Machine Learning thật thú vị (5): Dịch ngôn ngữ, chatbot và mô tả ảnh với RNN
Bài đăng này đã không được cập nhật trong 4 năm
Chúng ta đều biết và yêu quý Google Dịch, một website có thể dịch gần như ngay lập tức hơn 100 ngôn ngữ khác nhau trên thế giới, như thể ma thuật. Và hiện tại, ma thuật đó thậm chí đã xuất hiện trên điện thoại và đồng hồ thông minh:

Công nghệ phía sau Google Dịch là Machine Translation (Dịch Máy), một công nghệ đã thay đổi thế giới, cho phép mọi người giao tiếp với nhau mà trước đây không thể. Nhưng trong 2 năm vừa qua, Deep Learning đã tạo ra cách tiếp cận mới cho Dịch Máy. Những nhà nghiên cứ gần như không biết gì về dịch ngôn ngữ đã đưa ra những giải pháp học máy khá đơn giản, nhưng lại đánh bại những hệ thống ngôn ngữ dịch được xây dựng bởi những nhà ngôn ngữ học xuất sắc nhất thế giới.
Công nghệ phía sau đột phá này chính là Sequence-to-Sequence Learning (phương pháp học chuỗi liên tiếp). Đây là một kỹ thuật rất mạnh đã được sử dụng để giải quyết rất nhiều vấn đề. Sau khi chúng ta áp dụng phương pháp này trong dịch thuật, ta sẽ sử dụng chính thuật toán này để viết chatbot - trả lời tự động hay mô tả ảnh.
Bắt đầu thôi nào!!!
Máy tính dịch thuật
Làm thế nào mà một chương trình máy tính có thể dịch ngôn ngữ con người?
Cách đơn giản nhất là thay thế từng từ trong một câu với từ được dịch ở ngôn ngữ hướng tới. Đây là giải thích đơn giản dịch từ tiếng Tây Ba Nha (TBN) sang tiếng Anh từng từ một:
 Điều này rất dễ để triển khai, bởi vì tất cả những gì bạn cần là một cuốn từ điển để tìm nghĩa từng từ. Nhưng kết quả sẽ tồi tệ, bởi nó bỏ qua ngữ pháp và văn cảnh.
Điều này rất dễ để triển khai, bởi vì tất cả những gì bạn cần là một cuốn từ điển để tìm nghĩa từng từ. Nhưng kết quả sẽ tồi tệ, bởi nó bỏ qua ngữ pháp và văn cảnh.
Điều tiếp theo chúng ta có thể thử là bắt đầu thêm những luật ngôn ngữ để cải thiện kết quả. Ví dụ, bạn có thể dịch cụm 2 từ liên quan vào một nhóm. Và bạn hoán đổi vị trí danh từ với tính từ vì trong tiếng Anh, chúng luôn xuất hiện ở vị trí ngược lại so với tiếng TBN:
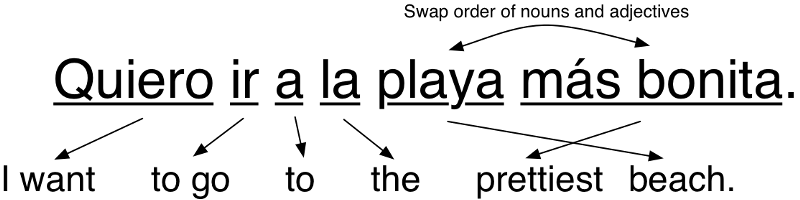
Câu đã chính xác! Nếu chúng ta cứ tiếp tục thêm thật nhiều luật lệ cho tới khi bao hàm được tất cả phần của ngữ pháp, chương trình của chúng ta có thể dịch bất cứ câu nào.
Đây chính là hệ thống dịch thuật đầu tiên được phát triển. Những nhà ngôn ngữ học đưa ra những luật lệ phức tạp và lập trình chúng từng dòng một. Một số nhà ngôn ngữ học thông thái nhất đã làm việc ròng rã nhiều năm trong suốt chiến tranh lạnh để tạo ra hệ thống dịch, như là một cách để hiểu tiếng Nga dễ dàng hơn.
