Text Preprocessing in NLP
Bài đăng này đã không được cập nhật trong 2 năm
Chào mọi người mình là Quân, một sinh viên đang nghiên cứu về AI. Trong bài viết này mình xin chia sẽ về các bước text preprocessing, Vì là kiến thức tự nghiên cứu nên xin được mọi người góp ý và cải thiện thêm để củng cố kiến thức ( trong bài viết ngày mình có sử dụng source của channel codebasis một chanel của các anh Ấn Độ rất hay hehehe )
Hãy nhìn vào pipeline của 1 project NLP bên dưới :
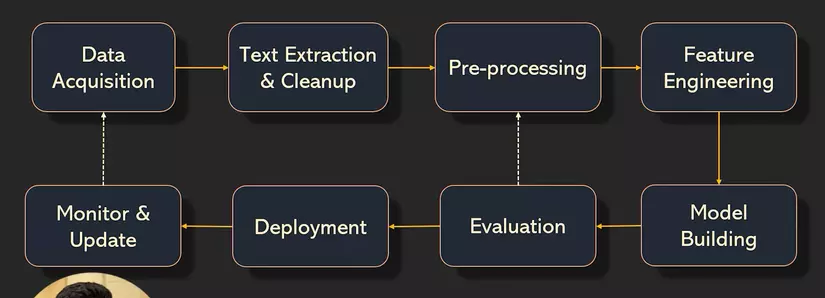
Text Preprocessing
Sau khi qua 2 bước là thu thập dữ liệu **(**Data Acquisition) và trích xuất văn bản & làm sạch (Text extraction & cleanup). chúng ta đến với bước Pre-processing. ở bước này gồm các bước nhỏ :
- Regex (Regular Expressions)
- Tokenization
- Parsing (phân tích cú pháp)
- Stemming (gốc từ)
- Lemmatization (ngữ pháp hóa)
- POS Tagging
- Named Entity Recognition (NER) (nhận diện thực thể)
- Information Extraction
- Regular Extraction
Regex
Là biểu thức chính quy, được sử dụng để tìm kiếm, so sánh, và xử lý các chuỗi ký tự trong ngôn ngữ tự nhiên. Các thành phần chính của Regex :
- Ký tự thường
- Ký tự đặc biệt
- Nhóm kí tự
→ 1 công cụ hỗ trợ mạnh mẽ để trích xuất Regex là https://regex101.com/
Một số ví dụ để làm quen với Regex : https://github.com/quan2206/NLP_tutorials/tree/main/NLP_Tutorials/1_regex
