
Bài toán trích xuất thông tin từ hóa đơn
Bài đăng này đã không được cập nhật trong 5 năm
Mở đầu
Đợt vừa rồi thì mình có tham gia một cuộc thi về trích xuất thông tin từ hóa đơn có tên gọi là The Mobile capture receipts Optical Character Recognition (MC-OCR) . Mình biết đến cuộc thi này từ lúc a Sơn bên tổ chức đăng bài thu thập dữ liệu về hóa đơn và mình đã hóng từ lúc đó đến tận tháng 12 năm 2020 thì cuộc thi được tổ chức. Cuộc thi bao gồm 2 bài toán đó là: Đánh giá chất lượng ảnh hóa đơn và trích xuất thông tin trên hóa đơn. Ở bài toán thứ nhất, chất lượng ảnh được đánh giá bằng cách lấy tỉ lệ giữa các dòng văn bản nhìn rõ và trên toàn bộ dòng văn bản. Còn bài toán thứ 2 là trích xuất được 4 trường thông tin từ 1 ảnh hóa đơn bao gồm:SELLER, SELLER_ADDRESS, TIMESTAMP, TOTAL_COST. Ở bài toán thứ 2 này giống như các challenges trong cuộc thi của ICDAR 2019-SROIE cũng về dữ liệu hóa đơn, nhưng không chia thành 3 tasks con gồm: Text Detection, Text Recognition và Information Extraction bài toán do BTC MC-OCR đưa ra là kết hợp cả 3 bài toán con lại thành 1 pipeline cho bài toán lớn này. Đặc biệt là cuộc thi này chỉ vỏn vẹn trong vòng 1 tháng nên cũng đòi hỏi sự ứng biến cũng như đưa ra lời giải cho đội của mình nhanh chóng và kịp thời để có thể triển khai, thử nghiệm và cải thiện nó. Ngoài ra, bộ dữ liệu vẫn được BTC public trên link này, các bạn quan tâm có thể tham khảo nhé.
Phương pháp
Vì là 1 cuộc thi mang tính chất ứng dụng thực tế nên mình sẽ chia sẽ cách làm của team mình ra sao để giải quyết bài toán lớn này một cách nhanh chóng nhất. Hy vọng nó sẽ giúp ích phần nào cho các bạn khi gặp dự án thực tế này. Ở bài viết này mình sẽ tập trung nói về phương pháp đưa ra để giải quyết task 2 nhé. Sau đây là pipeline của bọn mình :
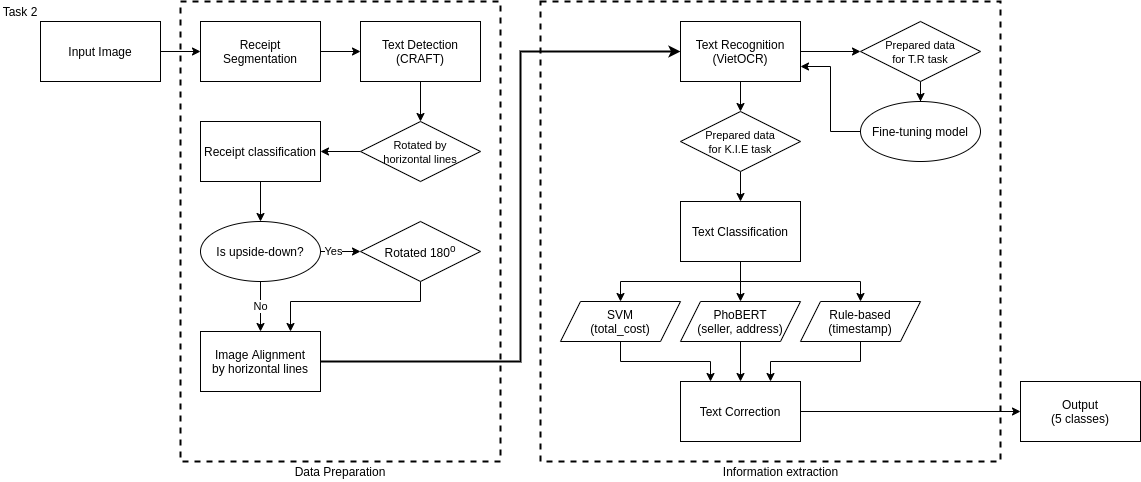
Hình 1: Pipeline phương pháp trích xuất thông tin từ hóa đơn
Theo như trên hình thì bài toán được chia thành 2 giai đoạn đó là giai đoạn chuẩn bị và xử lí data, giai đoạn thứ 2 là trích xuất thông tin.
Tiền xử lí dữ liệu(Preprocessing)
Sau khi nhận được dữ liệu thì mình cùng team đã tiến hành phân tích và thấy rằng dữ liệu có rất nhiều nhiễu và đòi hỏi phải xử lí nếu không muốn kết quả tệ đi. Dữ liễu sau khi phân tích thì nhận thấy rằng nó rất nhiều nhiễu như background ảnh nhiễu lớn, hóa đơn nghiêng, cong, ngược, ngang, nhàu, .... Dưới đây mình sẽ thực hiện cách để giải quyết những vấn đề trên:
Loại bỏ background bằng phương pháp segmentation (Remove background)
Sau khi quá trình EDA, nhận thấy rằng việc loại bỏ background cần thiết phải loại background đi vì nó chiếm không gian rất lớn, điều này làm cho quá trình nhận diễn chữ trở nên khó khăn hơn và nếu background chứa chữ thì sẽ làm cho quá trình nhận diện chữ bị nhầm lẫn.
Vì ảnh hóa đơn nhỏ, có màu tách biệt với màu nền và chữ cái sát viền nên việc cần nhận dạng đúng từng pixel là rất cần thiết nên mình lựa chọn phương pháp segmentation để có thể loại background một cách tốt nhất.
Do ban tổ chức không cung cấp dữ liệu nhãn segmentation nên để làm được điều này bọn mình phải tự label, việc này cũng tốn khá nhiều thời gian.
Sau khi có được label, bọn mình sử dụng thư viện Detectron2 để đem lại kết quả tốt nhất, để hiểu hơn về cách dùng thư viện Detectron2 các bạn tham khảo bài viết của mình tại đây nhé. Sau đây là kết quả của sau khi sử dụng mô hình segmentation:

