
U-net : Kiến trúc mạnh mẽ cho Segmentation
Bài đăng này đã không được cập nhật trong 6 năm
1. Segmentation! Segmentation!
Đôi chút về Image Processing trong Deep Learning
Với Deep Learning (hay Neural Network), máy tính ngày càng có khả năng quan sát và xử lí những hình ảnh phức tạp ở nhiều tác vụ khác nhau. Nếu các bạn thắc mắc máy tính khả năng như nào rồi, hãy cùng mình điểm qua một vài tác vụ kinh điển sau đây.
-
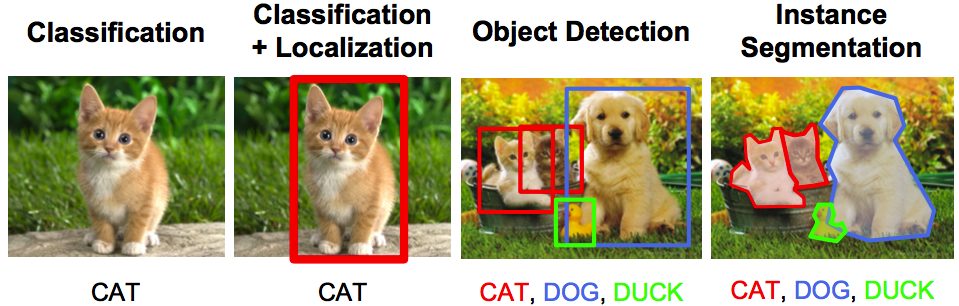
Image Classification
Phân lớp hình ảnh: Tác vụ cơ bản và kinh điển nhất. Ta có thể hiểu đơn giản công việc phân lớp này như sau: Bạn có một tấm ảnh, và bạn có một vài cái hộp. Bạn cần đặt tấm ảnh vào đúng cái hộp chứa các tấm ảnh khác cùng loại với tấm ảnh đó.
Nếu các bạn muốn bắt đầu với Deep Learning, hãy bắt đầu bằng một bài phân loại chữ số viết tay MNIST - bài này được coi như là "Hello world" của Deep Learning
-
Classification + Localization
Nâng level lên 1 chút. Bây giờ máy tính đã biết cách phân loại hình ảnh, vậy nếu ta muốn xác định thêm vị trí của vật thể trong ảnh? (Giả thiết trong ảnh chỉ có một vật thể). Ta có một tác vụ mới và khó hơn: Classification & Localization
-
Image Detection
Vậy nếu trong ảnh không chỉ có một vật thể, ta muốn tìm vị trí của tất cả các vật thể trong ảnh và phân loại nó. Image Detection hay Object Detetion ra đời.
Những kiến trúc được thiết kế riêng cho tác vụ này có thể kể đến như: RCNN, Fast RCNN, Faster RCNN, YOLO, ...
Đây là lẽ lác tác vụ được ứng dụng nhiều nhất mà mình biết, đơn giản là bởi tính "mở" của nó. Một loạt các ứng dụng có thể kể đến như: Nhận diện khuôn mặt để điểm danh, phát hiện biển số xe trong hệ thống quản lí xe, phát hiện các phương tiện vi phạm luật giao thông, theo dõi lưu lượng khách hàng ra vào siêu thị, ...
-
Image Segmentation
Tiếp tục nâng cao hơn (Con người luôn có khát khao chinh phục mà  ). Chúng ta không muốn xác định vật thể chỉ bằng "bounding box" nữa, cần có một lớp viền tốt hơn để bao sát vào vật thể. Tác vụ này được gọi với một cái tên: Segmentation (dịch ra là Phân đoạn hình ảnh thì phải)
). Chúng ta không muốn xác định vật thể chỉ bằng "bounding box" nữa, cần có một lớp viền tốt hơn để bao sát vào vật thể. Tác vụ này được gọi với một cái tên: Segmentation (dịch ra là Phân đoạn hình ảnh thì phải)
Image Segmentation là làm gì?
Mình có nói đến việc segment hình ảnh là tìm một "viền" đủ chính xác để bao sát vào vật thể, vậy điều này thực hiện như thế nào?
Rất đơn giản!
