Paper reading | CLIP4STR: A Simple Baseline for Scene Text Recognition with Pre-trained Vision-Language Model
Bài đăng này đã không được cập nhật trong 2 năm
Đóng góp của bài báo
Các mô hình pretrained Vision-language (VL) với dữ liệu lớn như CLIP và ALIGN thể hiện sự mạnh mẽ trong đa dạng task về hình ảnh và ngôn ngữ. Trong bài báo, nhóm tác giả chứng minh pretrained VL có thể sử dụng làm backbone cho các mô hình thuộc bài toán Scene Text Recognition.
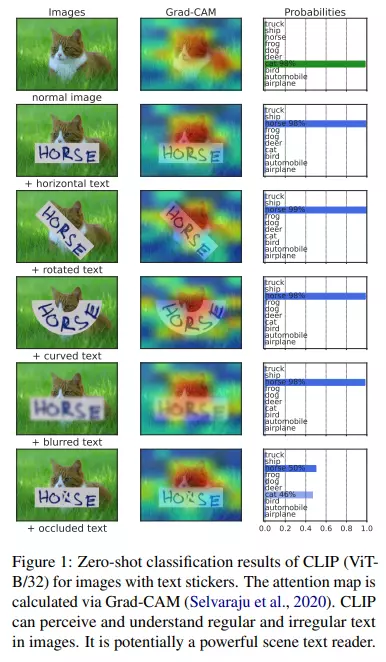
Trong hình trên, CLIP thể hiện được sức mạnh khi chú ý chính xác vào vùng có văn bản, kể cả văn bản đó có kích thước, hình dạng,... khác nhau. Bài báo giới thiệu mô hình CLIP4STR, là một framework hiệu quả sử dụng CLIP cho bài toán Scene Text Recognition. Mô hình CLIP4STR gồm 2 nhánh encoder-decoder là nhánh visual và nhánh cross-model. Để cho phép decoder học cấu trúc từ hiệu quả, nhóm tác giả sử dụng kĩ thuật permuted sequence modeling được đề xuất trong mô hình PARSeq. Trong quá trình training, nhánh visual cung cấp một kết quả dự đoán ban đầu dựa vào các visual feature và sau đó được tinh chỉnh bởi nhánh cross-model. CLIP4STR đạt hiệu suất SOTA trên 11 STR benchmark phổ biến.
Phương pháp
Nhắc lại các mô hình cơ bản
Trong phần này, ta cùng nhắc lại những thông tin cơ bản của model CLIP và kĩ thuật permuted sequence modeling được đề xuất trong mô hình PARSeq.
CLIP bao gồm hai thành phần chính: một bộ text encoder và một bộ image encoder. Mô hình được train trên một tập dữ liệu lớn gồm 400 triệu cặp hình ảnh-văn bản bằng cách sử dụng một phương pháp gọi là contrastive learning, giúp hiểu mối quan hệ giữa văn bản và hình ảnh.
Text encoder của CLIP dựa trên một kiến trúc transformer, một thiết kế mạng nơ-ron phổ biến trong xử lý ngôn ngữ tự nhiên. Kiến trúc này cho phép mô hình nắm bắt và biểu diễn thông tin văn bản một cách hiệu quả. Văn bản được encode bằng phương pháp gọi là mã hóa cặp byte pair encoding (BPE), với kích thước từ vựng là 49152. Văn bản được bổ sung bằng các token đặc biệt như [SOS] và [EOS]. Trong phiên bản trước của CLIP, chỉ có feature của mã [EOS] mới được trả về, nhưng trong phiên bản cải tiến này, feature của tất cả các token được trả về và sử dụng trong mô hình.
Song song với đó, image encoder của CLIP dựa trên kiến trúc vision transformer (ViT), được thiết kế đặc biệt để xử lý thông tin hình ảnh. ViT sử dụng một bộ encode hình ảnh, hoặc convolution, để chuyển đổi các patch hình ảnh không chồng nhau thành một sequence. Một token đặc biệt [CLASS] được thêm vào đầu chuỗi này. Ban đầu, trong CLIP, chỉ có feature của mã [CLASS] được trả về, nhưng trong phiên bản cải tiến này, feature của tất cả các token được trả về để cải thiện hiệu suất. Bộ image encoder thường sử dụng cấu hình ViT-B/16 (patch có kích thước ).