Hình 2: Kết quả sau khi sử dụng mô hình segmentation
Phát hiện chữ và điều chỉnh ảnh(Text Detection and align image)
Sau khi đã segmentation, ảnh sẽ được crop theo của toàn bộ pixel positive . Vì thời gian hạn chế nên mình quyết định sử dụng pretrained model text detection để sử dụng cho bài toán này. Về model text detection hiện nay có 2 model đạt kết quả khá cao trên các tập benchmark kể đến như CRAFT hay DB. Về độ chính xác thì CRAFT cho kết quả tốt hơn còn về thời gian thì DB cho tốc độ nhanh hơn. Vì đây là cuộc thi nên mình đề cao việc chính xác hơn do đó mình đã sử dụng CRAFT cho bài toán này, kết quả sau khi mình thử nghiệm thì đạt kết quả khá chính xác (Hình 3).
Sau khi nhận được output của CRAFT, mình có được tọa độ các box bao quanh text. Sau đó mình tính ratio của các box dài để xác định được độ nghiêng của box và thực hiện tính toán đề xoay ảnh thẳng trở lại. Kết quả nhận được ở dưới hình sau:

Hình 3: Kết quả khi sử dụng mô hình nhận diện chữ và điều chỉnh ảnh.
Phân loại ảnh(Classify image)
Sau khi đã kết thúc quá trình trên để chuẩn bị sử dụng mô hình nhận dạng chữ thì mình phát hiện ra có rất nhiều ảnh bị ngược và làm cho kết quả text sau khi dùng mô hình text reconition là rất tệ vì chữ bị ngược. Nên bọn mình lại phải xử lí vấn đề này bằng cách sử dụng mô hình classification để phân loại ảnh ngược và xuôi để từ đó xoay lại cho thẳng. Đến đây thì lại gặp vấn đề không có dữ liệu cho việc huấn luyện mô hình, mình và team lại phải tự tạo dữ liệu thành 2 lớp ngược và xuôi, chia toàn bộ tập dữ liệu theo tỉ lệ 4:6 cho xuôi và ngược. Kết quả đạt được cho f1-score đạt 98%. Dưới đây là kết quả mà bọn mình nhận được :

Hình 4: Kết quả sau khi sử dụng mô hình phân loại ảnh xuôi và ngược.
Nhận dạng chữ (Text Recognition)
Phần này may quá là BTC có cung cấp dữ liệu, nhưng chỉ annotated các box chứa các trường SELLER, SELLER_ADDRESS, TIMESTAMP, TOTAL_COST dữ liệu là quá ít để có thể train from srath. Gần đây thì thư viện VietOCR đã được public ra cộng đồng và cho kết quả khá tốt trên dữ liệu tiếng Việt. Do đó bọn mình sử dụng model pre-trained VIETOCR để fine-tunning với dữ liệu mà BTC cung cấp, điều này cho kết quả tốt hơn so với chỉ dùng pre-trained (Model mà mình lựa chọn là TransformerOCR, nếu bạn đang không rõ về nó là mô hình gì thì có thể tham khảo tại đây nhé ). Đây là link thư viện VietOCR, tác giả cũng đã có một tutorial trên notebook để hướng dẫn cách train model nhé, các bạn có thể tham khảo ở đây.
Trích xuất thông tin (Information Extraction)
Đây là một bài toán con khá hay và lớn trong bài toán lớn scence text recognition. Để hiểu hơn về bài toán bày thì mình cũng đã có một bài viết chi tiết để giải thích tại đây.
Ở trong bài viết trên thì mình có giải thích một paper có tên là PICK, tổng quan paper sử dụng dữ liệu về ảnh chứa text, text để nhận đầu vào. Sau khi lấy được đặc trưng về ngữ nghĩa của Text segment và Image segment thì cho qua mô hình Graph để có thể học được thêm đặc trưng về vị trí, mối tương quan giữa chúng. Output đầu ra của graph kết nối với đặc trưng của ảnh vs text ở trên để đưa vào module Decoder, module này gồm BiLSTM+CRF. Loss của mô hình này gồm 2 loss là và .
Model này đạt kết quả khá tốt trên tập dữ liệu SROI2019. Lúc đầu bọn mình có thử nghiệm với mô hình này trên bộ dữ liệu hóa đơn nhưng kết quả không tốt có thể do một số label của BTC đưa ra còn sai một số chỗ, mình có visuallize ra đễ xem và phát hiện được mấy lỗi, dưới đây thì mình đưa ra ví dụ 2 lỗi sau:

