả thu được cũng tốt hơn so với từng model một.
Để hiểu sâu thêm, chúng ta sẽ làm rõ khái niệm mô hình "yếu" và "mạnh".
Khi làm các bài toán về phân loại (classification) hay hồi quy (regression), chắc ai cũng biết phần quan trọng nhất là lựa chọn model. Việc chọn này phụ thuộc nhiều yếu tố: số lượng data, đặc điểm data (số chiều, phân phối), v.v...Từ đó ta sẽ có tương quan giữa data và model (bias-variance tradeoff) aka (mối quan hệ đánh đổi giữa bias và variance). Ok, tôi sẽ không đi chi tiết khái niệm này bởi nó cũng ngốn kha khá thời gian, các bạn có thể tham khảo ở đây (https://forum.machinelearningcoban.com/t/moi-quan-he-danh-doi-giua-bias-va-variance/4173).
Nói chung là không có một model nào hoàn hảo khi đi riêng lẻ bởi quy tắc tradeoff trên, các model này có điểm yếu rõ rệt như có cái bị high bias (model dự đoán sai so với giá trị thực tế rất nhiều) hay có cái bị high variance (đoán đúng trên bộ dữ liệu train nhưng tạch với bộ dữ liệu chưa gặp bao giờ), nên chúng đều bị gọi là "yếu". Vậy tại sao ta không kết hợp các model "yếu" để tạo ra một model "mạnh" đúng với câu " 3 cây chụm lại nên hòn núi cao" để giảm bias / variance.
II. Kết hợp các model "yếu" như thế lào ???
Ok, tóm lại là tôi có một đống model "yếu" và tôi muốn kết hợp thành một model "mạnh", hiệu quả hơn. Vậy tôi phải follow các bước sau:
First, chọn model sẽ làm base model cho cả thuật toán. Thường thì một model sẽ được chọn ra (ví dụ là Decision Tree), ta lại cần nhiều mô hình "yếu" nên ta phải tăng số lượng model cần dùng lên => ta có n model Decision Tree <- ví dụ thôi nhé  . NHƯNG chỉ giống nhau chưa đủ, các model này sẽ được train theo nhiều cách khác nhau. Tất nhiên cũng có vài phương pháp sử dụng các model khác nhau rồi kết hợp chúng lại (cái này nói sau).
. NHƯNG chỉ giống nhau chưa đủ, các model này sẽ được train theo nhiều cách khác nhau. Tất nhiên cũng có vài phương pháp sử dụng các model khác nhau rồi kết hợp chúng lại (cái này nói sau).
Một điểm quan trọng trong khi chọn model ở đây là chúng ta nên chọn model phù hợp với chiến thuật mà chúng ta lựa chọn ban đầu. Như các model có bias thấp nhưng variance cao vậy thì khi ta kết hợp chúng lại để tạo ra một model mạnh hơn, model tổ hợp này phải có xu hướng giảm variance. Ngược lại các model có bias cao nhưng variance thấp, model tổ hợp phải có xu hướng giảm bias. Điều này dẫn đến câu hỏi làm thế nào để kết hợp các model "yếu" lại với nhau.
Second, đến phần quan trọng rồi :3. Xin giới thiệu với các bạn 3 biến thể của phương thức ensemble learning được dùng khá nhiều hiện nay:
- Bagging: Xây dựng một lượng lớn các model (thường là cùng loại) trên những subsamples khác nhau từ tập training dataset (random sample trong 1 dataset để tạo 1 dataset mới). Những model này sẽ được train độc lập và song song với nhau nhưng đầu ra của chúng sẽ được trung bình cộng để cho ra kết quả cuối cùng.
- Boosting: Xây dựng một lượng lớn các model (thường là cùng loại). Mỗi model sau sẽ học cách sửa những errors của model trước (dữ liệu mà model trước dự đoán sai) -> tạo thành một chuỗi các model mà model sau sẽ tốt hơn model trước bởi trọng số được update qua mỗi model (cụ thể ở đây là trọng số của những dữ liệu dự đoán đúng sẽ không đổi, còn trọng số của những dữ liệu dự đoán sai sẽ được tăng thêm) <Well, có thể hơi khó hiểu tí nhưng tôi sẽ giải thích rõ hơn cho các bạn sau>. Chúng ta sẽ lấy kết quả của model cuối cùng trong chuỗi model này làm kết quả trả về (vì model sau sẽ tốt hơn model trước nên tương tự kết quả sau cũng sẽ tốt hơn kết quả trước).
