
Xây dựng mạng Unet cho bài toán Segmentation
Bài đăng này đã không được cập nhật trong 6 năm
1. Kiến trúc mạng Unet
Trong Computer Vision và xử lý ảnh chúng ta thường đề cập đến 2 bài toán là Image Classification và Image Detection. Hôm nay mình sẽ giới thiệu tới mọi người bài toán thứ 3 trong lĩnh vực này, đó là bài toán Image Segmentation. Có thể hiệu đơn giản về sự khác nhau giữa 3 bài toán này thông qua hình sau:
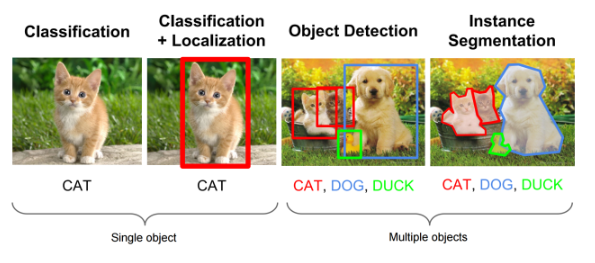
Đối với bài toán classification thì chúng ta quan tâm đến sự xuất hiện của các vật thể trong hình ảnh. Đối với bài toán detection chúng ta xác định vị trí của đối tượng trong hình ảnh sau đó vẽ 1 boundary box xung quanh đối tượng. Còn đối với bài toán segmentation chúng ta cần phải xác định class cho mỗi pixel trong bức ảnh.
Kĩ thuật chung khi ta xây dựng mạng cho bài toán này là ta sẽ xây dựng mạng gồm 2 thành phần encoder và decoder
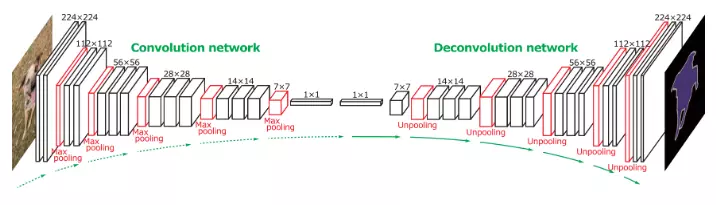
Trong đó phần encoder dùng để giảm chiều dài và chiều rộng của ảnh bằng việc sử dụng các lớp convolutions và các lớp poolings. Trong đó phần decoder dùng để phục hồi lại kích thước ban đầu của ảnh. Phần encoder thường chỉ là một mạng CNN thông thường nhưng bỏ đi những layer fully conected cuối cùng. Chúng ta có thể sử dụng những mạng có sẵn trong phần encoder như VGG16, VGG19, Alexnet,... Còn decoder tùy vào các kiến trúc mạng mà ta có thể xây dựng khác nhau. Ví dụ trong mạng FCN.
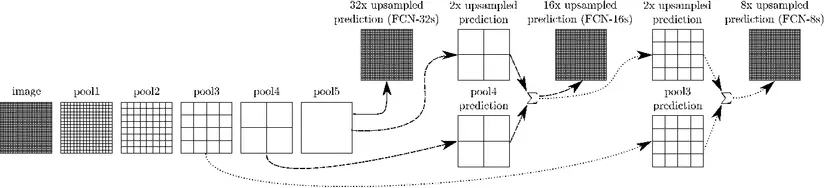
Trong kiến trúc FCN, có 3 cách để xây dựng phần decoder tạo thành 3 loại FCN khác nhau là FCN32, FCN16, FCN8. Đối với FCN32, sau khi đến lớp pooling cuối cùng (trong ví dụ trên là lớp pooling thứ 5) ta chỉ cần upsample về kích thước ban đầu. Đối với FCN16 thì tại lớp pooling thứ 5 ta nhân 2 lần để được kích thước bằng với kích thước của lớp pooling thứ 4, sau đó add 2 lớp vào với nhau rồi upsample lên bằng với kích thước ảnh ban đầu. Tương tự với FCN8 ta kết nối tới lớp pooling thứ 3.
Còn trong kiến trúc mạng Unet ta xây dựng phần decoder gần như đối xứng với phần decoder.
