Where do I find datasets for my machine learning research?
Bài đăng này đã không được cập nhật trong 8 năm
We all know "Data" is king in the field of machine learning because the machine learning algorithm needs data to train and improve its model either testing or production model. Luckily, nowadays data is everywhere. Today, I am going show you where I get the dataset for my machine learning research. There are two methods which I use to collect the dataset for my machine.
1. Download dataset where available online
There are lots of websites that hosts machine learning datasets which we can use for our machine learning research. And here the list of website where I regularly use to find the data I need:
- Kaggle is social network for data scientist. This platform has lots of real-world datasets which host by companies around the world in form of competition to solve their real-world problem. It is the go to site for me when I want to find the dataset I need. Ex: titanic dataset, house pricing, face expression .etc.
- UC Irvine Machine Learning Repository is a collection of databases, domain theories, and data generators that are used by the machine learning community for the empirical analysis of machine learning algorithms.
- ImageNet is an image database where you can use them to fit into you build object detection model.
- U.S. Government’s open data where you can find US government's open data that related various fields such as: agriculture, climate, consumer, education .etc.
- Open Data for Deep Learning where you’ll find an organized list of interesting, high-quality datasets for machine learning research.
- http://cocodataset.org/#download
- https://www.cs.toronto.edu/~kriz/cifar.html
- http://academictorrents.com/
- https://drive.google.com/drive/u/0/folders/0Bz8a_Dbh9Qhbfll6bVpmNUtUcFdjYmF2SEpmZUZUcVNiMUw1TWN6RDV3a0JHT3kxLVhVR2M
- https://github.com/openimages/dataset
and more ..
2. Web scraping
Sometimes, there is no dataset that matches your specifict problems, but it may be available on some website. So we can write few line of code to collect those information.
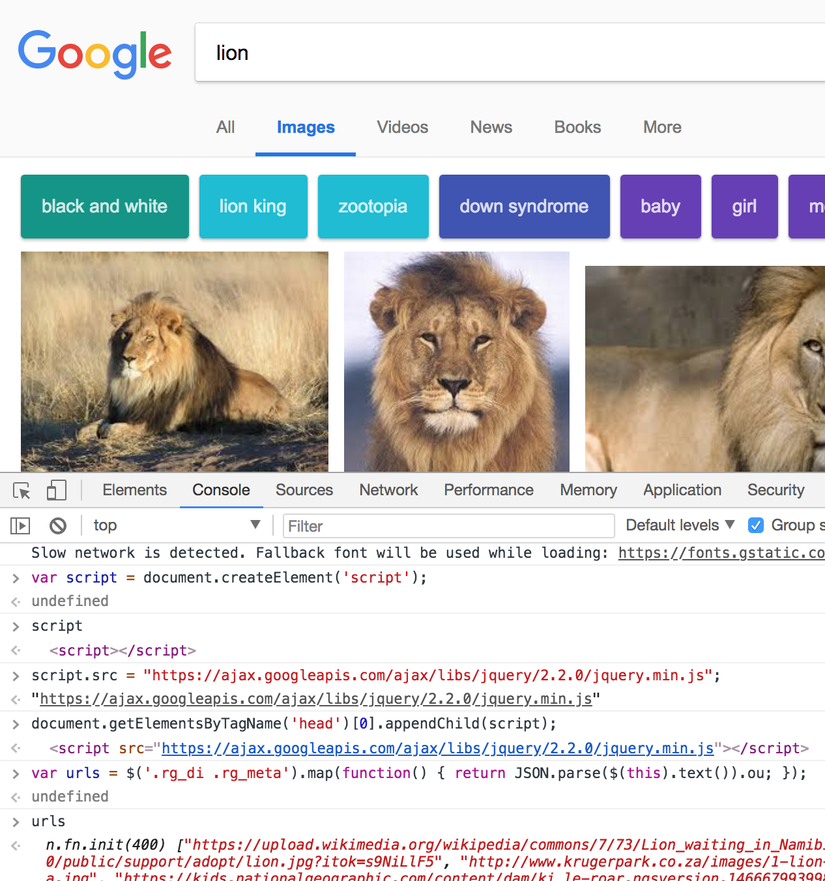
For example, after we usedog/cat dataset from ImageNet to train our model, we want to test our model on difference dataset ex: "lion". So we need to find dataset for that, and google image is a good place to find them.
