@thangtd90 em làm đc rồi ạ cảm ơn a, mà cho e hỏi e load cả thằng categorys thì bên view e hiển thị kiểu gì để lấy được tên của category đấy ạ, e dùng with thì lấy ra được nhưng sử dụng phương thức đấy cho load thì lại k lấy đc.
@yukihoaian tự tạo một navigation bằng 1 view ở top màn hình được nhé bạn. Nhưng custom nó thực sự khá mệt và tốn công đấy. Bạn cho mình biết tình huống bạn đang mắc đi, có thể sẽ có giải pháp khác mà không phải dùng đến custom view thành navigation
e lưu giống bên trên của a ạ, e xong phần admin rồi nên giờ e muốn hiển thị ra frontend, e làm theo kiểu này đầu tiên e
$productNew=Product::select(....)->get();
rồi e sử dụng foreach để lặp
foreach($productNew as $data)
// em hiển thị tag
foreach($data->tags as $tag)
<p>{!! $tag->name !!}</p>
@endforeach
endforeach
như này vẫn ra nhưng nhiều query quá ạ, thành ra e có 3 sản phẩm thì nó lên tận 4 câu query, bình thường join e hay sử dụng query builer thay vì dùng with('tags') vì with('tags') nó ra 2 câu query còn query builer nó hiển thị có 1 câu query, như ảnh bên dưới của e, e join với bảng category nó hiện ra có 1 câu query
mình làm cho ngân hàng, thì requirement liên quan đến core banking thì gần như không thay đổi, và do phòng nghiệp vụ làm, nếu có thay đổi thì thường là do nghiệp vụ, và sẽ là 1 issue khác. sản phẩm chỉ có đúng hoặc sai, chứ ko có vừa làm vừa sửa. trung bình 3 tháng cho 1 issue, 1 tháng phân tích, code 1 tháng, nghiệm thu 1 tháng.
nhưng bên internet banking thì lại khác, các issue rất nhiều nhưng mình chỉ làm trong ngày, có khi báo 1 cái 15 phút sau đã làm xong rồi, làm agile rất chuẩn
nên theo mình agile hay water fall thì cũng tùy ngữ cảnh mới có hiệu quả
Bài viết dịch và bài gốc viết hơi khó hiểu, nên bôi đậm những chỗ quan trọng, sắp xếp đại ý rõ ràng hơn.
Agile giúp thích ứng với thay đổi của khách hàng 1 cách tốt nhất, nhưng việc release nhanh chóng và nhỏ nhất có thể phụ thuộc vào trình độ team, REQs phân tích sao cho chuẩn nhất trong thời gian ngắn nhất của sprint ...
Mình thấy thực tế áp dụng Agile, cụ thể là Agile Scrum vẫn chưa hiệu quả như lý thuyết, vì yếu tố năng lực code và vị trí BA.
@Katoji dạ. e cảm ơn anh. à anh ơi. anh có bao giờ custom một cái view thành navigationcontroller bao giờ chưa anh? anh có ví dụ nào không? cho em tham khảo với ạ!

THẢO LUẬN
@xuanhung Em dùng
loadnhư thế nào mà không được nhỉVí dụ như khi đã có
$productsrồi, thì em có thể gọi$products->load('category')để eager loading tất cả các category của các products ra màNếu bạn thấy câu trả lời nào hợp lý , bạn có thể accept nó nhé. 😋
Bài viết có chất lượng khá cao.
