MongoDB - cơ bản (phần 1)
Bài đăng này đã không được cập nhật trong 4 năm
Một số định nghĩa trước khi đi sâu về MongoDB. Đây là một cross-platform, DB hướng documents với hiệu năng cao, có thể đáp ứng cho đa dạng các hệ thống và dễ dàng để scale. Tư tưởng của MongoDB là thông qua khái niệm collection và document. Vì không tìm được từ tiếng việt hay ho hơn nên tạm thời cho phép mình giữ nguyên các khái niệm tiếng anh của 2 thuật ngữ này.
Database
Database là một container vật lý cho các collection. Mỗi DB được thiết lập cho riêng nó một danh sách các files hệ thống files. Một máy chủ MongoDB đơn thường có nhiều DB.
Collection
Collection là một nhóm các documents của MongoDB. Nó tương đương với một table trong RDBMS. Một Collection tồn tại trong một cơ sở dữ liệu duy nhất. Các collection ko tạo nên một schema. Documents trong collection có thể có các fields khác nhau. Thông thường, tất cả các documents trong collections có mục đích khá giống nhau hoặc liên quan tới nhau

Document
Một document là một tập hợp các cặp key-value. Documents có schema động. Schema động có nghĩa là documents trong cùng một collection không cần phải có cùng một nhóm các fields hay cấu trúc giống nhau, và các fields phổ biến trong các documents của collection có thể chứa các loại dữ liệu khác nhau.
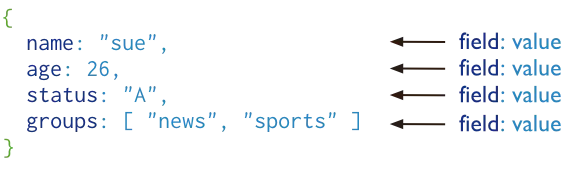
Bảng dưới đây cho thấy mối quan hệ của các thuật ngữ RDBMS với MongoDB
Một số cân nhắc khi thiết kế schema trong MongoDB
-
Thiết kế schema dựa trên yêu cầu của user
-
Kết hợp các object vào một document nếu bạn sử dụng chúng với nhau. Nếu không thì tách riêng hẳn nó ra (nhưng cần phải chú ý là sau này nó sẽ không phải joins).
-
Duplicate dữ liệu (nhưng có giới hạn) vì không gian đĩa là quá rẻ so với tốc độ xử lý.
-
joins khi write, không joins khi read.
-
Tối ưu schema cho hầu hết các case sử dụng thông thường
-
Tập hợp các nhóm phức tạp vào schema
Ví dụ :
Giả sử là một khách hàng cần một thiết kế DB cho blog của anh ta và cân nhắc sự khác biệt schema giữa RDMS và MongoDB. Web sẽ có những yêu cầu sau :
- Mọi post có unique title, description và url.
- Mọi post có thể có 1 hoặc nhiều tags.
- Mọi post có name của publisher và số lượng người xem likes
- Mọi post có comments bới một user với name, message, data-time và likes.
- Mỗi postc có thể có 0 hoặc nhiều comments.
Trong thiết kế schema của RDBMS chúng ta sẽ có như sau về post và comments và tags.
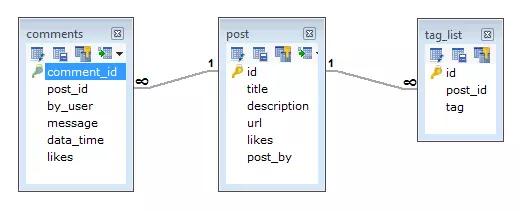
While in MongoDB schema design will have one collection post and has the following structure:
Trong khi đó ở MongoDB schema, chúng ta sẽ có thiết kế một collection post và có cấu trúc như sau :
{
_id: POST_ID
title: TITLE_OF_POST,
description: POST_DESCRIPTION,
by: POST_BY,
url: URL_OF_POST,
tags: [TAG1, TAG2, TAG3],
likes: TOTAL_LIKES,
comments: [
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
},
{
user:'COMMENT_BY',
message: TEXT,
dateCreated: DATE_TIME,
like: LIKES
}
]
}
Để show 1 post RDBMS cần phải join 3 bảng trong khi MongoDB chỉ cần lấy ra từ một collections. Nói đến đây nhiều bạn chú ý đừng thần tượng MongoDB quá nhé. Tháng sau mình sẽ viết 1 bài về so sánh hiệu năng với hàng triệu bản ghi giữa MySQL và NoSQL.