Thật không may, hệ thống chỉ hoạt động tốt cho các văn bản có cấu trúc đơn giản như dự báo thời tiết. Nó không đáng tin cậy trong văn bản đời thực.
Vấn đề là ngôn ngữ con người không tuân theo những luật lệ cố định. Ngôn ngữ chứa nhiều trường hợp đặc biệt, biến thể vùng miền hay các luật bị phá vỡ.
Sử dụng thống kê giúp máy tính dịch tốt hơn
Sau hàng loạt thất bại của hệ thống luật lệ, phương pháp dịch mới được phát triển dựa trên mô hình xác suất thống kê hơn là những luật lệ ngữ pháp.
Xây dựng hệ thống dịch dựa trên thống kê yêu cầu rất nhiều dữ liệu đã được dịch sang cả 2 ngôn ngữ. Tài liệu 2 ngôn ngữ này được gọi là parallel corpora (tài liệu song ngữ).
Thật may mắn, có rất nhiều tài liệu song ngữ tồn tại ở nhiều nơi. Ví dụ, Nghị Viện Châu Âu đã dịch tài liệu của họ sang 21 ngôn ngữ. Vì thế, những nhà nghiên cứu sử dụng tư liệu đó để xây dựng hệ thống dịch.

Nghĩ về xác suất
Điều đặc biệt của những hệ thống dịch xác suất là chúng không cố gắng tạo ra đoạn dịch chính xác. Thay vào đó, chúng tạo ra hàng ngàn khả năng dịch và sắp xếp chúng theo khả năng chính xác. Độ chính xác được ước lượng bằng cách so sánh với dữ liệu đào tạo. Dưới đây là cách thức hoạt động:
Bước 1: Tách câu ra thành từng phần

Bước 2: Tìm tất cả các cách dịch cho mỗi phần
Chúng ta dịch từng phần bằng cách tìm tất cả các cách đã được dịch trong tập đào tạo. Chú ý là chúng ta không chỉ tìm kiếm cách dịch trong từ điển, mà xem xem những người khác đã dịch phần đó như thế nào. Điều này giúp ta thu thập được các cách khác nhau mà từ ngữ được sử dụng ở văn cảnh khác nhau:
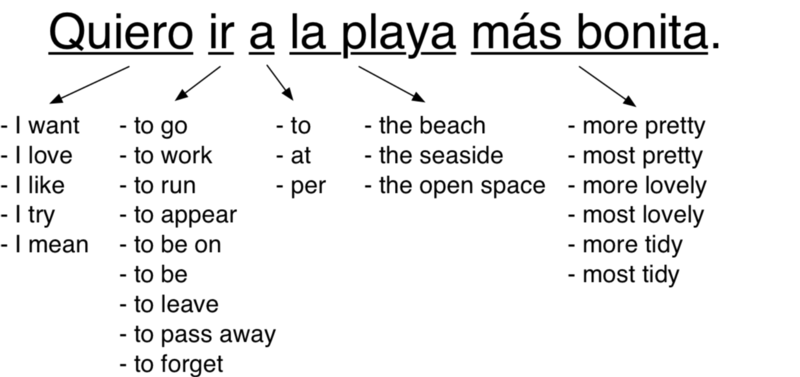 Một vài cách dịch được sử dụng thường xuyên hơn cách khác. Dựa vào tần suất mỗi cách dịch trong tập dữ liệu, chúng ta gán cho chúng một điểm số.
Một vài cách dịch được sử dụng thường xuyên hơn cách khác. Dựa vào tần suất mỗi cách dịch trong tập dữ liệu, chúng ta gán cho chúng một điểm số.
Ví dụ, chúng ta thường hiểu "Quiero" là "I want" - tôi muốn hơn là "I try" - tôi cố gắng. Vì thế, chúng ta dựa vào tần suất số lần dịch "Quiero" là "I want" trong tập dữ liệu để gán điểm số lớn hơn so với các cách dịch khác.
Bước 3: Tạo ra tất cả câu có thể và tìm câu có khả năng nhất
Tiếp đến, ta tìm tất cả các cách kết nối từng phần và tạo ra một loạt các câu có thể.
