XỬ LÝ DỮ LIỆU ÂM THANH
Bài đăng này đã không được cập nhật trong 4 năm
Cũng giống như các bài toán Deep Learning khác, việc đầu tiên chúng ta cần làm là xử lý dữ liệu. Vậy với dữ liệu audio, các bước tiền xử lý sẽ như thế nào? Trong bài viết này, mình sẽ trình bày chi tiết về vấn đề này.
Sử dụng các thư viện âm thanh trong python để lấy đặc trưng
Thư viện python hỗ trợ xử lý âm thanh
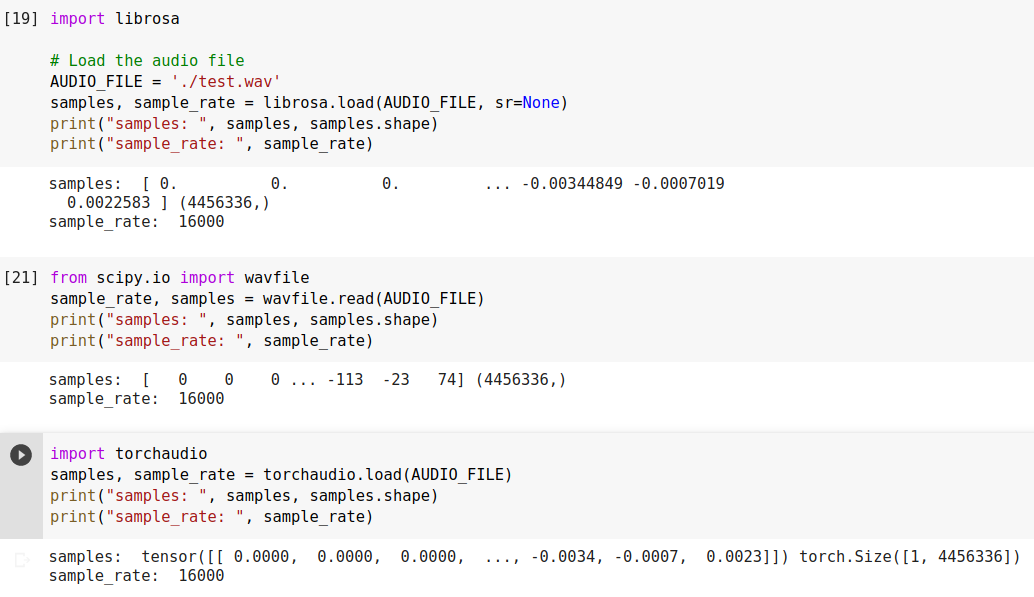
Một số thư viện python hỗ trợ xử lý âm thanh như librosa, scipy, torchaudio. Tất cả đều cho phép bạn đọc các tệp âm thanh ở các định dạng khác nhau.
- Bước đầu tiên là tải tệp lên:
![]()
- Bạn có thể biểu diễn sóng âm thanh như sau:
![fffffff.png]()
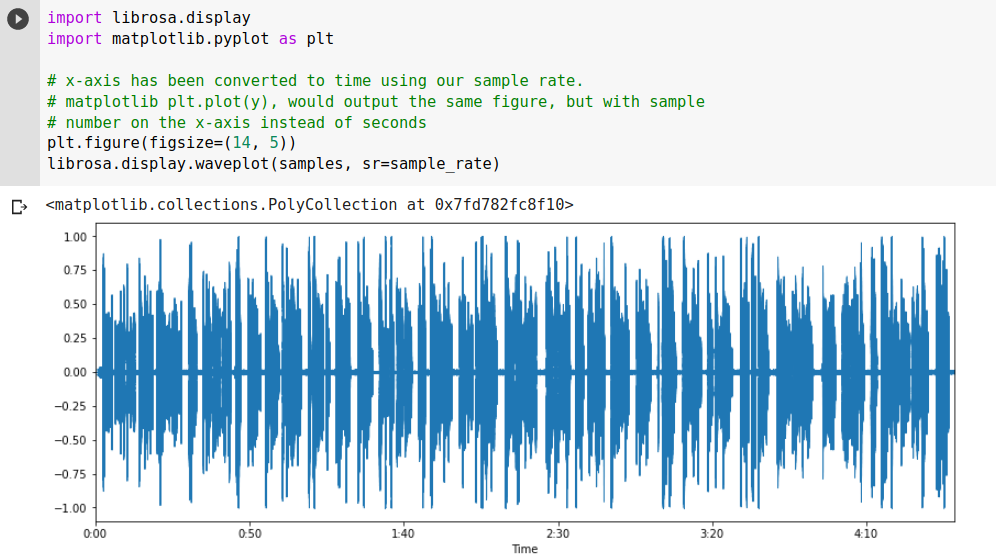
Dữ liệu tín hiệu âm thanh (Audio Signal Data)
Khi âm thanh được lưu trong một tệp, nó sẽ ở định dạng nén. Khi tệp được tải, nó sẽ được giải nén và chuyển đổi thành một mảng Numpy.