MongoDB - Create/Drop Database
Một số lệnh liên quan đến Database
use DATABASE_NAME
Ví dụ
>use duongdb
switched to db duongdb
Check đang sử dụng DB nào
>db
duongdb
show danh sách các DB trong server.
>show dbs
local 0.78125GB
test 0.23012GB
DB của bạn vừa mới create ko có ở đây. bạn phải insert một documents về nó vào list.
>db.movie.insert({"name":"tutorials point"})
>show dbs
local 0.78125GB
duongdb 0.23012GB
test 0.23012GB
Drop DB
db.dropDatabase()
MongoDB - Create/Drop Collection
Dưới đây là syntax để tạo một Collection
db.createCollection(name, options)
name thì sẽ yêu cầu phải là một string. Trong khi đó mục options thì chứa khá nhiều thông số về : capped, autoIndexID, size , max.
capped là một tập hợp các collection có size fixed và tự động viết đề lên các entries cũ của nó khi chạm đến max size. Nếu bạn cho nó true thì bạn phải điền size với lại max
autoIndexID sẽ tự động tạo một index trên biến _id field.s Mặc định giá trị này là false.
và syntax để drop một collection
db.COLLECTION_NAME.drop()
Ví dụ nhé :
>use test
switched to db test
>db.createCollection("duongcollection")
{ "ok" : 1 }
>show collections
duongcollection
system.indexes
>db.createCollection("mycol", { capped : true, autoIndexID : true, size : 6142800, max : 10000 } )
{ "ok" : 1 }
>
Trong MongoDB thì bạn ko nhất thiết phải tạo collection. Bọn này sẽ tự động tạo collection cho bạn khi bạn insert một documents.
>db.tutorialspoint.insert({"name" : "tutorialspoint"})
>show collections
mycol
mycollection
system.indexes
tutorialspoint
Đây là ví dụ drop
>use mydb
switched to db mydb
>show collections
mycol
mycollection
system.indexes
tutorialspoint
>db.mycollection.drop()
true
Kiểu dữ liệu
- String: String trong MongoDB phải là UTF-8 hợp lệ.
- Integer: Số nguyên có thể là 32 bit hoặc 64 bit tùy thuộc vào máy chủ của bạn.
- Boolean
- Double
- Min/ Max keys: Loại này được sử dụng để so sánh giá trị đối với các yếu tố thấp nhất và cao nhất BSON.
- Array
- Timestamp
- Object
- Null
- Symbol
- Date
- Object ID
- Binary data
- Code
- Regular expression
MongoDB - Document
Insert một Document
>db.COLLECTION_NAME.insert(document)
Ví dụ
>db.mycol.insert({
_id: ObjectId(7df78ad8902c),
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
})
Nếu bạn muốn insert nhiều documents trong một lệnh, bạn cần cho array vào trong lệnh insert().