- Stacking: Xây dựng một số model (thường là khác loại) và một meta model (supervisor model), train những model này độc lập, sau đó meta model sẽ học cách kết hợp kết quả dự báo của một số mô hình một cách tốt nhất.
Trong 3 biến thể trên thì Bagging giúp ensemble model giảm variance. Còn Boosting và Stacking tập trung vào việc giảm bias (cũng giảm cả variance).
Tiếp theo đó, tôi sẽ giới thiệu chi tiết hơn về Bagging, còn Boosting và Stacking thì trong phần tiếp theo 
III. Tập trung vào Bagging
Nhắc lại một lần nữa, với Bagging, chúng ta xây dựng một lượng lớn các model (thường là cùng loại) trên những subsamples khác nhau từ tập training dataset. Những model này sẽ được train độc lập và song song với nhau nhưng đầu ra của chúng sẽ được trung bình cộng để cho ra kết quả cuối cùng.
Bootstrapping
Đây là một kỹ thuật thống kê từ 1 bộ dữ liệu N sinh ra B bộ dữ liệu mới (bootstrap samples) (thường có kích thước với bộ dữ liệu ban đầu). Mình sẽ không đi sâu vào kỹ thuật này vì thời lượng có hạn (chung quy là lười  ). Dưới đây là một ví dụ ngắn về kỹ thuật này, áp dụng trên bộ dữ liệu Sonar:
). Dưới đây là một ví dụ ngắn về kỹ thuật này, áp dụng trên bộ dữ liệu Sonar:
# dataset: bộ dữ liệu ban đầu
# ratio: kích thước của bộ dữ liệu mới được quyết định theo %
def subsample(dataset, ratio=1.0):
sample = list()
n_sample = round(len(dataset) * ratio)
while len(sample) < n_sample:
index = randrange(len(dataset))
sample.append(dataset[index])
return sample
Các bạn có thể tham khảo thêm (https://towardsdatascience.com/an-introduction-to-the-bootstrap-method-58bcb51b4d60)
Bagging
Khi train một model, bất kể đó là classification hay regression, ta đều phải định nghĩa 1 hàm nhận đầu vào và trả về đầu ra xác định bởi kết quả training. Như thế, với đầu vào khác nhau chúng ta sẽ có nhiều model khác nhau, sơ sơ là thế.
Ý tưởng về bagging khá đơn giản: mình fit một đống model trên B bootstrap samples và tính trung bình cộng kết quả dự đoán của các model đó nhằm kiếm được một model có variance thấp. NHƯNG việc fit độc lập từng model cần nhiều dữ liệu mà bạn biết đấy dữ liệu thì đào đâu ra  . Cho nên chúng ta đành phải tạo bộ dữ liệu mới dựa trên bộ dữ liệu cũ bằng kỹ thuật bootstrapping. Những dữ liệu mới này có phân phối giống nhau và gần như độc lập nên cũng không ảnh hưởng tới kết quả cuối cùng tổng hợp từ các model "yếu", việc tính trung bình cộng đầu ra của các base model này cũng sẽ giảm variance.
. Cho nên chúng ta đành phải tạo bộ dữ liệu mới dựa trên bộ dữ liệu cũ bằng kỹ thuật bootstrapping. Những dữ liệu mới này có phân phối giống nhau và gần như độc lập nên cũng không ảnh hưởng tới kết quả cuối cùng tổng hợp từ các model "yếu", việc tính trung bình cộng đầu ra của các base model này cũng sẽ giảm variance.
Sơ lược dưới dạng toán học:
Ta có L bootstrap samples (tương ứng với L bộ dữ liệu) có kích thước B.
