Sơ lược về Mel Frequency Cepstral Coefficients (MFCCs)
Bài đăng này đã không được cập nhật trong 7 năm
Giới thiệu
MFCC là một cách để trích xuất các đặc trưng (feature extraction) giọng nói (speech) thường được sử dụng trong các model nhận dạng giọng nói (Automatic Speech Recognition) hay phân loại giọng nói (Speech Classification). Đúng như tên gọi của nó, MFCC sẽ cho ra kết quả là các hệ số (coefficients) của cepstral (từ này mình không biết dịch sao hết) từ Mel filter trên phổ lấy được từ các file âm thanh chứa giọng nói.
Nguyên lý hoạt động
Giọng nói thì thường sẽ được biểu diễn dưới dạng hai chiều với là thời gian (time) theo miliseconds (ms) và là amplitude (dịch ra là biên độ). Trong đó những giá trị trên được sinh ra trực tiếp từ bộ thu âm, do đó người ta thường gọi là speech signal.
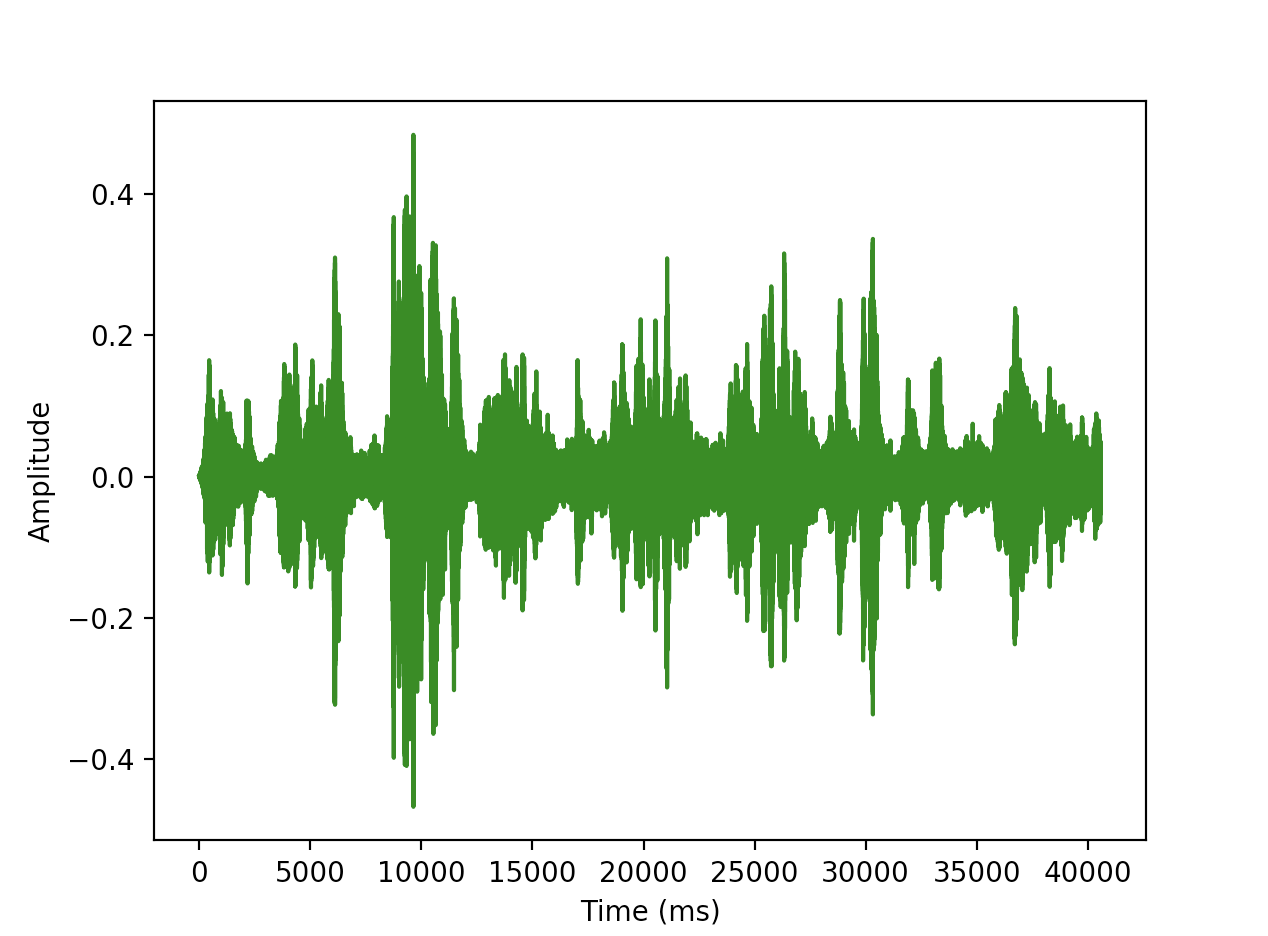
Đầu tiên, ta sẽ biến đối speech signal thành âm phổ (hay còn gọi là spectrum) bằng cách áp dụng Fast Fourier Transform, mình sẽ không giải thích giải thuật này, các bạn có thể xem khái niệm ở wikipedia.
