Machine Learning Cơ bản || Lesson 01: Sơ lược về Machine Learning
Bài đăng này đã không được cập nhật trong 3 năm
Sơ lược về Machine Learning (ML)
1) Định nghĩa về ML:
Arthur Samuel, người tiên phong của Mỹ trong lĩnh vực trò chơi máy tính và trí tuệ nhân tạo, đã đặt ra thuật ngữ “Machine Learning” vào năm 1959 khi còn ở IBM. Ông định nghĩa học máy là “lĩnh vực nghiên cứu cung cấp cho máy tính khả năng học hỏi mà không cần lập trình rõ ràng”. Tuy nhiên, không có định nghĩa nào được chấp nhận rộng rãi cho học máy. Các nhà khoa học máy tính khác nhau đưa ra các định nghĩa khác nhau. Trong đó định nghĩa được sử dụng rộng rãi: "ML là một chương trình máy tính tối ưu hóa tiêu chí hiệu suất bằng cách sử dụng các dữ liệu mẫu có sẵn và kinh nghiệm quá khứ. Chúng ta có một mô hình được xác định tối đa một số tham số và học tập là việc thực thi chương trình máy tính để tối ưu hóa các tham số của mô hình bằng cách sử dụng dữ liệu đào tạo hoặc kinh nghiệm trong quá khứ. Mô hình có thể là dự đoán để đưa ra dự đoán trong tương lai hoặc mô tả để thu thập kiến thức từ dữ liệu. Lĩnh vực nghiên cứu được gọi là học máy liên quan đến câu hỏi làm thế nào để xây dựng các chương trình máy tính tự động cải thiện theo kinh nghiệm."
1.2) Định nghĩa về việc học:
"Một chương trình máy tính được cho là học hỏi từ trải nghiệm E đối với một số loại nhiệm vụ T và phép đo hiệu suất P , nếu hiệu suất của nó ở các nhiệm vụ T, được đo bằng P , được cải thiện với trải nghiệm E."
Ví dụ:
-
Vấn đề học tập nhận dạng chữ viết tay
- Nhiệm vụ T: Nhận dạng và phân loại các từ viết tay trong hình ảnh
- Hiệu suất P : Phần trăm từ được phân loại chính xác
- Kinh nghiệm đào tạo E : Tập dữ liệu các từ viết tay với các phân loại nhất định
-
Một vấn đề học lái xe robot
- Nhiệm vụ T: Lái xe trên đường cao tốc sử dụng cảm biến tầm nhìn
- Hiệu suất P : Khoảng cách trung bình đã đi trước khi xảy ra lỗi
- Trải nghiệm đào tạo E : Chuỗi hình ảnh và lệnh điều khiển được ghi lại khi quan sát người lái xe
Một chương trình máy tính học hỏi kinh nghiệm được gọi là chương trình học máy hay đơn giản là chương trình học tập.
2) Phân loại Machine Learning:
A. Supervised learning (Học có giám sát):
Học có giám sát (supervised learning) là nhiệm vụ học máy học một chức năng ánh xạ đầu vào (input) thành đầu ra (output) dựa trên các cặp đầu vào (input) - đầu ra mẫu (output). Dữ liệu đã cho được dán nhãn (labels) . Cả hai bài toán phân loại và hồi quy đều là bài toán học có giám sát.
B. Unsupervised learning (Học không giám sát):
Học không giám sát (Unsupervised learning) là thuật toán ML được sử dụng để đưa ra các suy luận từ các tập dữ liệu đầu vào (input) mà không được gán nhãn.
C. Reinforcement learning (Học tăng cường):
Học tăng cường là vấn đề khiến một tác nhân hành động để tối đa hóa phần thưởng nhận được. Người học không được cho biết những hành động cần thực hiện như trong hầu hết các hình thức học máy mà thay vào đó phải khám phá hành động nào mang lại nhiều phần thưởng nhất bằng cách thử chúng.