![]()
Tương ứng với L bộ dữ liệu là L model "yếu".
Kết hợp các model này lại, ta được một model mới mạnh hơn. Với những vấn đề khác nhau, như regression, đầu ra của các model "yếu" sẽ được trung bình cộng, kết quả này sẽ là đầu ra của model "mạnh". Còn với classification, class đầu ra của mỗi một model "yếu" sẽ được coi là 1 vote và class mà nhận được số vote nhiều nhất sẽ là đầu ra của model "mạnh" (cách này gọi là hard-voting). Trong trường hợp model "yếu" dự đoán xác suất của tất cả class thì ta sẽ tính trung bình cộng của xác suất của từng class rồi lấy xác suất có giá trị lớn nhất (cách này gọi là soft-voting).
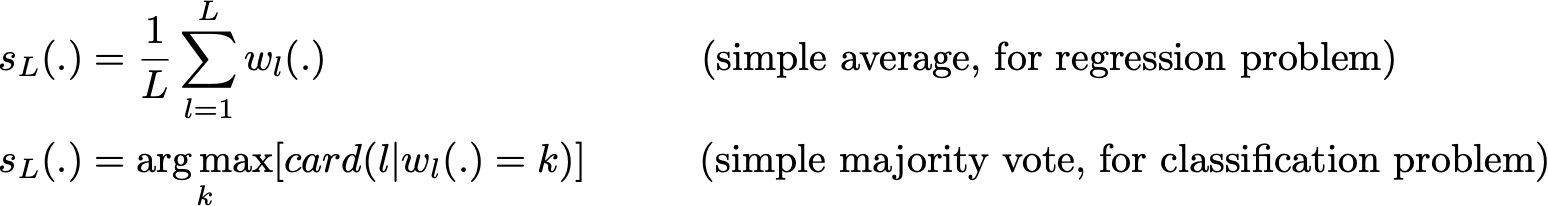
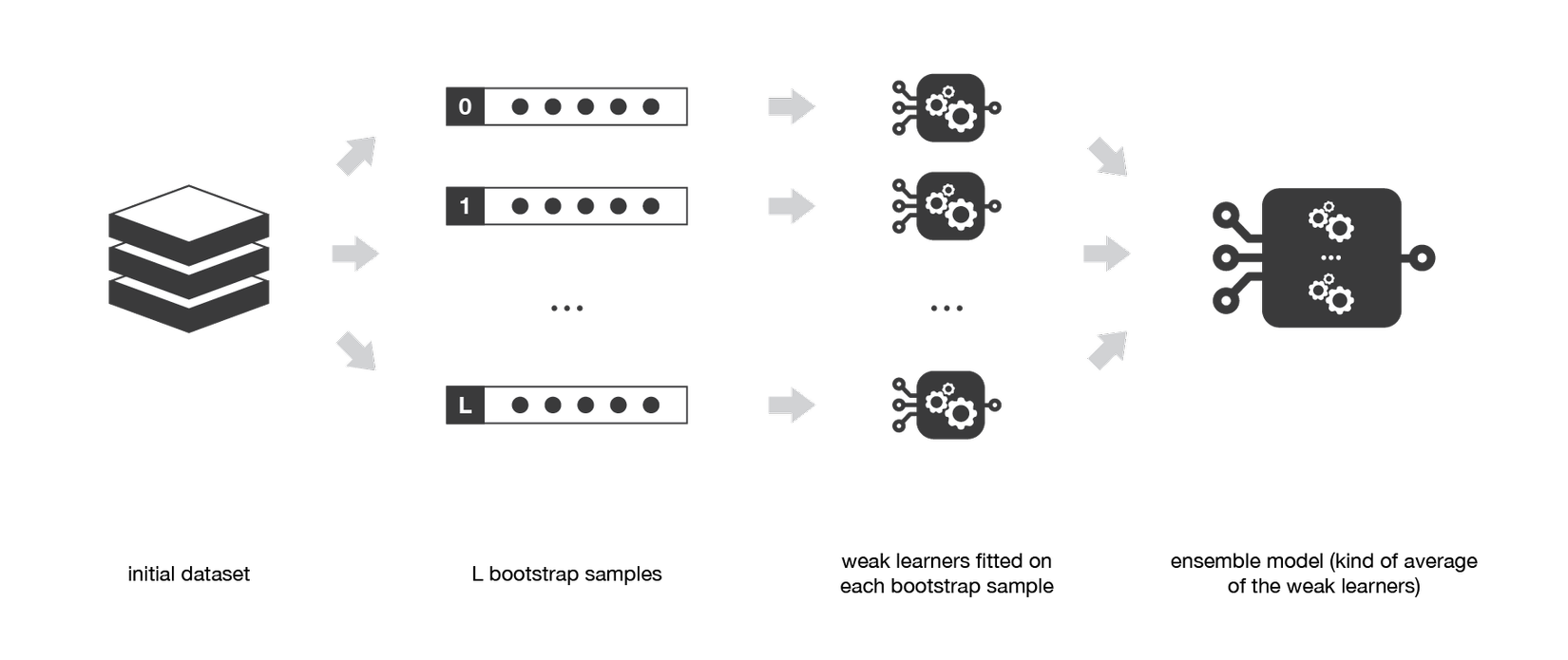
Cuối cùng, để chốt phần lý thuyết và sang phần code, tôi sẽ chỉ ra một trong những lợi ích mà bagging mang lại, đó là tính song song. Như hình dưới, bạn sẽ thấy phần core của bagging đều là tiến trình song song nên nếu bạn có con máy khỏe, bạn có thể train từng model song song với nhau và cuối cùng tổng hợp đầu ra của các model này lại.
Code of Bagging
Thật may cho chúng ta, thư viện sklearn đã hỗ trợ mọi thứ đến tận răng 
Với bagging dành cho regression:
# Code dễ hiểu đúng không :D
from sklearn.svm import SVR
from sklearn.ensemble import BaggingRegressor
from sklearn.datasets import make_regression
X, y = make_regression(n_samples=100, n_features=4,
n_informative=2, n_targets=1, random_state=0, shuffle=False)
regr = BaggingRegressor(base_estimator=SVR(), n_estimators=10, random_state=0).fit(X, y)
regr.predict([[0, 0, 0, 0]])
Với bagging dành cho classification:
from sklearn.svm import SVC
from sklearn.ensemble import BaggingClassifier
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=100, n_features=4,
n_informative=2, n_redundant=0, random_state=0, shuffle=False)
clf = BaggingClassifier(base_estimator=SVC(),
n_estimators=10, random_state=0).fit(X, y)
clf.predict([[0, 0, 0, 0]])
Random forests
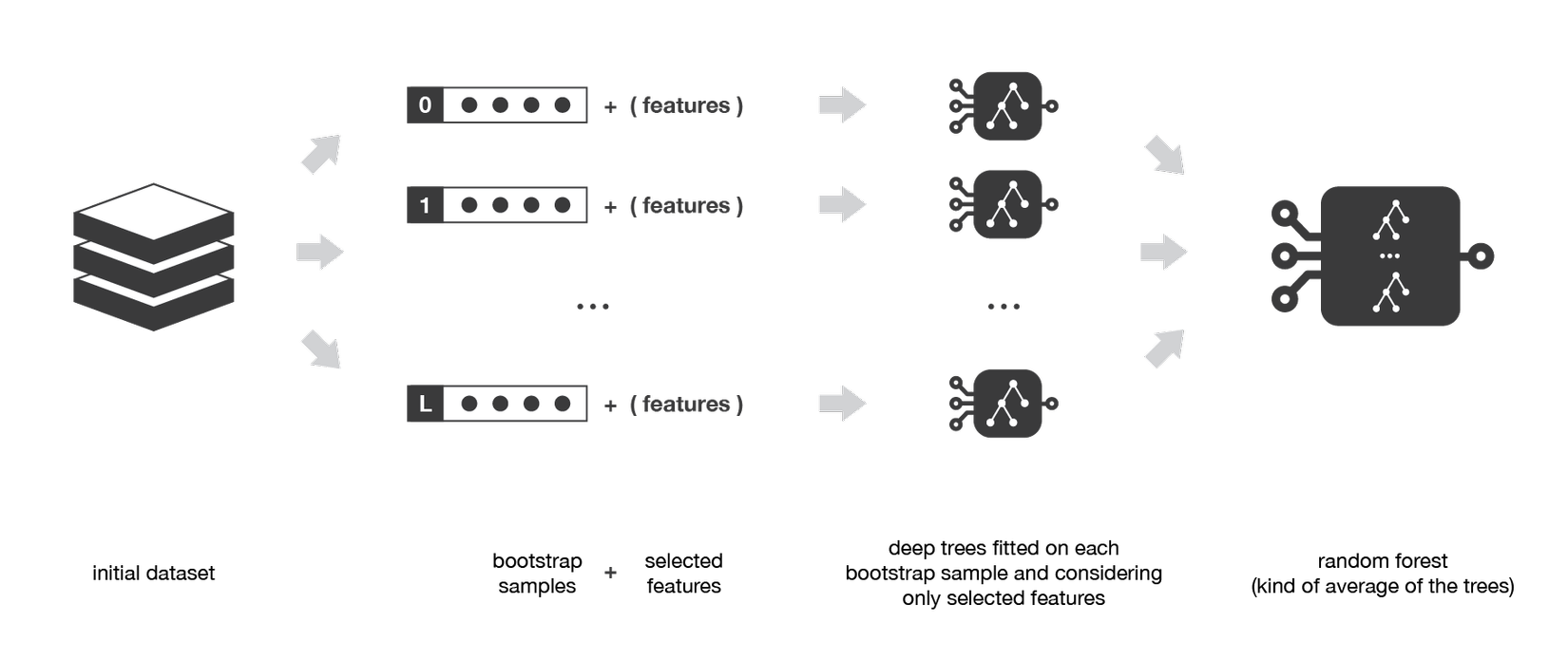
Model này là một ví dụ điển hình của phương thức Bagging. Tôi sẽ giả định các bạn đã hiểu khái niệm của random forests bởi giải thích nó cũng tốn kha khá thời gian (tôi sẽ chỉ tập trung vào ensemble và các biến thể của nó nên thông cảm nhé ).
Random forests là một tổ hợp của một đống Decision Tree, trong khi phát triển Tree, model này dùng một trick khác trong việc sinh dữ liệu: thay vì chỉ lấy mẫu qua observation trong tập dữ liệu để sinh mẫu, ta sẽ lấy mẫu trên tất cả features và chỉ lấy ngẫu nhiên 1 tập con để xây dựng tree.
