[LLM 101] Thử chạy Llama 3 trên Laptop cá nhân
Giới thiệu
LLama 3 là một mô hình mới được release gần đây bởi Meta gây xôn xao cho cộng đồng làm AI. Trong bài viết này, mình sẽ trình bày cách bạn có thể chạy một mô hình Llama 3 trên ngay chính laptop của mình. Không cần dài dòng nữa, chúng ta bắt đầu thôi 
Cài đặt
Chúng ta sẽ cần 2 thư viện sau:
Với CPU: Tạo một thư mục mới tên là TestLlama3 và vào terminal chạy đoạn script sau:
python -m venv venv
venv\Scripts\activate #to activate the virtual environment
Bây giờ bạn đã có một môi trường Python để triển rồi , chúng ta sẽ cài đặt thư viện llama-cpp-python và thư viện OpenAI
pip install llama-cpp-python[server]==0.2.62
pip install openai
Lưu ý: Ta chỉ cần càu thư viện OpenAI vì chúng ta sẽ sử dụng máy chủ OpenAPI tích hợp sẵn đi kèm với llama-cpp. Điều này sẽ giúp bạn dễ dàng triển khai các ứng dụng Streamlit hoặc Gradio trong tương lai 😁.
Với Nvidia GPU:
Nếu bạn có GPU Nvidia, bạn sẽ phải đặt flag cho trình biên dịch trước khi gọi lệnh pip:
$env:CMAKE_ARGS="-DLLAMA_CUBLAS=on"
pip install llama-cpp-python[server]==0.2.62
pip install openai
Xong! 👏
Tiếp theo ta sẽ tải mô hình Llama-3–8B GGUF từ HuggingFace.
Chúng ta sẽ sử dụng mô hình được quantized, trong định dạng GGUF.
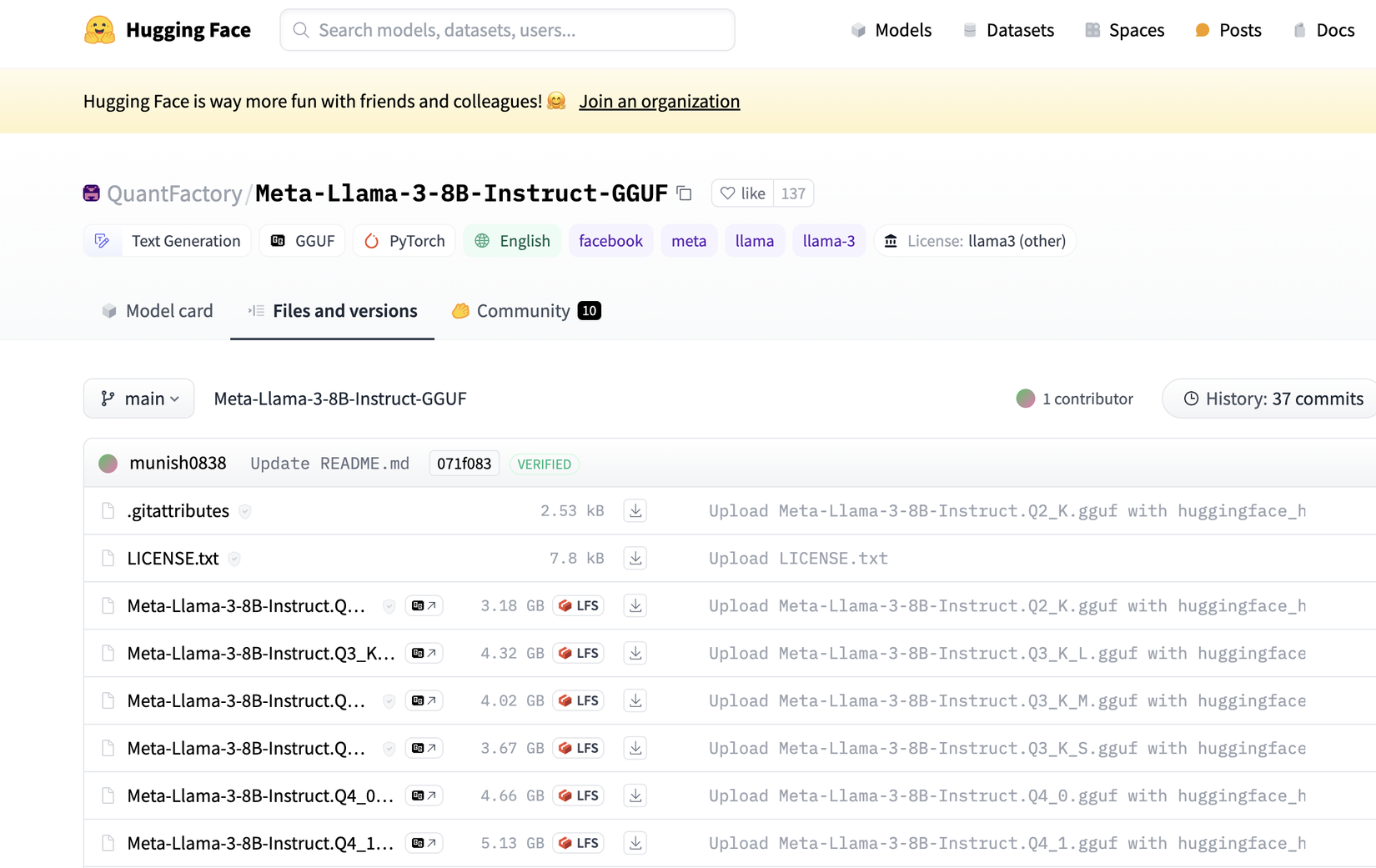
Ta sẽ tải 2 mô hình Q2_K (chỉ 3 Gb) và Q4_K_M (4,9 Gb). Cái đầu tiên sẽ kém chính xác hơn nhưng nhanh hơn, cái thứ hai có sự cân bằng tốt về tốc độ/độ chính xác.