>db.post.insert([
{
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
title: 'NoSQL Database',
description: 'NoSQL database doesn't have tables',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 20,
comments: [
{
user:'user1',
message: 'My first comment',
dateCreated: new Date(2013,11,10,2,35),
like: 0
}
]
}
])
Lệnh tìm kiếm
>db.COLLECTION_NAME.find()
Để hiện thể kết quả đẹp hơn. Bạn có thể dùng thêm phương thức pretty()
>db.mycol.find().pretty()
{
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
>
Cách sử dụng find AND trong MongoDB
>db.mycol.find({key1:value1, key2:value2}).pretty()
Cách sử dụng find OR trong MongoDB
>db.mycol.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()
Dưới đây là một ví dụ sử dụng cả AND và OR trong MongoDB
>db.mycol.find({"likes": {$gt:10}, $or: [{"by": "tutorials point"},
{"title": "MongoDB Overview"}]}).pretty()
{
"_id": ObjectId(7df78ad8902c),
"title": "MongoDB Overview",
"description": "MongoDB is no sql database",
"by": "tutorials point",
"url": "http://www.tutorialspoint.com",
"tags": ["mongodb", "database", "NoSQL"],
"likes": "100"
}
>
Tiếp đến là lệnh UPDATE
>db.COLLECTION_NAME.update(SELECTIOIN_CRITERIA, UPDATED_DATA)
Giá sử dữ liệu ban đầu của bạn là như thế này
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
Sau khi chạy
>db.mycol.update({'title':'MongoDB Overview'},{$set:{'title':'New MongoDB Tutorial'}})
Bạn sẽ nhận được kết quả như sau
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"New MongoDB Tutorial"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
>
Bạn có thể update nhiều documents bằng cach truyền một param 'multi' cho nó true
>db.mycol.update({'title':'MongoDB Overview'},
{$set:{'title':'New MongoDB Tutorial'}},{multi:true})
Lệnh SAVE
Cú pháp của lệnh này như sau
>db.COLLECTION_NAME.save({_id:ObjectId(),NEW_DATA})
Dưới đây là ví du
>db.mycol.save(
{
"_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview",
"by":"Tutorials Point"
}
)
khi bạn chạy đoạn này phần dữ liệu của documents có ID 5983548781331adf45ec7 sẽ bị thay thế như sau
>db.mycol.find()
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"New MongoDB Tutorial}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point New Topic",
"by":"Tutorials Point"}
>
Lệnh REMOVE
Lệnh này khá đơn giản. Các bạn tự tìm hiểu thêm nhé.
MongoDB - Projection
Trong mongodb, projection có nghĩa là bạn chỉ cần chọn những dữ liệu cần hthieets thay vì select hết mọi dữ liệu của documents. Nó khác find trong find Collection ở chỗ là find thì tìm kiếm dữ liệu document trong collection. Còn khía niệm này sẽ tìm kiếm kết quả fields trong documents. ví dụ bạn cần hiển thị 3 fields kết quả trong 5 fields của một documents.
syntax của lệnh tìm kiếm này sẽ là
>db.COLLECTION_NAME.find({},{KEY:1})
Ví dụ dữ liệu hiện tại của bạn như sau :
{ "_id" : ObjectId(5983548781331adf45ec5), "title":"MongoDB Overview"}
{ "_id" : ObjectId(5983548781331adf45ec6), "title":"NoSQL Overview"}
{ "_id" : ObjectId(5983548781331adf45ec7), "title":"Tutorials Point Overview"}
Bạn chỉ cần muốn hiển thị mỗi title thôi. Hãy làm như sau
>db.mycol.find({},{"title":1,_id:0})
{"title":"MongoDB Overview"}
{"title":"NoSQL Overview"}
{"title":"Tutorials Point Overview"}
>
Rất đơn giản phải ko !
MongoDB - Limit Records
Để giới hạn số lượng records trong MongoDB, bạn sẽ dùng phương thức limit(). Limit() sẽ chấp nhận số lượng record giới hạn thông qua argument mà bạn truyền vào. Nó sẽ thể hiện số lượng documents bạn muốn hiển thị.
>db.COLLECTION_NAME.find().limit(NUMBER)
Sử dụng ví dụ ở Projection ở trên chúng ta có ví dụ sau
>db.mycol.find({},{"title":1,_id:0}).limit(2)
{"title":"MongoDB Overview"}
{"title":"NoSQL Overview"}
>
Ngoài ra có lệnh skip() cho phép bạn bỏ qua 1 giá trị document.
>db.mycol.find({},{"title":1,_id:0}).limit(1).skip(1)
{"title":"NoSQL Overview"}
>
MongoDB - Sort Records
Để sort các document trong MongoDB, bạn cần phải sử dụng sort(). sort() cho pehsp một document trong chứa các fields theo thứ tự order. có 2 loại thứ tự, 1 sẽ tương đương với ascending và -1 sẽ tương đương với descending.
>db.COLLECTION_NAME.find().sort({KEY:1})
MongoDB - Indexing
Index hỗ trợ độ phân tích một cách hiệu quả các truy vấn. Nếu không có chỉ mục, MongoDB sẽ phải quét tất cả các documents của collection để chọn ra những document phù hợp với câu truy vấn. Quá trình quét này là không hiệu quả và yêu cầu MongoDB để xử lý một khối lượng lớn dữ liệu.
