[NVIDIA Tools] Bài 6: Global Memory Coalescing
Bài đăng này đã không được cập nhật trong 2 năm
Global memory là bộ nhớ lớn nhất NHƯNG cũng là chậm nhất ở GPU vậy nên ở bài viết này chúng ta sẽ phân tích những yếu tố nào dẫn đến "low performance" cũng như cách khác phục chúng
Trước khi đọc bài viết này hãy xem qua những bài viết này để nắm rõ hơn: Các bộ nhớ trong GPU - Sử dụng các bộ nhớ trong GPU
Global Memory Coalescing
Trước khi đi vào bài học mình sẽ lấy 1 ví dụ:
Bạn có 1 nhiệm vụ là phân phát số bánh, số kẹo cho các bạn trẻ ( 1 lưu ý là mỗi bạn trẻ sẽ có 1 sở thích khác nhau ).Thay vì đợi tới phiên các bạn trẻ lên nhận đồ và hỏi thích cái gì thì sẽ rất lâu và tốn thời gian ( tốn thời gian trong việc hỏi và lấy món đồ tương ứng ) thì trước khi phát đồ chúng ta sẽ quy định bạn nào chọn bánh thì đứng bên trái, kẹo thì đứng bên phải và lúc này chúng ta sẽ tối ưu hơn trong việc phát đồ.
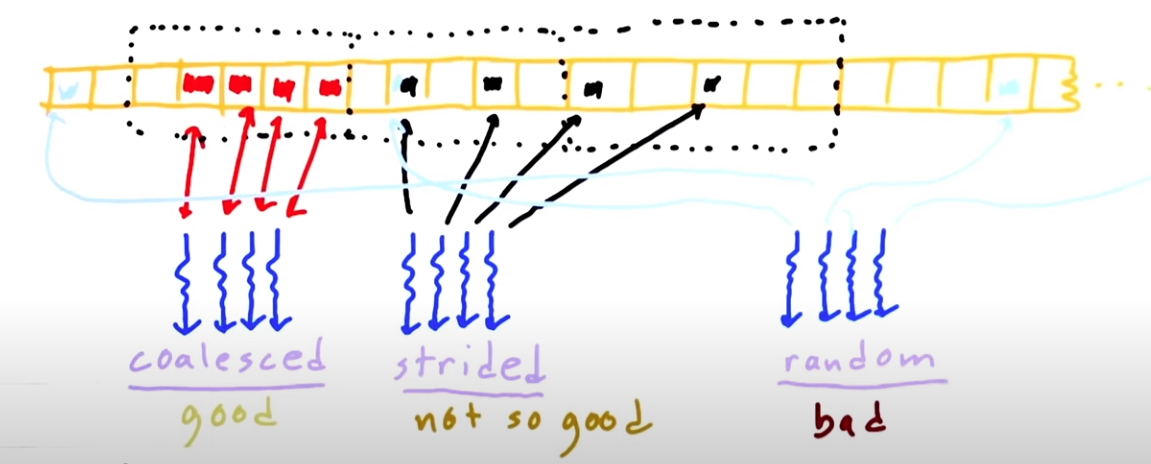
Khi nhắc đến việc truy cập global memory chúng ta thường thấy 3 khái niệm:
- Coalescing: là quá trình truy cập bộ nhớ 1 cách đồng thời của các thread trong cùng 1 warp, giúp tối ưu hóa việc truy cập bộ nhớ bằng cách giảm thiểu số lần truy cập cần thiết và tăng tốc độ truyền dữ liệu ( giống như việc phát bánh kẹo, thay vì đợi tới phiên rồi mới hỏi thì đây không cần hỏi cũng biết sẽ phát gì ==> hit cache )
- Alginment: liên quan đến việc sắp xếp dữ liệu trong bộ nhớ một cách tối ưu để đảm bảo rằng các truy cập bộ nhớ được thực hiện một cách hiệu quả nhất, giảm thiểu việc đọc dữ liệu không cần thiết và tăng cường hiệu suất xử lý ( giống như việc bạn phân chia bánh thì đứng bên trái, kẹo thì đứng bên phải ==> giúp chúng ta không bị nhẫm lẫn khi trong việc lấy bánh hay lấy kẹo để phát )
- Sector: đề cập đến đơn vị cơ bản của bộ nhớ mà có thể được truy cập đồng thời trong một lần truy cập, giúp định rõ phạm vi và cách thức mà dữ liệu được lấy ra hoặc ghi vào bộ nhớ
Tuy là 3 nhưng lại chung 1 mục đích là tối ưu trong việc truy cập 1 bộ nhớ lớn
Tóm lại: coalescing là quá trình truy cập sao cho tối ưu nhất (số lần truy cập càng bé càng tốt) còn alignment là sắp xếp dữ liệu 1 cách tối ưu nhất còn sector là đơn vị của mỗi lần truy cập