![]()
Mỗi phần tử trong mảng này đại diện cho biên độ của sóng âm thanh ở 1/sample_rate khoảng thời gian của giây.
-
Ví dụ với file âm thanh ở trên dài 278.521s với sample rate là 16000hz thì số lượng samples của file sẽ là 278.52 * 16000=4456336
-
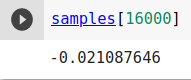
Biên độ của tần số ở giây thứ 1 là:
![]()
-
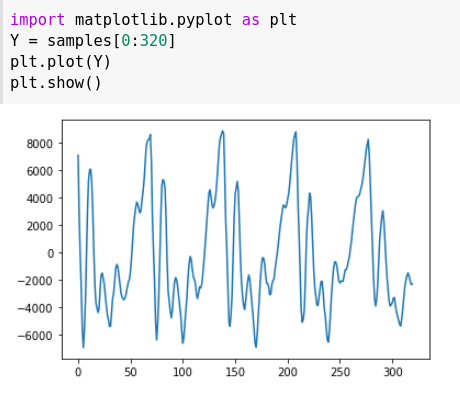
Bây giờ, chúng ta tiếp tục nhóm âm thanh lấy mẫu thành các đoạn dài 20 mili giây.
![aaaaaaâ.png]()
-
Biểu diễn dưới dạng biểu đồ đường cho khoảng thời gian 20ms này:
![rrrrrrrrrr.png]() Chúng ta có thể thấy đoạn ghi âm này chỉ dài 1/50 giây. Nhưng ngay cả đoạn ghi âm ngắn này cũng là một bản trộn lẫn phức tạp của các tần số âm thanh khác nhau. Có một số âm thanh trầm, một số âm thanh tầm trung và thậm chí một số âm thanh cường độ cao. Nhưng khi những tần số khác nhau này kết hợp với nhau lại tạo nên âm thanh phức tạp của giọng nói của con người.
Chúng ta có thể thấy đoạn ghi âm này chỉ dài 1/50 giây. Nhưng ngay cả đoạn ghi âm ngắn này cũng là một bản trộn lẫn phức tạp của các tần số âm thanh khác nhau. Có một số âm thanh trầm, một số âm thanh tầm trung và thậm chí một số âm thanh cường độ cao. Nhưng khi những tần số khác nhau này kết hợp với nhau lại tạo nên âm thanh phức tạp của giọng nói của con người. -
Để làm cho dữ liệu này dễ dàng hơn cho mạng nơ-ron xử lý, chúng ta sẽ tách sóng âm thanh phức tạp này thành các phần thành phần của nó. Vậy thì tách như thế nào ???
Thử hình dung theo ví dụ này, mọi người sẽ thấy dễ hiểu hơn. Trong âm nhạc, ta thường có các hợp âm. Giả sử bạn đánh hợp âm C Major trên đàn piano. m thanh này là sự kết hợp của 3 nốt nhạc C, E và G. Chúng ta cần tách âm thanh phức tạp này thành các nốt riêng lẻ để biết rằng chúng là C, E và G. Đây chính là ý tưởng phân tích âm thanh thành các thành phần của nó.
Chúng ta thực hiện việc phân tích này dựa vào biến đổi Fourier.

Biến đổi Fourier
Theo wikipedia, tính chất của biến đổi Fourier:

Với phép biến đổi Fourier, chúng ta chuyển đổi một tín hiệu từ miền thời gian sang miền tần số. Biến đổi Fourier không chỉ cung cấp các tần số có trong tín hiệu mà còn cung cấp độ lớn của mỗi tần số có trong tín hiệu.