Index là những cấu trúc dữ liệu đặc biệt, dùng để chứa một phần nhỏ của các tập dữ liệu một cách dễ dàng để quét. Chỉ số lưu trữ giá trị của một fields cụ thể hoặc thiết lập các fields, sắp xếp theo giá trị của các fields này.
>db.COLLECTION_NAME.ensureIndex({KEY:1})
Để có thể đánh số nhiều fields, bạn hãy dùng ensureIndex()
>db.mycol.ensureIndex({"title":1,"description":-1})
Ở đây giá trị 1 và -1 là thể hiện thứ tự sắp xếp index. ensureIndex() có khá nhiều tham số để bạn có thể tùy chỉnh.
MongoDB - Aggregation
Aggregation xử ly các record dữ liệu va trả về kết quả đã tính toán rồi. Aggregation sẽ group giá trị từ nhiều documents khác nhau và có thể tiến hành xử lý rất nhiều nhóm dư liệu để trả về một kết quả đơn lẻ. Xử lý này tương đương với count(*) trong SQL.
>db.COLLECTION_NAME.aggregate(AGGREGATE_OPERATION)
Ví dụ chúng ta có dữ liệu như thế này.
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by_user: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100
},
{
_id: ObjectId(7df78ad8902d)
title: 'NoSQL Overview',
description: 'No sql database is very fast',
by_user: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 10
},
{
_id: ObjectId(7df78ad8902e)
title: 'Neo4j Overview',
description: 'Neo4j is no sql database',
by_user: 'Neo4j',
url: 'http://www.neo4j.com',
tags: ['neo4j', 'database', 'NoSQL'],
likes: 750
},
Nếu bạn muốn hiển thị có bao nhiêu tutorial được viết bởi mỗi user bạn sẽ sử dụng aggregate() như sau :
> db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
{
"result" : [
{
"_id" : "tutorials point",
"num_tutorial" : 2
},
{
"_id" : "Neo4j",
"num_tutorial" : 1
}
],
"ok" : 1
}
>
Tương ứng với câu truy vấn trên trong SQL sẽ là select by_user, count(*) from mycol group by by_user. Trong ví dụ ở trên, chúng ta đã group các documents bới fields by_user và sau đó trên mỗi lần xả ra by_user giá trị tổng được tăng lên.
Khái niệm về PIPELINE
Trong các lệnh shell UNIX, pipeline có ý nghĩa khả năng để thực hiện một xử lý trên một vài input và sử dụng các outpust như là input cho lệnh toeeps theo. MongoDB cũng hỗ trợ khái niệm tương tự trong framework aggregation. Sẽ có một tập hợp các stage có thể xảy ra và mỗi stage được đánh dấu bằng môt nhóm các documents như là input và tính toán ra kết quả của nhóm documents đó. Kết quả nà có thể sẽ được chuyển thành input sử dụng cho stage kế tiếp.
Bài viết sau mình sẽ viết tiếp về những vấn đề nâng cao hơn của MongoDB.
MongoDB - Replication
Replication là khái niệm đồng bộ hóa dữ liệu trên nhiều server. REplication sẽ cung cấp rất nhiều và tăng tính sẵn sàng của data với nhiều bản copy dữ liệu trên nhiều server DB, replications bảo vê DB khỏi việc mất dữ liệu trên 1 server đơn lẻ. Relication cũng cho phép bạn có thể khôi phục dữ liệu từ các ổ cứng bị lỗi và việc service bị lỗi hay gặp vấn đề. Với rất nheieuf các copy dữ liệu, bạn có thể tinh chỉnh môt bản cho việc khôi phục, report hoặc backup.
Tại sao lại cần REPLICATION
- Dữ data an toàn
- Tạo tính sẵn sàng 24/7 cho dữ liệu
- Khôi phục dư liệu khỏi lỗi
- Không có downtime khi xảy ra maintenance.