Chỉ từ việc dịch từng phần, chúng ta có thể tạo ra hơn 2500 biến thể bằng cách kết nối chúng lại. Dưới đây là một vài ví dụ:
I love | to leave | at | the seaside | more tidy. I mean | to be on | to | the open space | most lovely. I like | to be |on | per the seaside | more lovely. I mean | to go | to | the open space | most tidy.
Nhưng trong hệ thống thực tế, thậm chí còn có nhiều cách kết nối hơn, bởi chúng ta thử các cách sắp xếp khác nhau của từ và các cách tách câu thành từng phần khác nhau.
I try | to run | at | the prettiest | open space. I want | to run | per | the more tidy | open space. I mean | to forget | at | the tidiest | beach. I try | to go | per | the more tidy | seaside.
Bây giờ, ta cần phải duyệt qua tất cả các câu được tạo để tìm ra câu phù hợp nhất. Để làm điều đó, chúng ta so sánh những câu được tạo với hàng triệu câu thực tế trong các văn bản được viết bằng tiếng Anh. Càng nhiều tài liệu, kết quả càng tốt.
Lấy một khả năng dịch:
I try | to leave | per | the most lovely | open space.
Có khả năng là chưa ai từng viết câu như thế cả. Do đó, câu trên sẽ không giống với bất kỳ câu nào trong tập dữ liệu, ta sẽ gán giá trị rất nhỏ cho câu trên.
Nhưng hãy nhìn một khả năng khác:
I want | to go | to | the prettiest | beach.
Câu này giống với nhiều câu trong tập đào tạo, vì thế nó sẽ có điểm số cao.
Sau khi thử tất cả các khả năng, chúng ta chọn câu có điểm số cao nhất. Kết quả dịch cuối cùng của chúng ta là “I want to go to the prettiest beach" - Rất chuẩn!!!
Dịch thuật dựa trên xác suất là một bước tiến lớn
Nếu bạn cung cấp đủ dữ liệu, hệ thống xác suất thường dịch tốt hơn so với hệ thống dựa trên luật lệ. Franz Josef Och cải tiến ý tưởng này và sử dụng để xây dựng Google dịch đầu những năm 2000s. Dịch Máy cuối cùng cũng ra đời.
Ở thời kì đầu, điều ngạc nhiên tất cả mọi người là phương pháp "còi" dựa trên xác suất lại có thể đánh bại hệ thống luật lệ tạo ra bởi những nhà ngôn ngữ học. Điều này dẫn tới câu nói đầu năm 80s giữa những nhà nghiên cứu:
"Mỗi khi tôi sa thải một nhà ngôn ngữ, độ chính xác của tôi tăng lên" - Frederick Jelinek
Giới hạn của hệ thống Dịch Máy dựa trên Xác Suất
Hệ thống Dịch Máy Xác Suất hoạt động tốt, nhưng thường phức tạp để xây dựng hay bảo trì. Mỗi cặp ngôn ngữ bạn muốn dịch cần rất nhiều chuyên gia để điều chỉnh trọng số trong chuỗi dịch thuật gồm rất nhiều bước.
Bởi vì quá trình này rất tốn tài nguyên, nhiều thay thế đã được thực hiện. Nếu bạn yêu cầu Google dịch tiếng Việt sang tiếng Thái, nó thường dịch sang tiếng Anh như cầu nối, bởi vì không đủ tài liệu song ngữ, hoặc nó có thể dịch với hệ thống không tân tiến và chưa có đầy đủ các trường hợp như nếu GG được yêu cầu dịch từ tiếng Pháp sang tiếng Anh.
Chẳng phải sẽ tuyệt với hơn, nếu máy tính làm toàn bộ quá trình phát triển cho chúng ta?
Dịch tốt hơn, và tiết kiệm nguồn lực hơn
Cốt lõi của dịch máy là một hệ thống hộp đen có thể tự động dịch, chỉ bằng việc nhìn vào dữ liệu. Với Dịch Máy Xác Suất, con người vẫn cần xây dựng và tìm kiếm trọng số trong mô hình xác suất nhiều bước.