Code
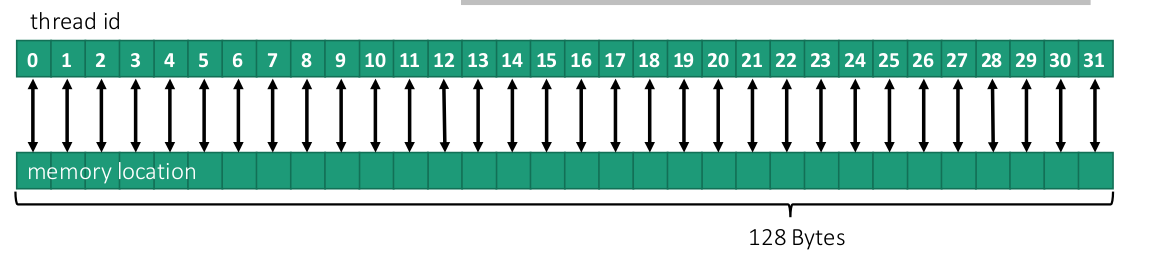
Mình sẽ demo 1 đoạn code đơn giản 32 dùng block ( 32 threads / block ) và elements(số phần tử) = 1024
Coalescing
__global__ void testCoalesced(int* in, int* out, int elements)
{
int id = blockDim.x * blockIdx.x +threadIdx.x;
out[id] = in[id];
}
Và chúng ta sẽ profiling đoạn code trên:
global load transactions per request: càng bé càng tốt (này là copy chunk--> check coalescing)
ncu --metrics l1tex__average_t_sectors_per_request_pipe_lsu_mem_global_op_ld.ratio ./a.out

global store transactions per request : càng bé càng tốt(này là copy chunk-- > check coalescing)
ncu --metrics l1tex__average_t_sectors_per_request_pipe_lsu_mem_global_op_st.ratio ./a.out

global load transactions: (so sánh xem kernel nào coalescing || càng bé càng tốt)
ncu --metrics l1tex__t_sectors_pipe_lsu_mem_global_op_ld.sum ./a.out

global store transactions: (so sánh xem kernel nào coalescing || càng bé càng tốt)
ncu --metrics l1tex__t_sectors_pipe_lsu_mem_global_op_st.sum ./a.out

Lý do càng bé càng tốt là vì nó giống như việc phát bánh kẹo, chúng ta thực hiện hành động đổi bánh thành kẹo và ngược càng ít thì việc phát càng nhanh ==> ở đây sector/request tức là mỗi 1 request chúng ta chỉ tốn 4 sector và tổng chỉ tốn 256 sector (load và store )
1 lưu ý là sector ở đây không phải là số phần tử được xử lí tại mỗi request mà là số lần máy tính truy cập đồng thời vào nơi lưu trữ dữ liệu để xử lí 1 request ==> số lần truy cập càng ít thì càng nhanh ( hit cache )
Mix but in cache line
__global__ void testMixed(int* in, int* out, int elements)
{
int id = ((blockDim.x * blockIdx.x +threadIdx.x* 7) % elements) %elements;
out[id] = in[id];
}

Ở đây chúng ta cũng profiling tương tự
global load transactions per request: càng bé càng tốt (này là copy chunk--> check coalescing)
ncu --metrics l1tex__average_t_sectors_per_request_pipe_lsu_mem_global_op_ld.ratio ./a.out

global store transactions per request : càng bé càng tốt(này là copy chunk-- > check coalescing)
ncu --metrics l1tex__average_t_sectors_per_request_pipe_lsu_mem_global_op_st.ratio ./a.out

global load transactions: (so sánh xem kernel nào coalescing || càng bé càng tốt)
ncu --metrics l1tex__t_sectors_pipe_lsu_mem_global_op_ld.sum ./a.out

global store transactions: (so sánh xem kernel nào coalescing || càng bé càng tốt)
ncu --metrics l1tex__t_sectors_pipe_lsu_mem_global_op_st.sum ./a.out

