CÁC MÔ HÌNH TRONG BÀI TOÁN SPEECH TO TEXT (S2T)
Bài đăng này đã không được cập nhật trong 4 năm
Ở 2 bài trước, mình đã trình bày về dữ liệu âm thanh. Bước tiếp theo chúng ta sẽ cùng tìm hiểu về các mô hình trong bài toán speech to text.
Cách tiếp cận thống kê trong bài toán S2T
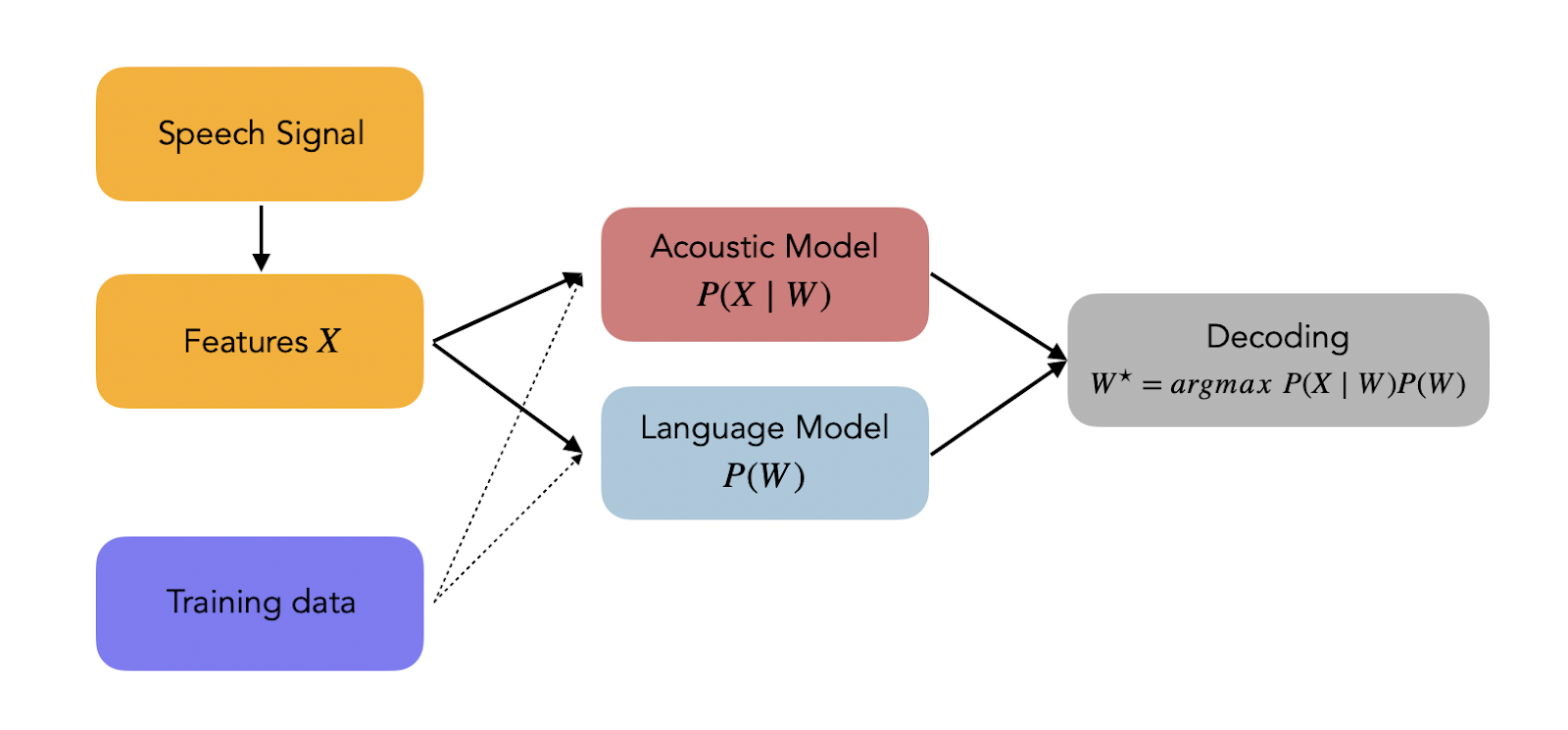
- Mục tiêu chính của bài toán S2T là xây dựng một mô hình thống kê để dự đoán các chuỗi văn bản (W) dựa trên các vector đặc trưng (X).