Nếu bạn có thể xác định từng pixel trong ảnh thuộc lớp nào, bạn đã hoàn thành tốt công việc "phân đoạn" rồi đấy
2. Lan man về các kiến trúc deep learning
Trước khi bắt đầu vào phần chính của bài viết này (kiến trúc U-net), có lẽ mình nên lan man một chút bên ngoài về các kiến trúc Deep Learning
Khởi nguyên của Deep Learning
Ngày xửa ngày xưa (là tầm trước năm 1943 sau CN), con người còn chưa biết đến Deep Learning, lúc đó là thời kì toàn thịnh của các cấu trúc thuật toán, các phương pháp xử lí dữ liệu truyền thống được ưa chuộng. Với lượng dữ liệu chưa đủ lớn khi đó, các phương pháp Machine Learning truyền thống đem lại kết quả khá chính xác và hiệu quả. Tuy nhiên, càng về sau, dữ liệu ngày càng bùng nổ, các phương pháp truyền thống tuy có thể sử dụng để phân tích dữ liệu, song hiệu quả ngày càng giảm dần, không thể theo kịp tốc độ phát triển của dữ liệu, cần một giải pháp mới có thể giải quyết được vấn đề này.
Vào 1 ngày đẹp trời, năm 1939, Walter Pitts và Warren McCulloch, sau khi tham khảo cấu trúc của mạng neural trong hệ thần kinh, đã xây dựng một kiến trúc mạng gọi là mạng neural nhằm mô phỏng lại hoạt động của não người trong quá trình học tập
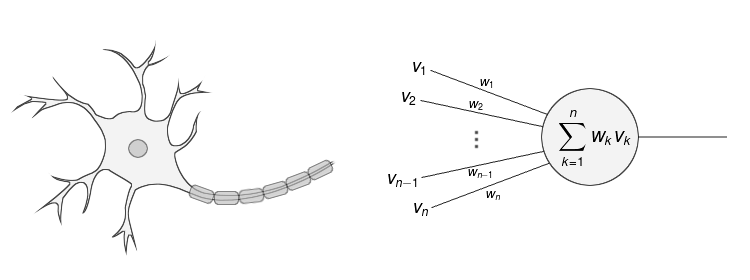
Kiến trúc mới đã tỏ ra khá hiệu quả, và càng về sau càng khẳng định được tầm quan trọng của mình. Đó là lúc cả một hệ thống Deep Learning được hình thành.
Quá trình phát triển và sự ra đời của các kiến trúc khác nhau
Sẽ chẳng có gì cần phải suy nghĩ bởi đơn giản, một kiến trúc mạng neural kết nối đầy đủ (fully connected neural network) có thể giải quyết hầu hết mọi vấn đề (trên lý thuyết là thế).
Tuy nhiên, khi áp dụng mạng neural vào các tác vụ xử lí hình ảnh (image processing), việc xác định trọng số cho từng pixel khiến mạng neural cần xây dựng trở nên lớn hơn bao giờ hết. Điều này khiến việc triển khai mạng neural là không khả thi
Từ suy nghĩ đơn giản: "Những vùng gần nhau trong một hình ảnh thì thường có liên quan đến nhau", năm 1979 Kunihiko Fukushima cho ra đời mạng neural tích chập (Convolution neural network) sử dụng phương pháp "cửa sổ trượt" để trích chọn đặc trưng trong từng vùng ảnh. CNN là kiến trúc mở đầu và nền tảng cho các kiến trúc khác xâm nhập vào thị trường của Computer Vision.
Về phía Nature Language Processing, với một ý nghĩa khá tương tự CNN: "những cụm từ gần nhau thường có liên quan đến nhau", năm 1986, mạng neural hồi quy ra đời (Reccurent Neural Network). Sau đó lần lượt các cấu trúc khác như Long Short Term Memory (LSTM), Word2Vector, ... sinh ra để cải thiện dần kết quả trong lĩnh vực này.
Càng về sau, càng có nhiều kiến trúc phát triển hơn nữa và tạo nên một cộng đồng "Deep Learning" lớn mạnh như hiện nay.
3. Tại sao lại là U-net?
Các cấu trúc nào có thể dùng cho Segment?
