
Kỹ thuật Dropout (Bỏ học) trong Deep Learning
Bài đăng này đã không được cập nhật trong 5 năm
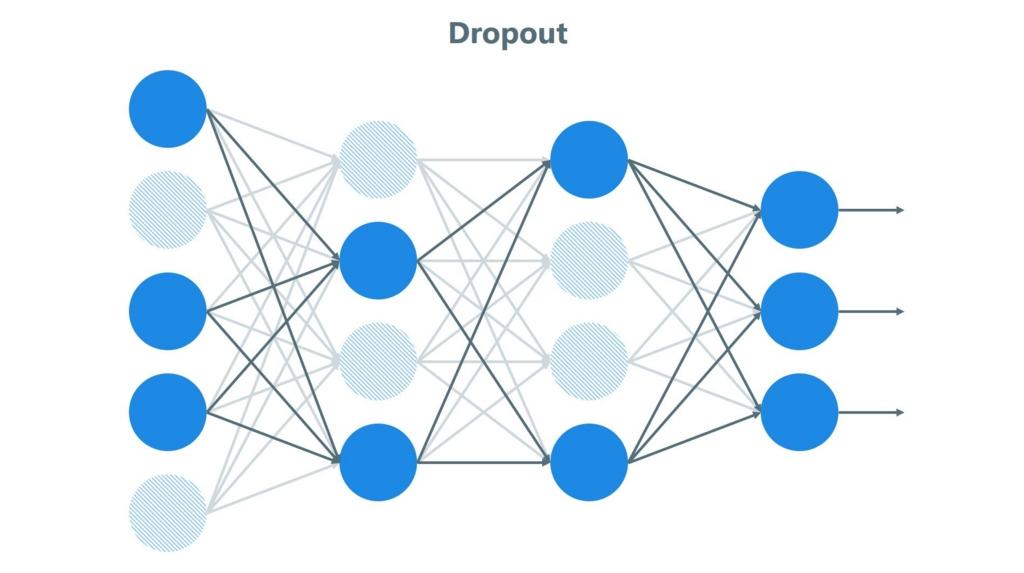 Trong bài viết này, mình xin phép giới thiệu về Dropout (Bỏ học) trong mạng Neural, sau đó là mình sẽ có 1 số đoạn code để xem Dropout ảnh hưởng thế nào đến hiệu suất của mạng Neural.
Trong bài viết này, mình xin phép giới thiệu về Dropout (Bỏ học) trong mạng Neural, sau đó là mình sẽ có 1 số đoạn code để xem Dropout ảnh hưởng thế nào đến hiệu suất của mạng Neural.
1. Lý thuyết
1.1. Dropout trong mạng Neural là gì
Theo Wikipedia - Thuật ngữ 'Dropout' đề cập đến việc bỏ qua các đơn vị (units) ẩn và hiện trong 1 mạng Neural.
Hiểu 1 cách đơn giản thì Dropout là việc bỏ qua các đơn vị (tức là 1 nút mạng) trong quá trình đào tạo 1 cách ngẫu nhiên. Bằng việc bỏ qua này thì đơn vị đó sẽ không được xem xét trong quá trình forward và backward. Theo đó, p được gọi là xác suất giữ lại 1 nút mạng trong mỗi giai đoạn huấn luyện, vì thế xác suất nó bị loại bỏ là (1 - p).
1.2. Tại sao lại cần Dropout
Câu hỏi là: Tại sao phải tắt 1 số nút mạng theo đúng nghĩa đen trong quá trình huấn luyện ? Câu trả lời là: Tránh học tủ (Over-fitting)
Nếu 1 lớp fully connected có quá nhiều tham số và chiếm hầu hết tham số, các nút mạng trong lớp đó quá phụ thuộc lẫn nhau trong quá trình huấn luyện thì sẽ hạn chế sức mạnh của mỗi nút, dẫn đến việc kết hợp quá mức.
1.3. Các kỹ thuật khác
Nếu bạn muốn biết Dropout là gì, thì chỉ 2 phần lý thuyết phía trên là đủ. Ở phần này mình cũng giới thiệu 1 số kỹ thuật có cùng tác dụng với Dropout.
Trong Machine Learning, việc chính quy hóa (regularization) sẽ làm giảm over-fitting bằng cách thêm 1 khoảng giá trị 'phạt' vào hàm loss. Bằng cách thêm 1 giá trị như vậy, mô hình của bạn sẽ không học quá nhiều sự phụ thuộc giữa các trọng số. Chắc hẳn nhiều người đã biết đến Logistic Regression thì đều biết đến L1 (Laplacian) và L2 (Gaussian) là 2 kỹ thuật 'phạt'.
-
Quá trình training: Đối với mỗi lớp ẩn, mỗi example, mỗi vòng lặp, ta sẽ bỏ học 1 cách ngẫu nhiên với xác suất (1 - p) cho mỗi nút mạng.
-
Quá trình test: Sử dụng tất cả các kích hoạt, nhưng sẽ giảm đi 1 hệ số p (để tính cho các kích hoạt bị bỏ học).
