Cách Merkle tree giải quyết các vấn đề trong một mạng phân tán
Bài đăng này đã không được cập nhật trong 6 năm
Bạn đã biết thứ gì chung được triển khai trong các công nghệ Bitcoin, Git, IPFS, Ethereum, BitTorrent, và Cassandra?
Có thể tiêu đề đã gợi ý cho bạn, đó là "Merkle tree", một kỹ thuật lưu trữ dữ liệu rất hữu dụng ở các hệ thống có kiến trúc phi tập trung. Nhưng Merkle tree giải quyết những vấn đề gì và bằng cách nào ? Mình sẽ lý giải điều đó trong bài viết này !

I. Xác thực trong mạng phân tán
Kiến trúc phân tán (peer-to-peer) từ khi sinh ra ngày càng được sử dụng rộng rãi, nhưng nó cũng gặp phải rất nhiều vấn đề và một trong số đó là làm thế nào để "Xác thực" hiệu quả. Một hệ thống tin cậy phải cần phải xác thực để đảm bảo rằng các thành phần tham gia không
- Làm thay đổi dữ liệu do vô tình hoặc
- Làm thay đổi dữ liệu do cố ý
Một trong những cách phổ biến để ngăn chặn vấn đề trên là dùng các hàm băm mã hoá. Vậy hãy tìm hiểu xem chúng được sử dụng thế nào.
Hàm băm mã hoá liệu đã là giải pháp ?
Băm toàn bộ dữ liệu
Nếu ta muốn lưu trữ phân tán 1 file dữ liệu lớn, hàm băm có thể giúp ta tính mã băm của toàn bộ file (trước khi lưu trữ phân tán) và lưu nó vào 1 máy chủ (có độ tin cậy cao) nhằm xác thực khi cần thiết.
Toàn bộ "File 1" (được chia làm 4 phần W, X, Y, Z) được băm ra và kết quả lưu trữ trong 1 server
Sau khi được băm, chúng ta lưu trữ phân tán file trên nhiều peer trong mạng. Bất cứ khi nào có 1 peer cần nội dung toàn bộ file sẽ phải tải chúng từ các peer đang lưu trữ các thành phần của file. Peer này sẽ cần tính toán mã băm của toàn bộ file (sau khi đã có đủ các thành phần) và xác thực bằng cách so sánh với mã băm ở server.
*P/s: Nếu bạn nghĩ 2 file có thể có cùng mã băm thì hoàn toàn đúng. Nhưng trong thực tế, mã băm 256-bit thường được sử dụng và có thể cho đến 2^256 kết quả. Vì vậy việc trùng lặp gần như không thể !
Cách tiếp cận này hoạt động, nhưng chưa hiệu quả bởi:
- Chỉ có thể tiến hành xác thực sau khi thu thập đủ toàn bộ file: Nếu dữ liệu phân tán trên hàng ngàn peer, sẽ có vấn đề là 1 số phần sẽ được gửi đến sớm, và 1 số sẽ đến muộn hơn. Việc chỉ chờ đợi toàn bộ được gửi đến rồi mới có thể xác thực là sự lãng phí thời gian.
- Không thể xác định được thành phần nào sai lệch (do chỉ kiểm khi toàn bộ các thành phần đã được gộp lại).
- Tính đồng bộ quá cao: Chỉ 1 ký tự thay đổi cũng dẫn đến việc tính toán lại mã băm toàn bộ file và lưu trữ lại tại server.
- Server lưu trữ mã băm là điểm yếu trong mạng phi tập trung này.
Băm từng phần dữ liệu
Việc lưu trữ mã băm cùng từng phần trên server có thể là giải pháp cho vấn đề "1", "2" bằng cách xác thực từng phần và phần nào vấn đề "3" vì có thể chỉ cập nhật lại phần dữ liệu thay đổi. Tuy nhiên, vẫn còn những nhược điểm:
- Server lưu trữ thêm 1 lượng nhỏ thông tin.
- Tăng khả năng trùng lặp mã hash.
- Toàn bộ mạng vẫn cần dựa vào 1 server. Sẽ thế nào nếu server này không đáng tin ?
Chuỗi băm
Vậy nếu ta làm thế này thì ?
Ta gộp các mã hash của từng thành phần vào và băm ra tiếp, kết quả (gọi là root hash) được lưu trữ tại server. Root hash sẽ có vai trò xác thực. Vậy thì sẽ thế này:
- Ban đầu, peer thu thập các phần của dữ liệu.
- Sau đó, ta sẽ hash từng phần và gộp các mã hash lại, tiếp tục tính toán root hash. Root hash này sẽ được so sánh với cái trên server.
- Và khi, và nếu root hash của ta tồn tại trên server, ta có thể lưu nó lại để tự xác thực cho tương lại mà không cần dựa vào server nữa.
Có vẻ là mọi thứ đều tốt ngoại trừ sẽ thế nào nếu server không đáng tin và trả về cho ta kết quả phản hồi sai về root hash.
Thật ra có 1 cách mà server có thể chứng minh nó đánh tin. Đọc tiếp nhé ....
Lưu trữ nhiều thông tin hơn trên server
Vậy nếu ta lưu trữ cả mã hash từng phần và root hash trên server thì ?
Tất nhiên chi phí lưu trữ sẽ tăng lên 1 chút, nhưng lại có thể giải quyết vấn đề "4" như sau:
- Thay vì phàn hồi root hash có tồn tại hay không, server sẽ phải gửi toàn bộ các mã hash để tính toán ra root hash.
- Với những mã hash gửi về, cùng với mã hash của phần dữ liệu cần xác thực, client có thể tự mình tính toàn ra root hash và so sánh với root hash được gửi về.
Chúng ta sắp đi đến toàn bộ lời giải về Merkle trees rồi !
II. Vậy Merkle Trees là gì ?
Kiến trúc
Đi đến lời giải, nếu mô hình lưu trữ thế này có hiểu quả không ?
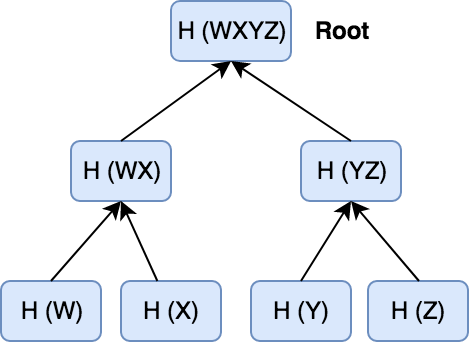
Các nút lá trong cây tương ứng với mã hash của từng phần dữ liệu, và 2 mã hash con kết hợp với nhau rồi tiếp tục hash sẽ ra mã hash ở nút mẹ. Đây chính là kiến trúc của Merkle trees.
Tại sao mô hình này hiệu quả ?
Bạn có thể đang tự hỏi bằng cách nào mô hình này hơn các mô hình trước và nó có lợi ích gì. Nó thực sự hiệu quả trong lưu trữ và tính toán như sau:
Xác thực dữ liệu
Dữ liệu sẽ được xác thực trong Merkle Trees như sau:
- Như trước, ta tải các phần dữ liệu về node.
- Ta gửi yêu cầu các mã hash cần thiết đến server.
- Server trả về kết quả.
- Với những mã hash hiện có, ta có thể tính toán ra root hash và so sánh với cái trên server.
Ví dụ, nếu 1 node cần xác thực dữ liệu Y, khi ta gửi request, server sẽ trả về cho ta H(Z) và H(WX), được gọi là audit trail hoặc merkle path.