Vào năm 2014, nhóm của KyungHuyn Cho đã tạo ra một bước đột phá. Họ tìm ra cách áp dụng Deep Learning để tìm ra hệ thống hộp đen. Mô hình này lấy tài liệu dịch 2 chiều và sử dụng chúng để học cách dịch giữa 2 ngôn ngữ mà không cần sự can thiệp của con người.
2 ý tưởng lớn để tạo nên điều này - Recurrent Neural nNetwork (RNN - mạng nơron hồi quy) và Encodings (mã hóa). Bằng việc kết hợp 2 ý tưởng này một cách thông minh, chúng ta có thể tự xây dựng hệ thống dịch tự học.
Mạng nơron hồi quy (RNN)
Chúng ta đã nói về mạng hồi quy ở phần 2, nhưng hãy cùng ôn lại một chút.
Mạng nơron thông thường truyền vào dãy số và tính toán kiết quả dựa trên mô hình đã được đào tạo. Mạng nơron có thể được sử dụng như là một hộp đen để giải quyết nhiều vấn đề. Ví dụ như tìm giá nhà dựa trên đặc tính nhà:

Nhưng giống như nhiều thuật toán học máy khác, mạng nơron này là phi trạng thái. Bạn truyền vào một dãy số, mạng tính ra kết quả. Lần tiếp theo bạn truyền dãy số đó, kết quả tìm ra là giống nhau. Không có sự phụ thuộc giữa các lần thử kết quả.
Mạng RNN có một chút thay đổi khi trạng thái trước đây của mạng (kết quả của lần tính toán trước) sẽ là đầu vào cho tính toán kế tiếp.
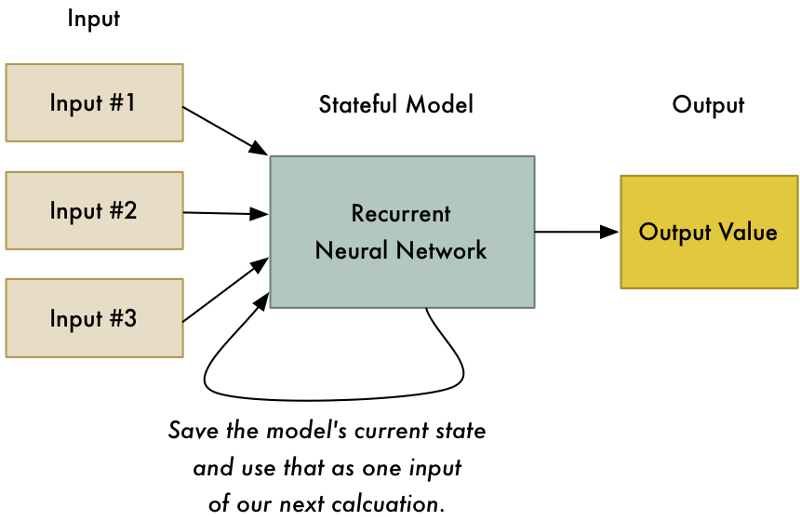
Phương pháp này cho phép mạng nơron học cấu trúc dạng chuỗi. Ví dụ, bạn dự đoán từ tiếp theo có khả năng nhất trong câu dựa trên vài từ đầu tiên.
 RNN sẽ hữu ích bất cứ khi nào bạn tìm kiếm mẫu cấu trúc của dữ liệu. Bởi vì ngôn ngữ con người chỉ là một cấu trúc lớn và phức tạp, RNN được sử dụng trong nhiều lĩnh vực xử lý ngôn ngữ.
RNN sẽ hữu ích bất cứ khi nào bạn tìm kiếm mẫu cấu trúc của dữ liệu. Bởi vì ngôn ngữ con người chỉ là một cấu trúc lớn và phức tạp, RNN được sử dụng trong nhiều lĩnh vực xử lý ngôn ngữ.
Ở phần 2, chúng ta đã cùng nhau sử dụng mạng RNN để tạo cuốn sách Hemingway, và tạo ra game Mario giả.
Encodings - Mã hóa
Ý tưởng khác chúng ta cần ôn lại là mã hóa, điều này đã được đề cập đến trong phần 4. Để giải thích về mã hóa, chúng ta quay lại ví dụ phân biệt mặt người trong học máy.