- Có thể giải thích mô hình thống kê như sau: tìm kiếm tất cả các chuỗi từ có thể có (hạn chế độ dài tối đa) và tìm một chuỗi từ phù hợp nhất với đặc điểm âm thanh đầu vào.
![yyyyyyyyy.png]()
- Các bước được trình bày ở hình sau:
![eeeeeeee.png]()

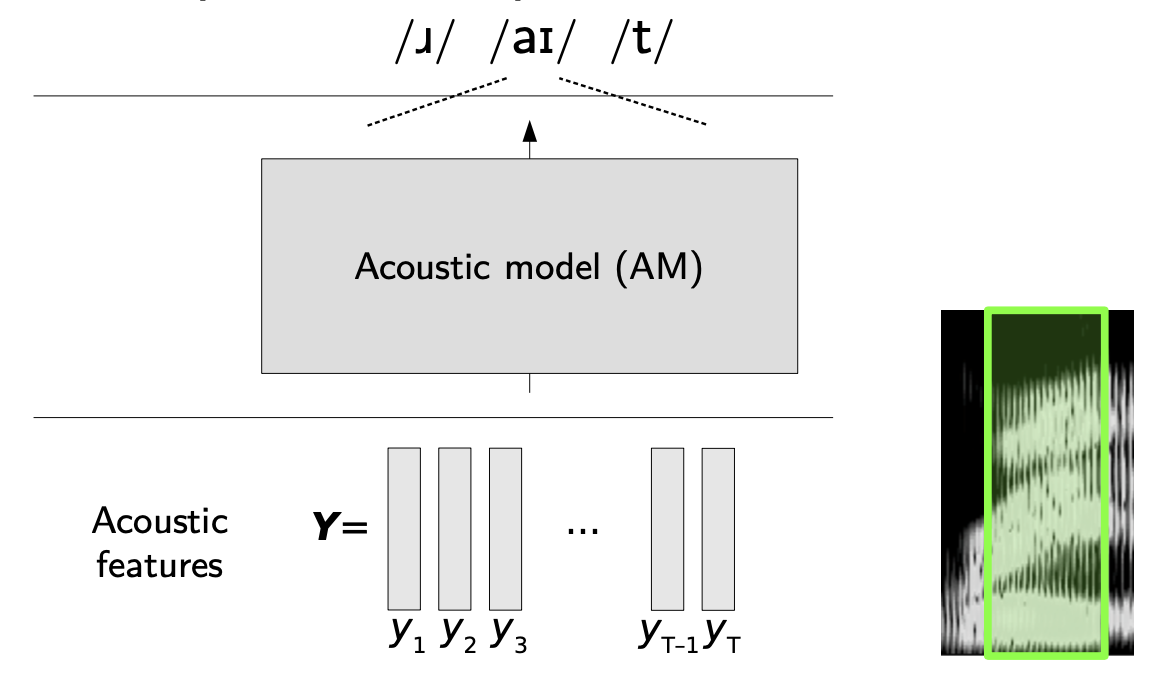
Acoustic Model (Mô hình âm thanh)
Mô hình âm thanh là một mô hình phức tạp, mô hình hóa mối quan hệ giữa tín hiệu âm thanh và các đơn vị ngữ âm trong ngôn ngữ.