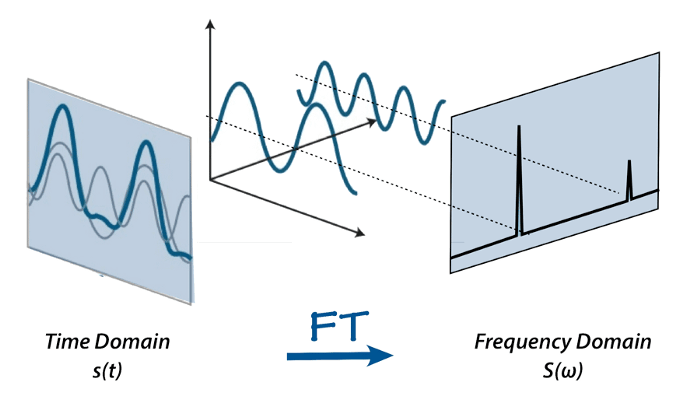
Tuy nhiên, hạn chế của biểu diễn miền tần số là không có thông tin về thời gian.
Spectrogram
Trong phần trước, chúng ta đã chia tín hiệu thành các giá trị tần số của nó, chúng sẽ đóng vai trò là features cho mạng nơ ron nhận dạng giọng nói. Nhưng khi áp dụng FFT cho tín hiệu của mình, nó chỉ cung cấp các giá trị tần số và chúng ta bị mất dấu thông tin thời gian. Do đó, chúng ta cần tìm một cách khác để tính toán các features sao cho các giá trị tần số và thời gian đều được quan sát. Spectrogram có thể giải quyết được vấn đề này.
Biểu diễn trực quan các tần số của một tín hiệu nhất định với thời gian được gọi là Spectrogram.
Trong biểu đồ biểu diễn Spectrogram - một trục biểu thị thời gian, trục thứ hai biểu thị tần số và màu sắc biểu thị độ lớn (biên độ) của tần số quan sát tại một thời điểm cụ thể. Màu sắc tươi sáng thể hiện tần số mạnh. Các tần số nhỏ hơn từ (0–1kHz) là mạnh (sáng). (Các tần số mạnh chỉ nằm trong khoảng từ 0 đến 1kHz vì đoạn âm thanh này là lời nói của con người. )
