Xây dựng Content-based Filtering RS [Recommender System cơ bản - Phần 2]
Bài đăng này đã không được cập nhật trong 5 năm
Tại bài viết trước, chúng ta đã tìm hiểu tổng quan về Recommender System. Tại bài viết này, chúng ta tiếp tục tìm hiểu thuật toán và xây dựng một hệ thống Content-based Recommender System đơn giản với bộ dữ liệu Movilens.
Thuật toán
Đối với phương pháp content-based, hệ thống sẽ đánh giá các đặc tính của items được recommended. Nó sẽ gợi ý các item dựa trên hồ sơ (profiles) của người dùng hoặc dựa vào nội dung, thuộc tính (attributes) của những item tương tự như item mà người dùng đã chọn trong quá khứ.
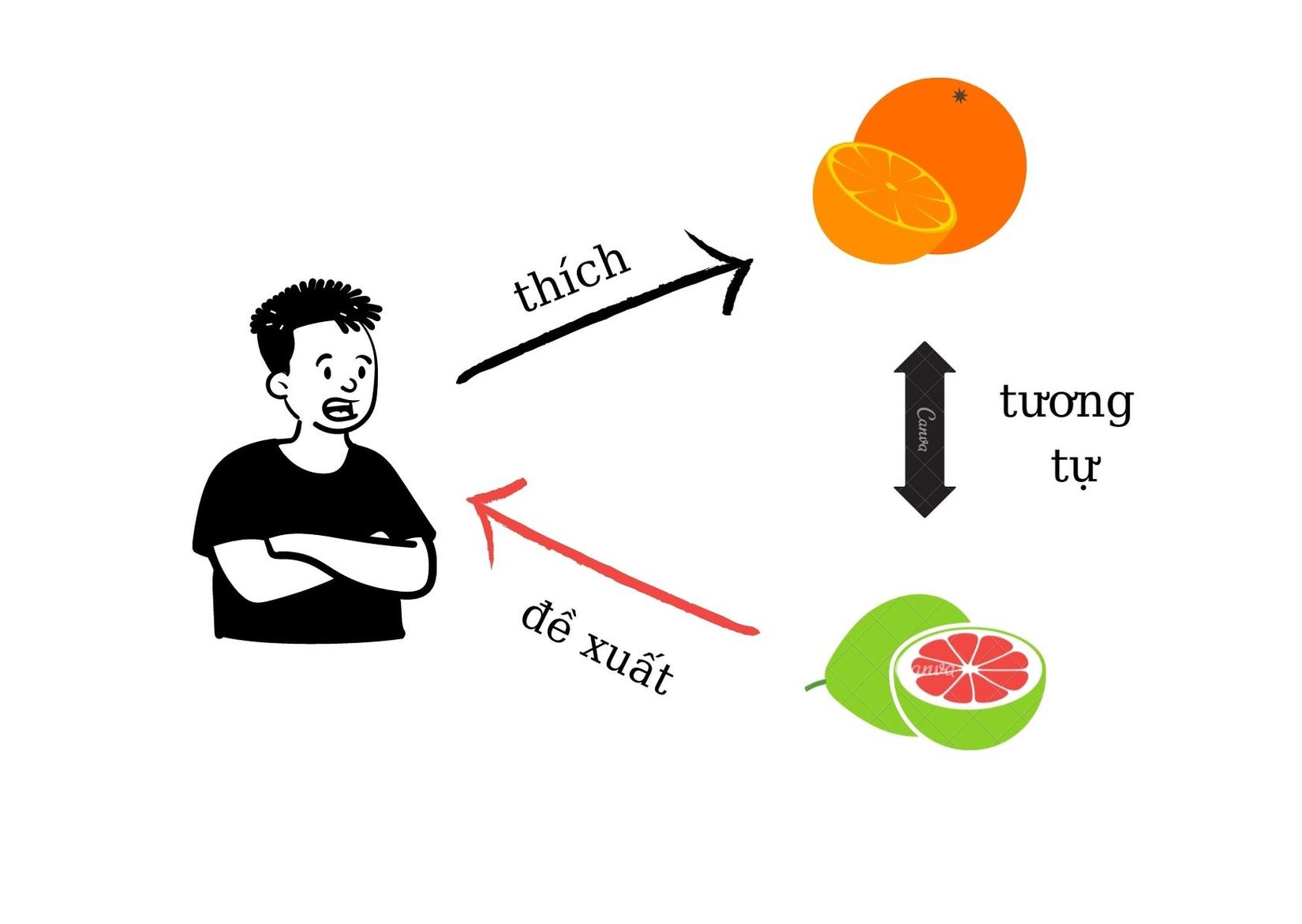
Ví dụ: một người rất thích ăn cam, vậy thì hệ thống gợi ý một loại trái cây tương tự với cam, ở đây là bưởi để đề xuất. Cách tiếp cận này yêu cầu việc sắp xếp các items vào từng nhóm hoặc đi tìm các đặc trưng của từng item.
