Tìm hiểu về hệ phân tán (Phần 3 - Quản lý tiến trình và luồng)
Bài đăng này đã không được cập nhật trong 5 năm
Tiếp tục chuỗi series về hệ phân tán, như đã hứa ở phần trước Kiến trúc hệ phân tán hôm nay mình sẽ giới thiệu về phần Quản lý tiến trình và luồng để mọi người có thể nắm được những kiến thức cơ bản về tiến trình và luồng trong HPT là như thế naò nhé! Let's go
Mục lục gồm 3 phần:
- Tiến trình và luồng
- Khái niệm ảo hóa
- Di trú mã
I. Các tiến trình và luồng
Tiến trình
- Là 1 chương trình đang được chạy trên 1 trong các bộ xử lý ảo của hệ điều hành.
- Để chạy các chương trình HĐH tạo ra các bộ xử lý ảo khác nhau, mỗi bộ xử lý ảo chạy 1 chương trình.
- Để ghi lại thông tin các bộ xử lý ảo này, HĐH cần có 1 bản tiến trình lưu lại thông tin về giá trị thanh ghi CPU, memory maps, các tệp đang mở, thông tin tài khoản,...
- 1 tiến trình được định nghĩa như 1 chương trình đang chạy trên 1 bộ xử lý ảo. Vấn đề quan trọng là HĐH làm cho hoạt động của các tiến trình đó là trong suốt với nhau. Chúng hoàn toàn độc lập và không gây ảnh hưởng được lẫn nhau
- HĐH cần sự hỗ trợ của phần cứng để thực hiện sự trong suốt này. Để thực hiện được điều đó, HĐH cần tạo ra các không gian địa chỉ hoàn toàn độc lập. Việc cấp phát vùng nhớ tương đương với việc khởi tạo vùng nhớ, xóa vùng dữ liệu, sao chép chương trình vào vùng nhớ đó, khởi tạo ngăn xếp cho dữ liệu tạm thời
- VIệc chuyển CPU giữa các tiến trình rất tốn kém tài nguyên của hệ thống. Nó bao gồm các việc: lưu lại thông tin ngữ cảnh của CPU (như giá trị thanh ghi, bộ đếm chương trình, con trỏ stack,...), HĐH còn phải thay đổi thanh ghi cho đơn vị quản lý bộ nhớ
- Ngoài ra nếu số tiến trình nhiều hơn khả năng lưu trữ của bộ nhớ chính, có thể dùng tạm bộ nhớ của ổ cứng để swap. Vấn để cần thiết là cần phải kiểm soát chặt chẽ độ bảo mật và an toàn. Dựa trên nguyên tắc các thao tác lỗi của 1 tiến trình rất khó có thể ảnh hưởng đến 1 tiến trình khác không phụ thuộc
Luồng
1. Luồng trong các hệ thống tập trung
- Khi 1 tiến trình chạy 1 chương trình nó sẽ sinh ra 1 hay nhiều luồng.
- Sau khi được tiến trình sinh ra mỗi luồng có đoạn mã thực hiện riêng, độc lập với các luồng khác.