Như mình đã đề cập mặc dù vẫn nằm trong cache line ( tức là các thread không bị vượt quá array space ) nhưng vì nó không coalescing ( không theo thứ tự bánh xong rồi tới kẹo hoặc ngược lại ) nên dẫn tới tốn nhiều sector/request dẫn tới chậm hơn
![]()
![]()
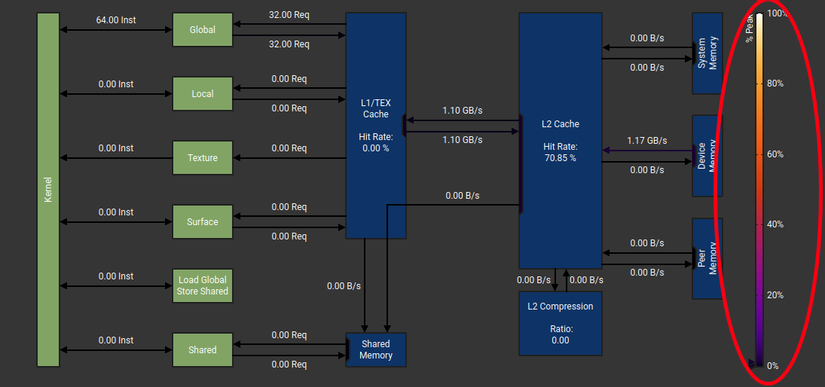
NHƯNG NẾU CÁC BẠN PROFILING FULL ( tức là in ra file .ncu-rep để dùng Nsight compute thì đây là dòng lệnh )
1 lưu ý là mình sẽ không đi quá sâu vào việc phân tích Nsight compute mà sẽ để ở bài sau
ncu --set full -o <tên file> ./a.out
Và các bạn sẽ thấy 1 điểm hơi lạ:
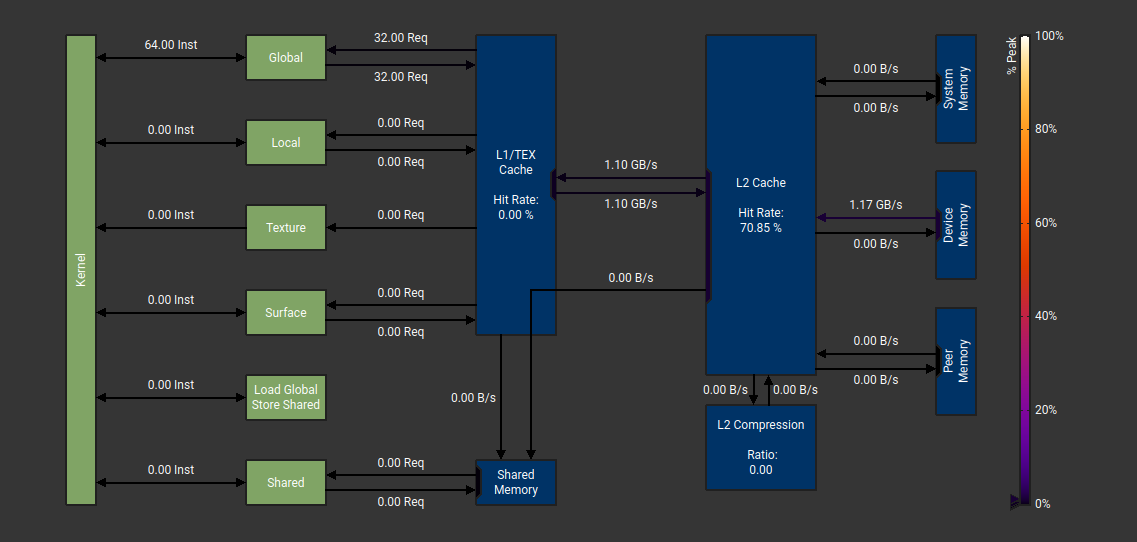
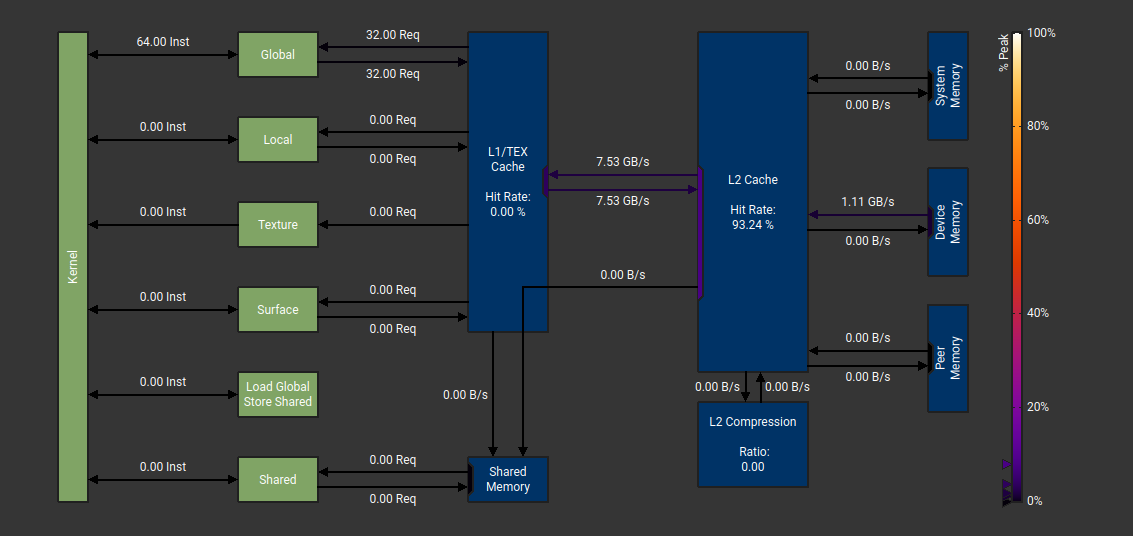
tại sao ở Coalescing throughput (GB/s ) lại bé hơn Mix và L2 cache hit rate lại thấp hơn nhưng total time lại nhanh hơn?
Ở đây ( theo mình đoán ) máy tính tự tối ưu cho chúng ta: tức là với 1 lượng byte nhất định thì sẽ tối ưu cần dùng với tốc độ transfer là bao nhiêu, không phải càng cao càng tốt vì nếu càng cao dẫn tới:
- Khi tốc độ truyền dữ liệu quá cao, có thể xảy ra tình trạng nghẽn mạng, làm giảm hiệu quả truyền dữ liệu.
- Tốc độ truyền dữ liệu cao cũng có thể tiêu tốn nhiều năng lượng hơn.