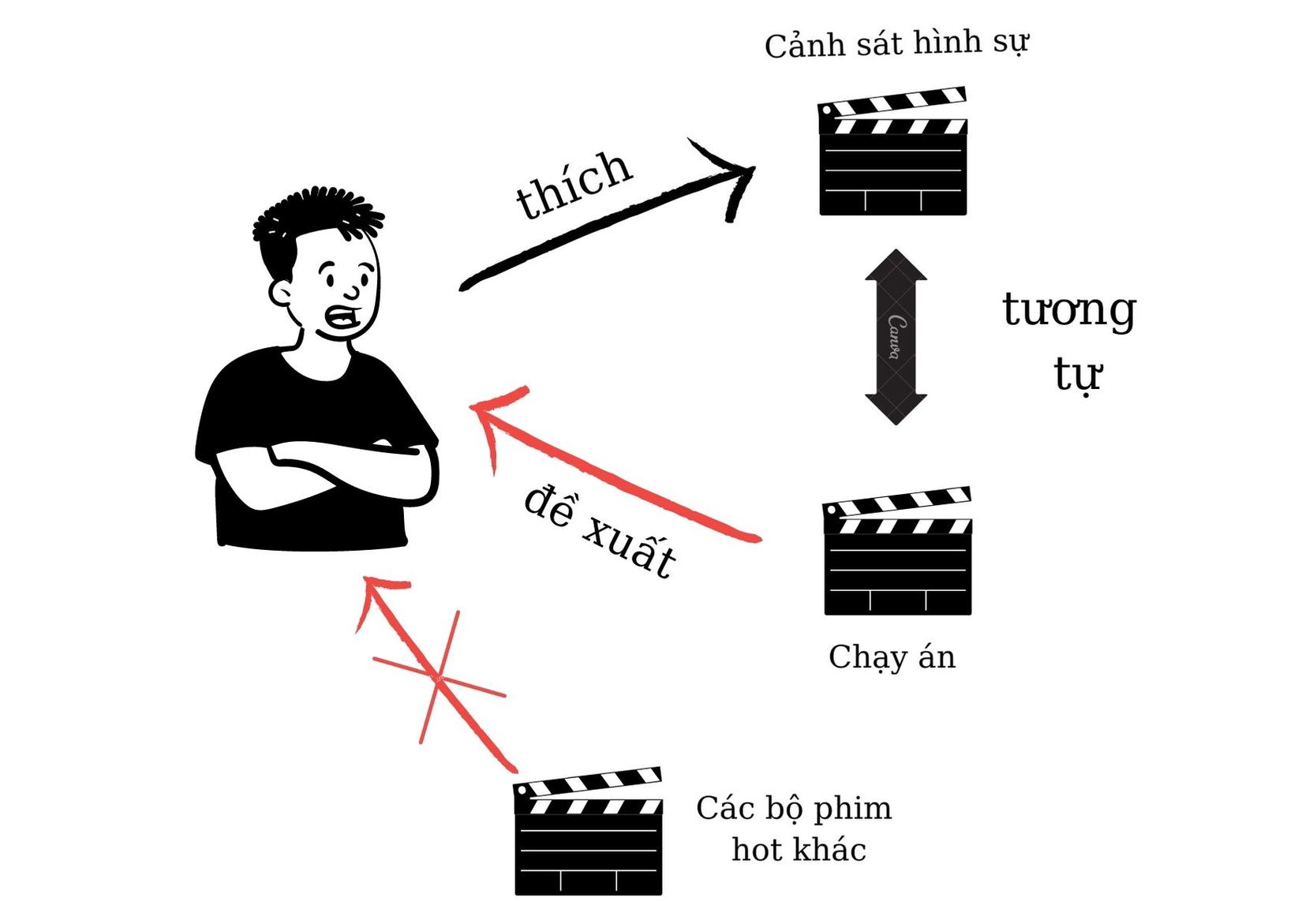
Một ví dụ khác, khi người dùng xem phim Cảnh sát hình sự, hệ thống sẽ đề xuất phim Chạy án, cùng thuộc thể loại hình sự với bộ phim người dùng thích. Chính vì vậy, hệ thống chỉ cần biết người dùng xem phim nào chứ không cần dữ liệu về ratings, giúp nó hoạt động ngay cả khi người dùng không có thói quen đánh giá phim. Và tất nhiên nó chỉ đề xuất các bộ phim có tính chất tương tự mà không đề xuất đa dạng phim hay các bộ phim được cộng đồng xem phim đánh giá cao.