HMM-GMM Acoustic model
HMM (Mô hình Markov ẩn)
Mô hình Markov ẩn với ba trạng thái:
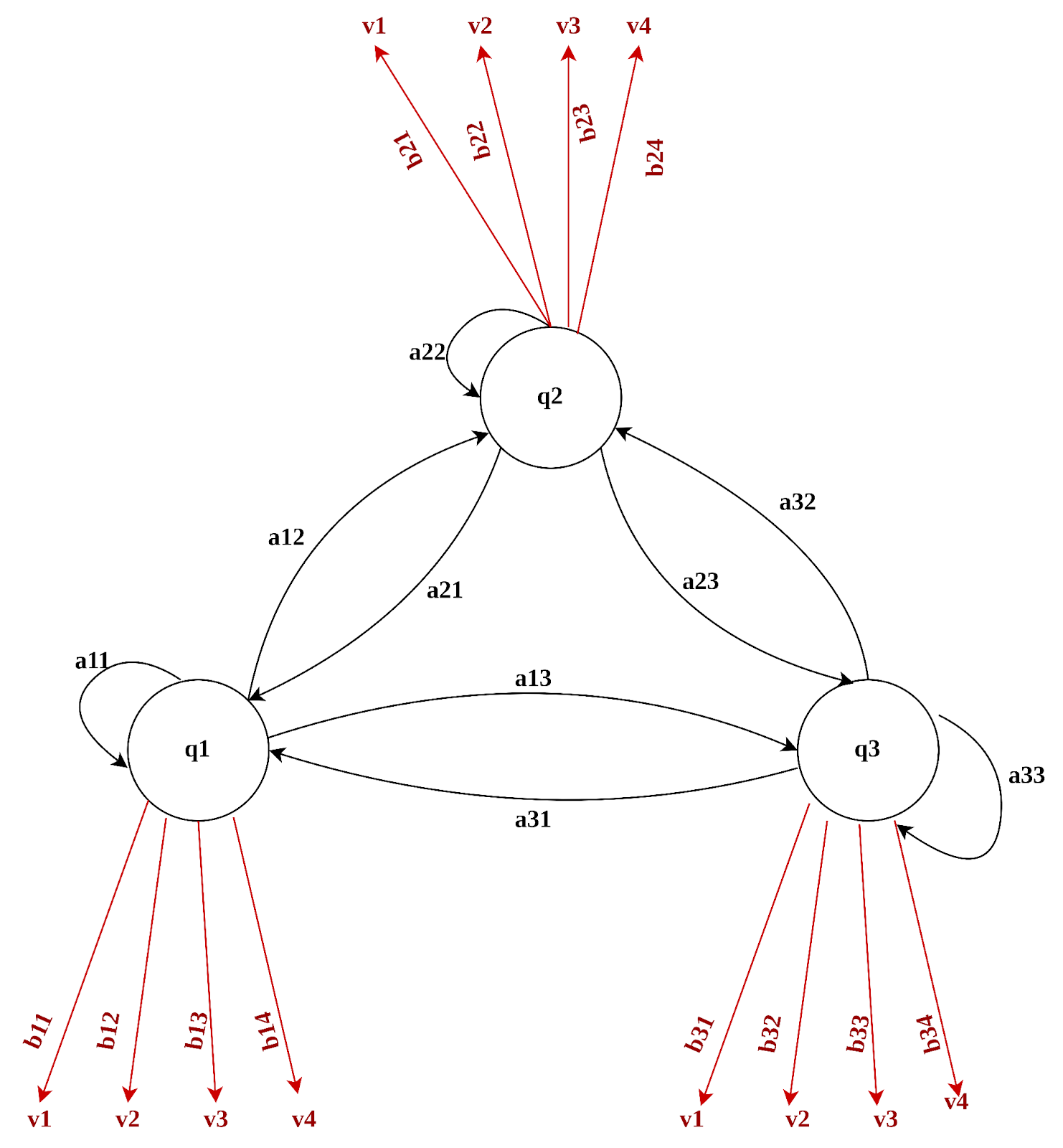
Mô hình Markov ẩn (HMM) là mô hình thống kê máy trạng thái, cho phép chúng ta xem xét đến hai thành phần là sự kiện quan sát được và các sự kiện ẩn.
Ví dụ trong nhận dạng giọng nói thì sự kiện quan sát được là các đặc trưng âm học của tiếng nói, còn sự kiện ẩn là các từ.
HMM bao gồm các thành phần chính sau:
- Q = q1, q2, …, qN: là tập của N trạng thái.
** A = a11, q12, …, ann*: là ma trận chuyển trạng thái (transition matrix) với aij là xác suất để trạng thái j xuất hiện tại thời điểm t+1 khi trạng thái i đã xuất hiện tại thời điểm t. - O = o1, o2, …, oT: là một chuỗi T các quan sát tại các thời điểm t khác nhau.
Tương ứng với mỗi trạng thái tại thời điểm t sẽ có một tập V = {o1, o2, …, om} là tập tất cả các quan sát có thể được quan sát thấy trong mỗi trạng thái. - 𝐵 = {𝑏𝑗 (𝑣𝑘 )}: B là phân bố xác suất quan sát được các quan sát o trong trạng thái qj.
- Π = {π1, π2, …, πN}: tập các phân bố xác suất cho trạng thái khởi đầu, πi là xác suất để trạng thái i được chọn tại thời điểm khởi đầu t = 1 (có thể hiểu như khi chúng ta khởi tạo tham số cho các mô hình Deep Learning).
