[NVIDIA Tools] Bài 7:Warp Scheduler
Bài đăng này đã không được cập nhật trong 2 năm
Ở trong bài Synchronization - Asynchronization mình có nhắc đến khái niệm latency hiding, một khái niệm rất thường thấy khi nhắc về cuda và khi nói đến latency hiding là sẽ nói đến always keep thread busy, vậy nên ở bài viết này mình sẽ giải thích rõ hơn về khái niệm này cũng như cơ chế hoạt động của nó - có thể nói không thể thiếu cơ chế này vì nó giúp ích chúng ta rất nhiều trong việc tối ưu code
Bài viết này mục đích là giúp các bạn hiểu rõ hơn về cơ chế hoạt động của cuda vậy nên sẽ khá quan trọng trong series NVIDIA Tools nhưng nếu bạn chỉ quan tâm đến việc code cuda ở mức độ cơ bản thì các bạn có thể bỏ qua bài viết này
Warp Scheduler
Trước khi vào bài học thì mình sẽ lấy ví dụ để các bạn dễ hình dung hơn:
Giả sử có 100 người tới bưu điện để gửi hàng và chỉ có 1 người làm việc, và để gửi hàng thành công bạn phải thực hiện 2 bước: điền đơn thông tin gửi hàng ( tốn nhiều thời gian ) - nhân viên xác nhận đơn và thực hiện thủ tục gửi hàng ( khá nhanh ). Ở đây người nhân viên thay vì cứ đợi từng người điền đơn xong để làm thủ tục thì tới lượt người nào sẽ được phát đơn và ra chỗ khác điền, và khi điền xong quay lại hàng chờ ==> nhanh hơn rất nhiều so với việc đợi từng người 1 điền đơn xong.
Ở đây máy tính cũng vậy, giả sử ta có bài toán: y[i] += x[i] * 3 thì máy tính cũng phải thực hiện 2 bước:
- Memory instruction: time between load/store operation being issue and data arriving at its destination
- Arithmetic instruction: time an arithmetic operation start to its output
Ở đây mình xin phép dùng tiếng anh nhưng các bạn có thể hiểu đơn giản là cũng cần 2 quy trình: đầu tiên là load/store data lên memory mà mình muốn xử lí ( khá lâu ) tiếp đến là tính toán cho tới khi ra được output
Quay lại ví dụ y[i] += x[i] * 3 , thay vì máy tính phải đợi load/store x[0] và y[0] thì máy tính sẽ chuyển qua load/store x[1] và y[1] rồi cứ tiếp tục cho đến khi x[0] và y[0] load/store xong mới quay về để tính toán
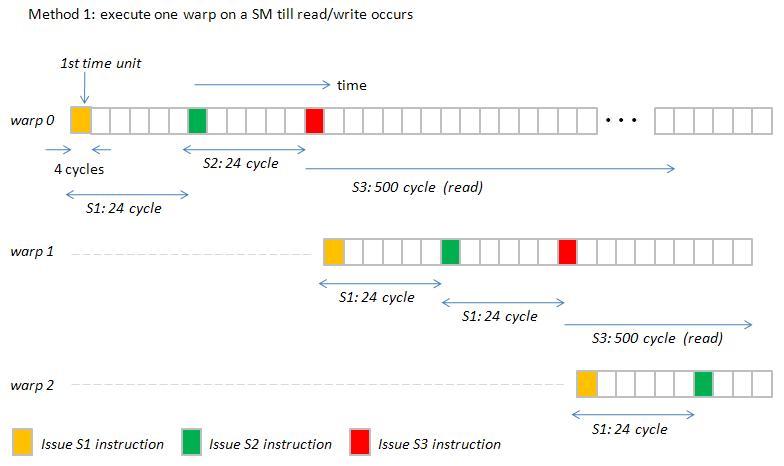
Cách 1
Cách 2
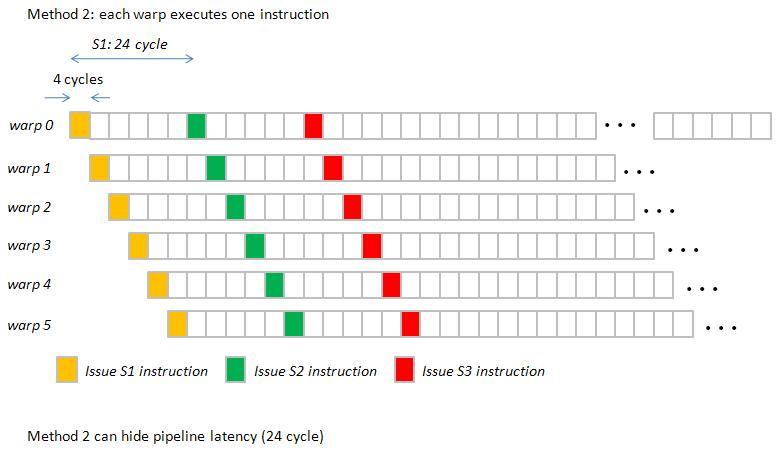
Tóm lại Warp Scheduler sẽ thực hiện hành động swap các warp đang bận để tiết kiệm thời gian nên người ta hay gọi là latency hiding hoặc always keep threads busy ( tùy vào mỗi máy mà 1 Warp Scheduler có thể điều khiển 1 số lượng warp nhất định )
Nếu các bạn thấy ví dụ trên giống với ví dụ phát bánh kẹo ở bài Cách thức hoạt động của máy tính thì các bạn đúng rồi đó