Trong khi con người xác định đặc trưng của khuôn mặt bằng kích thước tai, độ dài khuôn mặt, màu mắt..., máy tính không có khả năng làm điều đó, và chỉ nhận biết được các giá trị pixel. Tuy thế, bằng cách sử dụng 2 hình ảnh của cùng 1 người (#1, #2) và 1 hình ảnh của người khác (#3), máy tính sẽ tự động tìm ra 128 đặc trưng bằng cách thay đổi trọng số dần dần sao cho ảnh #1, và #2 ngày càng giống nhau, #2 ngày càng khác #3.
Cuối cùng, khuôn mặt người đã được mã hóa thành 128 đo lường.
 Bây giờ chúng ta đã có thể so sánh 2 khuôn mặt dễ dàng hơn rất nhiều bởi chúng ta chỉ cần so sánh 128 số thay vì so sánh toàn bộ giá trị pixel của ảnh.
Bây giờ chúng ta đã có thể so sánh 2 khuôn mặt dễ dàng hơn rất nhiều bởi chúng ta chỉ cần so sánh 128 số thay vì so sánh toàn bộ giá trị pixel của ảnh.
Kết hợp RNN và mã hóa
Và chúng ta có thể làm điều tương tự với câu văn. Chúng ta sẽ để máy tính học và tạo ra 128 đơn vị đo lường duy nhất đại diện cho mỗi câu văn.

Để tạo ra đoạn mã hóa này, chúng ta truyền câu trên vào RNN, từng từ một. Kết quả cuối cùng sau từ cuối cùng sẽ là giá trị đại diện cho cả câu. 
Tuyệt vời! Chúng ta đã tìm ra cách đại diện toàn câu bằng một chuỗi giá trị duy nhất. Chúng ta không biết chính xác ý nghĩa biểu tượng của từng mã hóa, nhưng điều đó không quan trọng. Miễn là mỗi câu văn là độc nhất bởi một chuỗi số.
Bắt đầu dịch thôi!
Chúng ta đã chuyển 1 câu sang một chuỗi mã hóa. Vậy thì sao?
Hãy tưởng tượng chúng ta có 2 chuỗi RNNs được kết nối bởi chuỗi mã hóa. Mạng RNN thứ 1 chuyển chuyển câu văn sang chuỗi mã hóa và mạng RNN thứ 2 biên dịch mã hóa đó thành câu văn ban đầu:
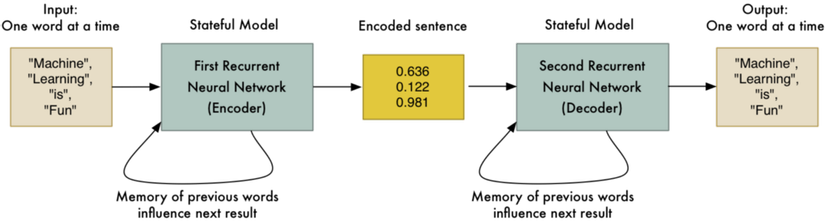 Dĩ nhiên, việc mã hóa rồi biên dịch lại câu văn ban đầu không mang nhiều ý nghĩa, nhưng nếu chúng ta sử dụng mạng RNN thứ 2 để biên dịch sang tiếng TBN thay vì tiếng Anh thì sao? Chúng ta có thể sử dụng tài liệu song ngữ để đào tạo mô hình này.
Dĩ nhiên, việc mã hóa rồi biên dịch lại câu văn ban đầu không mang nhiều ý nghĩa, nhưng nếu chúng ta sử dụng mạng RNN thứ 2 để biên dịch sang tiếng TBN thay vì tiếng Anh thì sao? Chúng ta có thể sử dụng tài liệu song ngữ để đào tạo mô hình này.