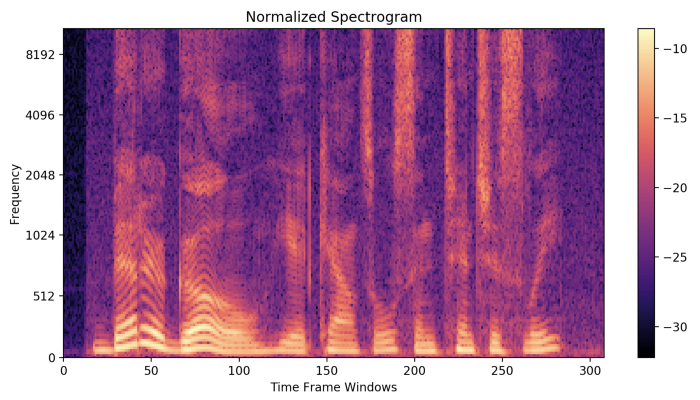
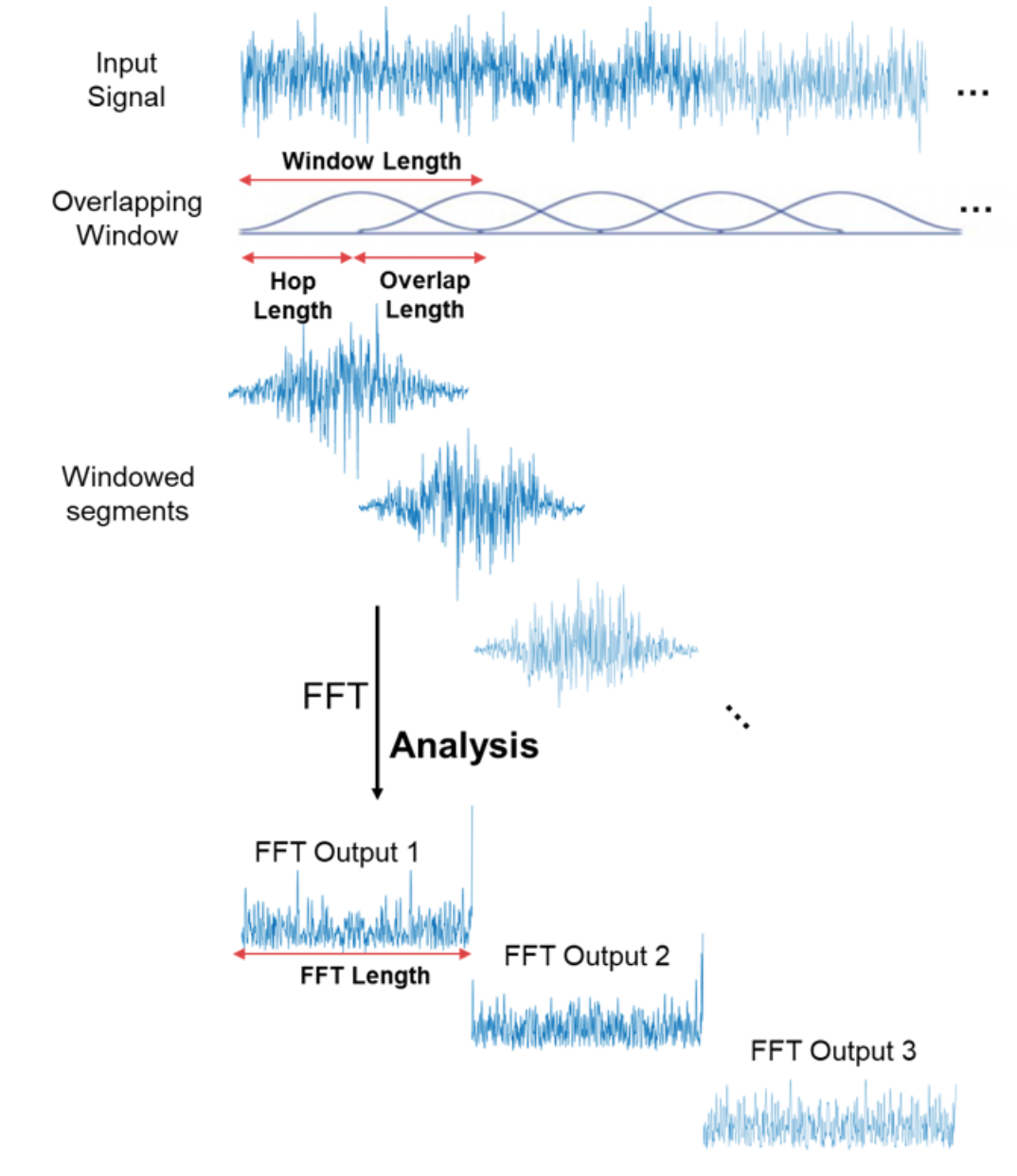
Tạo Spectrogram
-
Ý tưởng chính là chia tín hiệu âm thanh thành các khung nhỏ hơn (cửa sổ) và tính toán DFT (hoặc FFT) cho mỗi cửa sổ đó. Bằng cách này, chúng tôi sẽ nhận được tần số cho mỗi cửa sổ và số cửa sổ sẽ đại diện cho thời gian. Để không làm mất một vài tần số khi lấy các cửa sổ một cách liên tục, chúng ta thường giữ cho các cửa sổ này chồng lên nhau (overlap). Đối với tác vụ nhận dạng giọng nói thông thường, bạn nên sử dụng cửa sổ dài từ 20 đến 30 ms. Một con người không thể nói nhiều hơn một âm vị trong khoảng thời gian này.
![o.png]()
-
Đầu ra của thuật toán DFT (hoặc FFT) là 1 mảng các số đại diện cho các biên độ của các tần số khác nhau trong cửa sổ. Ma trận 2D thu được là biểu đồ Spectrogram.