Tạo một thư mục trong thư mục dự án chính của bạn có tên model. Tải xuống file GGUF và chuyển vào trong thư mục đó.
Dưới đây là cách thực hiện. Cách đơn giản nhất là chạy máy chủ llama-cpp-server trong một cửa sổ terminal (với môi trường ảo được kích hoạt...) và tệp Python tương tác với API trong một cửa sổ terminal khác (cũng với môi trường ảo được kích hoạt...)
Vì vậy, ta sẽ mở một cửa sổ terminal trong thư mục chính và kích hoạt venv.
Tạo một file python tên LLama3-ChatAPI.py. Đây là một chương trình giao diện văn bản. Ta sẽ nhập vào prompt, gửi tới máy chủ API và nhận câu trả lời.
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="not-needed")
Ở đây ta gọi thư viện OpenAI có một lớp tích hợp sẵn để gọi API tiêu chuẩn, sau đó chúng ta sẽ thực hiện khởi tạo client.
Tiếp theo, ta định dạng lịch sử tin nhắn với cặp đầu tiên: mục nhập đầu tiên của từ điển Python là tin nhắn hệ thống, và mục nhập thứ hai là prompt người dùng yêu cầu mô hình giới thiệu bản thân.
history = [
{"role": "system", "content": "You are an intelligent assistant. You always provide well-reasoned answers that are both correct and helpful."},
{"role": "user", "content": "Hello, introduce yourself to someone opening this program for the first time. Be concise."},
]
print("\033[92;1m")
Câu lệnh in dưới cùng là mã escape ANSI để thay đổi màu của terminal giúp cho việc theo dõi output dễ dàng hơn
Bây giờ ta sẽ bắt đầu một vòng lặp while: Về cơ bản, chúng ta luôn yêu cầu người dùng nhập vào prompt và tạo ra phản hồi từ mô hình Meta-Llama-3–7B-instruct.
