Xây dựng một hệ thống gợi ý phim đơn giản với Python
Bài đăng này đã không được cập nhật trong 7 năm
Trong bài viết này mình sẽ giới thiệu hệ thống gợi ý (Recommender System) đơn giản. Và sau đó chúng ta sẽ xây dựng một hệ thống gợi ý đơn giản với Python. Hệ thống bạn xây dựng được trong bài này không phải là cách người ta xây dựng hệ thống tương tự ở các công ty mà chỉ là một bài giới thiệu và cái nhìn chung về hệ thống gợi ý. Với bài viết này mình yêu cầu bạn phải có kiến thức làm việc với machine learning thông qua các thư viện trong Python như Pandas và Numpy.
Hệ thống gợi ý là gì?
Hệ thống gợi ý là một thuận toán đơn giản mà ở đó nó phục vụ cho mục đích cung cấp thông tin liên quan đến một người dùng cụ thể dựa mô hình khám phá trên một tập dữ liệu. Thuật toán này đánh giá các sản phẩm và hiện thị cho người dùng rằng là sản phẩm nào được đánh giá (liên quan) cao nhất. Một ví dụ của hệ thống gợi ý được áp dụng trong thực tế đó là khi bạn truy cập trang web Amazon và bạn nhận ra rằng một số sản phẩm sẽ được gợi ý cho bạn hoặc là khi bạn truy cập web Netfix sẽ gợi ý một số bộ phim nhất định cho bạn. Các hệ thống này còn được dùng trong lĩnh vực nghe nhạc trực tuyến ví dụ như Spotify and Deezer, ở đó chúng có nhiệm vụ gợi ý các bài nhạc mà bạn có thể thích.
Dưới đây là một mô tả đơn giản về cách hoạt động của hệ thống gợi ý khi được áp dụng các các trang web thương mại điện tử (e-commerce).
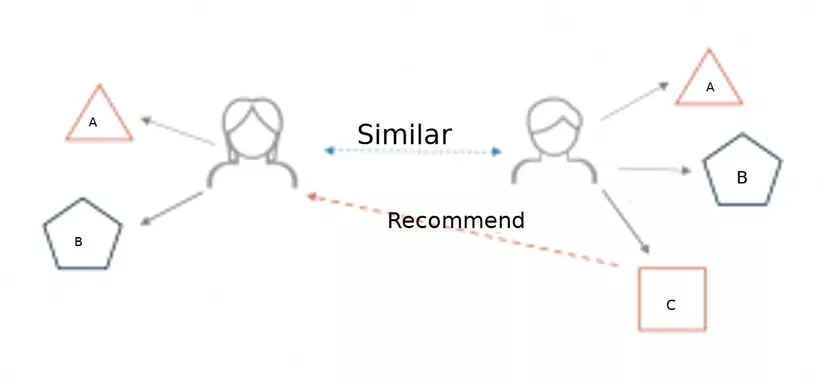
Hai người dùng mua chung sản phẩm A và B từ một website thương mại điện tử. Khi điều đó xảy ra thì chỉ số tương tự (similarity index) của 2 người dùng này sẽ được tính toán. Dựa theo điểm số tính toán từ hệ thống mà có thể gợi ý sản phẩm C đến với người dùng khác khi mua hàng, bởi vì hệ thống phát hiện ra rằng 2 người dùng đó có sự giống nhau về mặt hàng họ mua.
Phân loại các hệ thống gợi ý
Các loại hệ thống gợi ý phố biến nhất là đề xuất dựa theo content based (đề xuất dựa theo nội dung) và collaborative filtering (đề xuất dựa theo sự tương đồng). với collaborative filtering , hành vi của một nhóm người dùng được sử dụng để đưa ra khuyến nghị cho những người dùng khác. Khuyến nghị dựa trên sở thích của người dùng khác. Một ví dụ đơn giản sẽ giới thiệu phim cho người dùng dựa trên thực tế là bạn của họ thích phim. Có hai loại mô hình collaborative đó là Memory-based và Model-based. Ưu điểm của kỹ thuật dựa trên bộ nhớ là đơn giản để thực hiện và các khuyến nghị kết quả thường dễ giải thích. Chúng được chia thành hai:
- User-based collaborative filtering : Trong mô hình này, các sản phẩm được khuyến nghị cho người dùng dựa trên thực tế là các sản phẩm đã được người dùng yêu thích tương tự như người dùng. Ví dụ: nếu Derrick và Dennis thích những bộ phim giống nhau và một bộ phim mới ra mắt mà Derick thích, thì chúng tôi có thể giới thiệu bộ phim đó cho Dennis vì Derrick và Dennis có vẻ thích những bộ phim tương tự.