-
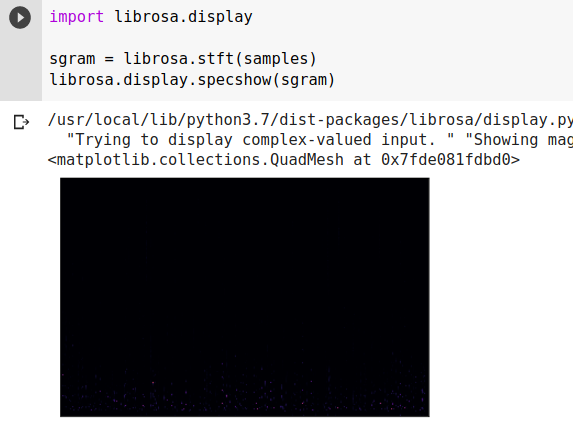
Thử biểu diễn Spectrograms bằng code:
![iiiiiii.png]() Nhìn vào biểu đồ trên, chúng ta không thể thấy rõ được các thông tin về tần số, biên độ mà Spectrogram thể hiện. Điều này được giải thích là do khả năng nhận thức âm thanh của con người. Hầu hết những âm thanh mà chúng ta nghe được đều tập trung xung quanh một dải tần số và biên độ khá hẹp. Vì vậy, trong nhiều bài toán (đặc biệt là nhận dạng giọng nói), Spectrogram không phải là sự lựa chọn hoàn hảo. Vì vậy ta cần thêm vài bước tính nữa để thu được dạng MFCC hoặc Mel Spectrogram, tốt hơn, phổ biến hơn, hiệu quả hơn Spectrogram.
Nhìn vào biểu đồ trên, chúng ta không thể thấy rõ được các thông tin về tần số, biên độ mà Spectrogram thể hiện. Điều này được giải thích là do khả năng nhận thức âm thanh của con người. Hầu hết những âm thanh mà chúng ta nghe được đều tập trung xung quanh một dải tần số và biên độ khá hẹp. Vì vậy, trong nhiều bài toán (đặc biệt là nhận dạng giọng nói), Spectrogram không phải là sự lựa chọn hoàn hảo. Vì vậy ta cần thêm vài bước tính nữa để thu được dạng MFCC hoặc Mel Spectrogram, tốt hơn, phổ biến hơn, hiệu quả hơn Spectrogram.
Mel Spectrogram
Mel Scale
- Các nghiên cứu đã chỉ ra rằng con người không cảm nhận được tần số trên thang đo tuyến tính. Con người có thể dễ dàng phân biệt được âm thanh với tần số thấp hơn tần số cao. hầu hết con người có thể dễ dàng nhận ra sự khác biệt giữa âm thanh 100 Hz và 200 Hz nhưng lại khó nhận ra sự khác biệt giữa 2000 và 2100 Hz, mặc dù khoảng cách giữa hai bộ âm thanh là như nhau. Đây là cách con người cảm nhận các tần số. Đây là điều khiến Mel Scale trở thành nền tảng cơ bản trong các ứng dụng Máy học đối với âm thanh, vì nó bắt chước nhận thức của con người về âm thanh.
- Sự chuyển đổi từ thang đo Hertz sang thang đo Mel như sau:
![sssssssssss.png]()
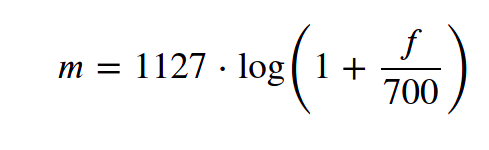
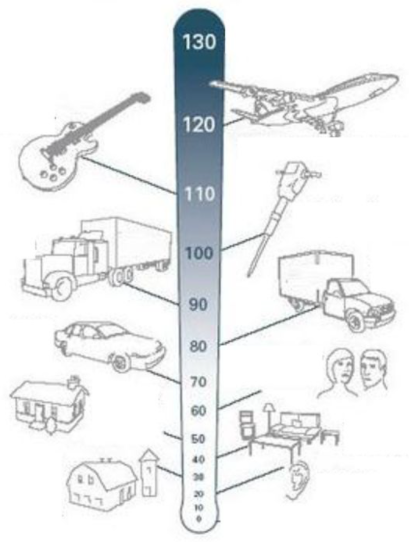
Decibel Scale
- Trong thang đo này, 0 dB là hoàn toàn im lặng. Từ đó, các đơn vị đo lường tăng lên theo cấp số nhân. 10 dB lớn hơn 10 lần so với 0 dB, 20 dB lớn hơn 100 lần và 30 dB lớn hơn 1000 lần. Trên thang đo này, âm thanh trên 100 dB bắt đầu trở nên lớn đến mức không thể chịu nổi.