Hình 5: Trường hợp label sai nhãn của box

Hình 6: Trường hợp label sai tọa độ box
Điều này có thể phần nào làm kết quả mô hình trở nên tệ đi và một phần nữa do cấu trúc của hóa đơn rất phức tạp.
Sau đó bọn mình đã lựa chọn dùng mô hình phân loại. Trở thành bài toán phân loại text thành 5 lớp SELLER, SELLER_ADDRESS, TIMESTAMP, TOTAL_COST và OTHER. Sự khó khăn của phương pháp này là label cho nhãn OTHER không được BTC cung cấp và bọn mình đã tự xây dụng tập dữ liệu bằng cách sau: Dùng model CRAFT để nhận được box chứa text, sau đó tính IOU giữa box này và box được BTC label, ngưỡng lớn hơn 0.1 bọn mình sẽ lấy label giống với label của BTC, ngược lại sẽ label cho text đó là OTHER. Từ đó bọn mình có được tập dữ liệu để huấn luyện mô hình phân loại, sau khi phân loại 1 model cho cả 5 lớp thì kết quả cho ra không tốt lắm, nhất là bị nhầm lần rất nhiều giữa tập Other và Total_cost. Sau đó bọn mình đã đưa ra giải pháp sử dụng phân loại theo cụm, theo đó cụm đầu tiên sẽ gốm SELLER, SELLER_ADDRESS và OTHER, cụm thứ 2 chỉ có 2 class là TOTAL_COST và OTHER và về TIMESTAMP mình sử dụng regex. Về cụm thứ 1, gồm các text dài nên mình sử dụng VnCoreNLP+PhoBert cho kết quả khá cao và mình thử nghiệm thì hấu như đều bắt được hết trường SELLER và SELLER_ADDRESS . Cụm thứ 2 mình sử dụng Tf-idf+SVM để phân loại 2 label TOTAL_COST và OTHER vì 2 label này có sự không rõ ràng nên việc đưa mô hình phức tạp như PhoBert không cho kết quả cao, thay vì đó sử dụng SVM cho kết quả tốt hơn. Về TIMESTAMP mình sử dụng regex bắt form ngày tháng năm để tìm ra text chứa những form đó, điều này có thể gây sai khi hóa đơn đấy có nhiều ngày giờ, nhưng phần lớn các hóa đơn được giải quyết.
Sau đây là kết quả cuối cùng mình nhận được:

Hình 7: Kết quả 4 trường thông tin từ 1 hóa đơn ngăn bởi dấu ||| theo thứ tự label SELLER, SELLER_ADDRESS, TIMESTAMP, TOTAL_COST
Thử nghiệm
Sau khi kết thúc cuộc thi thì mình có đẩy code lên github, tại đây . Lưu ý đây chỉ là code để inference, code train do có nhiều mô hình nên mình chưa đẩy lên được, trong thời gian sớm nhất mình sẽ đẩy lên.
Để chạy, các bạn phải chuẩn bị bộ dữ liệu cần test vào 1 folder. Sau đó, làm theo các bước sau:
- Bước 1: clone repo về colab hoặc máy gpu
git clone https://github.com/hoainv99/mc-ocr.git
- Bước 2: cài đặt thư viện liên quan
pip install -r requirements.txt
python3 -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
- Bước 3: tải model
cd weights
pip install gdown
gdown --id 1W-O3hPQc4szNezeZQnowNrn46tcgLwz8
Sau đó unzip file weight ra hoặc các bạn lên đây để tải trực tiếp về sau đó cho vào folder weights, tại đây.
- Bước 4: Chạy folder test, kết quả sẽ được 1 file results.csv
python3 test.py --folder_test [path to folder test]
Tổng kết
Kết quả cuộc thi bọn mình đạt được top 2 public test và top 5 private test ở task 2 và bọn mình cũng có submit 1 short paper vào hội thảo RIVF202. Cuối cùng, mình cảm ơn 2 anh Bao Linh và Việt Hoàng đã cùng đóng góp vào cuộc thi này và a Phan Huy Hoang đã tham gia cố vấn. Bài viết còn nhiều hạn chế, mong các bạn đóng góp thêm cho mình vào bài viết và link github ở trên.
All rights reserved