Thiết kế
1. Khởi tạo dữ liệu
Chúng ta sử dụng dữ liệu của Movilens, cụ thể là file movies.csv: chứa thông tin về bộ phim (id phim, tên phim, thể loại). Một phim có thể có nhiều thể loại được ngăn cách bởi “|” hoặc không thuộc thể loại loại nào. Sử dụng module read_csv của Pandas để đọc file và lưu thành dataframe.
import pandas
from pandas import read_csv
def get_dataframe_movies_csv(text):
"""
đọc file csv của movilens, lưu thành dataframe với 3 cột user id, title, genres
"""
movie_cols = ['movie_id', 'title', 'genres']
movies = pandas.read_csv(text, sep=',', names=movie_cols, encoding='latin-1')
return movies
2. Thiết lập ma trận TF - IDF
− Mỗi item làm 1 bộ phim − Dựa trên thể loại của mỗi item, chúng ta cần xây dựng một bộ hồ sơ (profile) cho mỗi item. Profile này được biểu diễn dưới dạng toán học là một feature vector. Trong những trường hợp đơn giản, feature vector được trực tiếp trích xuất từ item:
- Lọc ra các thể loại film:
- Xây dựng ma trận với với số dòng tương ứng với số lượng film và số cột tương ứng với số từ được tách ra từ "genres"
- Xây dựng feature vector cho mỗi item dựa trên ma trận thể loại phim và feature TF-IDF
- Về bản chất, TF - IDF là một thước đo thống kê đánh giá mức độ liên quan của một từ với một tài liệu trong bộ sưu tập tài liệu. Điều này được thực hiện bằng cách nhân hai số liệu: số lần một từ xuất hiện trong tài liệu và nghịch đảo tần suất tài liệu của từ trên một tập hợp tài liệu (hiểu đơn giản thì điểm TF-IDF là tần suất xuất hiện của một từ trong một tài liệu)
− Sử dụng Class TfIdfVectorizer tạo ra ma trận TF - IDF:
- Nhập module Tfidf bằng scikit-learning.
- Thay thế các giá trị not-a-number bằng một chuỗi trống
from sklearn.metrics.pairwise import linear_kernel
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas
from pandas import isnull, notnull
def tfidf_matrix(movies):
"""
Dùng hàm "TfidfVectorizer" để chuẩn hóa "genres" với:
+ analyzer='word': chọn đơn vị trích xuất là word
+ ngram_range=(1, 1): mỗi lần trích xuất 1 word
+ min_df=0: tỉ lệ word không đọc được là 0
Lúc này ma trận trả về với số dòng tương ứng với số lượng film và số cột tương ứng với số từ được tách ra từ "genres"
"""
tf = TfidfVectorizer(analyzer='word', ngram_range=(1, 1), min_df=0)
new_tfidf_matrix = tf.fit_transform(movies['genres'])
return new_tfidf_matrix
3. Tính độ tương đồng giữa các item
− Tiếp theo, ta sử dụng độ tương tự cosine để tính toán một đại lượng số biểu thị sự giống nhau giữa hai phim. Chọn điểm tương tự cosine vì nó không phụ thuộc vào độ lớn và tương đối dễ dàng để tính toán (đặc biệt khi được sử dụng kết hợp với điểm TF - IDF).
