Simple Contrastive Learning of Sentence Embeddings (SimCSE)
Bài đăng này đã không được cập nhật trong 2 năm
Link paper nếu mọi người muốn đọc kĩ hơn : https://arxiv.org/pdf/2104.08821.pdf Dạo gần đây mình có tìm hiểu về các cách embedding sentence và mình thấy CSE là 1 kĩ thuật rất hay Trước đây, họ thường sử dụng :NLI supervised cho việc giám sát tạo thành các bộ ( pair ) phân loại để dự đoán mối quan hệ
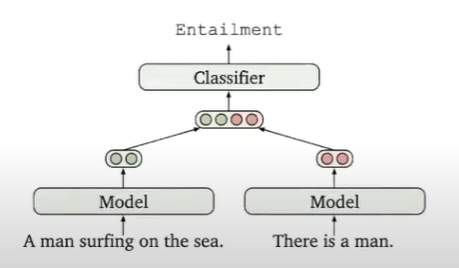
và ngoài ra khi data augmentation họ thường sử dụng xóa ngẫu nhiên một số từ để tạo tối đa về data và kết hợp lại tạo thành các phần nhúng tổng hợp
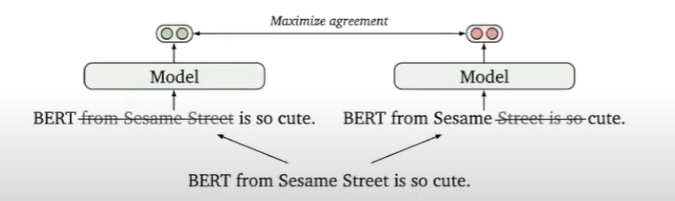
Điều này tốt nhưng không tốt bằng các mô hình được giám sát ( supervised ) vì đôi lúc khi xóa ngẫu nhiên và tạo ra các câu vô nghĩa
Ý tưởng cơ bản là sử dụng unsupervised SimCSE và supervised simCSE để giúp model embedding một cách tốt hơn

→ contrastive learning : về ý tưởng cơ bản là kéo những hàng xóm ( tương tự nhau ) lại gần hơn và đẩy những phần không tương tự nhau ra xa
mục tiêu contrastive learning là điều chỉnh không gian nhúng được đào tạo trước để đồng nhất hơn, nó sắp xếp tốt hơn các cặp gần nhau về mặt ngữ nghĩa với các tín hiệu được giám sát
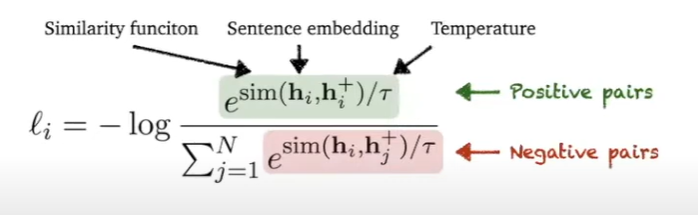
- InfoNCE loss:
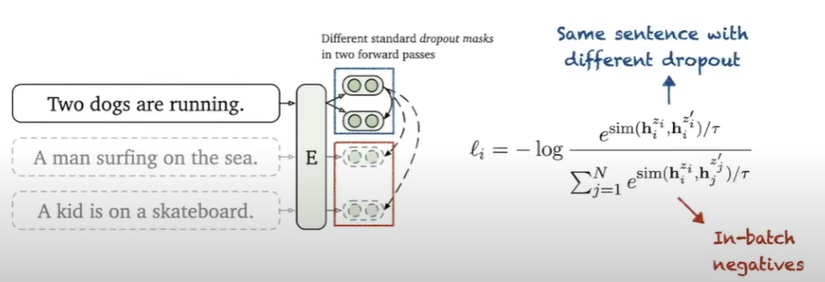
- positive pairs : là embedding của cùng 1 câu với các dropout masks khác nhau
- negative pairs : là embedding của tất cả các câu cùng 1 batch ( in-batch negatives )
example :
supervised simCSE :
ý tưởng cơ bản :
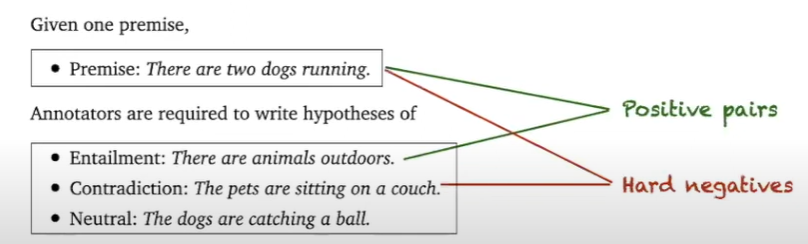
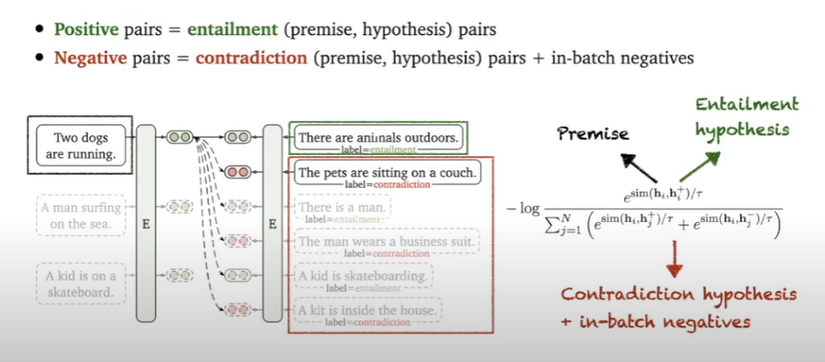 → không những so sánh với các embedding của tất cả các câu trong 1 batch mà sẽ dùng các phần còn lại và xem như là negative pairs
→ không những so sánh với các embedding của tất cả các câu trong 1 batch mà sẽ dùng các phần còn lại và xem như là negative pairs
Ngoài ra hiện nay đối với tiếng việt đã có repo của anh Võ Văn Phúc , mình xin trích dẫn link huggingface cho pretrain model nếu bạn nào có hứng thú test thử : https://huggingface.co/VoVanPhuc/unsup-SimCSE-VietNamese-phobert-base#usage1
Cảm ơn mọi người, bài viết của mình tới đây à hết !!!
All rights reserved
