[NVIDIA Tools] Bài 4: NVIDIA Compute Sanitizer Phần 1
Bài đăng này đã không được cập nhật trong 2 năm
Ở bài viết này mình sẽ hướng dẫn các bạn sử dụng NVIDIA Compute Sanitizer, 1 công cụ rất tuyệt vời để hỗ trợ cho các bạn mới bắt đầu về cuda
Đối với các bạn đã quá quen thuộc về cuda thì NVIDIA Compute Sanitizer không giúp ích được mấy nhưng dù sao biết vẫn hơn không
NVIDIA Compute Sanitizer
NVIDIA Compute Sanitizer giúp chúng ta check 4 lỗi quan trọng mà các cuda beginner hay mắc phải:
- Memcheck for memory access error and leak detection
- Racecheck, a shared memory data access hazard detection tool
- Initcheck, an uninitialized device global memory access detection tool
- Synccheck for thread synchronization hazard detection
Đây là 1 đoạn code đơn giản ( cộng 2 vector) để phân tích 4 trường hợp
#include <stdio.h>
__global__ void vectorAdd(int *a, int *b, int *c, int n) {
int tid = blockIdx.x * blockDim.x + threadIdx.x;
c[tid] = a[tid] + b[tid];
}
int main() {
int n = 10;
int *a, *b, *c;
int *d_a, *d_b, *d_c;
int size = n * sizeof(int);
a = (int*)malloc(size);
b = (int*)malloc(size);
c = (int*)malloc(size);
for (int i = 0; i < n; i++) {
a[i] = i;
b[i] = i;
}
cudaMalloc((void**)&d_a, size);
cudaMalloc((void**)&d_b, size);
cudaMalloc((void**)&d_c, size);
cudaMemcpy(d_a, a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, size, cudaMemcpyHostToDevice);
vectorAdd<<<1, ?>>>(d_a, d_b, d_c, n);
cudaMemcpy(c, d_c, size, cudaMemcpyDeviceToHost);
free(a);
free(b);
free(c);
return 0;
}
Khi mới bắt đầu code cuda, các bạn sẽ mắc vào 1 lỗi cơ bản là sử dụng thread ít/nhiều hơn data và điều này sẽ dẫn tới 1 bug “undefined behavior”, Nó có thể hoạt động mà không có báo lỗi. Trong một chương trình lớn hơn, nó có thể gây ra các vấn đề về logic và nghiêm trọng ảnh hưởng đến việc phân bổ các memory khác
Initcheck
Ở đây mình sẽ ví dụ cụ thể
vectorAdd<<<1, ?>>>(d_a, d_b, d_c, n)--> vectorAdd<<<1, 9>>>(d_a, d_b, d_c, n)
Như các bạn có thể thấy, chúng ta có N = 10 nhưng chỉ dùng 9 thread để xử lí và việc này dẫn đến leak memory, và chúng ta sẽ dùng câu lệnh này để profile
compute-sanitizer --tool initcheck --track-unused-memory yes --show-backtrace no
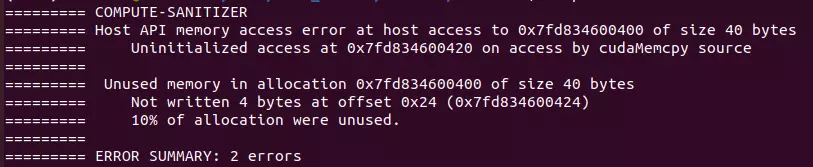 Chúng ta dùng N =10 (int) nên tổng byte là 40 bytes và sử dụng 9 thread ==> còn dư 10% memory không được sử dụng
Chúng ta dùng N =10 (int) nên tổng byte là 40 bytes và sử dụng 9 thread ==> còn dư 10% memory không được sử dụng
Và đây là kết quả khi ta sửa lại thành dùng 10 thread

Memcheck
Ở phía trên là trường hợp sử dụng thread ít hơn thì bây giờ chúng ta đến trường hợp thread nhiều hơn
vectorAdd<<<1, ?>>>(d_a, d_b, d_c, n)--> vectorAdd<<<1, 11>>>(d_a, d_b, d_c, n)
Như các bạn có thể thấy, chúng ta chỉ khởi tạo đủ cho 10 thread hoạt động ==> dẫn tới thread thứ 11 sẽ bị threads out-of-bounds array access và chúng ta sẽ dùng câu lệnh này để profile
compute-sanitizer --tool memcheck --show-backtrace no

Để giải thích đơn giản là khi chúng ta dùng cudaMemcpy để copy qua GPU thì phần tử thứ 11 sẽ bị fail vì khi khởi tạo chỉ đủ cho 10 phần tử ==> và việc fail này là thread(10,0,0 ) tức là thread thứ 11 sẽ bị nằm ngoài rìa dẫn đến “undefined behavior”
Các khắc phục là chúng ta chỉnh về dùng 10 thread hoặc thêm boundary
if (tid < n) {
c[tid] = a[tid] + b[tid] ---> c[tid] = a[tid] + b[tid];
}
Và đây là kết quả

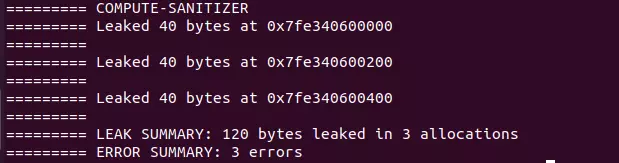
Ngoài ra nếu các bạn để ý thì đoạn code này chúng ta thiếu cudaFree nên cũng sẽ dẫn tới leak memory và chúng ta sẽ dùng câu lệnh này để profile
compute-sanitizer --tool memcheck --leak-check=full --show-backtrace no
2 lỗi còn lại ( Synccheck - Racecheck) mình sẽ nói sau khi hết bài atomic function và data hazard
All rights reserved