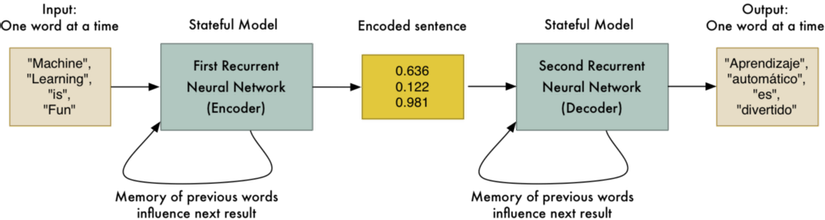 Cuối cùng, chúng ta đã tìm được cách chung để chuyển một chuỗi từ tiếng Anh sang tiếng TBN tương ứng.
Cuối cùng, chúng ta đã tìm được cách chung để chuyển một chuỗi từ tiếng Anh sang tiếng TBN tương ứng.
Đây là một ý tưởng đột phá:
- Phương pháp này hầu như chỉ bị giới hạn bởi số lượng dữ liệu đào tạo bạn có và nguồn lực của máy tính. Các nhà nghiên cứu chỉ sáng tạo ra phương pháp này 2 năm trước, nhưng nó đã thể hiện tốt hơn các phương pháp dịch trên xác suất được phát triển trong 20 năm.
- Phương pháp này không phụ thuộc vào hiểu biết về luật lệ của ngôn ngữ. Thuật toán tự tìm ra luật lệ. Chúng ta không cần chuyên gia để tinh chỉnh trọng số ở từng bước.
- Phương pháp này áp dụng cho hầu hết vấn đề dạng chuỗi! Và hóa ra, có rất nhiều vấn đề chuỗi thú vị.
Xây dựng hệ thống dịch dạng chuỗi
Nếu bạn muốn xây dựng hệ thống dịch ngôn ngữ của riêng bạn, dưới đây là bản demo với Tensorflow giúp dịch giữa tiếng Anh và tiếng Pháp. Tuy thế, xây dựng hệ thống này cần cả sự kiên nhẫn lẫn tài nguyên. Nếu bạn có một chiếc máy tính nhanh cùng thẻ đồ họa tân tiến nhất, có thể cần mất cả tháng để đào tạo hệ thống.
Sức mạnh không tưởng của mô hình chuỗi
Chúng ta có thể làm gì với mô hình chuỗi?
Khoảng 1 năm trước, những nhà nghiên cứu ở GG đã chỉ ra rằng bạn có thể sử dụng mô hình chuỗi để xây dựng AI bots - hệ thống trả lời tự động thông minh. Ý tưởng rất đơn giản nhưng lại rất thành công.
Đầu tiên, người ta thu thập đoạn chat giữa nhân viên và bộ phận hỗ trợ kỹ thuật tại GG. Họ đào tạo mô hình với câu hỏi của nhân viên là đầu vào và câu trả lời của kỹ thuật viên là đầu ra, và coi đó là "một bản dịch".
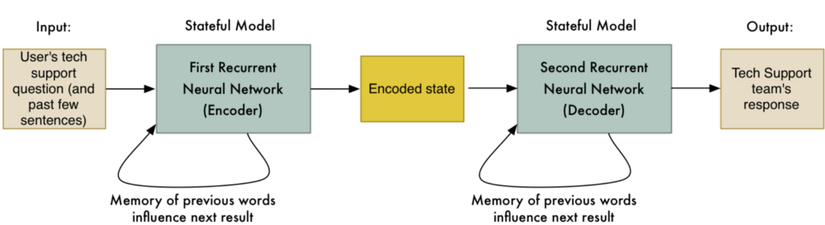
Khi người sử dụng tương tác với bot, nó sẽ "biên dịch" tin nhắn từ người sử dụng và lấy ra câu trả lời từ hệ thống. Dưới đây là đoạn hội thoại giữa người sử dụng và bot từ bài báo khoa học.
Human: kết nối bị từ chối hoặc có gì đó như thế Machine: liệu tôi có thể biết được phiên bản mạng của bạn không? Human: tôi không chắc tôi biết Machine: kết nối mạng có yêu cầu xác nhận từ người dùng Human: có Machine: bạn đang ở nhà hay ở cơ quan ngay lúc này? cơ quan? Human: Tôi ở nhà Machine: thử điều này. Vào trang http://*** rồi nhập tên tài khoản và mật khẩu của bạn Human: xong Machine: thử đăng nhập với tên *** và kiểm tra xem mọi thứ đã hoạt động chưa? Human: oh, đã hoạt động Machine: tuyệt vời. tôi có thể giúp gì bạn thêm không?