![]()
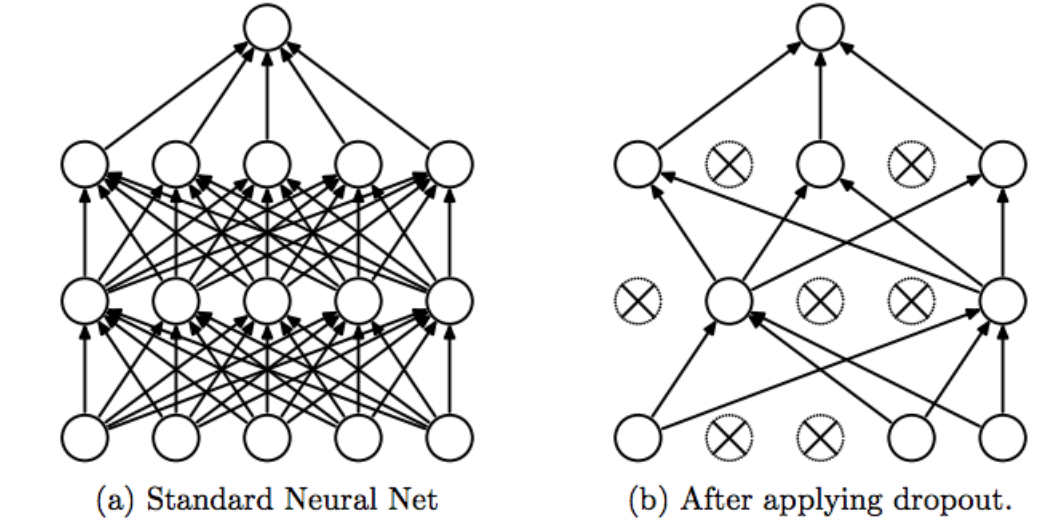
1.4. Một số nhận xét
- Dropout sẽ được học thêm các tính năng mạnh mẽ hữu ích
- Nó gần như tăng gấp đôi số epochs cần thiết để hội tụ. Tuy nhiên, thời gian cho mỗi epoch là ít hơn.
- Ta có H đơn vị ẩn, với xác suất bỏ học cho mỗi đơn vị là (1 - p) thì ta có thể có 2^H mô hình có thể có. Nhưng trong giai đoạn test, tất cả các nút mạng phải được xét đến, và mỗi activation sẽ giảm đi 1 hệ số p.
2. Thực hành
Nói thì hơi khó hiểu, nên mình sẽ code 2 phần để xem Dropout là như thế nào.
Đặt vấn đề: Bạn đi xem 1 trận đấu bóng đá và bạn thử dự đoán xem thủ môn sút vào vị trí nào thì cầu thủ nhà đánh đầu được quả bóng.
Mình import các thư viện cần thiết
# import packages
import numpy as np
import matplotlib.pyplot as plt
from reg_utils import sigmoid, relu, plot_decision_boundary, initialize_parameters, load_2D_dataset, predict_dec
from reg_utils import compute_cost, predict, forward_propagation, backward_propagation, update_parameters
import sklearn
import sklearn.datasets
import scipy.io
from testCases import *
%matplotlib inline
plt.rcParams['figure.figsize'] = (7.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
Visualize dữ liệu 1 chút
train_X, train_Y, test_X, test_Y = load_2D_dataset()
Ta được kết quả
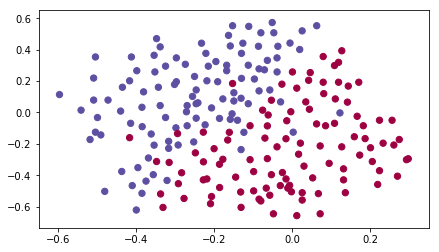
Dấu chấm đỏ là cầu thủ nhà đã từng đánh đầu, chấm xanh là cầu thủ bạn đánh đầu. Việc chúng ta là dự đoán xem thủ môn nên sút bóng vào khu vực nào để cầu thủ nhà đánh đầu được. Nhìn có vẻ như chỉ cần kẻ 1 đường thẳng để phân chia 2 khu vực là được.
2.1. Mô hình không có chính quy hóa
def model(X, Y, learning_rate = 0.3, num_iterations = 30000, print_cost = True):
"""
Triển khai mạng với 3 layer: LINEAR->RELU->LINEAR->RELU->LINEAR->SIGMOID.