- Item-based collaborative filtering : Các hệ thống này xác định các mục tương tự dựa trên xếp hạng trước đây của người dùng. Ví dụ: nếu người dùng A, B và C xếp hạng 5 sao cho sách X và Y thì khi người dùng D mua sách Y, họ cũng nhận được đề xuất mua sách X vì hệ thống xác định sách X và Y giống nhau dựa trên xếp hạng của người dùng A, B và C
Các phương pháp Model-based dựa trên yếu tố ma trận (matrix factorizatio) và tốt hơn trong việc xử lý sự thưa thớt. Chúng được phát triển bằng cách sử dụng khai thác dữ liệu (data mining), thuật toán học máy (machine learning) để dự đoán xếp hạng của người dùng đối với các mục chưa được đánh giá. Trong phương pháp này, các kỹ thuật như giảm kích thước được sử dụng để cải thiện độ chính xác. Ví dụ về các phương Model-based như vậy bao gồm cây quyết định (decision trees), mô hình dựa trên quy tắc (rule based models), phương pháp Bayes và mô hình nhân tố tiềm ẩn (latent factor models).
Các hệ thống Content based sử dụng tập dữ liệu chứ nhiều thông tin như thể loại (genre), nhà sản xuất (producer), diễn viên (actor), nhạc sĩ (musician) để đề xuất các mục nói phim hoặc nhạc. Một đề xuất như vậy sẽ là ví dụ khuyến nghị Infinity War có sự góp mặt của Vin Disiel vì ai đó đã xem và thích The Fate of the Furious. Tương tự như vậy, bạn có thể nhận được đề xuất âm nhạc từ các nghệ sĩ nhất định vì bạn thích âm nhạc của họ. Các hệ thống content based dựa trên ý tưởng rằng nếu bạn thích một mặt hàng nào đó, bạn rất có thể thích một thứ tương tự như nó.
Bộ dữ liệu dùng để xây dựng hệ thống gợi ý
Trong hướng dẫn này, chúng tôi sẽ sử dụng Bộ dữ liệu MovieLes. Bộ dữ liệu này được tập hợp bởi nhóm nghiên cứu Grouplens tại Đại học Minnesota. Nó chứa 1, 10 và 20 triệu xếp hạng. Movielens cũng có một trang web nơi bạn có thể đăng ký, đóng góp đánh giá và nhận đề xuất phim. Bạn có thể tìm thêm bộ dữ liệu cho các nhiệm vụ khoa học dữ liệu khác nhau từ bộ dữ liệu.
Các bước để xây dựng hệ thống gợi ý
Chúng tôi sẽ sử dụng các Movielens để xây dựng một hệ thống đề xuất dựa trên vật phẩm tương tự đơn giản. Điều đầu tiên chúng ta cần làm là chèn 2 thư viện pandas và numpy.
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
Tiếp theo, chúng tôi sử dụng tập dữ liệu bằng lệnh pandas read_csv (). Tập dữ liệu được phân tách bằng tab để chúng tôi chuyển vào \ t cho tham số sep. Sau đó chúng ta chuyển vào tên cột bằng tên tham số.
df = pd.read_csv('u.data', sep='\t', names=
['user_id','item_id','rating','titmestamp'])
Bây giờ, hãy để kiểm tra phần đầu của dữ liệu để xem dữ liệu chúng ta đang xử lý.
df.head()
Sẽ thật tuyệt nếu chúng ta có thể xem các tiêu đề của bộ phim thay vì các thông tin liên quan đến các ID. Hãy tải xuống trong các tựa phim và hợp nhất nó với bộ dữ liệu này.
movie_titles = pd.read_csv('Movie_Titles')
movie_titles.head()
Vì các cột item_id giống nhau, chúng tôi có thể hợp nhất các bộ dữ liệu này trên cột này.
df = pd.merge(df, movie_titles, on='item_id')
df.head()
Hãy xem mỗi cột thể hiện điều gì:
- user_id - Cột ID của người dùng đã đánh giá bộ phim.
- item_id - Cột ID of bộ phim.
- rating - Xếp hạng người dùng đã cho bộ phim, từ 1 đến 5.
- timestamp - Thời gian bộ phim được đánh giá.
- title - Tiêu đề của bộ phim.