=> Ở hình trên biểu diễn một ví dụ của HMM với 3 trạng thái Q = q1, q2, q3. Tại mỗi trạng thái q, các sự kiện quan sát được là V = (v1, v2, v3, v4) và B = (b1, b2, b3, b4) là phân bố xác suất quan sát được sự kiện với bj(k) là xác suất quan sát được sự kiện vk trong trạng thái qj.
Đối với HMM, có 3 bài toán chính:
- Bài toán 1: Computing likelihood
Cho biết trước mô hình HMM λ(π, A, B) và chuỗi quan sát O=O1, O2, …, OT. Xác định likelihood P(O|λ). Ví dụ trong nhận dạng tiếng nói, ta có quan sát O là tín hiệu tiếng nói và λ là mô hình, vậy bài toán cần giải là tính likelihood P để mô hình λ quan sát được O. - Bài toán 2: Decoding
Cho một chuỗi quan sát O và mô hình HMM λ(A,B,π), xác định chuỗi Q tốt nhất. Trong nhận dạng tiếng nói thì đây chính là bài toán nhận dạng, khi quan sát O là tín hiệu tiếng nói thì bài toán là tìm chuỗi âm vị Q tương ứng với tín hiệu này. - Bài toán 3: Learning
Co một chuỗi quan sát O và tập các trạng thái của HMM, điều chỉnh các tham số λ = {A, B, π} của HMM để P(O| λ) lớn nhất.
Đây chính là bài toán huấn luyện mô hình HMM.
Có thể giải quyết 3 bài toán trên bằng 3 thuật toán sau: Forward, Viterbi, Baum Welch. Các bạn có thể tìm hiểu thêm về các thuật toán này tại đây.
Trong HMM, 1 âm vị thường được biểu diễn bằng HMM tuyến tính 3 hoặc 5 trạng thái
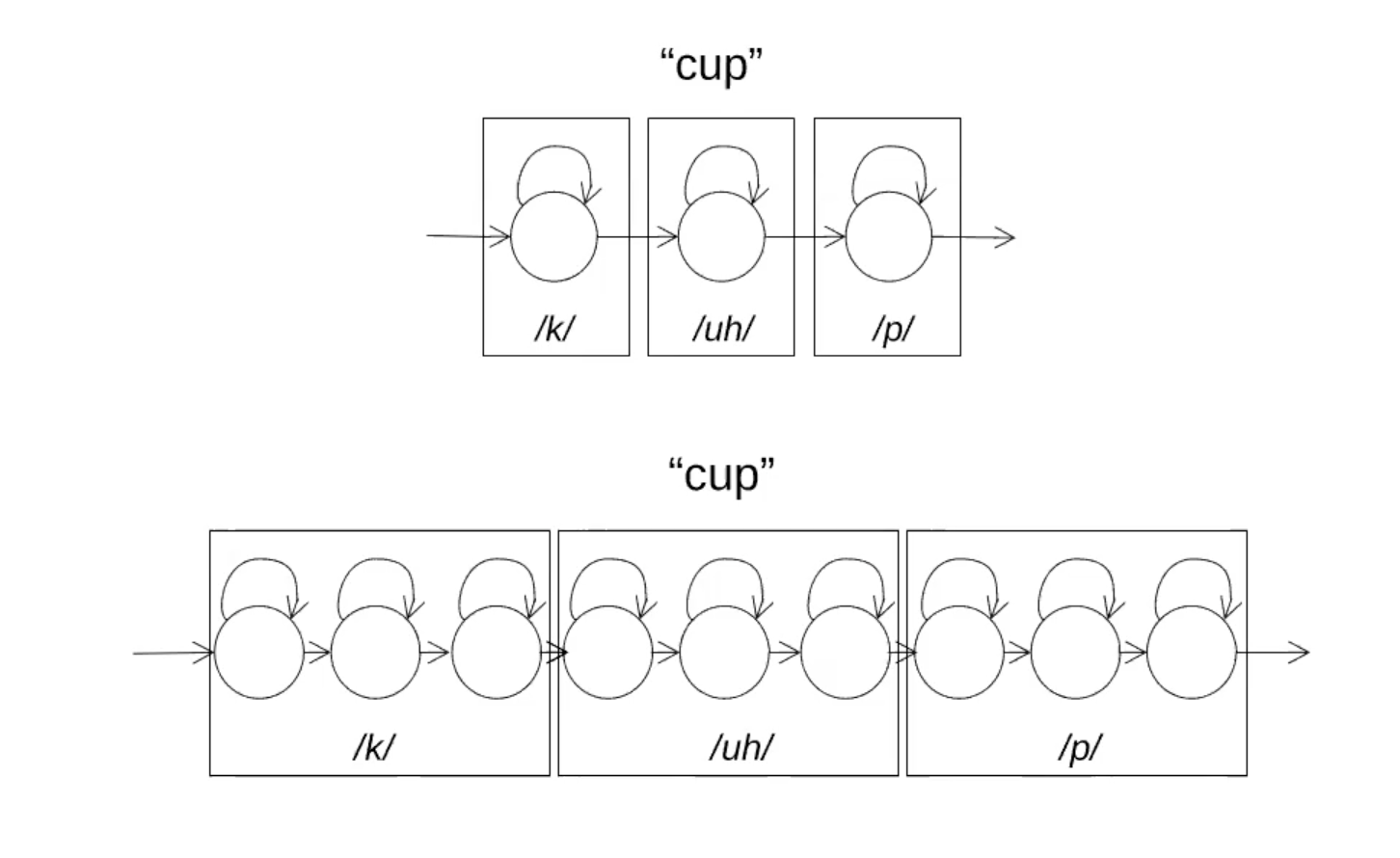
Có 1 câu hỏi đặt ra là: Các quan sát được tạo ra bằng cách nào?