- Tuy nhiên khác với tiến trình, các luồng không cần phải hoạt động hoàn toàn độc lập và trong suốt với nhau. Vì vậy mỗi luồng chỉ cần lưu trữ thông tin ít nhât để có thể cho phép các luồng chia sẻ CPU
- Ngữ cảnh của luồng chỉ là ngữ cảnh của CPU và 1 vài thông tin quản lý luồng khác. Những thông tin nào không cần thiết để quản lý đa luồng thường được bỏ qua. Do đó việc bảo về truy cập giữa các luồng thường được thực hiện bởi lập trình viên (chính là chúng ta đó
 )
) - Các ứng dụng đa luồng thường giúp chương trình có hiệu năng cao hơn. Tuy nhiên việc lập trình để cho các luồng không ảnh hưởng lẫn nhau là khá khó khăn
Lợi ích của tiến trình đa luồng so với đơn luồng:
- Trong trường hợp khi không sử dụng đa luồng, với các lời gọi hệ thống dừng, toàn bộ tiến trình sẽ bị dừng => treo chương trình => đa luồng giải quyết vấn đề đó
- Khai thác đa vi xử lý, ứng dụng trong chương trình tính toán song song. Mỗi luồng nằm ở 1 CPU nhưng dữ liệu chia sẻ lại cùng nằm ở bộ nhớ chính. Với mô hình này chúng ta hoàn toàn có thể dùng các thuật toán tính toán song song để tăng hiệu năng hệ thống với kiến trúc đa vi xử lý
- Đa luồng hữu dụng trong các chương trình lớn. Thông thường chương trình lớn dược cấu thành từ các chương trình nhỏ có liên kết phối hợp với nhau. Mỗi chương trình nhỏ đều được chạy bởi 1 tiến trình phân biệt. Nhược điểm của mô hình này là các giao tiếp cần đến sự chuyển ngữ cảnh => áp dụng cơ chế đa luồng để giải quyết vấn đề, với việc mỗi luồng đảm nhận 1 chương trình con và không cần việc chuyển ngữ cảnh
- Module hóa các phần mềm. Mỗi phần mềm có nhiều chúc năng khác nhau, kỹ thuật lập trình đa luồng cho phép phát trỉnh phần mềm bằng cách tạo ra các luồng đảm đương các chức năng khác nhau
Cách thức cài đặt luồng
- Các luồng thường được cung ứng bởi các gói luồng.
- Các gói bao gồm các nhiệm vụ: tạo, hủy và đồng bộ giữa các luồng
- Có 2 hướng tiếp cận để cài đặt luồng: User mode và kernel mode
Xây dựng luồng kiểu người dùng (User mode)
- Ưu điểm:
- Tiết kiệm tài nguyên hệ thống để tạo và hủy luồng. Vì quản lý luồng nằm hoàn toàn ở vùng nhớ của user, chi phí để tạo luồng được xác định bằng chi phí để cấp phát vùng nhớ được tạo 1 stack các luồng
- VIệc chuyển ngữ cảnh được thực hiện nhanh. Thực tế việc chuyển ngữ cảnh được thực hiện khi 2 luồng đồng bộ hóa
- Nhược điểm:
- Lời triệu gọi của lời gọi hệ thống dừng sẽ làm dừng toàn bộ tiến trình chứa luồng đó và tất cả các luồng khác do tiến trình đó sinh ra
Xây dựng luồng kiểu nhân (Kernel mode)
- Ưu điểm:
- Vấn đề bị dừng tiến trình ở trên được giải quyết ở hướng tiếp cận này tuy nhiên chi phí rất lớn.
- Nhược điểm:
- Mỗi thao tác với luồng như tạo, hủy, đồng bộ sẽ được đảm nhiệm bởi nhân và cần 1 lời gọi hệ thống => gây tốn kém chi phí
- Việc chuyển ngữ cảnh luông trở nên tốn kém tài nguyên hệ thống như việc chuyển ngữ cảnh tiến trình => các lơi ích về hiệu năng khi sử dụng đa luồng không còn
=> Do đó cần xây dựng hệ thống tận dụng ưu điểm của cả 2 phương pháp này => tiến trình nhẹ (lightweight processes) được sinh ra
Các tiến trình nhẹ (Lightweight processes)
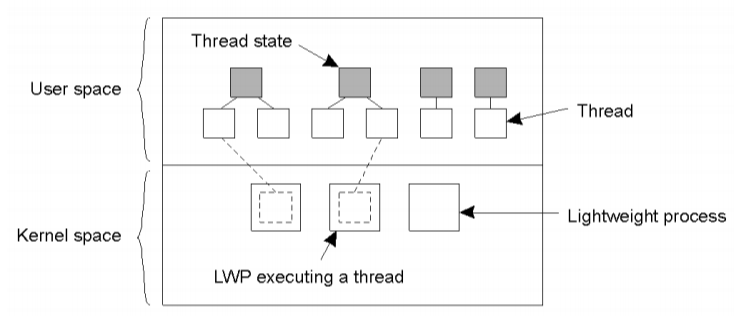
Viêc sử dụng tiến trình nhẹ là sự kết hợp của việc chạy đa luồng ở chế độ người dùng và nhân.