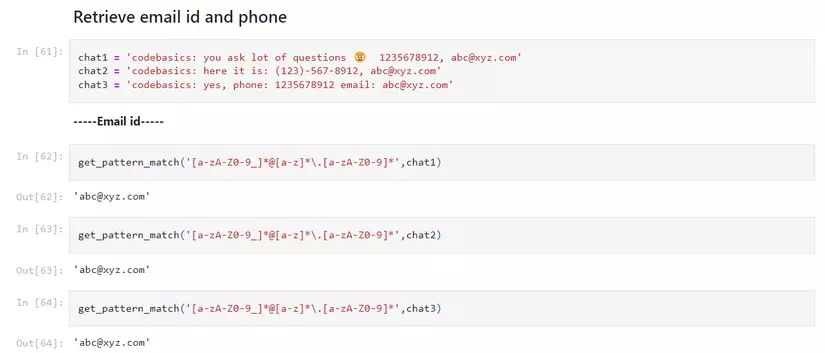
→ về cơ bản Regex sẽ giúp chúng ta lấy ra được những cú pháp mà chúng ta mong muốn ( như ví dụ ở trên khi tôi cố gắng lấy gmail từ một đoạn text, điều này có thể giúp hỗ trợ làm tools spam email,…. )
→ regex thực sự mạnh mẽ để giúp chúng ta trích xuất những thông tin cần thiết
Có nhiều thư viện để text preprocessing nhưng chủ yếu hiện nay là spacy và NLTK :


→ ví dụ làm quen với spacy và nltk
:https://github.com/quan2206/NLP_tutorials/tree/main/NLP_Tutorials/2_nltk_vs_spacy
Khi làm việc với spacy sẽ có :
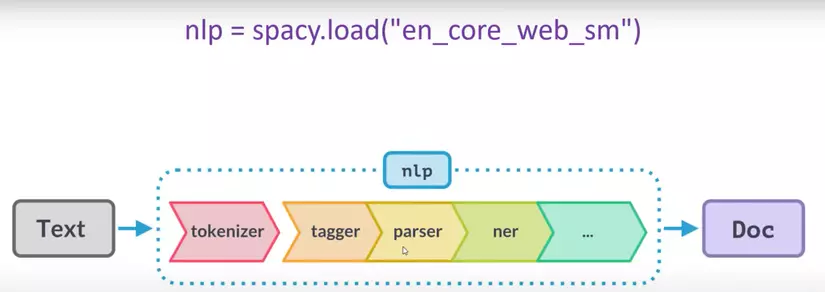
Khi chúng ta muốn làm việc với phần tokenizer có thể sử dụng spacy.blank (pre-tokenized) :
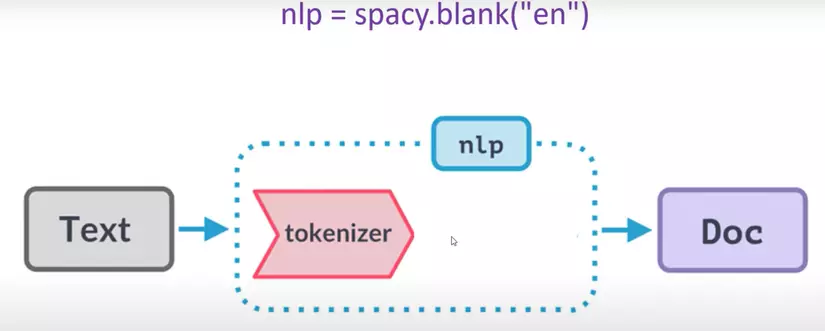
khi chúng ta feed text qua spacy.blank thì thu được Doc document, lúc này Doc document có thể hiểu được tokens ( lưu ý : mỗi ngôn ngữ sẽ có mã riêng “en” , “ja”, … bởi vì đối với mỗi ngôn ngữ sẽ có các kiểu quy ước riêng)
Tokenization
là quá trình chia một đoạn văn bản thành các phần nhỏ gọi là "token." Mỗi token có thể là một từ, một dấu câu, hoặc thậm chí là một phần của từ, tùy thuộc vào cách bạn định nghĩa quy tắc tokenization và có ý nghĩa

→ ví dụ làm quen với tokenization : https://github.com/quan2206/NLP_tutorials/tree/main/NLP_Tutorials/4_tokenization