@thangtd90 em làm đc rồi ạ cảm ơn a, mà cho e hỏi e load cả thằng categorys thì bên view e hiển thị kiểu gì để lấy được tên của category đấy ạ, e dùng with thì lấy ra được nhưng sử dụng phương thức đấy cho load thì lại k lấy đc.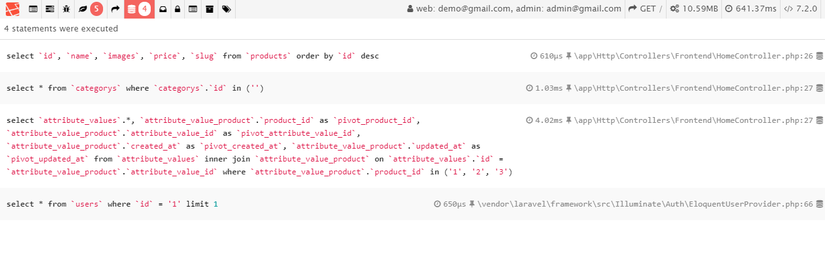
@yukihoaian tự tạo một navigation bằng 1 view ở top màn hình được nhé bạn. Nhưng custom nó thực sự khá mệt và tốn công đấy. Bạn cho mình biết tình huống bạn đang mắc đi, có thể sẽ có giải pháp khác mà không phải dùng đến custom view thành navigation
@xuanhung Dùng Many to Many Relationship của Laravel thì em cũng dùng được eager loading mà
Bài viết rất hữu ích. Thanks tác giả nhé
thanks you
thanks you
e lưu giống bên trên của a ạ, e xong phần admin rồi nên giờ e muốn hiển thị ra frontend, e làm theo kiểu này đầu tiên e
rồi e sử dụng foreach để lặp
như này vẫn ra nhưng nhiều query quá ạ, thành ra e có 3 sản phẩm thì nó lên tận 4 câu query, bình thường join e hay sử dụng query builer thay vì dùng
with('tags')vìwith('tags')nó ra 2 câu query còn query builer nó hiển thị có 1 câu query, như ảnh bên dưới của e, e join với bảng category nó hiện ra có 1 câu querymình làm cho ngân hàng, thì requirement liên quan đến core banking thì gần như không thay đổi, và do phòng nghiệp vụ làm, nếu có thay đổi thì thường là do nghiệp vụ, và sẽ là 1 issue khác. sản phẩm chỉ có đúng hoặc sai, chứ ko có vừa làm vừa sửa. trung bình 3 tháng cho 1 issue, 1 tháng phân tích, code 1 tháng, nghiệm thu 1 tháng.
nhưng bên internet banking thì lại khác, các issue rất nhiều nhưng mình chỉ làm trong ngày, có khi báo 1 cái 15 phút sau đã làm xong rồi, làm agile rất chuẩn
nên theo mình agile hay water fall thì cũng tùy ngữ cảnh mới có hiệu quả
@Nam_Nguyen bạn có thể tiếp cận theo hướng headless browser, có khá nhiều thư viện với nhiều ngôn ngữ hỗ trợ, nổi bật là js với PhantomJS.
P ython thì có Ghost.
Bạn có thể google thêm tuỳ theo ngôn ngữ đang sử dụng.
Bạn ơi, bạn cho mình xin
Reposource code được không ạ. Tks bạnlike
Bài viết hay, cảm ơn đã chia sẻ
Bài viết dịch và bài gốc viết hơi khó hiểu, nên bôi đậm những chỗ quan trọng, sắp xếp đại ý rõ ràng hơn. Agile giúp thích ứng với thay đổi của khách hàng 1 cách tốt nhất, nhưng việc release nhanh chóng và nhỏ nhất có thể phụ thuộc vào trình độ team, REQs phân tích sao cho chuẩn nhất trong thời gian ngắn nhất của sprint ... Mình thấy thực tế áp dụng Agile, cụ thể là Agile Scrum vẫn chưa hiệu quả như lý thuyết, vì yếu tố năng lực code và vị trí BA.
@Katoji dạ. e cảm ơn anh. à anh ơi. anh có bao giờ custom một cái view thành navigationcontroller bao giờ chưa anh? anh có ví dụ nào không? cho em tham khảo với ạ!
tks bạn nhiều
tks bạn
Thanks c nhieu