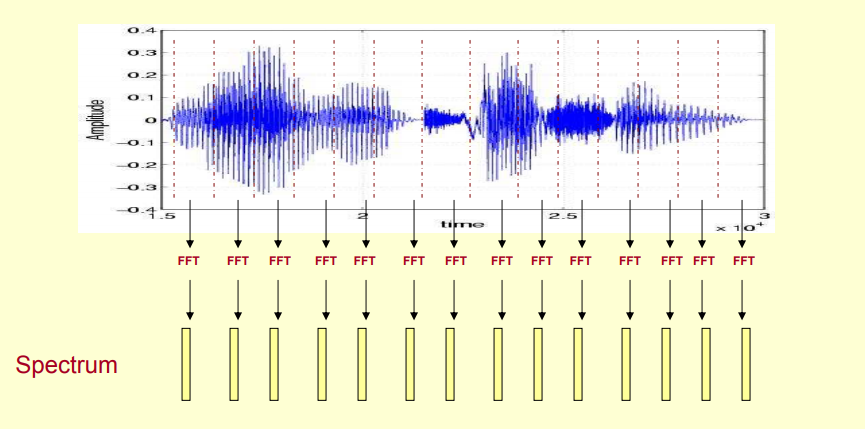
Kết quả của việc biến đổi này, tức là spectrum, được biểu diễn dưới dạng hai chiều với là tần số (Hz) và là cường độ (dB).
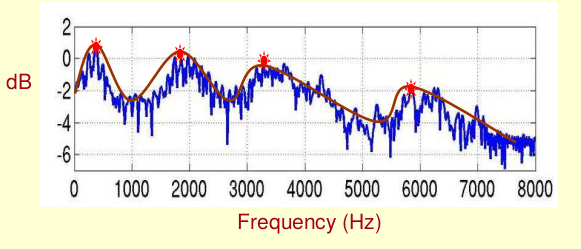
Ở hình trên, các điểm màu đỏ được gọi là Formants, là nơi có các tần số áp đảo (dominant), mang đặc tính của âm thanh. Đường màu đỏ gọi là Spectral Envelopes. Mục tiêu chính của ta là lấy được đường màu đỏ này.
Gọi spectrum là có hai thành phần là spectral envelopes và spectral details
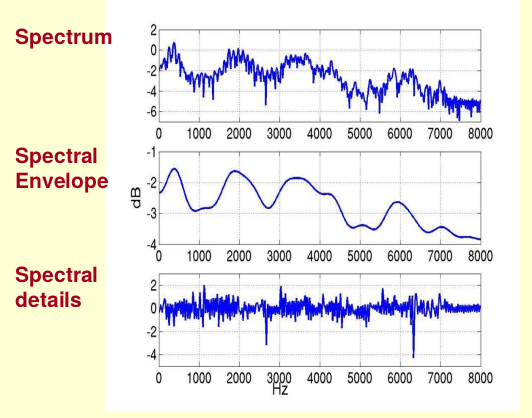
Để tách được , ta cần phải lấy logarithm của spectrum và lấy phần ở tần số thấp (low frequency):
Người ta thấy rằng tai người hoạt động như một bộ lọc, chỉ tập trung vào một phần thay vì hết cả spectral envelopes. Thế là một bộ lọc lấy ý tưởng này ra đời, gọi là Mel-Frequency Filter:
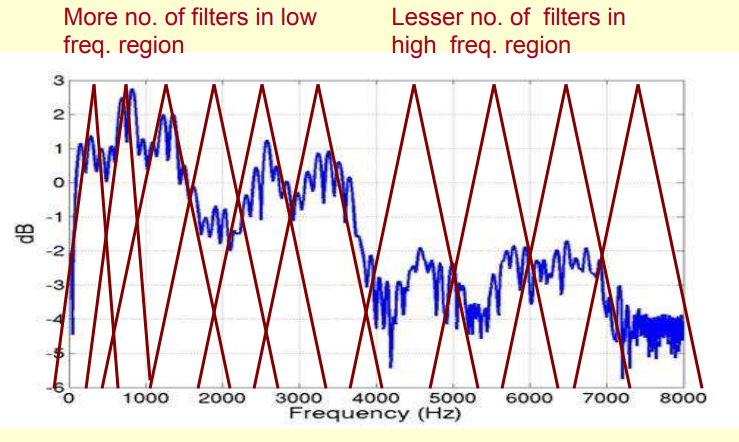
Chi tiết về bộ lọc này sẽ được nói ở phần sau. Sau khi áp dụng bộ lọc này, ta sẽ sử dụng Inverse Fast Fourier Transform lên logarithm của spectrum:
Trong đó, được gọi là cepstrum vì IFFT là nghịch đảo của FFT và cepstrum cũng là nghịch đảo của spectrum, hay chứ nhỉ.
