Tìm hiểu về hệ phân tán (Phần 5: Định danh) - Part 2
Bài đăng này đã không được cập nhật trong 4 năm
Ở phần 1 chúng ta đã tim hiểu thế nào là định danh và Không gian tên phẳng. Hôm nay mình cũng tìm hiểu tiếp mục (3), (4) nhé!
Mục lục
- (1) Tên, định danh, và địa chỉ
- (2) Không gian tên phẳng
- (3) Không gian tên có cấu trúc
- (4) Không gian tên theo thuộc tính
3. Không gian tên có cấu trúc
3.1. Cấu trúc không gian tên
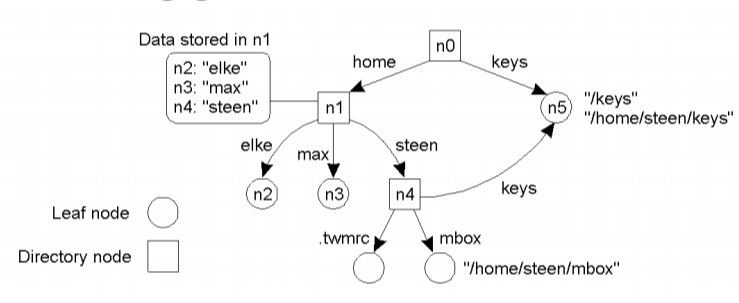
Các tên thường được tổ chức thành không gian tên, được thể hiện bằng các nhãn hoặc đồ thị có hướng với hai loại nút: nút lá và nút thư mục.
- Nút lá:
- Thể hiện thực thể được đặt tên.
- Không có nhánh ra.
- Chứa địa chỉ, trạng thái,... của thực thể
- Nút thư mục:
- Được gán nhãn.
- Có các nhánh ra.
- Có chứa tên của các thực thể trong thư mục.
- Đường dẫn tương ứng với một tên.
- Tên toàn cục/đường dẫn tuyệt đối.
- Tên cục bộ/đường dẫn tương đối.
Cách mô tả đồ thị trên gần giống với hệ thống quản lý tập tin trên một máy tính.
- Các nhãn trong đường dẫn được phân cách nhau bởi dấu gạch chéo, nếu tồn tại nhiều đường dẫn đến một nút thì nó sẽ biểu diễn bằng các tên đường dẫn khác nhau.
- Tên của các tài nguyên được đặt giống như tên của các tập tin.
- Hầu hết không gian tên chỉ có duy nhất một nút gốc, trong nhiều trường hợp nó được tổ chức chặt chẽ dưới dạng cây, khi đó mỗi nút chỉ có một cạnh đến, ngoại trừ nút gốc => mỗi nút có chính xác một tên đường dẫn liên kết tuyệt đối.
- Trong thực tế có thể có những không gian tên được biểu diễn ở dạng đồ thị không tuần hoàn có hướng, có thể đến một nút bằng nhiều đường khác nhau nhưng không được phép tạo thành vòng tuần hoàn.
Không gian tên (UNIX)
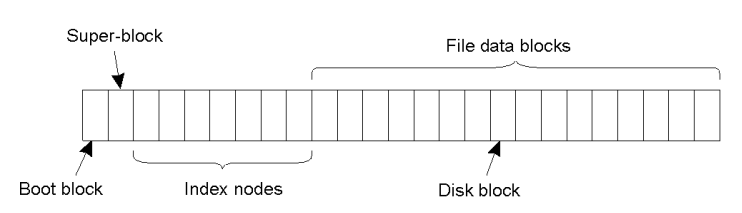
Đây hệ thống quản lý tập tin của hệ điều hành Unix:
- Nút thư mục đại diện cho thư mục, nút lá đại diện cho tập tin và nút gốc là tên ổ đĩa logic.
- Ổ đĩa được chia thành nhiều khối kế tiếp nhau, chúng bao gồm:
- Khối khởi động (boot block): nạp hệ điều hành sau khi bật máy tính.