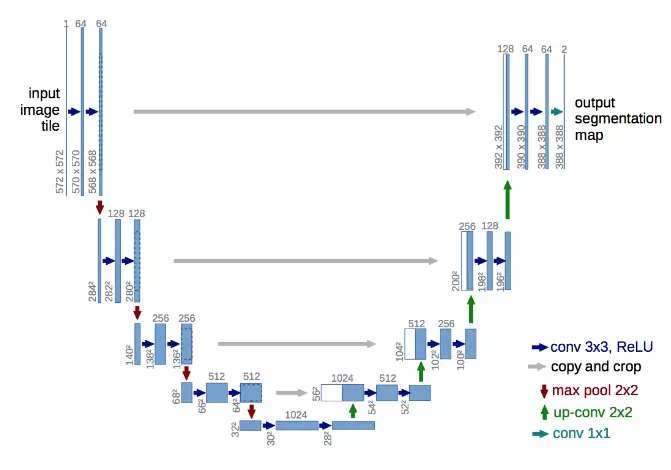
Trong phần decoder ngoài việc upsample ta còn thực hiện kết nối đối xứng với các layer phần encoder cho đến tận layer cuối cùng. Rõ ràng nếu như ta upsample ngay từ layer cuối cùng ở phần encoder thì thông tin của bức ảnh ban đầu bị mất đi rất nhiều. Do đó việc ta kết nối đối xứng với phần encoder sẽ giúp ta phục hồi lại thông tin đã mất tại các lớp pooling. Bây giờ mình sẽ code để xây dựng mạng một mạng Unet đơn giản.
Xây dựng mạng Unet đơn giản
Mình sẽ xây dựng mạng Unet với các tham số sau:
- nch: số channels của anhr đầu vào
- patch_height, patch_width: kích thước chiều dài chiều rộng bức ảnh
- conv: số filters của các lớp convolution
- activ: là các activation function sau moõi lớp conv
- core_activation_function: activation function tại layer cuối cùng
- learning_rate: là tham số learning rate của thuật toán optimization
- dropout và loss_function
def unet (n_ch, patch_height, patch_width , conv =[64, 128, 256, 512, 1024], activ,
core_ activation_function, learning_rate, drop_out, loss_function):
Đầu tiên ta sẽ định nghĩa kích thước ảnh đầu vào:
inputs = Input((n_ch, patch_height, patch_width))
Sau đó ta sẽ xây dựng phần encoder. Phần encoder ở đây mình sẽ xây dựng gồm 5 lớp convolution đơn giản. Ở cả 5 layer mình đều sử dụng fulter kích thước 3x3. Ở layer đầu tiên là 64 filter, ở layer thứ 2 là 128 filter, ở layer thứ 3 là 256 filter, layer thứ 4 là 512 filter, ở layer cuối cùng là 1024 filter. Ở mỗi layẻ mình đều sử dụng maxpooling kích thước 2x2. Như vậy sau mỗi layer, kích thước của ảnh sẽ giảm đi 2 lần và độ sâu của ảnh tăng lên 2 lần.
conv1 = Convolution2D(conv[0], 3, 3, activ, border_mode = 'same')(inputs)
conv1 = Dropout(drop_out)(conv1)
conv1 = Convolution2D(conv[0], 3, 3, activ, border_mode = 'same')(conv1)
pool1 = MaxPooling2D(pool_size = (2, 2))(conv1)
Tương tự ta sẽ xây dựng các layer thứ 2, 3, 4, 5.
conv2 = Convolution2D(conv[0], 3, 3, activ, border_mode = 'same')(pool1)
conv2 = Dropout(drop_out)(conv2)
conv2 = Convolution2D(conv[0], 3, 3, activ, border_mode = 'same')(conv2)
pool2 = MaxPooling2D(pool_size = (2, 2))(conv2)
conv3 = Convolution2D(conv[0], 3, 3, activ, border_mode = 'same')(pool2)
conv3 = Dropout(drop_out)(conv3)
conv3 = Convolution2D(conv[0], 3, 3, activ, border_mode = 'same')(conv3)
pool3 = MaxPooling2D(pool_size = (2, 2))(conv3)
conv4 = Convolution2D(conv[0], 3, 3, activ, border_mode = 'same')(pool3)
conv4 = Dropout(drop_out)(conv4)
conv4 = Convolution2D(conv[0], 3, 3, activ, border_mode = 'same')(conv4)
poo4 = MaxPooling2D(pool_size = (2, 2))(conv4)
conv5 = Convolution2D(conv[0], 3, 3, activ, border_mode = 'same')(pool4)
conv5 = Dropout(drop_out)(conv5)
conv5 = Convolution2D(conv[0], 3, 3, activ, border_mode = 'same')(conv5)
Như vậy ta đã xây dựng xong phần encoder cho mạng Unet. giờ ta sẽ đi xây dựng phần decoder.