Như mình có lan man về Deep Learning, cộng đồng kiến trúc mạng là vô cùng to lớn, do đó, số kiến trúc mạng được nghiên cứu cho tác vụ Segmentation cũng không hề nhỏ. Tuy nhiên, mình sẽ chỉ nêu một số kiến trúc được coi là kinh điển trong lĩnh vực này
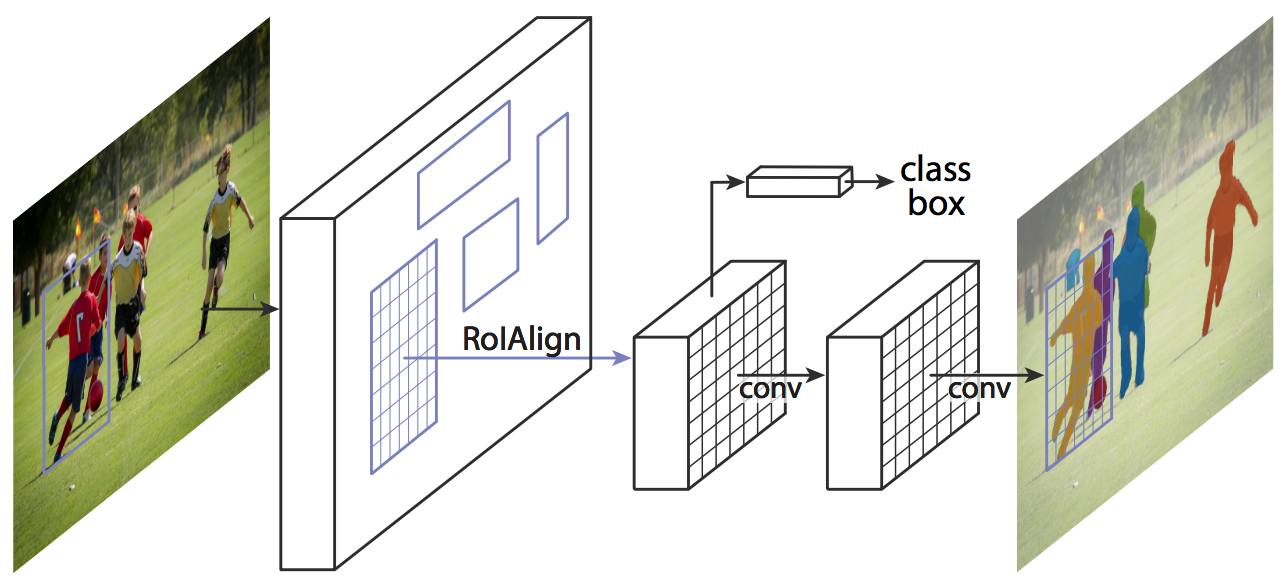
1. Mask RCNN
Mask RCNN là sự kết hợp giữa Faster RCNN và Fully Connected Network (FCN):
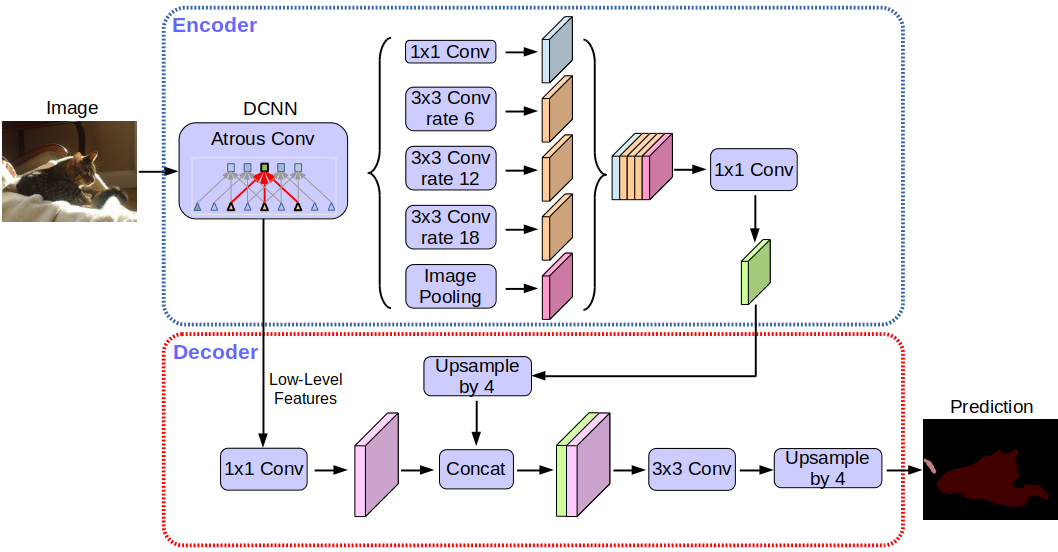
2. Deep Lab
Deep lab v3 sử dụng cấu trúc Encoder-Decoder (nhìn hình):
3. U-net
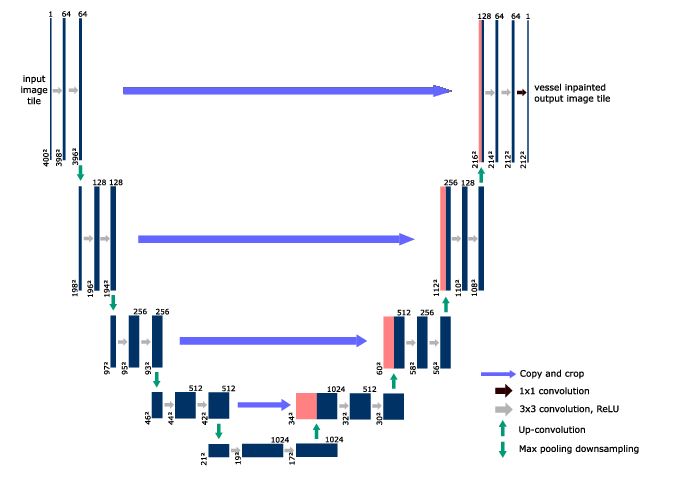
U-net (như tên gọi, có hình chữ U luôn), được thiết kế ban đầu nhằm vào việc segment đối với hình ảnh y tế.
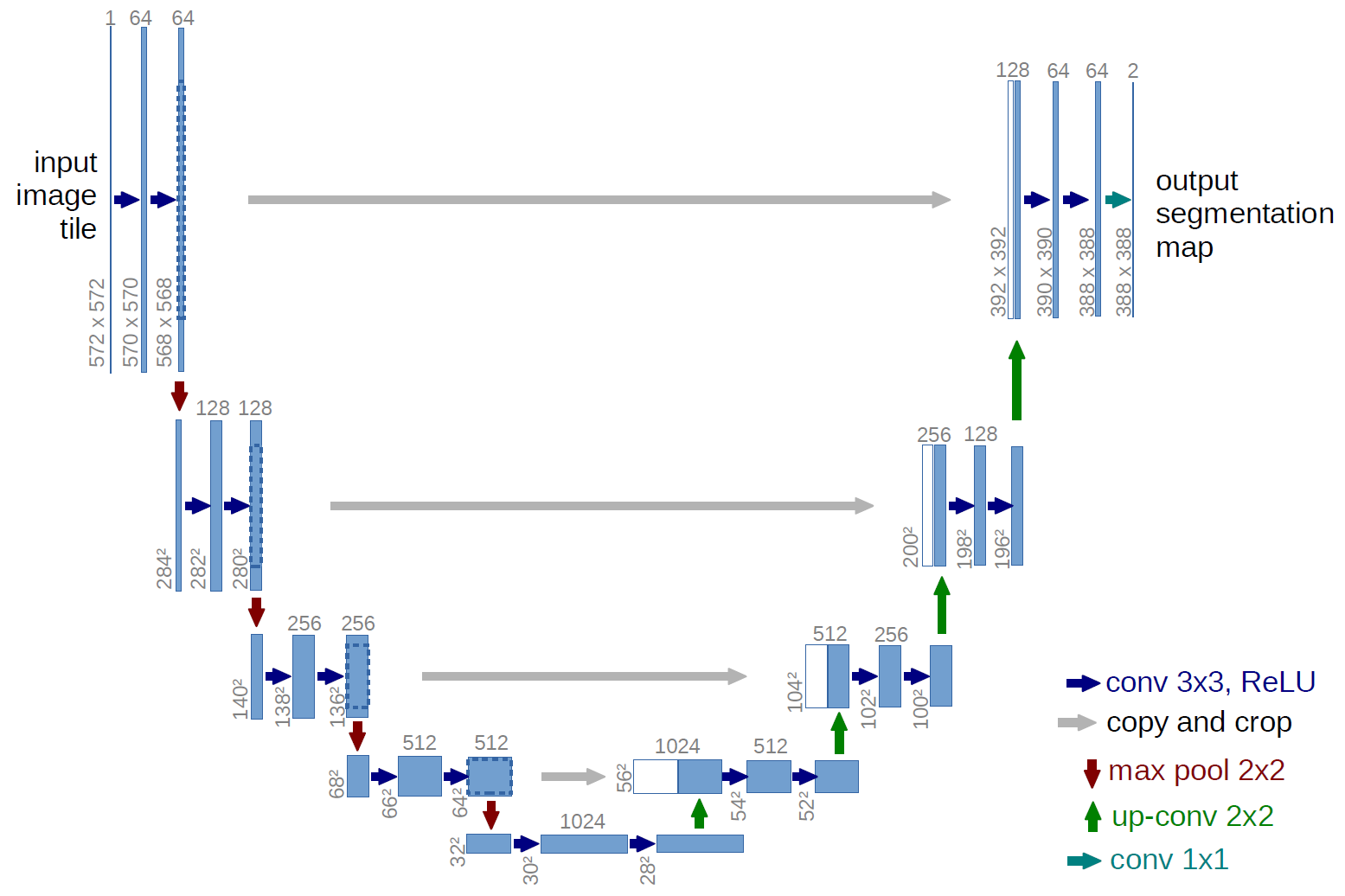
U-net có gì đặc biệt?