- Siêu khối (super block): mô tả hệ thống tập tin.
- Các nút chỉ mục (index nodes):
- Chứa thông tin phục vụ cho tìm kiếm tập tin.
- Chứa thông tin về thuộc tính của tập tin như chủ sở hữu, thời gian tạo, thời gian cập nhật cuối cùng...,
- Lưu trữ thông tin về các thư mục.
- Do đó số chỉ mục tương ứng với một định danh của nút trong đồ thị tên.
- Cuối cùng là các khối chứa dữ liệu của tập tin (file data blocks).
3.2. Phân giải tên
Không gian tên cung cấp cơ chế thuận tiện để lưu trữ và truy xuất thông tin về các thực thể bằng tên. Tổng quát hơn, cho một tên đường dẫn, nó có thể tìm kiếm bất kỳ thông tin được lưu trữ trong các node được gọi bằng cái tên đó. Quá trình này gọi là phân giải tên.
- Đầu tiên nó truy vấn bảng thư mục để tìm ra dữ liệu thực được lưu trữ ở đâu.
- Quá trình tìm kiếm tiếp diễn từ nút thư mục này qua nút thư mục khác, cuối cùng trả về định danh một nút.
- Do đó việc phân giải tên chỉ có thể diễn ra nếu biết được bắt đầu từ nút nào trong không gian tên, nó còn gọi là cơ chế đóng.
- Hệ thống quản lý tên trong hệ điều hành Unix phân biệt tên cục bộ và tên toàn cục.
- Biến môi trường HOME sử dụng để tham chiếu đến thư mục gốc của người dùng.
- Mỗi người dùng có bản sao riêng của biến này được khởi tạo thành tên toàn cục tương ứng với thư mục chính của người dùng.
- Cơ chế đóng gắn kết với các biến môi trường đảm bảo việc phân giải tên chính xác bằng cách tra cứu bảng dành riêng cho người dùng.
- Trong thực tế Unix coi nút chỉ mục đầu tiên của ổ đĩa là nút gốc, độ lệch thực tế của nó được tính toán từ dữ liệu lấy từ siêu khối.
Linking
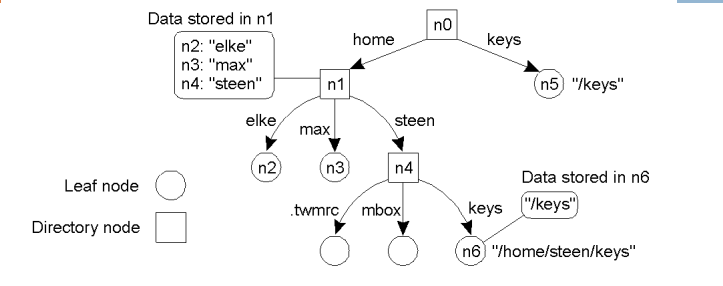
Bí danh là một tên khác của cùng một thực thể, có hai cách triển khai trong đồ thị tên.
- Cách 1: cho phép nhiều đường dẫn tuyệt đối tham chiếu đến cùng một nút, sau đó mới phân giải đường dẫn này. Cơ chế này gọi là liên kết tên.
- Ví dụ: thực thể các đường dẫn /keys và /home/steen/keys đều trỏ đến nút n5.
- Cách 2: biểu diễn một thực thể bằng nút lá nhưng nó không lưu trữ địa chỉ hay trạng thái mà lưu trữ đường dẫn tuyệt đối đến thực thể.
Phân giải tên cũng có thể được thực hiện trên hai không gian khác nhau.
- Để thực hiện nhiệm vụ này cần có một nút thư mục được gọi là điểm gắn kết lưu giữ định danh từ một không gian khác.
- Nút thư mục bên phía không gian tên cần gắn kết được gọi là điểm gắn.