Câu trả lời là sử dụng GMM (Gaussian Mixture Model). GMM là một mô hình phân phối để đánh giá khả năng các quan sát được tạo ra.
Việc đào tạo HMM-GMM được giải quyết bằng Tối đa hóa kỳ vọng (Expectation Maximization - EM). Các bạn có thể tìm hiểu rõ hơn về GMM và EM qua bài viết này.
HMM-DNN Acoustic model
Kiến trúc HMM-DNN tiếp cận mô hình âm thanh theo một cách khác. Thay vì đi tìm kiếm câu trả lời cho P(X|W), thì HMM-DNN trực tiếp trả lời cho P(W|X). DNN dự đoán xác suất trạng thái của một khung thoại, trong khi HMM kết hợp các dự đoán của DNN để dự đoán trạng thái tiếp theo.
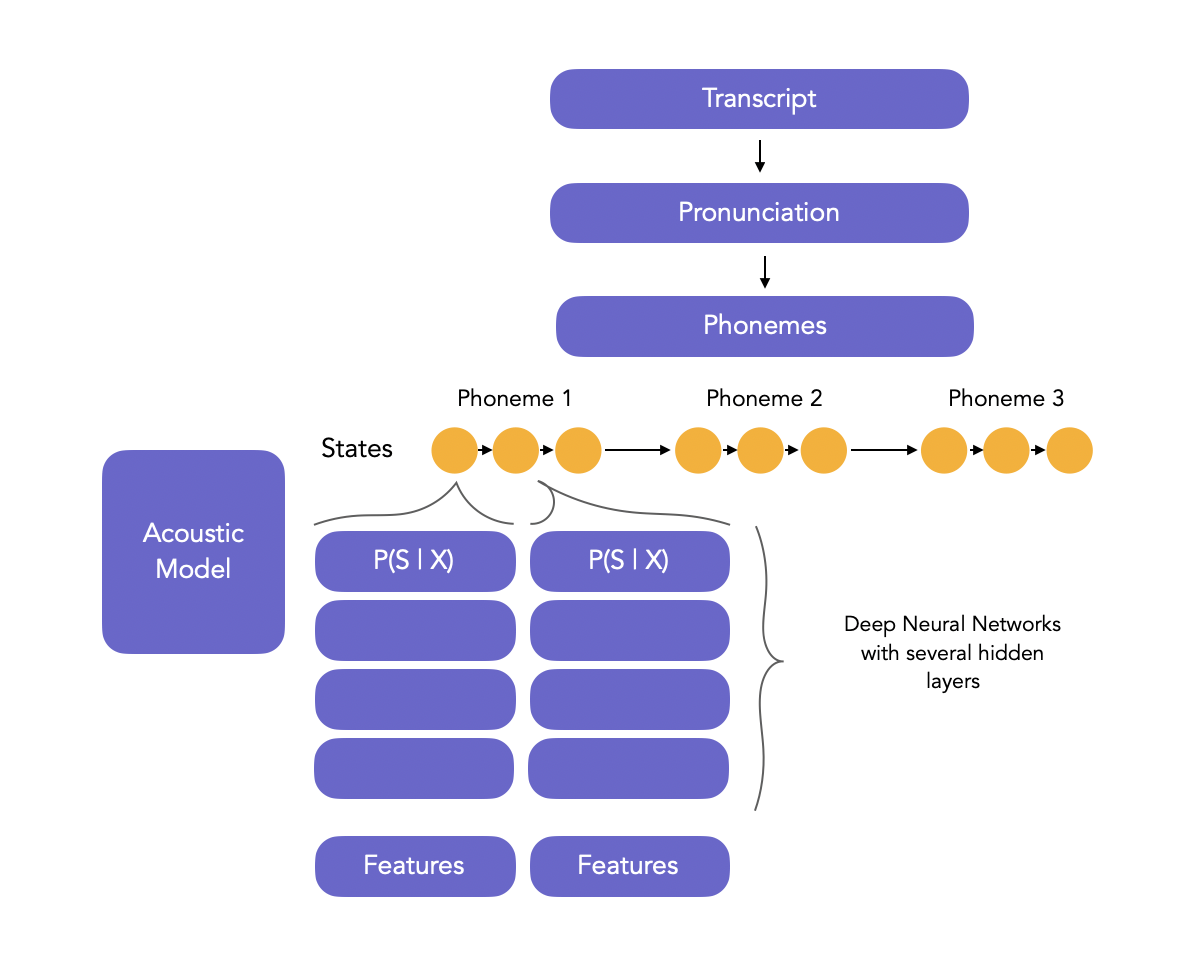
Language Modeling (Mô hình ngôn ngữ)
Mô hình ngôn ngữ được biểu diễn bằng P(W). Mô hình ngôn ngữ thống kê là loại mô hình gán xác suất cho các chuỗi từ.
N-gram language model
Công thức:
P(w|h), tính xác suất của từ w khi biết trước các từ trước nó h
Ví dụ:
P(yêu|Tôi là một cô gái đáng)
Ở đây, w = yêu,
h = Tôi là một cô gái đáng .
Tính xác suất trên bằng phương pháp đếm tần suất tương đối, trong đó chúng ta cần sử dụng một kho ngữ liệu (corpus) lớn. Từ kho ngữ liệu này, đếm số lần xuất hiện của “Tôi là một cô gái đáng”, sau đó đếm số lần xuất hiện của “yêu" sau nó.
- P(yêu|Tôi là một cô gái đáng) = C(Tôi là một cô gái đáng yêu)/C(Tôi là một cô gái đáng)