Mô hình CLIP4STR cũng sử dụng kĩ thuật Permuted sequence modeling được đề xuất trong mô hình PARSeq. Ý tưởng chính của permuted sequence modeling là sinh ngẫu nhiên quan hệ phụ thuộc giữa input context và output bằng cách sử dụng một attention mask ngẫu nhiên trong suốt quá trình thực hiện attention (xem 3 bảng dưới).

Encoder
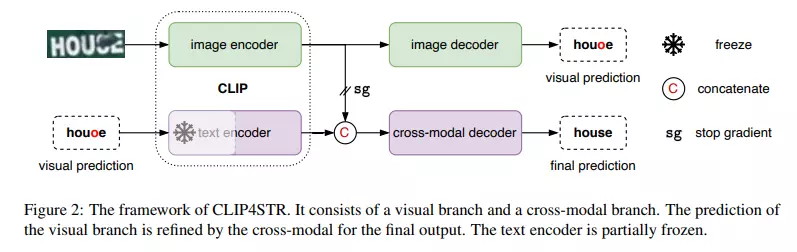
Kiến trúc tổng quát của mô hình CLIP4STR được thể hiện trong hình trên. CLIP4STR sử dụng đồng thời 2 nhánh encoder-decoder là nhánh visual và nhánh cross-modal. Text encoder và image encoder sử dụng pretrained weight từ model CLIP.
Nhánh visual branch đưa ra dự đoán ban đầu dựa trên các feature hình ảnh được trích xuất từ bộ encode hình ảnh. Tiếp theo, nhánh cross-modal tinh chỉnh dự đoán ban đầu bằng cách xử lý sự không tương thích giữa các feature hình ảnh và ngữ nghĩa văn bản trong dự đoán. Do hình ảnh và văn bản được embed trong một không gian chung nên dễ dàng xác định sự không tương thích này. Do vậy, nhánh cross-modal hoạt động giống như một trình kiểm tra chính tả.
Ngoài ra, ở hình trên ta thấy bộ encode văn bản được đóng băng (freeze) ở một phần, đây là một cách làm phổ biến trong transfer learning các mô hình ngôn ngữ lớn. Thao tác đóng băng này giữ lại khả năng hiểu văn bản của mô hình ngôn ngữ đã học và giảm chi phí tính toán trong quá trình huấn luyện.
Ngược lại, nhánh visual được huấn luyện đầy đủ do sự khác biệt về dữ liệu giữa dữ liệu STR (hình ảnh từng từ được cắt ra) và dữ liệu huấn luyện của CLIP (thường là hình ảnh tự nhiên thu thập trên internet). Ngoài ra, gradient flow từ bộ decoder cross-modal đến bộ visual encoder bị chặn để cho phép nhánh visual học độc lập với mục tiêu cải thiện các dự đoán từ refined cross-model.
Cụ thể, cho text encoder và image encoder . Với input text và input image , ta tính text, image và cross-model feature như sau:
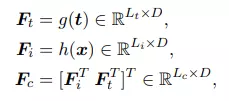
trong đó là độ dài chuỗi text, là độ dài chuỗi các token hình ảnh, là chiều của không gian embedding image-text và độ dài chuỗi cross-modal là .