Now, let's write sample code to scrape the image of "lion" from google image(you may need scroll down to get more image) then save it into file.
// pull down jquery then append into document header
var script = document.createElement('script');
script.src = "https://ajax.googleapis.com/ajax/libs/jquery/2.2.0/jquery.min.js";
document.getElementsByTagName('head')[0].appendChild(script);
// grab the images URLs
var urls = $('.rg_di .rg_meta').map(function() { return JSON.parse($(this).text()).ou; });
// write the URls to file (one per line)
var textToSave = urls.toArray().join('\n');
// create an "a" tag
var hiddenElement = document.createElement('a');
// add some attribute to element
hiddenElement.href = 'data:attachment/text,' + encodeURI(textToSave);
hiddenElement.target = '_blank';
// add link urls file
hiddenElement.download = 'urls.txt';
// trigger click even on element
hiddenElement.click();
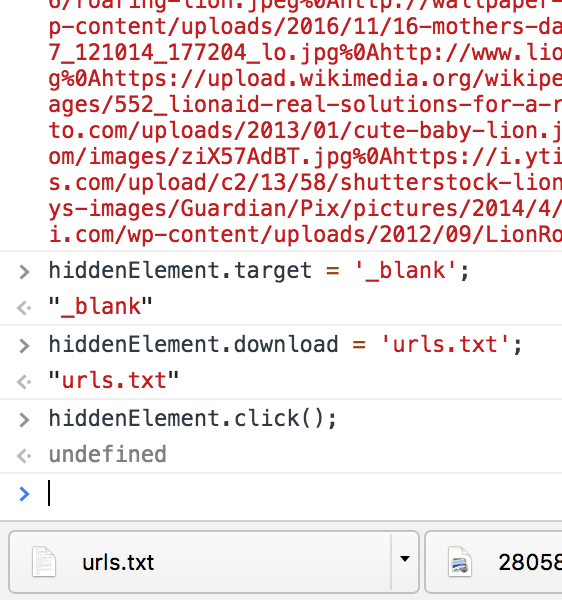
Then we get "urls.txt" file.
Screenshot:
Let's write python code to download the image into our local machine:
# import the necessary packages
from imutils import paths
import argparse
import requests
import cv2
import os
# construct the argument parse and parse the arguments
ap = argparse.ArgumentParser()
ap.add_argument("-u", "--urls", required=True,
help="path to file containing image URLs")
ap.add_argument("-o", "--output", required=True,
help="path to output directory of images")
args = vars(ap.parse_args())
# grab the list of URLs from the input file, then initialize the
# total number of images downloaded thus far
rows = open(args["urls"]).read().strip().split("\n")
total = 0
# loop the URLs
for url in rows:
try:
# try to download the image
r = requests.get(url, timeout=60)
# save the image to disk
p = os.path.sep.join([args["output"], "{}.jpg".format(
str(total).zfill(8))])
f = open(p, "wb")
f.write(r.content)
f.close()
# update the counter
print("[INFO] downloaded: {}".format(p))
total += 1
# handle if any exceptions are thrown during the download process
except:
print("[INFO] error downloading {}...skipping".format(p))
# loop over the image paths we just downloaded
for imagePath in paths.list_images(args["output"]):
# initialize if the image should be deleted or not
delete = False
# try to load the image
try:
image = cv2.imread(imagePath)
# if the image is `None` then we could not properly load it
# from disk, so delete it
if image is None:
delete = True
# if OpenCV cannot load the image then the image is likely
# corrupt so we should delete it
except:
print("Except")
delete = True
# check to see if the image should be deleted
if delete:
print("[INFO] deleting {}".format(imagePath))
os.remove(imagePath)
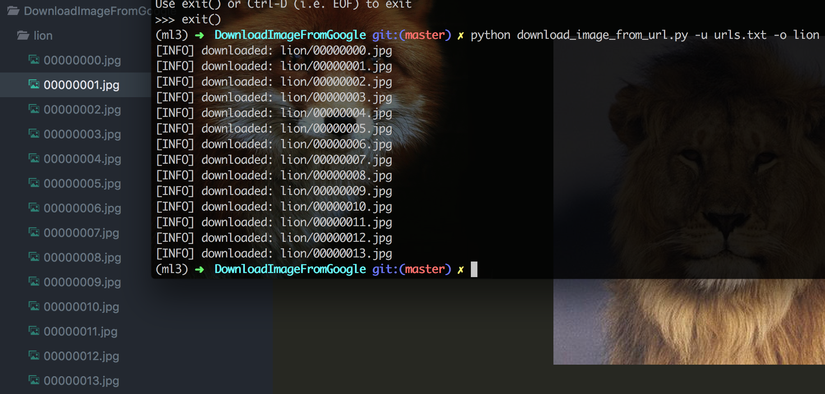
The code above need a path to urls.txt and output path. it read the url string in file line by line and make a request to those url and it use opencv to save the image in file.
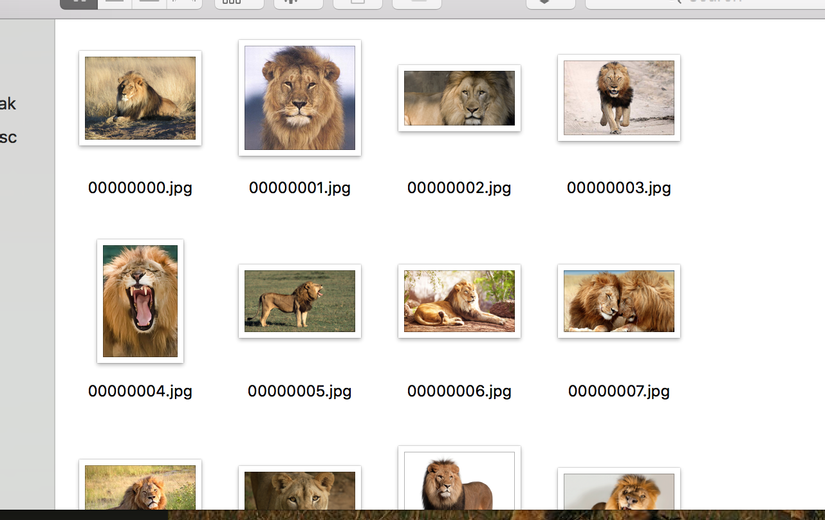
Next, you need to open folder and delete some image which may be incorrect manually. Finally, you can use those images to train your model.

3. Other
There are some methods which you can use to get the dataset for your specific problems such:
- API: some website have opened their API where you can get the information needed for trainning your learning model.
- Own website: you can make your website smarter by implement an algorithm to learn from your website's data. Ex: suggestion, recommendation system. etc.
- Survey: you can create a survey then ask people to fill the information where we can use it to fit into our model.
- more ...
Resources:
- source code
- https://machinelearningmastery.com/tour-of-real-world-machine-learning-problems/
- https://www.pyimagesearch.com/2017/12/04/how-to-create-a-deep-learning-dataset-using-google-images/
Summary
In this post, we talk about methods use to get dataset for your machine learning research. So, you use any of those methods to get the right data then you can implement the algorithm to solve your specific problems. So, let's find your dataset .
All rights reserved