- Với cơ chế này khi chạy ngữ cảnh ở 1 tiến trình đơn và mỗi tiến trình đơn có nhiều tiến trình nhẹ.
- Ngoài việc có nhiều tiến trình nhẹ, hệ thống cung cấp gói luồng ở mức user, trợ giúp các ứng dụng về việc tạo và hủy luồng. Gói cũng cung cấp phương tiện để đồng bộ hóa các luồng.
- Vì việc sử dụng gói luồng hoàn toàn ở tầng user do đó các thao tác với luồng không cần can thiệp của tầng kernel => giảm nhiều chi phí
- Gói luồng có routing duy nhất là lập lịch cho luồng kế tiếp
- Khi 1 tiến trình nhẹ được tạo ra vs 1 stack, nó sẽ tìm luồng phù hợp để thực thi.
- Mỗi tiến trình nhẹ giữ 1 bảng luồng để tránh việc cùng dùng 1 luồng. Việc tránh truy cập cùng lúc vào dữ liệu chia sẻ được đảm đương hoàn toàn bởi mức người dùng
- Việc đồng bộ giữa các tiến trình nhẹ không cần mức kernel. Nếu 1 luồng bị dừng nó sẽ thực hiện lời gọi lập lịch. Khi 1 luồng khả chạy khác được tìm thấy nó sẽ chuyển ngữ cảnh sang cho luồng mới đó và tiến trình nhẹ đang chạy luồng đó hoàn toàn không biết việc chuyển ngữ cảnh
- Khi 1 luồng thực hiện 1 lời gọi hệ thống dừng, việc thực thi được chuyển xuống cho kiểu nhân nhưng vẫn ở trong ngữ cảnh của tiến trình nhẹ hiện tại. HĐH sẽ chuyển ngữ cảnh sang cho tiến trình nhẹ khác, dẫn tới việc chuyển ngữ cảnh chuyển ngược lại về cho kiểu người dùng. => lời gọi hệ thống dùng không làm dừng cả hệ thống lại
Ưu điểm
- Các thao tác với luồng có chi phí thấp và hoàn toàn không có sự can thiệp của tầng nhân.
- Khi 1 tiến trình có đủ các tiến trình nhẹ, 1 lời gọi hệ thống dừng không làm dùng cả hệ thống mà chỉ làm dừng 1 tiến trình nhẹ.
- Ứng dụng không cần phải biết về các tiến trình nhẹ, nó chỉ nhìn thấy các luồng ở mức user
- Tiến trình nhẹ có thể được sử dụng trong môi trường đa vi xử lý, mỗi tiến trình nhẹ gán với 1 CPU
Nhược điểm
- Tạo và hủy các tiến trình nhẹ chi phí cao vì ở tầng nhân. Tuy nhiên việc này diễn ra không thường xuyên
Mọi người có thể hiểu tóm gọn lại như sau:
- 1 tiến trình sinh ra nhiều tiến trình nhẹ
- 1 tiến trình nhẹ được gán với nhiều luồng
- Khi 1 luồng có thao tác vào ra tiến trình nhẹ tương ứng bị treo, tuy nhiên các tiến trình nhẹ khác vẫn tiếp tục được thực hiện
2. Luồng trong các hệ thống phân tán
Server đơn luồng
- Là tiến trình server chỉ sinh ra 1 luồng duy nhất để xử lý các việc và y/c từ client gửi đến
- Do chỉ có duy nhất 1 luồng nên:
- Chỉ xử lý được một yêu cầu tại một thời điểm
- Các yêu cầu chỉ có thể được xử lý tuần tự
- Các yêu cầu có thể được xử lý bởi các tiến trình khác nhau
- Các yêu cầu có thể được gửi đến các server khác nhau
- Không đảm bảo tính trong suốt, nếu các việc gửi lên chưa được xử lý kịp và đang phải xếp trong hàng đợi sẽ kiến người dùng không cảm nhận được sẹ trong suốt của hệ thống
=> cần dùng đến server đa luồng
Client và server đa luồng
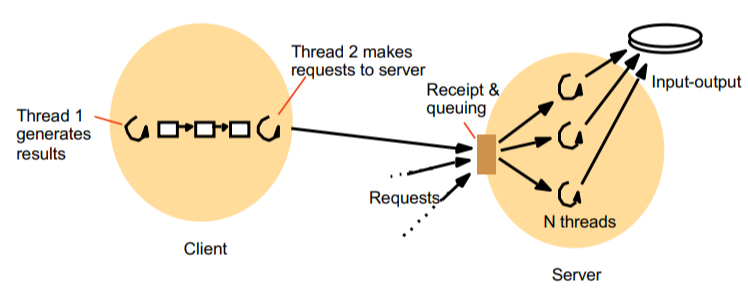
Mỗi tiến trình client và server sẽ có nhiều luồng để xử lý các công việc. Mình lấy ví dụ ở hình vẽ trên nhé!