Decoder
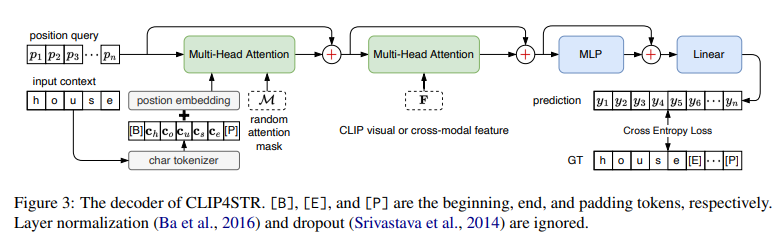
Decoder có nhiệm vụ trích xuất thông tin kí tự từ visual feature hoặc cross-model feature (thể hiện trong hình trên). Decoder được thiết kế giống như encode của mô hình transformer tiêu chuẩn. Cả visual và cross-modal decoder có cùng kiến trúc nhưng khác input. Đầu vào của mỗi decoder bao gồm:
- Một learnable position query
- Một learnable input context
- Một attention mask
trong đó là độ dài chuỗi kí tự. Các output của decoder là , trong đó là số class kí tự khác nhau (character class). Decoding stage có thể công thức hóa như sau:
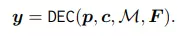
Module Multi-Head Attention (MHA) đầu tiên thực hiện context-position attention:
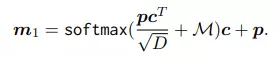
Module MHA thứ 2 thực hiện feature-position attention:
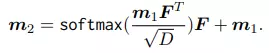
Sau đó được sử dụng để đưa ra dự đoán cuối cùng :
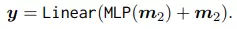
Loss của CLIP4STR là tổng của các cross-entropy loss của 2 nhánh là nhánh visual và nhánh cross-modal:
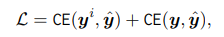
Để tận dụng hoàn toàn khả năng của cả hai nhánh, mô hình được thiết kế với một cơ chế dual decoding gọi là "predict-and-refine". Cụ thể, mô hình CLIP4STR sử dụng một quy trình decoding bao gồm ba bước:
- Nhánh visual ban đầu thực hiện autoregressive decoding, nghĩa là dự đoán tương lai phụ thuộc vào các dự đoán trước đó.
- Tiếp theo, nhánh cross-modal xử lý sự không tương thích có thể xuất hiện giữa feature hình ảnh và ngữ nghĩa văn bản. Quá trình này cũng là autoregressive.
- Cuối cùng, các dự đoán trước đó được sử dụng làm input context theo một phương pháp gọi là "cloze-filling". Quá trình này có thể lặp lại nhiều lần. Sau quá trình thực hiện theo từng bước, đầu ra của nhánh cross-modal trở thành dự đoán cuối cùng cho mô hình.
Quá trình decoding được thể hiện trong mã giả dưới đây:

Thực nghiệm
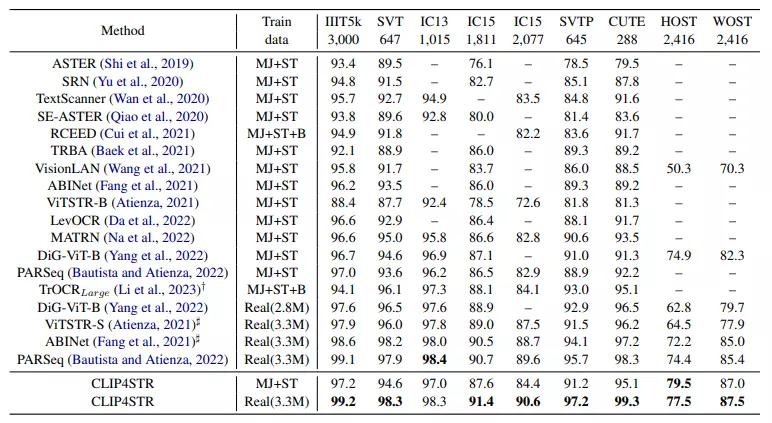
Bảng dưới trình bày độ chính xác theo từ trên 9 benchmark phổ biến. Số lượng sample cũng được hiển thị trong bảng.
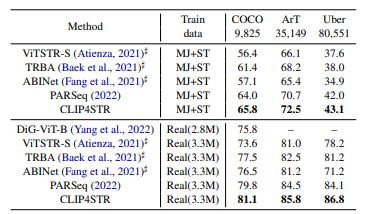
Bảng dưới trình bày độ chính xác theo từ trên 3 benchmark lớn.
Tham khảo
[1] CLIP4STR: A Simple Baseline for Scene Text Recognition with Pre-trained Vision-Language Model
All rights reserved