Có quá nhiều kiến trúc như vậy, vậy U-net có gì khác biệt so với các kiến trúc khác? Tất nhiên là có rồi
- Thứ nhất, toàn bộ kiến trúc không hề sử dụng một lớp fully connected nào. Nếu các bạn từng làm việc với deep learning, với các mô hình end-to-end thông thường, lớp kế cuối của mạng sẽ là các lớp fully connected để kết nối các đặc trưng đã phân tích được nhằm đưa ra kết quả dự đoán. Tuy nhiên, ở kiến trúc U-net, việc kết nối các đặc trưng sẽ do nửa thứ 2 của "chữ U" đảm nhận, điều này giúp mạng không cần mạng fully connected, do đó có thể chấp nhận input với kích thước bất kì
- Thứ hai: U-net sử dụng Phương pháp đệm (Padding method), điều này giúp kiến trúc có thể phân đoạn hình ảnh được hoàn toàn. Phương pháp này đặc biệt quan trọng khi segment cho các hình ảnh, nếu không, độ phân giải có thể bị hạn chế bởi dung lượng của bộ nhớ GPU.
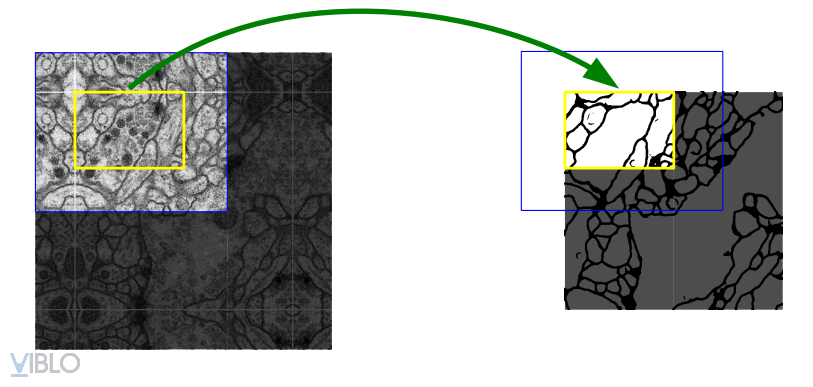
4. Thử một vài thứ hay ho: Segment cho hình ảnh y tế
Đặt vấn đề
Nếu các bạn đã từng phẫu thuật chắc các bạn cũng có thể cảm nhận được cơn đau khi đó và cả những cơn đau kéo dài sau đó (hoặc có thể không - mình cũng chưa phẫu thuật bao giờ nên không biết). Để làm giảm được cơ đau cho bệnh nhân, các bác sĩ thường sử dụng các ống thông giảm đau nhằm ngăn chặn cơn đau tại nguồn. Trong đó, việc xác định chính xác cấu trúc thần kinh trong hình ảnh siêu âm là một bước quan trọng trong việc chèn hiệu quả ống thông cho bệnh nhân. Giả sử bạn không phải là một người có kinh nghiệm trong việc xác định cấu trúc thần kinh, bạn có thể làm gì để giúp các bác sĩ?????