- Ở tiến trình Client sẽ có 1 luồng chuyên sinh ra các gói tin y/c, luồng khác lo việc đóng gói gói tin và gửi đi cho server
- Ở phía server có 1 luồng chuyên lo thu nhận các gói tin và xếp chúng vào hàng đợi. Sau đó gửi chúng đi các luồng khác chuyên xử lý thông điệp. Các luồng này sẽ trực tiếp làm việc với các module vào ra
=> Việc sử dụng cơ chế đa luồng giúp cho việc trao đổi thông tin giữa client và server có thể tiến hành song song với các công việc xử lý thông tin khác => tăng tốc độ và hiệu năng hệ thống.
Qua đó ta có thể biết chức năng chính của 1 server đa luồng:
- Nhận các y/c do 1 luồng có nhiệm vụ thu nhận y/c của client và gửi vào các luồng xử lý, nếu không có đủ luồng xử lý sẽ xếp y/c vào hàng đợi
- Xử lý y/c do luồng xử lý y/c đảm nhiệm, luồng này xử lý các y/c bao gồm cả những module vào ra
- Gửi trả lời cho client
Mô hình server có điều phối
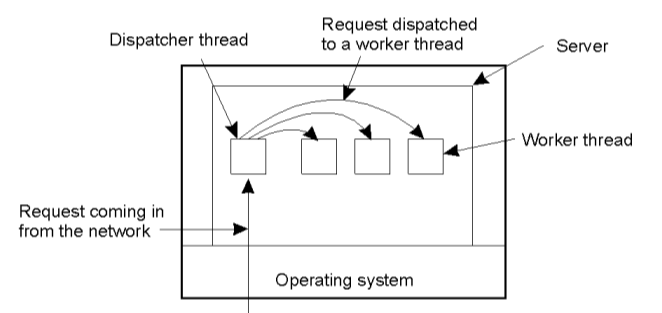
Trong mô hình này ngoài các luồng để xử lý các công việc, tiến trình server có 1 luồng chuyên dụng đảm nhiệm chức năng điều phối các công việc y/c gọi là Dispatcher.Mỗi khi nhận được y/c luồng này sẽ phân tích y/c đó và gửi đến cho luồng phù hợp để xử lý
Với mô hình đa luồng này các luồng sẽ hoạt động hiệu quả hơn với việc mỗi luồng sẽ chuyên xử lý các công việc chuyên biệt do luồng điều phối phân loại và gửi đến
Một số kiến trúc tổ chức Server đa luồng thông dụng
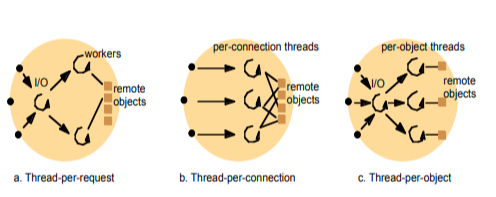
a) Thread-per-request (Luồng cho mỗi y/c)
- Tiến trình vào ra sinh ra 1 luồng worker mới cho mỗi y/c nhận được
- Mỗi luồng sẽ tự hủy sau khi hoàn thành nhiệm vụ
- Ưu điểm:
- Không cần có hàng đợi vì mỗi y/c gửi đến đều được sinh ra 1 luồng và xử lý ngay
- Băng thông có thể đạt mức tối đa vì có khả năng sinh không giới hạn các luồng của worker
- Nhược điểm: việc tạo, hủy luồng trong mỗi request nhận được, đặc biệt trong trường hợp có quá nhiều y/c gửi đến thì overhit của các thao tác hủy và tạo luồng sẽ rất cao làm giảm hiệu năng và làm tăng chi phí các hoạt động của hệ thống
b) Thread-per-connection (Luồng cho mỗi kết nối)
- Gắn kết mỗi luồng với 1 kết nối. Khi 1 client y/c kết nối đến với server, server sẽ tạo ra 1 luồng cho kết nối đó và hủy luồng nếu kết nối đó ngắt
c) Thread-per-object (Luồng cho mỗi đối tượng)
- Tiến trình gắn 1 luồng với 1 đối tượng từ xa (remote object) mà mình quản lý.