Sử dụng các lệnh describe hoặc info, chúng tôi có thể nhận được một mô tả ngắn gọn về tập dữ liệu của chúng tôi. Điều này rất quan trọng để cho phép chúng tôi hiểu bộ dữ liệu mà chúng tôi đang làm việc.
df.describe()
Chúng ta có thể nói rằng xếp hạng trung bình là 3,52 và tối đa là 5. Chúng ta cũng thấy rằng tập dữ liệu có 100003 hồ sơ.
Let’s now create a dataframe with the average rating for each movie and the number of ratings. We are going to use these ratings to calculate the correlation between the movies later. Correlation is a statistical measure that indicates the extent to which two or more variables fluctuate together. Movies that have a high correlation coefficient are the movies that are most similar to each other. In our case we shall use the Pearson correlation coefficient. This number will lie between -1 and 1. 1 indicates a positive linear correlation while -1 indicates a negative correlation. 0 indicates no linear correlation. Therefore movies with a zero correlation are not similar at all. In order to create this dataframe we use pandas groupby functionality. We group the dataset by the title column and compute its mean to obtain the average rating for each movie.
Bây giờ, hãy tạo một khung dữ liệu với xếp hạng trung bình cho mỗi phim và số lượng xếp hạng. Chúng tôi sẽ sử dụng các xếp hạng này để tính toán mối tương quan giữa các bộ phim sau này. Tương quan là một thước đo thống kê chỉ ra mức độ mà hai hoặc nhiều biến số dao động cùng nhau. Những bộ phim có hệ số tương quan cao là những bộ phim giống nhau nhất. Trong trường hợp của chúng tôi, chúng tôi sẽ sử dụng hệ số tương quan Pearson. Con số này sẽ nằm giữa -1 và 1. 1 cho thấy mối tương quan tuyến tính dương trong khi -1 chỉ ra mối tương quan âm. 0 chỉ ra không có tương quan tuyến tính. Do đó, những bộ phim có tương quan bằng 0 hoàn toàn không giống nhau. Để tạo khung dữ liệu này, chúng tôi sử dụng chức năng groupby của pandas. Chúng tôi nhóm dữ liệu theo cột title và tính toán giá trị trung bình của nó để có được xếp hạng trung bình cho mỗi phim.
ratings = pd.DataFrame(df.groupby('title')['rating'].mean())
ratings.head()
Tiếp theo chúng tôi muốn xem số lượng xếp hạng cho mỗi bộ phim. Chúng tôi làm điều này bằng cách tạo một cột number_of_ratings. Điều này rất quan trọng để chúng ta có thể thấy mối quan hệ giữa xếp hạng trung bình của phim và số xếp hạng mà phim đạt được. Rất có thể một bộ phim 5 sao được đánh giá chỉ bởi một người. Do đó, không chính xác về mặt thống kê để phân loại phim có phim 5 sao. Do đó, chúng tôi sẽ cần đặt ngưỡng cho số lượng xếp hạng tối thiểu khi chúng tôi xây dựng hệ thống đề xuất. Để tạo cột mới này, chúng tôi sử dụng tiện ích groupby của pandas. Chúng tôi nhóm theo cột title và sau đó sử dụng phương thức count để tính số lượng xếp hạng mỗi phim nhận được. Sau đó, chúng tôi xem khung dữ liệu mới bằng cách sử dụng hàm head().
ratings['number_of_ratings'] = df.groupby('title')['rating'].count()
ratings.head()
Bây giờ, hãy vẽ biểu đồ biểu đồ bằng cách sử dụng chức năng vẽ biểu đồ của gấu trúc để trực quan hóa việc phân phối xếp hạng
import matplotlib.pyplot as plt
%matplotlib inline
ratings['rating'].hist(bins=50)
Chúng ta có thể thấy rằng hầu hết các bộ phim được xếp hạng từ 2,5 đến 4. Tiếp theo, hãy để trực quan hóa hình ảnh cột number_of_ratings theo cách tương tự.
ratings['number_of_ratings'].hist(bins=60)
Từ biểu đồ trên, rõ ràng hầu hết các bộ phim đều có ít xếp hạng. Những bộ phim có hầu hết xếp hạng là những bộ phim nổi tiếng nhất.