Không làm gì cả! Có thể bạn sẽ làm mọi chuyện tệ hơn. (Just Kidding )
Tuy nhiên, bạn có thể sử dụng U-net, và tiến hành "dạy" máy tính cách xác định các cấu trúc đó.
Cùng thử nào !!!!!
Muốn "dạy" máy tính thì cần có kiến thức, kiến thức ở đây là dataset. Các bạn có thể lấy dataset từ link sau: dataset
Chúng ta sẽ dạy máy tính cách tìm ra những "Đám rối thần kinh cánh tay – Brachial Plexus" từ hình ảnh siêu âm
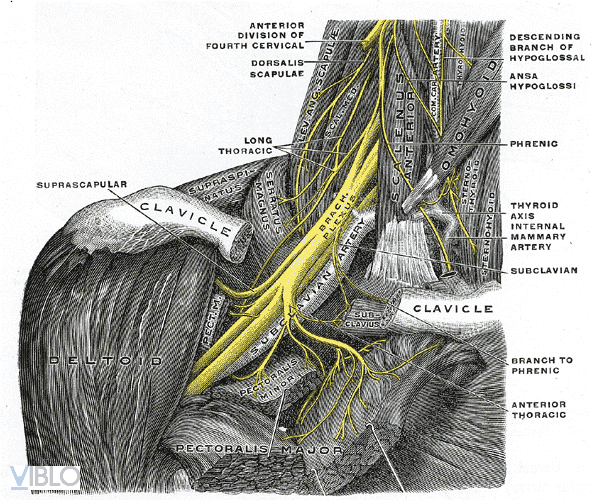
Build Dataset and Preprocess
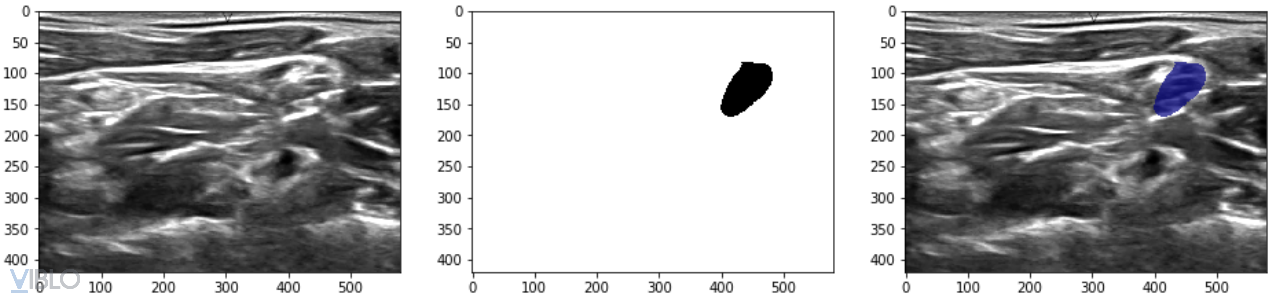
Phía trên là 1 ví dụ về hình ảnh và mask trong dataset
Công việc đầu tiên: Chúng ta tiến hành giải nén tập train, sau đó lần lượt lưu ảnh vào tập imgs_train.npy và lưu mask vào tập imgs_mask_train.npy
Tiếp theo:
- resize lại ảnh về kích thước 64 * 64
- normalize ảnh và mask đưa về khoảng (0, 1)
Build Model
Kiến trúc U-net mình xây dựng được mô tả trong ảnh dưới
Một số chú ý:
Hàm loss được định nghĩa ở đây là hàm Dice_loss (Các bạn có thể tham khảo thêm các hàm loss khác tại đây)
Results
Kết luận
Trong blog này, mình đã trình bày về kiến trúc U-net cũng như tản mạn một chút về một số phần khác. Hi vọng bài viết có thể giúp bạn có một cái nhìn rõ hơn về kiến trúc này cũng như thích thú với các bài toán Segmentation.
Hẹn gặp các bạn ở những blog sau.
All rights reserved