D. Semi-supervised learning (Học bán giám sát):
Học bán giám sát là một cách tiếp cận học máy kết hợp dữ liệu nhỏ được gắn nhãn với một lượng lớn dữ liệu không được gắn nhãn trong quá trình đào tạo. Học bán giám sát nằm giữa học không giám sát và học có giám sát.
3) ML thật chất là gì?
Arthur Samuel, người tiên phong trong lĩnh vực trí tuệ nhân tạo và lập trình game, đã đặt ra thuật ngữ “Machine Learning”. Ông định nghĩa máy học là một “Lĩnh vực nghiên cứu cung cấp cho máy tính khả năng học hỏi mà không cần lập trình rõ ràng”. Theo cách phổ thông hơn, Machine Learning (ML) có thể được giải thích là tự động hóa và cải thiện quá trình học tập của máy tính dựa trên kinh nghiệm của chúng mà không được lập trình thực sự, tức là không có bất kỳ sự trợ giúp nào của con người. Quá trình bắt đầu bằng việc cung cấp dữ liệu chất lượng tốt và sau đó đào tạo máy móc (máy tính) bằng cách xây dựng các mô hình máy học sử dụng dữ liệu và các thuật toán khác nhau. Việc lựa chọn thuật toán phụ thuộc vào loại dữ liệu và loại nhiệm vụ đang cố gắng tự động hóa.
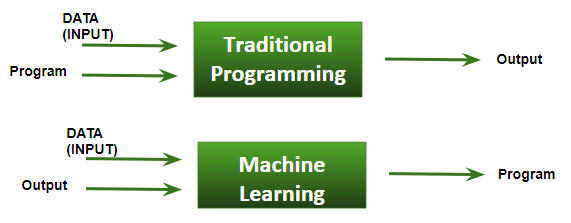
4) Sự khác biệt cơ bản giữa ML và lập trình truyền thống:
- Lập trình truyền thống: cung cấp DỮ LIỆU (Đầu vào) + CHƯƠNG TRÌNH (logic), chạy chương trình trên máy tính và nhận đầu ra.
- Học máy: cung cấp DỮ LIỆU (Đầu vào) + Đầu ra, chạy chương trình trên máy tính trong quá trình đào tạo và máy tính tự tạo chương trình (logic) riêng, chương trình này có thể được đánh giá trong khi thử nghiệm.
Chính xác việc học có ý nghĩa gì đối với máy tính? Một máy tính được cho là đang học hỏi từ Trải nghiệm đối với một số loại Tác vụ nếu hiệu suất của nó trong một tác vụ nhất định được cải thiện nhờ Trải nghiệm. Một chương trình máy tính được cho là học hỏi từ trải nghiệm E đối với một số loại nhiệm vụ T và phép đo hiệu suất P, nếu hiệu suất của nó ở các nhiệm vụ trong T, được đo bằng P, được cải thiện với trải nghiệm E. Ví dụ: chơi cờ, E = kinh nghiệm chơi nhiều ván cờ, T = nhiệm vụ chơi cờ, P = xác suất chương trình sẽ thắng trò chơi tiếp theo. Nói chung, bất kỳ vấn đề học máy nào cũng có thể được gán cho một trong hai cách phân loại chính: Học có giám sát và Học không giám sát.
5) Một vài ứng dụng thực tế:
- Nói về mua sắm trực tuyến, có hàng triệu người dùng với vô số sở thích về thương hiệu, màu sắc, phạm vi giá, v.v. Khi mua sắm trực tuyến, người mua có xu hướng tìm kiếm một số sản phẩm. Giờ đây, việc tìm kiếm một sản phẩm thường xuyên sẽ khiến Facebook, website, công cụ tìm kiếm hoặc cửa hàng trực tuyến của người mua bắt đầu đề xuất hoặc hiển thị ưu đãi cho sản phẩm cụ thể đó. Không có ai ngồi đó để mã hóa một nhiệm vụ như vậy cho từng người dùng, tất cả nhiệm vụ này là hoàn toàn tự động. Ở đây, ML đóng vai trò của nó. Các nhà nghiên cứu, nhà khoa học dữ liệu và kỹ sư ML xây dựng các mô hình trên máy tính bằng cách sử dụng chất lượng dữ liệu và lượng dữ liệu khổng lồ và giờ đây, máy tính của họ đang tự động hoạt động và thậm chí cải thiện với kinh nghiệm và thời gian ngày càng nhiều. Theo truyền thống, quảng cáo chỉ được thực hiện trên báo, tạp chí và đài phát thanh nhưng giờ đây công nghệ đã giúp chúng ta đủ thông minh để thực hiện Quảng cáo được nhắm mục tiêu (hệ thống quảng cáo trực tuyến), một phương pháp hiệu quả hơn để nhắm mục tiêu đối tượng dễ tiếp thu nhất.