def cosine_sim(matrix):
"""
Dùng hàm "linear_kernel" để tạo thành ma trận hình vuông với số hàng và số cột là số lượng film
để tính toán điểm tương đồng giữa từng bộ phim với nhau
"""
new_cosine_sim = linear_kernel(matrix, matrix)
return new_cosine_sim
− Chúng tôi sử dụng module linear_kernel () của sklearn thay vì cosine_similities () tốc độ xử lý của linear_kernal nhanh hơn. Kết quả thu được của chúng tôi là ma trận có hình dạng 9743x9743, có nghĩa là điểm tương đồng của mỗi tổng quan về cosine của mỗi bộ phim với mọi tổng quan của bộ phim khác. Do đó, mỗi bộ phim sẽ là một vectơ cột 1x9743 trong đó mỗi cột sẽ là một điểm tương đồng với mỗi bộ phim.
import pandas as pd
import function_package.content_base_function
class CB(object):
"""
Khởi tại dataframe "movies" với hàm "get_dataframe_movies_csv"
"""
def __init__(self, movies_csv):
self.movies = function_package.read_data_function.get_dataframe_movies_csv(movies_csv)
self.tfidf_matrix = None
self.cosine_sim = None
def build_model(self):
"""
Tách các giá trị của genres ở từng bộ phim đang được ngăn cách bởi '|'
"""
self.movies['genres'] = self.movies['genres'].str.split('|')
self.movies['genres'] = self.movies['genres'].fillna("").astype('str')
self.tfidf_matrix = function_package.content_base_function.tfidf_matrix(self.movies)
self.cosine_sim = function_package.content_base_function.cosine_sim(self.tfidf_matrix)
def refresh(self):
"""
Chuẩn hóa dữ liệu và tính toán lại ma trận
"""
self.build_model()
def fit(self):
self.refresh()
4. Kết quả
Sau khi đã có ma trận điểm tương đồng của các bộ phim, chúng tôi lấy ra được top bộ phim có điểm tương đồng cao nhất so với bộ phim được so sánh với các bước: − Lấy chỉ mục của bộ phim với tiêu đề của nó. − Nhận danh sách điểm tương đồng cosine của phim cụ thể đó với các bộ phim. − Sắp xếp danh sách các bộ giá trị nói trên dựa trên điểm số tương tự − Trả về các tiêu đề tương ứng với chỉ số của các phần tử trên cùng.
# Hàm này ở trong class CB
def genre_recommendations(self, title, top_x):
"""
Xây dựng hàm trả về danh sách top film tương đồng theo tên film truyền vào:
+ Tham số truyền vào gồm "title" là tên film và "topX" là top film tương đồng cần lấy
+ Tạo ra list "sim_score" là danh sách điểm tương đồng với film truyền vào
+ Sắp xếp điểm tương đồng từ cao đến thấp
+ Trả về top danh sách tương đồng cao nhất theo giá trị "topX" truyền vào
"""
titles = self.movies['title']
indices = pd.Series(self.movies.index, index=self.movies['title'])
idx = indices[title]
sim_scores = list(enumerate(self.cosine_sim[idx]))
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
sim_scores = sim_scores[1:top_x + 1]
movie_indices = [i[0] for i in sim_scores]
return sim_scores, titles.iloc[movie_indices].values
Vậy là chúng ta đã tìm hiểu và xây dựng xong một hệ thống Content-based Recommender System cơ bản vs Python và bộ dữ liệu Movilens. Và như chúng ta đã biết, hệ thống content-based chỉ đề xuất các bộ phim/item có tính chất tương tự mà không đề xuất đa dạng phi/item hay các bộ phim/item được những người khác đánh giá cao. Bên cạnh đó, contented-based Recommender System trên có hai nhược điểm:
- Thứ nhất, khi xây dựng mô hình cho một user, các hệ thống Content-based không tận dụng được thông tin từ các users khác. Những thông tin này thường rất hữu ích vì hành vi mua hàng của các users thường được nhóm thành một vài nhóm đơn giản; nếu biết hành vi mua hàng của một vài users trong nhóm, hệ thống nên suy luận ra hành vi của những users còn lại.
- Thứ hai, không phải lúc nào chúng ta cũng có bản mô tả cho mỗi item. Việc yêu cầu users gắn tags còn khó khăn hơn vì không phải ai cũng sẵn sàng làm việc đó; hoặc có làm nhưng sẽ mang xu hướng cá nhân. Các thuật toán NLP cũng phức tạp hơn ở việc phải xử lý các từ gần nghĩa, viết tắt, sai chính tả, hoặc được viết ở các ngôn ngữ khác nhau.
Những nhược điểm phía trên có thể được giải quyết bằng Collaborative Filtering Recommender System. Chúng ta sẽ cùng tìm hiểu về nó ở bài viết sau.
All rights reserved