Bây giờ, hãy kiểm tra mối quan hệ giữa xếp hạng của một bộ phim và số lượng xếp hạng. Chúng tôi làm điều này bằng cách vẽ một âm mưu phân tán bằng cách sử dụng seaborn. Seaborn cho phép chúng ta thực hiện điều này bằng cách sử dụng hàm joinplot().
import seaborn as sns
sns.jointplot(x='rating', y='number_of_ratings', data=ratings)
Từ sơ đồ, chúng ta có thể thấy rằng họ là một mối quan hệ tích cực giữa xếp hạng trung bình của một bộ phim và số lượng xếp hạng. Biểu đồ biểu thị rằng càng nhiều xếp hạng phim càng được xếp hạng trung bình cao hơn. Điều này rất quan trọng cần lưu ý đặc biệt là khi chọn ngưỡng cho số lượng xếp hạng trên mỗi phim.
Bây giờ chúng ta hãy tiến lên nhanh chóng và tạo ra một hệ thống đề xuất dựa trên vật phẩm đơn giản. Để thực hiện điều này, chúng tôi cần chuyển đổi tập dữ liệu của chúng tôi thành ma trận với các tiêu đề phim là các cột, user_id làm chỉ mục và xếp hạng làm giá trị. Bằng cách này, chúng ta sẽ có được một khung dữ liệu với các cột là tiêu đề phim và các hàng dưới dạng id người dùng. Mỗi cột đại diện cho tất cả các xếp hạng của một bộ phim bởi tất cả người dùng. Xếp hạng xuất hiện dưới dạng NAN nơi người dùng không đánh giá một bộ phim nhất định. Chúng ta sẽ sử dụng ma trận này để tính toán mối tương quan giữa xếp hạng của một bộ phim và phần còn lại của các bộ phim trong ma trận. Chúng tôi sử dụng tiện ích gấu trúc p pivot_table để tạo ma trận phim.
movie_matrix = df.pivot_table(index='user_id', columns='title', values='rating')
movie_matrix.head()
Tiếp theo, hãy cùng xem các bộ phim được đánh giá cao nhất và chọn hai trong số chúng để hợp tác trong hệ thống đề xuất đơn giản này. Chúng tôi sử dụng tiện ích pandas sort_values và đặt tăng dần thành false để sắp xếp các bộ phim từ mức được đánh giá cao nhất. Sau đó, chúng tôi sử dụng hàm head() để xem top 10.
ratings.sort_values('number_of_ratings', ascending=False).head(10)
Hãy giả sử rằng một người dùng đã xem Air Force One (1997) và Contact (1997). Chúng tôi muốn giới thiệu phim cho người dùng này dựa trên lịch sử xem này. Mục tiêu là tìm kiếm những bộ phim tương tự như Liên hệ (1997) và Air Force One (1997 mà chúng tôi sẽ giới thiệu cho người dùng này. Chúng tôi có thể đạt được điều này bằng cách tính toán mối tương quan giữa xếp hạng của hai phim này và xếp hạng của phần còn lại của Các bộ phim trong tập dữ liệu. Bước đầu tiên là tạo một khung dữ liệu với xếp hạng của những bộ phim này từ movie_matrix của chúng tôi.
AFO_user_rating = movie_matrix['Air Force One (1997)']
contact_user_rating = movie_matrix['Contact (1997)']
Bây giờ chúng ta có các tệp dữ liệu hiển thị user_id và xếp hạng họ đã cho hai phim. Hãy xem chúng dưới đây.
AFO_user_rating.head()
contact_user_rating.head()
Để tính toán mối tương quan giữa hai datafram, chúng tôi sử dụng hàm corwith của pandas. Corrwith tính toán mối tương quan theo cặp của các hàng hoặc cột của hai đối tượng khung dữ liệu. Chúng ta hãy sử dụng chức năng này để có được mối tương quan giữa xếp hạng của từng bộ phim và xếp hạng của bộ phim Air Force One.
similar_to_air_force_one=movie_matrix.corrwith(AFO_user_rating)
Chúng ta có thể thấy rằng mối tương quan giữa bộ phim Air Force One và Til there Was You (1997) là 0,867. Điều này cho thấy sự tương đồng rất mạnh mẽ giữa hai bộ phim này.
similar_to_air_force_one.head()
Hãy để Lôi di chuyển và tính toán mối tương quan giữa xếp hạng Liên hệ (1997) và phần còn lại của xếp hạng phim. Thủ tục giống như quy trình được sử dụng ở trên.
similar_to_contact = movie_matrix.corrwith(contact_user_rating)
Chúng tôi nhận ra từ tính toán rằng có một mối tương quan rất mạnh (0,904) giữa Liên hệ (1997) và Til there Was You (1997).