Ví dụ
Ta có 1 bộ dữ liệu:
1, 2, 3, 4, 5
6, 7, 8, 9, 10
Thông thường ta sẽ sinh ra bộ subsample mới:
1, 3, 5, 4, 2
8, 9, 7, 10, 6
Còn với Random Forests:
9, 6, 5, 10, 2
8, 4, 7, 1, 3
Với cách xây dựng dữ liệu của random forests, tất cả các trees sẽ không sợ đầu vào giống nhau aka đầu ra của các trees khác nhau. Một lợi ích khác của trick này sẽ giúp Decision Tree hoạt động hiệu quả hơn khi thiếu dữ liệu aka observations.
III. End
Tôi sẽ kết thúc phần 1 bài viết ở đây, phần 2 sẽ tập trung vào boosting và stacking. Nếu có gì sai sót thì hãy góp ý nhé. Bài viết trên dựa trên ý hiểu của tôi và có một phần dịch lại sau khi tham khảo một cơ số bài viết trên medium, blog, v.v... Nếu bạn muốn có cái nhìn tổng quan hơn thì nên tham khảo thêm các link dưới đây.
Source
https://towardsdatascience.com/ensemble-methods-bagging-boosting-and-stacking-c9214a10a205
https://machinelearningmastery.com/implement-bagging-scratch-python/
https://svcuonghvktqs.github.io/data-science/ensemble-learning
Cám ơn đã đọc bài viết của tôi. See u again 
All rights reserved