- Điểm gắn kết được coi là một nút thư mục và thông thường nó là gốc của không gian tên bên ngoài, do đó quá trình phân giải sẽ bắt đầu bằng việc truy nhập bảng thư mục của nút này.
- Để gắn kết không gian tên của các máy tính khác nhau cần có thông tin sau:
- Tên của giao thức truy nhập: để giao tiếp với máy tính của không gian tên bên ngoài.
- Tên của máy chủ: dể xác định địa chỉ của máy chủ quản lý không gian tên bên ngoài.
- Tên của điểm truy nhập: tên của nút gắn kết của không gian tên bên ngoài. Nó được phân giải thành định danh của nút trong không gian tên bên ngoài.
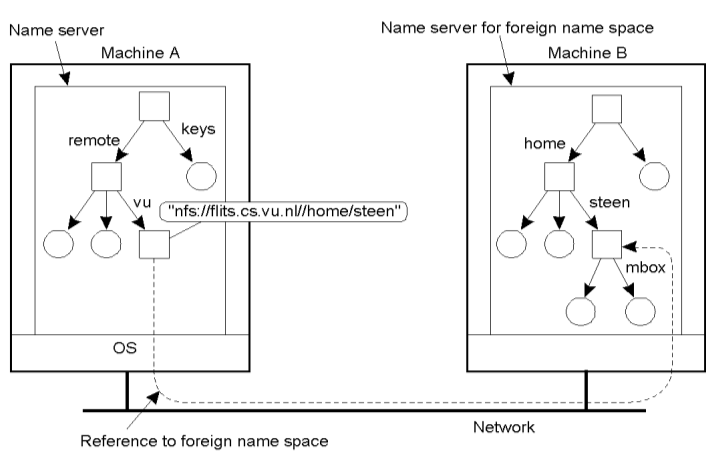
Mounting
-
Ba thông tin trên không thực sự cần thiết nếu không phải là hệ thống phân tán, không cần giao thức truy nhập cũng như tên của máy tính và điểm gắn kết.
-
Có thể sử dụng đường liên kết URL để đại diện cho cả ba thông tin này.
-
Giao thức hệ thống tập tin mạng (NFS) cho phép các máy khách có thể truy nhập đến các tập tin cài đặt trên máy chủ. Ví dụ:
- Đường liên kết nfs://flits.cs.vu.nl/home/steen cho biết giao thức là NFS.
- Tên máy chủ là flits.cs.vu.nl và điểm truy nhập là /home/steen.
- Tên nfs được hiểu là cần phải triển khai giao thức NFS, tên máy chủ flits.cs.vu.nl sẽ được phân giải bằng dịch vụ tên miền DNS. Như vậy /home/steen sẽ được máy chủ của không gian tên bên ngoài phân giải.
-
Tổ chức tập tin trên máy khách do người dùng định nghĩa, nó chứa thư mục con /remote gồm các điểm gắn kết với không gian tên bên ngoài. Ví dụ hình trên thể hiện gắn kết không gian tên của máy chủ:
- Thư mục chính sẽ sử dụng nút /vu để lưu trữ đường liên kết nfs://flits.cs.vu.nl/home/steen.
- Tên /remote/vu/mbox được phân giải trên máy khách cho đến khi gặp nút /remote/vu. Sau đó tiếp tục bằng cách trả về đường liên kết nfs://flits.cs.vu.nl/home/steen.
- Máy khách sẽ sử dụng giao thức NFS để liên lạc với máy chủ để có thể truy nhập vào thư mục /home/steen.
- Quá trình phân giải tên sẽ tiếp tục trên máy chủ bằng cách đọc tập tin mbox.
3.3. Phân tán không gian tên
- Không gian tên cho hệ thống phân tán quy mô lớn thường được tổ chức theo dạng phân cấp. Để tổ chức một cách hiệu quả người ta phân biệt ba lớp: lớp toàn cục, lớp hành chính và lớp quản lý.