→ sau khi tokenization : hãy dùng dir() để biết tất cả method của variable :

→ tokenization rất mạnh và hỗ trợ rất nhiều trong quá trình tạo sản phẩm : Ví dụ như is_email method có thể giúp chúng ta trả về true/fasle → để quyết định các hành động phía sau như gửi tin nhắn đến email này. Hãy xem tutorials của spacy nếu muốn hiểu rõ hơn : https://spacy.io/usage/linguistic-features
→ ngoài ra chúng ta cũng có thể customize tokenization rule :
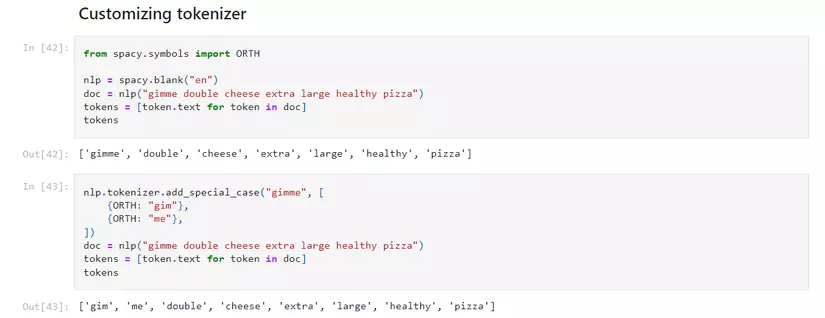
Điều này thực sự rất tốt khi chúng ta làm việc với những data có ngoại lệ (slang, trending word, …)
Processing pipeline
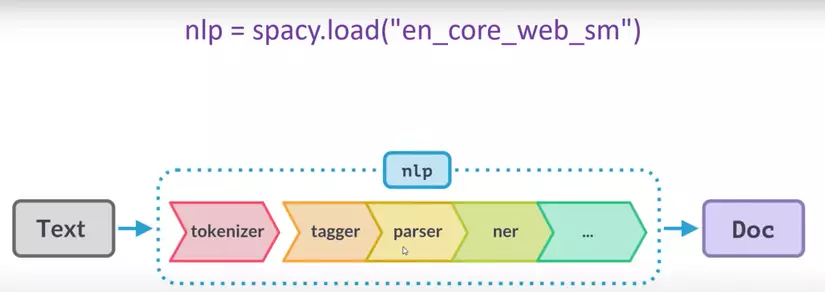
download pretrain-pipeline : https://spacy.io/usage/processing-pipelines
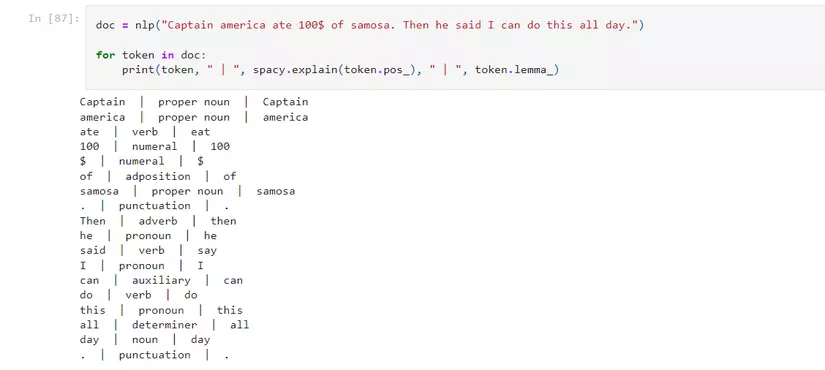
→ như ví dụ phía trên :
- khi dùng pos_ method chúng ta sẽ biết token này được gắn là loại từ nào ( ví dụ Captain : được xem là noun , Then : được xem là adverb )
- lemma_ sẽ giúp chúng ta biết được từ gốc của token ( ví dụ: said thì từ gốc là say )
Stemming and Lemmatization :
- Stemming :

→ stemming giúp loại bỏ hậu tố của từ và giữ lại từ gốc
- Lemmatization :

→ lemmatization có thể hiểu là sử dụng kiến thức về ngôn ngữ giúp lấy lại từ gốc ( như ví dụ ở trên )