similar_to_contact.head()
Như đã lưu ý trước đó, ma trận của chúng tôi có rất nhiều giá trị bị thiếu vì không phải tất cả các bộ phim đều được người dùng đánh giá. Do đó, chúng tôi bỏ các giá trị null đó và chuyển đổi kết quả tương quan thành các tệp dữ liệu để làm cho kết quả trông hấp dẫn hơn.
corr_contact = pd.DataFrame(similar_to_contact, columns=['Correlation'])
corr_contact.dropna(inplace=True)
corr_contact.head()
corr_AFO = pd.DataFrame(similar_to_air_force_one, columns=['correlation'])
corr_AFO.dropna(inplace=True)
corr_AFO.head()
Hai datafram ở trên cho chúng ta thấy những bộ phim tương tự như phim Liên hệ (1997) và Air Force One (1997) tương ứng. Tuy nhiên, chúng tôi có một thách thức ở chỗ một số phim có rất ít xếp hạng và cuối cùng có thể được đề xuất chỉ vì một hoặc hai người cho họ xếp hạng 5 sao. Chúng tôi có thể khắc phục điều này bằng cách đặt ngưỡng cho số lượng xếp hạng. Từ biểu đồ trước đó, chúng tôi đã thấy số lượng xếp hạng giảm mạnh từ 100. Do đó, chúng tôi sẽ đặt đây là ngưỡng, tuy nhiên đây là con số bạn có thể chơi xung quanh cho đến khi bạn có được một lựa chọn phù hợp. Để thực hiện điều này, chúng ta cần nối hai biểu dữ liệu với cột number_of_ratings trong khung bộ dữ liệu ratings.
corr_AFO = corr_AFO.join(ratings['number_of_ratings'])
corr_contact = corr_contact.join(ratings['number_of_ratings'])
corr_AFO .head()
corr_contact.head()
Bây giờ chúng ta sẽ có được những bộ phim giống với Air Force One (1997) bằng cách giới hạn chúng trong những bộ phim có ít nhất 100 đánh giá. Sau đó chúng tôi sắp xếp chúng theo cột correlation và xem 10 đầu tiên.
corr_AFO[corr_AFO['number_of_ratings'] >
100].sort_values(by='correlation', ascending=False).head(10)
Chúng tôi nhận thấy rằng Air Force One (1997) có mối tương quan hoàn hảo với chính nó, điều này không đáng ngạc nhiên. Bộ phim tương tự tiếp theo của Air Force One (1997) là Hunt for Red Oct, The (1990) với tương quan 0,554. Rõ ràng bằng cách thay đổi ngưỡng cho số lượng đánh giá, chúng tôi nhận được kết quả khác với cách thực hiện trước đó. Giới hạn số lượng đánh giá mang lại cho chúng tôi kết quả tốt hơn và chúng tôi có thể tự tin giới thiệu những bộ phim trên cho ai đó đã xem Air Force One (1997).
Bây giờ, hãy để Lừa làm điều tương tự cho phim Liên hệ (1997) và xem những bộ phim có tương quan nhất với nó.
corr_contact[corr_contact['number_of_ratings'] >
100].sort_values(by='Correlation', ascending=False).head(10)
Một lần nữa chúng tôi nhận được kết quả khác nhau. Bộ phim tương tự nhất với Liên hệ (1997) là Philadelphia (1993) với hệ số tương quan là 0,446 với 137 xếp hạng. Vì vậy, nếu ai đó thích Liên hệ (1997), chúng tôi có thể giới thiệu những bộ phim trên cho họ.
Rõ ràng đây là một cách rất đơn giản để xây dựng hệ thống đề xuất và không có nơi nào gần với tiêu chuẩn ngành.
Cách để cải thiện hệ thống gợi ý
Hệ thống này có thể được cải thiện bằng cách xây dựng Memory-Based Collaborative Filtering dựa trên bộ nhớ. Trong trường hợp này, chúng tôi sẽ chia dữ liệu thành tập huấn luyện và tập kiểm tra. Sau đó, chúng tôi sẽ sử dụng các kỹ thuật như độ cosine similarity để tính toán độ tương tự giữa các phim. Một cách khác là xây dựng hệ thống Model-based Collaborative Filtering. Điều này dựa trên yếu tố matrix factorization. Matrix factorization là tốt trong việc đối phó với khả năng mở rộng và thưa thớt hơn so với trước đây. Sau đó, bạn có thể đánh giá mô hình của mình bằng các kỹ thuật như Root Mean Squared Error (RMSE).
All rights reserved