- Lớp toàn cục: được tạo bởi các nút mức cao nhất, nghĩa là chỉ gồm nút gốc và các nút con của nó.
- Bảng thư mục của các nút ít thay đổi => tính ổn định khá cao.
- Các nút như vậy thường đại diện cho các tổ chức.
- Lớp quản trị: được tạo ra từ các nút thư mục do cùng một đơn vị quản lý.
- Chúng đại diện cho các nhóm thực thể thuộc cùng một tổ chức.
- Các nút ít khi thay đổi nhưng tính ổn định của nó thấp hơn lớp toàn cục.
- Lớp quản lý: gồm các nút có thể thay đổi thường xuyên, là các nút đại diện cho dịch vụ nào đó.
- Khác với hai lớp trên, người dùng đầu cuối cũng có thể quản trị các nút thư mục thuộc lớp này.
- Lớp toàn cục: được tạo bởi các nút mức cao nhất, nghĩa là chỉ gồm nút gốc và các nút con của nó.
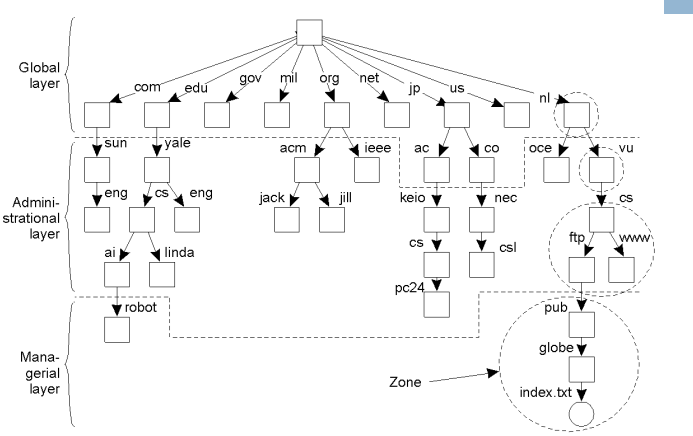
Ví dụ về phân lớp trong không gian tên như hình vẽ:
- Chúng được chia thành các vùng không trùng lặp do một máy chủ quản lý.
- Xét về tính sẵn sàng và hiệu năng thì mỗi máy chủ phân giải tên miền sẽ phải đáp ứng các yêu cầu khác nhau.
- Máy chủ ở lớp toàn cục đòi hỏi tính sẵn sàng cao. Nếu nó bị lỗi thì một lượng lớn tên miền sẽ không thể phân giải.
- Vấn đề hiệu suất có thể giải quyết bằng cách máy khách lưu trữ địa chỉ của tên miền trong bộ nhớ đệm, có thể kiểm tra bằng lệnh ipconfig /displaydns và xóa bằng lệnh ipconfig /flushdns.
- Như vậy chỉ lần đầu tiên truy nhập máy khách mới phải sử dụng dịch vụ phân giải tên, do đó các máy chủ lớp toàn cục không cần phải đáp ứng nhanh các yêu cầu tra cứu. Tuy nhiên phải cung cấp đủ băng thông phục vụ cho qui mô hàng triệu yêu cầu gửi đến.
- Để đáp ứng yêu cầu về tính sẵn sàng và hiệu năng thì các máy chủ lớp toàn cục phải được nhân bản.
- Do các tên miền không đòi hỏi cập nhật ngay lập tức cho nên vẫn duy trì được tính nhất quán cho các bản sao.
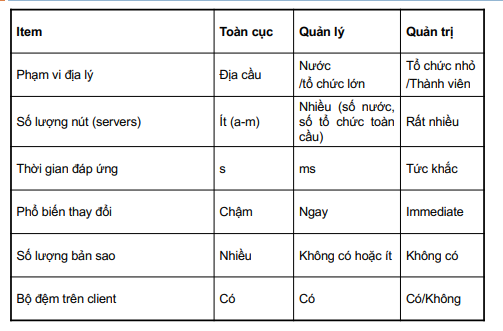
3.4. Cài đặt cơ chế phân giải tên
-
Việc cài đặt các máy chủ phân giải tên tại lớp toàn cục và lớp quản trị là phức tạp nhất.