⇒ sự khác biệt giữa stemming và lemma là stemming thường chỉ có những rules đơn giản như loại bỏ -ing, -able,… Trong khi làm việc với các từ vựng phức tạp hơn chúng ta cần dùng tới lemma . Đi kèm với điều này chúng ta cũng có thể customize lemma hay stemming
- Để hiểu rõ hơn : https://github.com/quan2206/NLP_tutorials/tree/main/NLP_Tutorials/6_stemming_lematization
Part of speech ( POS )
Để dễ hiểu thì part of speech là từ loại (hiện nay có 8 từ loại trong ngữ pháp truyền thống)

→ vì sao điều này lại quan trọng ? Vì điều này giúp hiểu được ý nghĩa câu, phân tích ngữ cảnh, đồng nhất dữ liệu, hỗ trợ các tác vụ khác trong NLP
Tiếp theo mình xin nói về cách sử dụng POS trong spacy ( https://github.com/quan2206/NLP_tutorials/tree/main/NLP_Tutorials/7_pos)
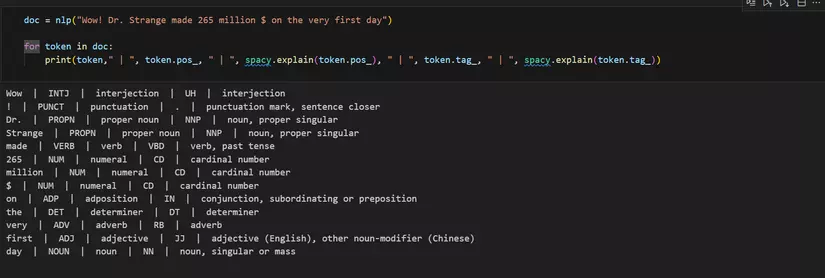
→ chúng ta có thể thấy nó hoạt động khá tốt ( chẳng hạn như Strange được quy ước là Propn( danh từ chỉ tên riêng, được gắn tag là tên riêng số ít )
→ để hiểu hơn về những quy ước của thư viện và nắm rõ : https://spacy.io/usage/linguistic-features#pos-tagging
→ khi xây dựng ứng dụng NLP những điều này là cực hữu ích ( để lấy 1 ví dụ cho dự án thực về điều này : chẳng hạn như ở tác vụ phân loại cảm xúc của các bình luận chúng ta có thể lựa chọn lấy những tính từ ( chỉ cảm xúc ) từ đó có thể đánh giá được cảm xúc của người dùng thông qua bình luận )