- Với kến trúc này luồng I/O phải quản lý thêm hàng đợi cho mỗi object
Ưu điểm của kiến trúc b) và c): Không tốn nhiều overhit vì không phải tạo và hủy nhiều luồng do số lượng đối tượng kết nối và đối tượng từ xa là không thay đổi nhiều
Nhược điểm: Các client có thể bị phục vụ với độ trễ cao do, trong khi 1 số luồng thì phục vụ quá nhiều y/c 1 số luồng khác thì không có việc để làm
Mô hình máy trạng thái hữu hạn
Chỉ có 1 luồng nhận request từ các client. Khi nhận 1 thông điệp nếu trong bộ đệm còn chỗ thì nhận và thực hiện luôn, nếu không đủ chỗ thì không dừng tiến trình mà gửi vào đĩa cứng. Tiếp đó ghi thông tin trạng thái vào 1 bảng sau đó tiếp tục đi nhận thông điệp khác. Thông điệp nếu là công việc mới thì thực hiện luôn còn nếu là câu trả lời của đĩa thì lấy thông tin phù hợp từ bảng và thực hiện gửi trả lời cho client
Đặc diểm của mô hình
- Các y/c từ client và xử lý được sắp hàng
- Tại một thời điểm server thực hiện thao tác trong hàng
- Không cần đa luồng
- Các lời gọi xử lý là các lời gọi “không dừng”
- VD: Node.js
- Bất đồng bộ và hướng sự kiện
- Đơn luồng nhưng khả năng co giãn cao
Đến đây chúng ta tổng kết lại 1 chút về các mô hình ở trên nhé
| Mô hình | Đặc điểm |
|---|---|
| Đơn luồng | Không có cơ chế xử lý song song, lời gọi hệ thống dừng |
| Đa luồng | Có cơ chế xử lý song song, lời gọi hệ thống dừng |
| Máy trạng thái hữu hạn | Có cơ chế xử lý song song, lời gọi hệ thống không dừng |
Client đa luồng
- Tách biệt giao diện người dùng và xử lý: mỗi ứng dụng có giao diện người dùng luôn có 2 luồng, công việc chính là hiển thị giao diện người dùng và việc xử lý bên trong => tăng tốc độ sử dụng hệ thống nhờ đó che giấu được độ trễ của thời gian phục vụ.