- Không những khó khăn trong việc đáp ứng các yêu cầu về tính sẵn sàng và hiệu năng mà còn ở khía cạnh nhất quán trong nhân bản.
- Vấn đề sẽ trở nên khó khăn hơn khi bộ nhớ đệm và các bản sao được trải rộng trên quy mô lớn => có thể gây nên sự chậm trễ truyền thông trong quá trình tra cứu.
-
Mỗi thực thể đều có tên và địa chỉ tương ứng, việc ánh xạ từ tên đến địa chỉ của thực thể được thực hiện theo hai phương pháp:
- Mô hình một lớp: chỉ ánh xạ giữa tên và thực thể, mỗi lần thực thể thay đổi vị trí, ánh xạ cần phải được thay đổi theo.
- Mô hình hai lớp: phân biệt tên và địa chỉ nhờ định danh thực thể, gồm quá trình tìm định danh thực thể tương ứng từ tên của thực thể được thực hiện bằng dịch vụ tên và quá trình xác định vị trí của thực thể từ định danh được thực hiện bởi dịch vụ định vị.
-
Phân giải tên được thực hiện theo hai phương pháp:
- Phân giải tên tương tác: thực hiện bằng cách truyền và nhận qua lại giữa máy khách và các máy chủ quản lý tên ở các mức khác nhau.
- Các máy chủ quản lý tên không trao đổi trực tiếp với nhau.
- Mỗi máy chủ chỉ phân giải nhãn tương ứng với lớp để xác định địa chỉ của máy chủ tiếp theo.
- Kết quả trả lại cho máy khách là địa chỉ của máy chủ quản lý tên kế tiếp và việc liên kết với máy chủ tiếp theo là do máy khách đảm nhiệm.
- Phân giải tên đệ quy: thực hiện bằng cách mỗi máy chủ quản lý tên sẽ gửi kết quả đến máy chủ quản lý tên tiếp theo mà nó tìm thấy và cứ như vậy cho đến khi hoàn thành phân giải toàn bộ đường dẫn.
- Phân giải tên tương tác: thực hiện bằng cách truyền và nhận qua lại giữa máy khách và các máy chủ quản lý tên ở các mức khác nhau.
4. Không gian tên theo thuộc tính
- Đặt tên có cấu trúc hay không có cấu trúc đều bảo đảm tham chiếu đến một thực thể duy nhất một cách độc lập với vị trí của thực thể đó.
- Trong thực tế, hai tiêu chí thân thiện với người dùng và độc lập vị trí là chưa đủ, người dùng muốn tìm kiếm các thực thể dựa trên các thuộc tính của chúng, mô tả càng nhiều thuộc tính càng tốt.
- Nếu tên được phân ra thành nhiều thuộc tính thì có thể lợi dụng thứ tự các thuộc tính. Ví dụ:
- Người sử dụng với thuộc tính tên là <A>, thuộc tính tổ chức là <FOT> và thuộc tính quốc gia là <VN> có thể tạo ra thành một thuộc tính tổng hợp là <A.FOT.VN> như thuộc tính tên.
- Khi không cho thứ tự các thuộc tính, có thể định vị đối tượng nhờ tập hợp tất cả các thuộc tính. Ví dụ U=A, C=FOT, O=VN khi đó U, C, và O đại diện cho các thuộc tính là tên, cơ quan và quốc gia.
- Những tên này được xác định dựa vào việc ghép nối kế tiếp các thuộc tính dựa vào tên cấu trúc phân cấp hoặc dựa vào chỉ tập hợp các thuộc tính với cấu trúc tùy ý.