- Tăng khả năng read dữ liệu
- Replica setting không ảnh hưởng đến ứng dung
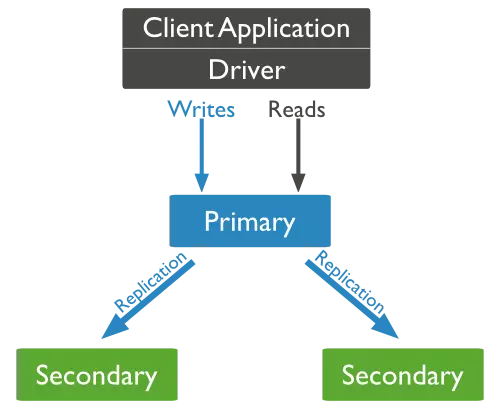
REPILCATION hoạt động như thế nào trong MongoDB
MongoDB lưu trử replication bằng việc sử dụng tập hợp repica. Một tập hơp replica chính là một group các instance mongodb mà có host
cung chung tập hợp dữ liệu. Tất cả các instance khác, thứ 2 sẽ được apply xử lý từ instance primary cho nên nó sẽ có chung tập hợp dữ liệu. Replica chỉ có duy nhất một node primary chính.
- Replica là một tâp hợp 2 hoặc nhiều nodes
- Trong tập hợp replica, một node là node chính và phần còn lại là nốt thứ 2
- Tất cả các dữ liệu được replicates từ node chính sang các node phụ
- Tại một thời điểm nào tự động maintenance, sẽ có một "cuộc bầu cử " được thiết lập lại để chọn ra node chính mới.
- Sau một lần recovery một node bị lỗi, nó sẽ join lại nhóm replica và làm việc như một nốt phụ tiếp.
MongoDB - Sharding
Sharding là quá trình xử lý lưu trử dữ liệu record trên nhiều máy và đây là cách tiếp cận của MongoDB để có thể thỏa mãn các yêu cầu về big data. Khi size của dữ liệu gia tăng, một máy tính đơn lẻ ko thể đủ để lưu dữ liệu cũng như cung cấp các xử lý read và write thông thường. Sharding giải quyết bài toán này bằng cách scale lên theo chiều ngang. VỚi sharding, bạn có thể sẽ add thêm machines để hỗ trợ lưu trữ dữ liệu cũng như các yêu cầu về đọc và viết.
Tại sao lại cần Sharding
- Trong replication tất cả writes sẽ được tiến hành ở node master
- Các câu truy vấn trên master có một chút độ trễ
- Một tập hợp replica có giới hạn 12 nodes
- Bộ nhớ không thể đủ lớn khi làm việc với big data
- Local disk không đủ lớn
- Scale dọc quá tốn tiền
Sharding in MongoDB
Đây là mô hình sharding trong MongoDB
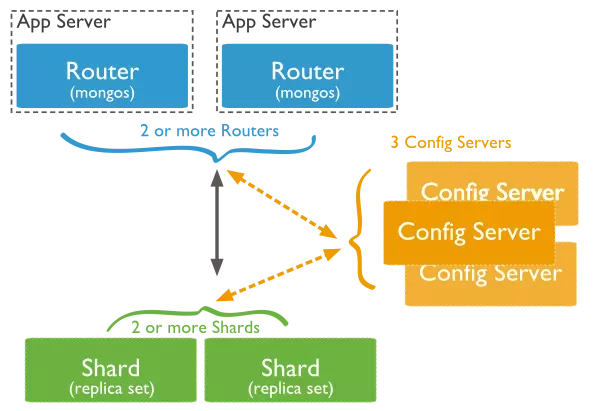
- Shards : Shards được sử dụng để lưu trữ dữ liệu. Chúng cung cấp các dữ liệu với tính ổn định và sẵn sàng cao. Trong môi trường production, shard chính là một nhóm các replica riêng rẽ.
- Config Servers : Config Servers lưu dứ liệu metadata trong cluster. Dữ liệu chứa các thông tin về map dữa nhóm dữ liệu với các shards. Mỗi query router sẽ dụng metadata để định hướng các xử lý đến các sharding cụ thể. Trong môi trường production, nhóm shard sẽ có 3 config server.
- Query Routes : Query Routes về cơ bản là các instance của mongos, giao tiếp với ứng dụng cliens và chỉ định các xử lý đến shard tương ứng. Query Router xử lý và nhắm đến các shards và trả về kết quả cho clients. Một nhóm các shard có thể chưa nhiều hơn một query router để phân loại tải request. Một Clients send request đến một query router. Nhìn chung thì một nhóm các sharded sẽ có nhiều query router.
Nguồn : http://www.tutorialspoint.com/
All rights reserved