- Tăng tốc độ khi làm việc với nhiều server khác nhau: ứng với mỗi server tiến tình client sinh ra 1 luồng để xử lý công việc tương ứng với server đó. Cụ thể: thiết lập kết nối, nhận gửi gói tin
- Che giấu các chi tiết cài đặt: các việc này thực hiện bằng cách dành 1 luồng để phục vụ giao diện người dùng, các luồng khác thực hiện các thao tác cài đặt cần thiết
II. Ảo hóa
1. Vai trò của ảo hóa
- Ở những năm 1970s, khi giá thành các máy mainframe cao, ảo hóa đóng vai trò mô phỏng phần cứng thay vì phát triển lại phần mềm
- Khi giá thành phần cứng hạ, ảo hóa giúp cho việc sử dụng tối ưu hơn tài nguyên phần cứng
- Khi tốc độ thay đổi phần cứng nhanh nảy sinh vấn đề là nhiều phần mềm không được hỗ trợ đủ, lúc đó cần đến ảo hóa
- Giuos cho nguwoif dùng dễ dàng quản trị các ứng dụng phần mềm
Khái niệm ảo hóa
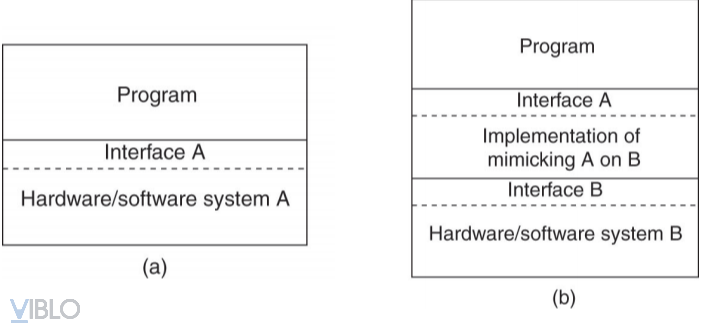
- Hình a): Mô hình hoạt động của 1 hệ thống thông thường với việc sử dụng giao diện như 1 tầng trung gian giữa các chương trình ứng dụng và tầng dưới là hệ thống phần cứng A và phần mềm A. Tàng giao diện này cung cấp các phương thức được triển khai ở tầng hệ thống A bên dưới, tầng chương trình ở trên chỉ việc sử dụng giao diện này để gọi các phương thức đó
- Hình b): Khi đem cùng những chương trình kèm theo giao diện A sang 1 hệ thống khác (hệ thống B), lúc này cần 1 tầng trung gian để mô phỏng sự triển khai của hệ thống A trên hệ thống B. Cụ thể là triển khai các phương thức hệ thống A bằng các gọi phương thức tương ứng của hệ thống B mà giao diện B cung cấp. Tâng trung gian này mô phỏng ý tưởng của thực hiện ảo hóa (giả lập môi trường làm việc của hệ thống này trên môi trường làm việc của hệ thống khác)
2. Các kiến trúc máy ảo
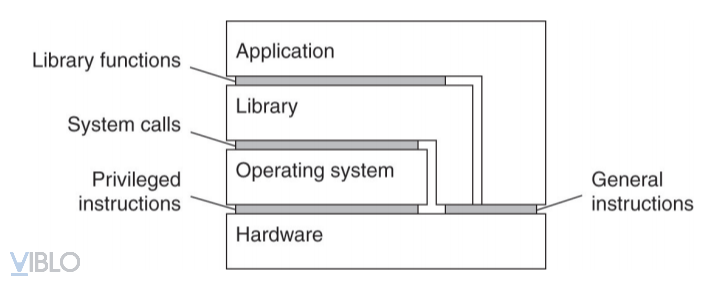
- Giao diện giữa phần cứng và phần mềm bao gồm các tập lệnh máy có thể được gọi ở bất cứ chương trình nào
- Giao diện giữa phần cứng và phần mềm bao gồm các tập lệnh máy chỉ có thể được gọi các chương trình đặc quyền, ví dụ như HĐH
- Giao diện bao gồm các lời gọi hệ thống (system call) được cung cấp bởi HĐH
- Giao diện bao gồm các lời gọi thư viện, API
III. Di trú mã
1. Vì sao phải di trú mã
Di trú 1 tiến trình đang chạy là rất tốn kém và phức tạp. Tuy nhiên di trú mã có 2 tác dụng lớn: hiệu năng và độ mềm dẻo trong thiết kế hệ thống
- Về hiệu năng: giảm thiểu các trao đổi thông tin
- Truyền mã client cho server: trong 1 hệ thống client-server và server quản lý 1 csdl lớn. Nếu 1 client muốn thực hiện các câu lệnh csdl nhiều lần thì tốt hơn là truyền 1 phần ứng dụng của client sang server. Ở đây ứng dụng chạy nhiều lần truy vấn và chỉ gửi kết quả trả về sau khi đã thực hiện xong => giúp tiết kiệm tài nguyên hệ thống bằng việc giảm thiểu các kết nối và gửi thông tin qua mạng
- Truyền mã server cho client: với các ứng dụng csdl tương tác, người dùng phải nhập 1 form sau đó chuyển thành 1 chuỗi các thao tác csdl nhỏ lẻ hoặc việc kiểm tra form ở phía server sẽ dẫn tới 1 loạt các thao tác gửi thông điệp qua lại giữa client và server với mục đích người dùng chỉnh sửa form. Giải pháp là thực hiện xử lý form ở phía client bằng đoạn code của server sau đó gửi form đầy đủ về cho server