Họ cũng đã cố gắng xây dựng hệ thống chat bot dựa trên hàng triệu phụ đề phim. Ý tưởng là xây dựng bot có thể nói chuyện như con người. Đầu vào là câu văn được nói bởi 1 nhân vật, và "bản dịch" là câu trả lời của nhân vật tiếp theo.
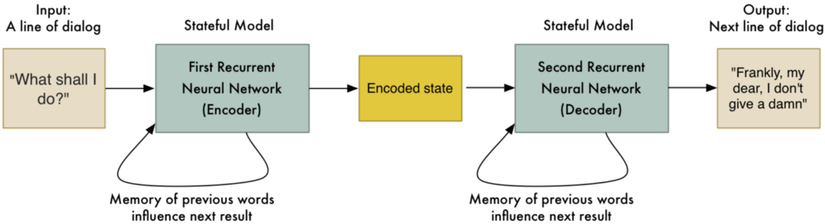 Hệ thống này tạo ra kết quả khá thú vị. Không chỉ có khả năng hội thoại như con người, mà còn thể hiện một chút thông minh.
Hệ thống này tạo ra kết quả khá thú vị. Không chỉ có khả năng hội thoại như con người, mà còn thể hiện một chút thông minh.
Human: tên tôi là "chúc mừng". Tên bạn là gì? Machine: "chúc mừng" Human: tên tôi là "năm mới". Tên bạn là gì? Machine: "năm mới" Human: bạn là người lãnh đạo hay là người theo sau? Machine: tôi là người lãnh đạo Human: bạn là người theo sau hay là người lãnh đạo? Machine: tôi là người lãnh dạo
Và đây chỉ là bắt đầu của những điều tưởng như không thể. Chúng ta không bị giới hạn chuyển từ một câu sang câu khác. Chúng ta có thể tạo ra Image-to-Sequence Model (mô hình ảnh sang chuỗi).
Một nhóm khác tại Google đã làm điều này bằng cách thay thế mạng RNN đầu tiên bằng mạng Convolutional Neural Network (CNN). Điều này cho phép nhận đầu vào là ảnh thay vì là một câu.
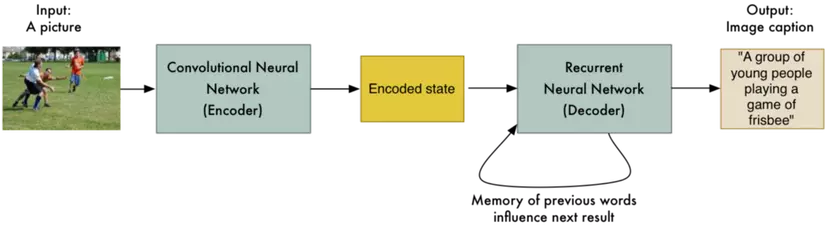
Hơn thế nữa, Andrej Karpathy phát triển ý tưởng để xây dựng hệ thống mô tả ảnh với từng chi tiết bằng cách xử lý từng vùng của bức ảnh riêng biệt:

Điều này cho phép hệ thống tìm kiếm ảnh tìm ra bức tranh dựa trên mô tả:

Thậm chí có những nhà nghiên cứu tìm cách giải quyết vấn đề ngược lại, tạo ra một tấm ảnh từ đoạn mô tả.
Với những ví dụ trên, bạn có thể bắt dầu tưởng tượng ra những khả năng không giới hạn của học máy. Hiện tại, ứng dụng chuỗi được áp dụng từ nhận diện giọng nói cho tới tầm nhìn máy tính. Tôi cá là sẽ còn rất nhiều ứng dụng tuyệt hảo khác nữa trong những năm sắp tới.
Nguồn:
Nếu các bạn thấy hứng thú với series này, các bạn có thể follow mình hoặc clip series để nhận được thông báo khi có bản dịch mới nhất. Series hiện có 8 bài, những bản dịch tiếp theo sẽ được cập nhật dần dần

All rights reserved