Named Entity Recognition (NER)
Nhiệm vụ chính của NER là xác định và phân loại các thực thể có tên (Named Entities) trong văn bản thành các danh mục nhất định như tên người, tên địa điểm, tên tổ chức, ngày tháng, số tiền, và các thực thể khác
-
Use-case 1 : Search
- để hiểu rõ hơn mình xin lấy 1 ví dụ thực tế : Khi chúng ta vào các bất kì website tin tức đều sẽ cung cấp cho chúng ta method search. và mình sẽ tìm kiếm với keyword “Tesla”
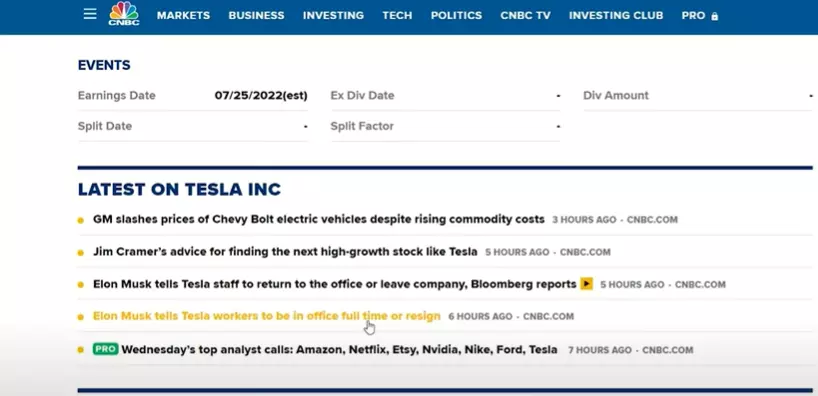
có thể thấy website đã hiện ra những tin có liên quan tới “Tesla” ( company )
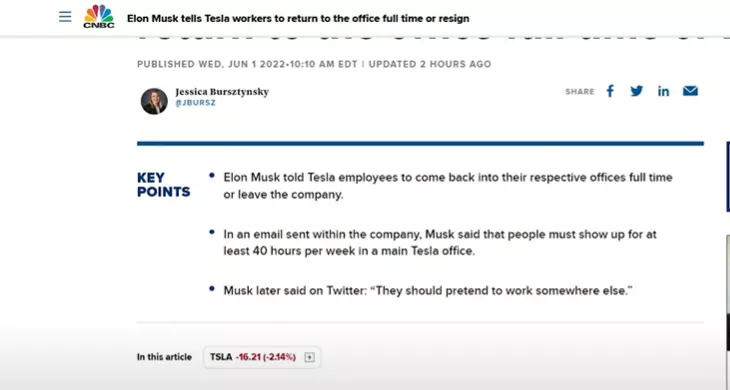 để làm được điều này thì những tin tức này đã được gắn thẻ với “Tesla”
để làm được điều này thì những tin tức này đã được gắn thẻ với “Tesla”
 → Trông có vẻ đơn giản đúng không ? Nhưng sự thật đằng sau không đơn giản như thế vì Tesla cũng có thể là tên của company hoặc tên riêng ( Nicolai Tesla ). Và khi “Tesla” xuất hiện ở các bài viết chúng ta không thể biết được đó là người hay company vì vậy đó là lúc NER system hữu dụng
→ Trông có vẻ đơn giản đúng không ? Nhưng sự thật đằng sau không đơn giản như thế vì Tesla cũng có thể là tên của company hoặc tên riêng ( Nicolai Tesla ). Và khi “Tesla” xuất hiện ở các bài viết chúng ta không thể biết được đó là người hay company vì vậy đó là lúc NER system hữu dụng