- Thực hiện song song một code trên nhiều máy: khi muốn thực hiện tìm kiếm trên web cách đơn giản là triển khai 1 đoạn truy vấn tìm kiếm trong form của 1 chương trình di động nhỏ gọi là toán tử di động (mobile agent) di chuyển từ side này sang side khác
- Về đặc tính mềm dẻo:
- Tải stub động: khi client muốn truy cập từ xa vào hệ thống file, để cho phép client truy cập vào csdl server cung cấp 1 giao thức độc quyền. Sự triển khai của giao diện hệ thống file ở phía client là dựa trên giao thức độc quyền đó và giao diện đó gắn với ứng dụng client
- Cấu hình động hệ thống: khi server cung cấp mã triển khai cho client chỉ khi thực sự cần. Khi kết nối tới server, client chủ động tải triển khai về trải qua 1 vài bước ban đầu rồi thực hiện lời gọi server. Giao thức để tải và khởi tạo các mã phải là giao thức chuẩn
2. Mô hình di trú mã
DI trú mà là dịch chuyển chương trình giữa các máy , mục đích là để các chương trình chạy ở máy đích, trong vài trường hợp phải chuyển tình trạng đang chạy của chương trình, tín hiệu phát đi và các thành phần khác của môi trường
Một tiến trình bao gồm ba yếu tố:
- Mã (Code segment) : gồm các tập lệnh của tiến trình.
- Tài nguyên (Resource segment) : chứa các tham số tới các tài nguyên mà tiến trình cần.
- Trạng thái (Execution segment): chứa các trạng thái thực thi hiện hành của tiến trình như dữ liệu, bộ đếm, stack...
Các kiểu di trú mã
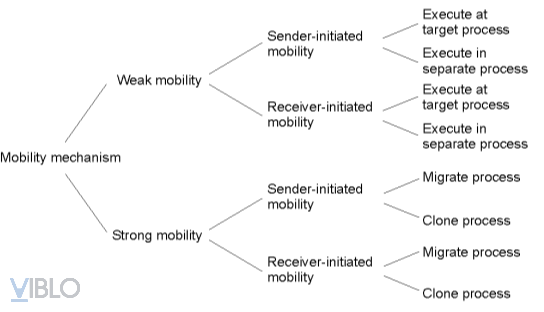
-
Di trú mã yếu (weak mobility): chỉ có thành phần Code Segment cùng với một số tham số khởi động được di trú.
- Đặc điểm của mô hình này là chương trình được di chuyển luôn luôn được khởi tạo từ một trong các vị trí bắt đầu được định nghĩa trước. Ví dụ như Java applets, nó luôn được bắt đầu thực thi ngay từ đầu.
- Lợi ích của mô hình này là tính đơn giản của nó. Nó chỉ đòi hỏi phía máy đích có khả năng thực thi đoạn mã nguồn đó, ý tưởng chính của nó chỉ là làm cho đoạn code có khả năng di động.
-
Di trú mã mạnh (Strong Mobility) : Cả ba thành phần của tiến trình đều được di chuyển.
- Đặc điểm của mô hình là một tiến trình đang chạy có thể được tạm dừng hoạt động, sau đó, nó được di chuyển tới một máy khác, rồi sau đó lại tiếp tục hoạt động của mình ở chính vị trí mà nó đã dừng lại ở thời điểm trước.
-
Sender-initiated: di trú được khởi tạo ở máy đang chứa mã đó
-
Receiver-initiated: khởi đầu cho mã di trú được bắt đầu bằng máy đích
Trên đây là một số khái niệm cơ bản về tiến trình và luồng để giúp mọi người có cái nhìn tổng quan về tiến trình và luồng cũng như cách tổ chức, cách quản lý chúng như thế nào.
Phần tiếp theo của chuỗi series này sẽ là phần Trao đổi thông tin trong hệ phân tán. Mong mọi người đón đọc nhé
Thanks for reading
Tài liệu tham khảo: Bài giảng Hệ phân tán - ĐHBKHN
All rights reserved