Ta có thể tính toán:
- H(YZ) được tính toán từ H(Y) cùng với H(Z) đã được server gửi về.
- H(WXYZ) được tính toán từ H(YZ) cùng với H(WX) đã được server gửi về.
Cuối cùng, ta so sánh H (WXYZ) với root hash trong server. Nếu khớp, có thể khẳng định dữ liệu đáng tin cậy. Còn không, ta nên check lại peer đã gửi Y cho ta và request Y từ peer khác.
Vậy nó tốt ở đâu:
- Chỉ cần rất ít thông tin phục vụ cho việc xác thực. Ngay cả khi số nút lá (phần dữ liệu) tăng gấp đôi, ta cũng chỉ cần thêm 1 mã hash và tiến hành hashing thêm 1 lần để xác thực.
- Và với việc cần ít dữ liệu, sẽ giúp giảm tải cho băng thông.

Đây là cải tiến lớn so với cách tiếp cận trước mà ta cần gửi toàn bộ mã hash từ server.
Xác minh tính nhất quan
Các hệ thống phân tán chỉ cho phép dữ liệu được thêm vào mà không thể xoá đi. Vì vậy Merkle Trees rất hữu ích trong việc xác thực bất cứ phiên bản mới vào của dữ liệu có chứa các dữ liệu cũ hay không.
Đồng bộ dữ liệu
Merkle trees có thể thay thế cho việc so sánh toàn bộ dữ liệu để xác định thay đổi. Ta chỉ cần so sánh các mã hash trong cây và một khi có nút lá thay đổi, chỉ dữ liệu đó cần đồng bộ hoá với các node khác trong mạng.
III. Kết luận
Trong bài viết này, ta đã từng bước tìm hiểu cách Merkle trees làm việc và so sánh nó với các giải pháp khác và làm thế nào nó giải quyết các vấn đề trong mạng phân tán. Tuy hiệu quả cao trong sử dụng nhưng việc cài đặt nó thì hết sức đơn giản.
Trong bài viết tiếp, mình sẽ hướng dẫn các bạn cài đặt Merkle trees.
Tài liệu tham khảo
- https://www.codementor.io/blog/merkle-trees-5h9arzd3n8
- https://en.wikipedia.org/wiki/Merkle_tree
- Mastering Bitcoin: Unlocking Digital Cryptocurrencies - Andreas Antonopoulos
All rights reserved