- Để xử lý âm thanh một cách chân thực, cách xử lý của Mel Spectrogram như sau:
- Tần số (trục y) được thay thế bằng giá trị Logarithmic của nó, gọi là Mel Scale.
- Biên độ được thay thế bằng giá trị Logarithmic của nó, gọi là Decibel Scale để chỉ ra màu sắc.
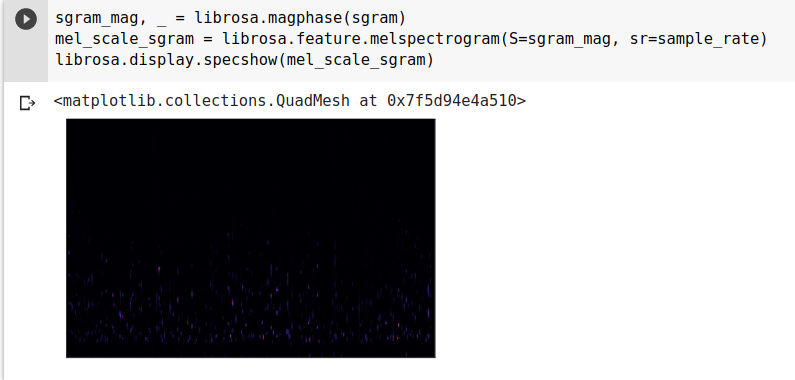
- Chúng ta thử vẽ lại Spectrogram ở trên, thay thế tần số bằng Mel Scale:
![p.png]()
- Biểu đồ này biểu diễn tốt hơn Spectrograms, nhưng phần lớn vẫn còn tối và không mang đủ thông tin hữu ích. Thử sửa đổi nó để sử dụng Decibel Scale thay vì Biên độ.
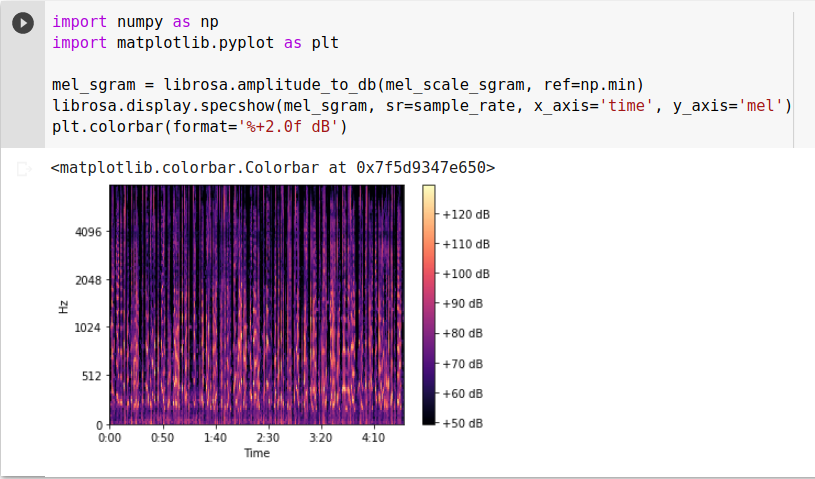
![rrrrrrrrrrrr.png]()
Đến đây thì thông tin của Audio đã được thể hiện rất rõ ràng trên hình ảnh của Mel Spectrogram.
Ngoài Mel Spectrogram, thì đặc trưng MFCC cũng thường được sử dụng để trích xuất đặc trưng âm thanh. Các bạn có thể tìm hiểu kĩ hơn ở đây.
Kết luận
Ở bài này, mình đã trình bày về một số đặc trưng âm thanh thường được sử dụng trong bài toán Speech To Text. Bài tiếp theo mình sẽ trình bày về cách tiếp cận các mô hình trong bài toán này. Cảm ơn các bạn đã đón đọc và xem tiếp bài của mình nhé. 👋👋👋
Tài liệu tham khảo
https://towardsdatascience.com/learning-from-audio-the-mel-scale-mel-spectrograms-and-mel-frequency-cepstral-coefficients-f5752b6324a8
https://towardsdatascience.com/audio-deep-learning-made-simple-part-2-why-mel-spectrograms-perform-better-aad889a93505
All rights reserved