- Ngay cả trong lĩnh vực chăm sóc sức khỏe, ML cũng đang làm một công việc tuyệt vời. Các nhà nghiên cứu và các nhà khoa học đã chuẩn bị các mô hình để đào tạo máy phát hiện ung thư chỉ bằng cách nhìn vào hình ảnh tế bào trượt. Để con người thực hiện nhiệm vụ này, nó sẽ mất rất nhiều thời gian. Nhưng bây giờ, không còn chậm trễ nữa, máy móc dự đoán khả năng mắc hay không mắc bệnh ung thư với độ chính xác nhất định và các bác sĩ chỉ cần đưa ra một cuộc gọi đảm bảo, thế là xong. Câu trả lời cho việc làm thế nào điều này có thể thực hiện được rất đơn giản, tất cả những gì cần thiết là một cỗ máy tính toán cao, một lượng lớn dữ liệu hình ảnh chất lượng tốt, mô hình ML với các thuật toán tốt để đạt được kết quả hiện đại. Các bác sĩ thậm chí đang sử dụng ML để chẩn đoán bệnh nhân dựa trên các thông số khác nhau đang được xem xét.
- Tất cả các bạn có thể phải sử dụng xếp hạng IMDB, Google Photos nơi nhận dạng khuôn mặt, Google Lens nơi mô hình nhận dạng văn bản hình ảnh, ML có thể trích xuất văn bản từ hình ảnh bạn cung cấp và Gmail phân loại E-mail là xã hội, quảng cáo, cập nhật, hoặc diễn đàn sử dụng phân loại văn bản, là một phần của ML.
6) Cách thức hoạt động của ML:
- Thu thập dữ liệu trong quá khứ dưới mọi hình thức phù hợp để xử lý. Chất lượng dữ liệu càng tốt thì càng phù hợp để mô hình hóa
- Xử lý dữ liệu – Đôi khi, dữ liệu được thu thập ở dạng thô và cần được xử lý trước. Ví dụ: Một số bộ dữ liệu có thể thiếu giá trị cho một số thuộc tính nhất định và trong trường hợp này, nó phải được điền các giá trị phù hợp để thực hiện học máy hoặc bất kỳ hình thức khai thác dữ liệu nào. Các giá trị bị thiếu cho các thuộc tính số như giá nhà có thể được thay thế bằng giá trị trung bình của thuộc tính trong khi các giá trị bị thiếu cho các thuộc tính phân loại có thể được thay thế bằng thuộc tính có chế độ cao nhất. Điều này luôn phụ thuộc vào loại bộ lọc sử dụng. Nếu dữ liệu ở dạng văn bản hoặc hình ảnh thì cần chuyển đổi nó sang dạng số, có thể là danh sách hoặc mảng hoặc ma trận. Đơn giản, Dữ liệu phải được làm cho phù hợp và nhất quán. Nó sẽ được chuyển đổi sang định dạng mà máy có thể hiểu được.
- Chia dữ liệu đầu vào thành các tập huấn luyện, xác thực chéo (cross-validation) và kiểm tra (test sets). Tỷ lệ giữa các bộ tương ứng phải là 6:2:2.
- Xây dựng mô hình với các thuật toán và kỹ thuật phù hợp trên tập huấn luyện.
- Thử nghiệm mô hình được khái niệm hóa với dữ liệu không được cung cấp cho mô hình tại thời điểm đào tạo và đánh giá hiệu suất của mô hình.
All rights reserved