- Việc phân chia thuộc tính cho giải pháp tên của đối tượng có thể căn cứ vào tính chất vật lý, theo tổ chức hoặc theo chức năng.
4.1. Dịch vụ thư mục
-
Cho phép tìm kiếm của một tên và thông tin được liên kết với tên đó.
-
Trong một thư mục, một tên có thể có nhiều loại dữ liệu khác nhau.
-
Thư mục có thể được thu hẹp trong phạm vi, hỗ trợ chỉ một tập hợp các loại giao điểm nhỏ và loại dữ liệu hoặc chúng có thể rất rộng, hỗ trợ một loại tùy ý hoặc mở rộng.
-
Trong một thư mục được sử dụng bởi một hệ điều hành mạng, các giao điểm đại diện cho các nguồn tài nguyên được quản lý bởi các hệ điều hành, bao gồm cả người sử dụng, máy tính, máy in và các tài nguyên chia sẻ khác.
-
Một thư mục đơn giản, dịch vụ đặt tên gọi là một dịch vụ bản đồ tên của mạng lưới các tài nguyên tới các địa chỉ mạng tương ứng.
-
Với tên gọi loại hình dịch vụ thư mục, một người dùng không cần phải ghi nhớ địa chỉ vật lý của một mạng tài nguyên, cung cấp một tên sẽ tìm tài nguyên.
-
Mỗi tài nguyên trên mạng được xem là một đối tượng trên thư mục máy chủ.
- Thông tin về một tài nguyên đặc biệt này được lưu giữ như là thuộc tính của đối tượng đó.
- Thông tin trong các đối tượng có thể được thực hiện để bảo đảm rằng chỉ có người dùng với quyền truy cập sẵn có là có thể truy cập nó.
-
Một dịch vụ thư mục:
- Là một thông tin chia sẻ về cơ sở hạ tầng cho định vị, quản lý, điều hành, tổ chức các tài nguyên mạng bao gồm: các khối tin, thư mục, tập tin, máy in, người dùng, các nhóm, các thiết bị, số điện thoại và các đối tượng khác.
- Là một thành phần quan trọng của một hệ điều hành mạng.
- Trong trường hợp phức tạp hơn, nó có thể là một kho thông tin trung tâm cho một nền tảng phân phối dịch vụ.
4.2. Giao thức LDAP (Lightweight directory access protocol)
-
Một phương pháp phổ biến để giải quyết các dịch vụ thư mục phân tán là kết hợp định danh có cấu trúc với định danh dựa trên thuộc tính.
-
Nhiều hệ thống sử dụng cái này, hoặc dựa vào các giao thức truy cập thư mục nhẹ gọi là LDAP.
-
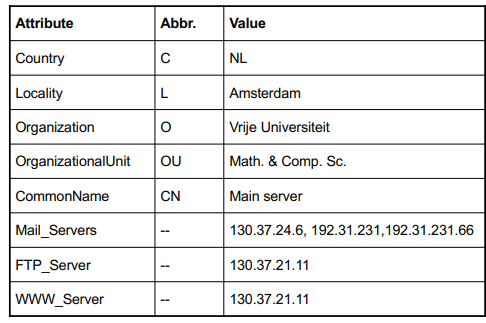
Một dịch vụ thư mục LDAP bao gồm một số lượng record (bản ghi), mỗi record được tạo thành từ một cặp (giá trị, thuộc tính).
-
Ví dụ đơn giản của một đường dẫn thư mục LDAP sử dụng quy ước định danh LDAP.
![]()
Đến đây mình xin kết thúc part 2 của phần ĐỊnh danh trong hệ phân tán. Phần tiếp theo sẽ là phần Đồng bộ hóa trong hệ phân tán. Mong mọi người đón đọc.
Thanks for reading💖
Tài liệu tham khảo Bài giảng Hệ phân tán - ĐHBKHN
All rights reserved