Cepstrum bây giờ sẽ giống như Speech Signal, biểu diễn dưới dạng hai chiều , nhưng giá trị sẽ khác nên người ta cũng gọi hai cột với tên khác là là magnitude (không có đơn vị) và là quefrency (ms).
Và MFCCs cũng chính là các giá trị lấy từ Cepstrum này, thông thường người ta sẽ lấy 12 hệ số của vì mấy cái còn lại không có tác dụng trong các hệ thống nhận diện âm thanh.
Tóm lại, pipeline của ta sẽ là speech signal spectrum mel-freq filter cepstral.
MFCCs được hiện thực như thế nào?
Với nguyên lý hoạt động ở trên, để hiện thực cho máy tính trích xuất được MFCCs thì ta sẽ phải thêm một số thành phần khác. Pipeline cơ bản như sau:
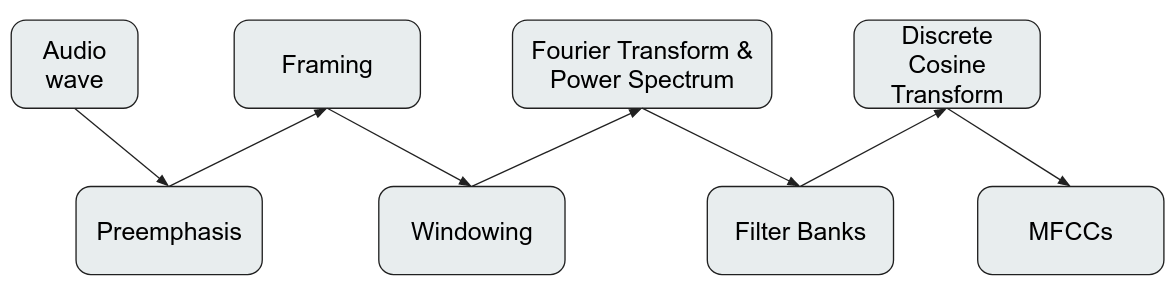
Preemphasis
Ta sẽ áp dụng công thức sau lên speech signal:
Có nhiều lý do để áp dụng preemphasis như:
- Tránh vấn đề về số khi áp dụng FFT
- Làm cân bằng tần số spectrum
- Khuếch đại tần số cao (để lọc tần số thấp dễ hơn)
Nhưng mà preemphasis không bắt buộc sử dụng nữa vì FFT đã được cải thiện.
Framing
Speech signal ở dạng liên tục theo từng ms, do đó khó để giải quyết nên người ta sẽ chia speech signal thành các frames.
Mỗi frame có kích thước khoảng 20-40 ms và chồng lên nhau (tức là từ đầu frame sau tới cuối frame trước) khoảng 10-15 ms.
Kết quả sẽ ở dưới dạng hai chiều với là frame_length và là number_of_frames.
Windowing
Do framing làm rời rạc hóa speech signal ta sẽ áp dụng một hàm gọi là Hamming Window để làm smooth các frames:
Trong đó là frame_length
Fourier Transform and Power Spectrum
Đây là bước ta chuyển speech signal thành spectrum, ta sẽ áp dụng công thức sau:
Trong đó bằng 256 hoặc 512, là frame thứ của speech signal .
Filter Banks
Đây là bước ta áp dụng bộ lọc Mel-Frequency FIlter.
Các phương trình sau dùng để chuyển giữa Hert và Mel :
Sau đây là chi tiết về bộ lọc này, đó là các phương trình sau:
Discrete Cosine Transform and MFCCs
Đây là bước ta chuyển từ spectrum qua cepstrum, áp dụng DCT (1 dạng IFFT) lên kết quả của filter banks ta sẽ có được các MFCCs, sau đó lấy 12 hệ số như đã nói.
Tham khảo
- https://wiki.aalto.fi/display/ITSP/Cepstrum+and+MFCC
- http://practicalcryptography.com/miscellaneous/machine-learning/guide-mel-frequency-cepstral-coefficients-mfccs/
- https://haythamfayek.com/2016/04/21/speech-processing-for-machine-learning.html ở đây có cách hiện thực trong python
- http://www.speech.cs.cmu.edu/15-492/slides/03_mfcc.pdf
All rights reserved