- Use-case 2 : Recomendations :
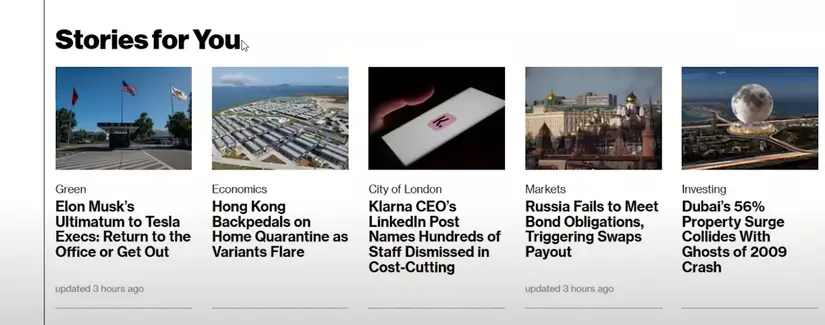
→ khi một người đọc các bài báo trước đó liên quan tới Tesla, Elon Musk,… thì chúng ta có thể recommend cho họ những bài viết có các thực thể tương tự
- Use-case 3 : Customer care service
Để hiểu rõ hơn về use-case này mình xin đưa ra 1 ví dụ thực tế : chẳng hạn như xây dựng 1 website dạy các khóa học về NLP, đôi khi các khóa học sẽ có vấn đề ( như mất bài giảng, vấn đề chất lượng âm thanh, hình ảnh,…. ) . Và để giải quyết điều này, chúng ta xây dựng 1 khung report chung :
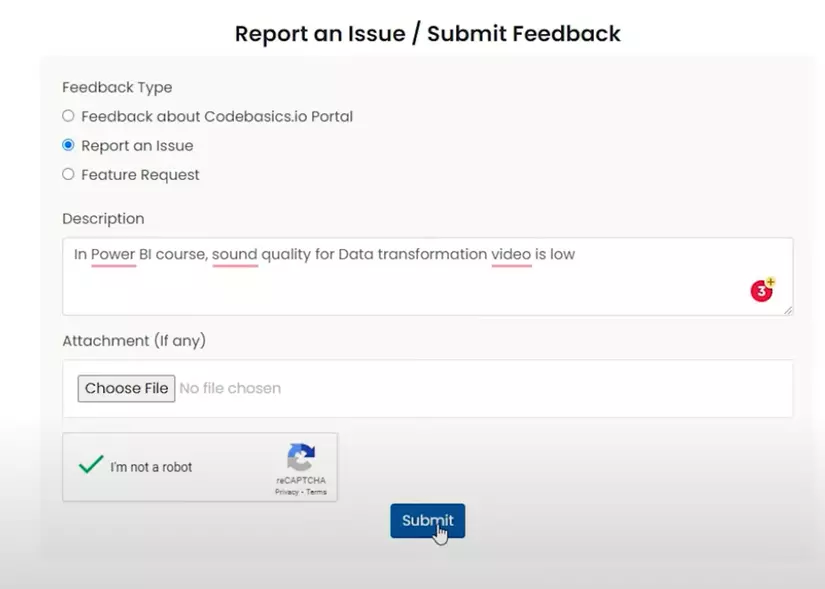
Vâng nhìn vào đây, làm sao chúng ta có thể phân biệt được các vấn đề đang nói về khóa học nào ? Vậy làm sao để biết được điều này
→ Đây là lúc chúng ta dùng đến NER, chúng ta sẽ trích xuất thực thể là tên khóa hóa → sau đó phân loại issue và gửi đến support team
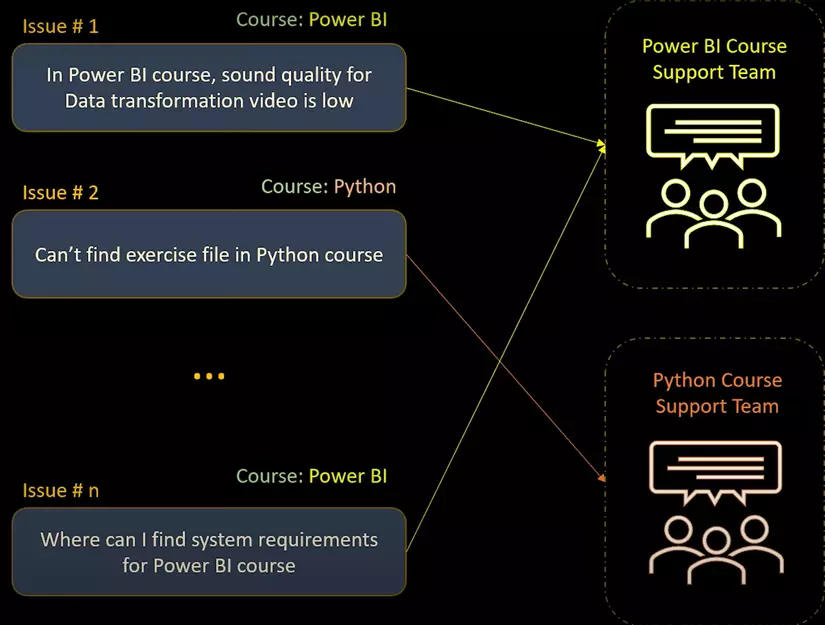
Coding NER with spacy :
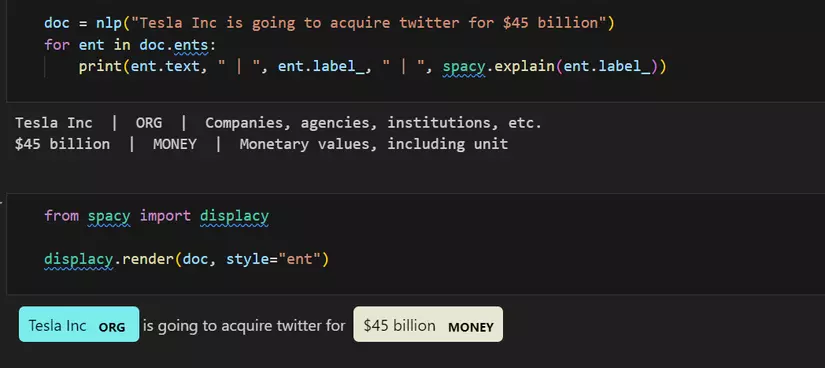
Để hiểu rõ hơn : https://github.com/quan2206/NLP_tutorials/tree/main/NLP_Tutorials/8_NER Bài viết cũng khá dài nên mình sẽ viết tiếp vào các bài sau . Nếu thấy hay hãy cho mình xin 1 like và 1 subcriber để có thêm động lực hehehe ! Thân ái
All rights reserved