Thử tượng tưởng, nếu corpus bạn lên đến hàng triệu, hàng trăm nghìn từ thì tính toán này có khả thi không? Mô hình N-gram có thể giải quyết vấn đề này, thay vì tính toán xác suất bằng cách sử dụng toàn bộ kho dữ liệu, thì sẽ ước tính nó chỉ bằng một vài từ (N) đã xuất hiện trước đó.
![]() Trong đó n có thể là 1(unigram), 2(bigram), 3(trigram)
Trong đó n có thể là 1(unigram), 2(bigram), 3(trigram)
-
Có thể thấy nhược điểm của các mô hình ngôn ngữ thống kê là được đào tạo dựa trên 1 kho ngữ liệu cố định. Nếu dữ liệu ở ngoài tập ngữ liệu này, sẽ dẫn đến xác suất bằng 0. Ngoài ra còn thiếu tính tổng quát khi tùy vào từng thể loại, từng chủ đề thì sẽ có các cách kết hợp câu, từ khác nhau.
-
Để giải quyết vấn đề này, chúng ta có thể sử dụng các mô hình ngôn ngữ học sâu. Gần đây, trong lĩnh vực NLP, các mô hình ngôn ngữ dựa trên mạng nơ ron ngày càng trở nên phổ biến hơn.
Kết luận
Mình sẽ kết thúc bài này tại đây. Qua bài này chúng ta đã hiểu rõ phần nào về kiến trúc bài toán S2T. Mình sẽ viết thêm về cách huấn luyện cũng như sử dụng các mô hình deep learning thay vì mô hình thống kê trong các bài sau. Các bạn cùng đón đọc nhé.
Tài liệu tham khảo
https://www.aiourlife.com/2020/04/tong-hop-tieng-noi-su-dung-mo-hinh.html?showComment=1598613008903
https://jonathan-hui.medium.com/speech-recognition-gmm-hmm-8bb5eff8b196
https://maelfabien.github.io/machinelearning/speech_reco/#1-hmm-gmm-acoustic-model
https://towardsdatascience.com/introduction-to-language-models-n-gram-e323081503d9
All rights reserved