while True:
completion = client.chat.completions.create(
model="local-model", # trường này hiện đang không được sử dụng
messages=history,
temperature=0.7,
stream=True,
)
new_message = {"role": "assistant", "content": ""}
for chunk in completion:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
new_message["content"] += chunk.choices[0].delta.content
history.append(new_message)
print("\033[91;1m")
userinput = input("> ")
if userinput.lower() in ["quit", "exit"]:
print("\033[0mBYE BYE!")
break
history.append({"role": "user", "content": userinput})
print("\033[92;1m")
Trong đoạn code trên, lệnh đầu tiên là để tạo một chat completion. Bạn có thể chạy và nhập message của mình để kiểm tra kết quả.
Ta sử dụng Stream method nên Python sẽ bắt đầu output phản hồi theo từng token ngay khi chúng được gửi từ cuộc gọi API.
Lưu ý: nếu bạn không có GPU thì có thể mất vài giây, tùy thuộc vào prompt như thế nào (nên cân nhắc rằng tất cả các cuộc trò chuyện trước đó luôn là một phần của lời message... nếu không, Llama3 sẽ quên cả tên của bạn! 😭)
Trong code, ta thêm message mới vào lịch sử trò chuyện hiện có (history) để Llama3 có thể lấy thông tin từ đoạn chat trước.
Để chạy chương trình, trong cửa sổ terminal đầu tiên, với venv được kích hoạt, hãy chạy lệnh sau:
# Với CPU
python -m llama_cpp.server --host 0.0.0.0 --model .\model\Meta-Llama-3-8B-Instruct.Q2_K.gguf --n_ctx 2048
# Nếu bạn có GPU Nvidia
python -m llama_cpp.server --host 0.0.0.0 --model .\model\Meta-Llama-3-8B-Instruct.Q2_K.gguf --n_ctx 2048 --n_gpu_layers 28
Câu lệnh trên sẽ khởi chạy server FastAPI tương thích với tiêu chuẩn OpenAI. Bạn sẽ nhận được kết quả như sau:
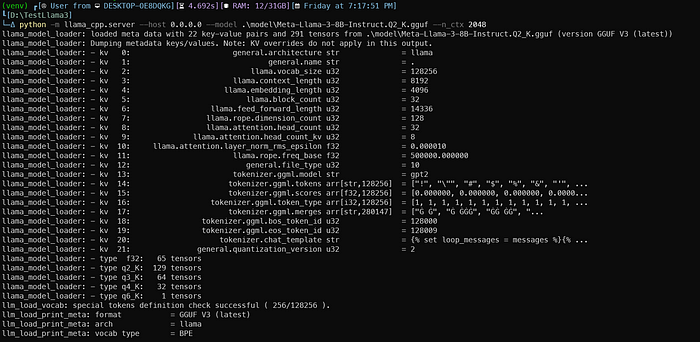
Khi máy chủ sẵn sàng, Uvicorn sẽ thông báo cho bạn như hình dưới:
Một số lưu ý:
-
Trong ví dụ trên ta set 2048 token context: Thực tế, Llama3 có 8192 token cho context, nhưng điều này cũng tiêu thụ RAM hoặc VRAM nhiều hơn, vì vậy mình để tạm giá trị thấp.
-
Mô hình tham số 8B này thực sự có 33 layer, nhưng mình chỉ đặt 28 layer trên GPU. Bạn có thể tự thử nghiệm set số layer và theo dõi kết quả 😁.
-
Trong ví dụ này, mình sử dụng phiên bản Q2 của mô hình Meta-Llama-3–8B-Instruct.Q2_K.gguf. Bạn có thể thay thế nó bằng tên tệp Q4_K_M để chạy phiên bản quantized 4 bit.
Tổng kết
Trong bài viết trên, mình đã trình bày cách chạy một mô hình Llama 3 đơn giản mà bạn có thể thực hành ngay trên laptop của mình. Hy vọng bạn có thể sử dụng mô hình mới này của Meta để phục vụ và tối ưu cho các công việc của mình
All rights reserved