- Trong một số trường hợp, tốc độ truyền dữ liệu cao không mang lại lợi ích đáng kể, ví dụ khi truyền tải các tập tin nhỏ.
Giống như việc mua sắm vậy, không phải cứ đắt nhất là tốt nhất mà đôi khi còn phụ thuộc vào nhu cầu của mình
Vậy nên khi dùng nhiều GB/s dẫn tới hit rate sẽ cao
Tóm lại: Ở bài viết này các bạn đã biết cách để phân tích cũng như tối ưu khi sử dụng global memory ( và theo mình tìm hiểu thì 4 sector/request là tốt nhất ==> tức là chúng ta đạt được coalescing khi sector/request = 4 )
Bài tập
- Hãy code thử trường hợp offset và profiling nó
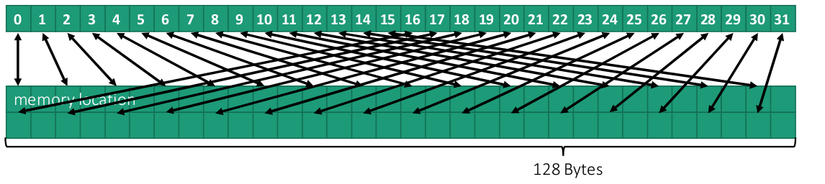
Ở bức ảnh trên là offset = 2 và khi có offset dẫn tới out of cache line ( tức là thay vì tốn 1024 * 4 bytes (vì là int ) cho 1 cái array thì ở đây chúng ta tốn 1024 * 2 * 4 bytes )
- 1 Câu hỏi thú vị: (CHÚNG TA VẪN DÙNG GLOBAL MEMORY) mặc dù là coalescing nhưng chúng ta vẫn có thể cải tiến, vậy thì trước khi cải tiến thì nguyên nhân khiến nó chậm là do đâu ?
Gợi ý:
- memory bound ( chưa sử dụng hết khả năng của máy tính )
- kiểu dữ liệu int ( 4 bytes ) và int4 ( 16 bytes )
Code mình sẽ để ở đây
All rights reserved