up1 = merge([UpSampling2D(size = (2, 2))(conv5), conv4], mode = 'concat', concat_axis = 1)
conv6 = Convolution2D(conv[3], 3, 3, activ, border_mode = 'same')(up1)
conv6 = Dropout(drop_out)(conv6)
conv6 = Convolution2D(conv[3], 3, 3, activ, border_mode = 'same')(conv6)
Đây là layer đâù tiên (tính từ dưới lên) trong phần decode. Sau phần encode ta được lớp conv5. ở layer đầu tiên này ta sẽ Upsample conv5 lên 2 lần rổi concat với lớp conv4 trước đó. Ta được lớp conv6.
Tương tự với các layer tiếp theo của phần decoder, ta sẽ có
up2 = merge([UpSampling2D(size = (2, 2))(conv6), conv3], mode = 'concat', concat_axis = 1)
conv7 = Convolution2D(conv[3], 3, 3, activ, border_mode = 'same')(up2)
conv7 = Dropout(drop_out)(conv7)
conv7 = Convolution2D(conv[3], 3, 3, activ, border_mode = 'same')(conv7)
up3 = merge([UpSampling2D(size = (2, 2))(conv7), conv2], mode = 'concat', concat_axis = 1)
conv8 = Convolution2D(conv[3], 3, 3, activ, border_mode = 'same')(up3)
conv8 = Dropout(drop_out)(conv8)
conv8 = Convolution2D(conv[3], 3, 3, activ, border_mode = 'same')(conv8)
up4 = merge([UpSampling2D(size = (2, 2))(conv8), conv1], mode = 'concat', concat_axis = 1)
conv9 = Convolution2D(conv[3], 3, 3, activ, border_mode = 'same')(up4)
conv9 = Dropout(drop_out)(conv9)
conv9 = Convolution2D(conv[3], 3, 3, activ, border_mode = 'same')(conv9)
conv10 = Convolution2D(2, 1, 1, activ, border_mode='same')(conv9)
conv11 = core.Activation(core_activation_function)(conv10)
model = Model(input = inputs, output = conv11)
model.compile(optimizer = Adam(lr = learning_rate), loss = loss_function, metrics = [d1])
return model
Đến đây chúng ta đã xây dựng xong 1 mạng Unet đơn giản và có thể cho dữ liệu vào train model Unet.
Thảo luận
Thông thường với các bài toán sử dụng Unet, ta thường sử dụng các mô hình mạng được train sẵn trong phần encoder ví dụ như VGG, Alexnet, Resnet,.... Ta dùng các pre_train model để khởi tạo tham số cho phần encoder. Còn đối với phần decoder ta cũng có thể xây dựng linh hoạt ngoài việc concat đối xứng, ta có thể làm những cách khác nhau như Upsample luôn hoặc add đối xứng các layer lại với nhau.
Tham khảo
https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/
https://pdfs.semanticscholar.org/0704/5f87709d0b7b998794e9fa912c0aba912281.pdf
All rights reserved

Bình luận
Chào bạn. Mình đang tìm hiểu về Variational Auto Encoder. Mình thấy nó khá giống với Unet ko biết bạn có thể phân biệt 2 cái giúp mình được không.
Unet được thiết kế giống như auto-encoder cũng gồm 2 phần encode và decode. Nhưng cái Unet phần decoder của nó còn được kết nối trực tiếp với phần encoder còn VAE thì không. Hơn nữa Unet với mục đích là classification từng pixel trong ảnh input còn VAE sẽ cho output gần giống với input nhất, thường cho các bài toán unsupervised learning.
Vậy là 2 cái chỉ khác nhau ở phần decoder đúng ko bạn. Unet phần decoder sẽ phân loại từng pixel vào các class còn VAE phần decoder sẽ sinh ra những pixel gần giống với input nhất.
dạ chào a ạ, hiện tại e đang làm đồ án về unet steganography, có một vài thắc mắc ạ, mong được a giải đáp. a có thể cho e xin sđt hoặc link fb để tiện trao đổi hơn được không ạ? em cảm ơn ạ
Bạn cho mình hỏi size của input có nhất thiết phải bằng size output trong kiến trúc Unet ko? cám ơn bạn.