Khi nói đến warp chúng ta sẽ luôn thấy 3 trạng thái của warp:
- stalled: warp đang bận thực thi 1 thứ gì đó
- eligible: warp đang rãnh và sẵn sàng tham gia
- selected: warp được chọn để thực thi
Có thể hiểu là warp sau khi được selected thì sẽ vô thực thi Memory instruction và trong thời gian đợi thì sẽ được swap qua warp khác, ở đây sẽ có 2 tình huống là warp tiếp đó stalled hoặc eligible, nếu eligible thì sẽ tuyệt vời còn nếu là stalled thì sẽ được swap tiếp cho đến khi gặp được warp eligible
Câu hỏi đặt ra: Nếu vậy chúng ta chỉ cần tạo ra nhiều warp thì số lượng eligible sẽ tăng lên ?
Nếu bạn cũng nghĩ như vậy thì sai nha, tạo ra nhiều warp đồng nghĩa với việc warp scheduler sẽ thực hiện nhiều hơn và khi tạo ra nhiều warp ( tức là nhiều thread ) dẫn tới số lượng register của mỗi thread ít đi ==> khiến SM chạy chậm ==> chúng ta phải cân nhắc đến việc sử dụng bao nhiêu thread thì phù hợp ?
Nếu các bạn nghĩ có 128 người tới gửi thư thì chúng ta sẽ dùng 128 người nhân viên thì sai nha, cũng giống như nếu chúng ta cần xử lí 1 array 128 phần tử mà dùng 128 thread ( 4 warp ) là sai lầm
Lý do: tốn tài nguyên và ngày nay máy tính chúng ta rất rất mạnh, tức là 1 nhân viên có thể cùng 1 lúc xử lí cho 2 người mà chúng ta chỉ cho họ xử lí 1 người tại 1 thời điểm thì hơi phí ==> 1 thread xử lí 2 phần tử ===> giảm số lượng thread khởi tạo ==> tăng register cho mỗi thread + giảm bớt công việc cho warp scheduler
Cũng vì lý do đó mà khi các bạn profile các đoạn code opencv cuda bằng nsight system sẽ thấy họ dùng rất ít thread
Đây là 1 ví dụ sử dụng thư viện opencv cuda để cộng 2 bức ảnh
#include "opencv2/opencv.hpp"
#include <opencv2/cudaarithm.hpp>
cv::Mat opencv_add(const cv::Mat &img1, const cv::Mat &img2)
{
cv::cuda::GpuMat d_img1, d_img2, d_result;
d_img1.upload(img1);
d_img2.upload(img2);
cv::cuda::add(d_img1, d_img2, d_result);
cv::Mat result;
d_result.download(result);
return result;
}
int main()
{
cv::Mat img1 = cv::imread("circles.png");
cv::Mat img2 = cv::imread("cameraman.png");
cv::Mat result = opencv_add(img1, img2);
cv::imshow("Result", result);
cv::waitKey();
return 0;
}
Và các bạn profile bằng nsight system để xem kernel nó bằng lệnh:
nsys profile -o test ./a.out

Câu hỏi đặt ra: vậy chúng ta dùng bao nhiêu thread là phù hợp?
==> Tùy thuộc vào cấu hình của mỗi máy tính cũng như những nguyên nhân khiến warp stalled mà chúng ta lựa chọn, ở bài sau mình sẽ phân tích những nguyên nhân khiến warp stalled cũng như cách xác định số lượng thread phù hợp
All rights reserved