Tham số:
X -- Dữ liệu đầu vào, kích thước (input size, number of examples)
Y -- 1 vector (1 là chấm xanh / 0 là chấm đỏ), kích thước (output size, number of examples)
learning_rate -- Tỷ lệ học
num_iterations -- Số epochs
print_cost -- Nếu là True, in ra coss cho mỗi 10000 vòng lặp
Returns:
parameters -- Tham số học được, được dùng để dự đoán
"""
grads = {}
costs = [] # to keep track of the cost
m = X.shape[1] # number of examples
layers_dims = [X.shape[0], 20, 3, 1]
# Initialize parameters dictionary.
parameters = initialize_parameters(layers_dims)
# Loop (gradient descent)
for i in range(0, num_iterations):
# Forward propagation: LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID.
a3, cache = forward_propagation(X, parameters)
# Cost function
cost = compute_cost(a3, Y)
grads = backward_propagation(X, Y, cache)
# Update parameters.
parameters = update_parameters(parameters, grads, learning_rate)
# Print the loss every 10000 iterations
if print_cost and i % 10000 == 0:
print("Cost after iteration {}: {}".format(i, cost))
if print_cost and i % 1000 == 0:
costs.append(cost)
# plot the cost
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (x1,000)')
plt.title("Learning rate =" + str(learning_rate))
plt.show()
return parameters
Hàm dự đoán
print("On the training set:")
predictions_train = predict(train_X, train_Y, parameters)
print("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
Xem kết quả
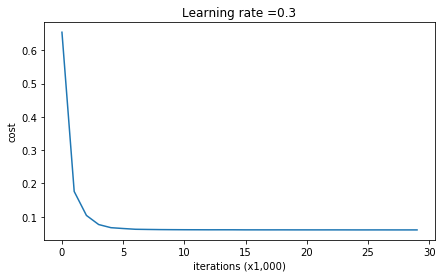
Cost after iteration 0: 0.6557412523481002
Cost after iteration 10000: 0.16329987525724216
Cost after iteration 20000: 0.13851642423255986
...
On the training set:
Accuracy: 0.947867298578
On the test set:
Accuracy: 0.915
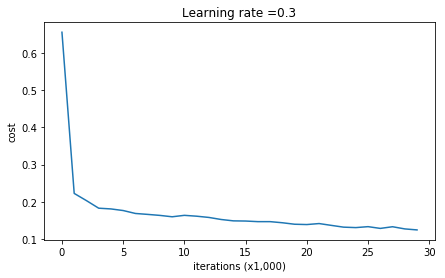
Có thể thấy độ chính xác ở tập training là 94% và tập test là 91% (khá cao). Ta sẽ visualize 1 chút
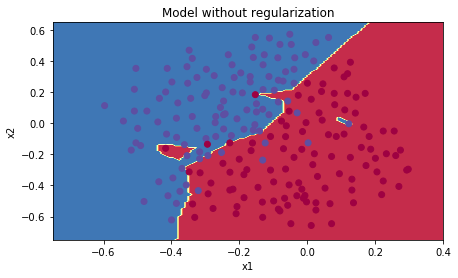
Khi không có chính quy hóa, ta thấy đường phân chia vẽ rất chi tiết, tức là nó đang over-fitting.
2.2. Mô hình chính quy hóa với Dropout
2.2.1. Quá trình Forward Propagation
def forward_propagation_with_dropout(X, parameters, keep_prob=0.5):
"""
Triển khai 3 layer: LINEAR -> RELU + DROPOUT -> LINEAR -> RELU + DROPOUT -> LINEAR -> SIGMOID.
Arguments:
X -- Dữ liệu đầu vào, kích thước (2, number of examples)
parameters -- Các đối số chúng ta có "W1", "b1", "W2", "b2", "W3", "b3":
W1 -- weight matrix of shape (20, 2)
b1 -- bias vector of shape (20, 1)
W2 -- weight matrix of shape (3, 20)
b2 -- bias vector of shape (3, 1)
W3 -- weight matrix of shape (1, 3)
b3 -- bias vector of shape (1, 1)
keep_prob - xác suất giữ lại 1 unit
Returns:
A3 -- giá trị đầu ra mô hình, kích thước (1,1)
cache -- lưu các đối số để tính cho phần Backward Propagation
"""
np.random.seed(1)
# retrieve parameters
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
W3 = parameters["W3"]
b3 = parameters["b3"]
# LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID
Z1 = np.dot(W1, X) + b1
A1 = relu(Z1)
### START CODE HERE ### (approx. 4 lines) # Steps 1-4 below correspond to the Steps 1-4 described above.
D1 = np.random.rand(A1.shape[0], A1.shape[1]) # Step 1: khởi tạo ngẫu nhiên 1 ma trận kích thước bằng kích thước A1, giá trị (0, 1)
D1 = D1 < keep_prob # Step 2: chuyển các giá trị về 0 hoặc 1, trả về 1 nếu giá trị đó nhỏ hơn keep_prob
A1 = A1 * D1 # Step 3: giữ nguyên các phần tự trong A1 ứng với phần tử 1 của D1, và đổi thành 0 nếu vị trị trong D1 tương tứng là 0
A1 = A1 / keep_prob # Step 4: giảm đi 1 hệ số keep_prob, để tính cho các phần tử đã bỏ học.
### END CODE HERE ###
Z2 = np.dot(W2, A1) + b2
A2 = relu(Z2)
### START CODE HERE ### (approx. 4 lines)
D2 = np.random.rand(A2.shape[0], A2.shape[1])
D2 = D2 < keep_prob
A2 = A2 * D2
A2 = A2 / keep_prob
### END CODE HERE ###
Z3 = np.dot(W3, A2) + b3
A3 = sigmoid(Z3)
cache = (Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3)
return A3, cache
2.2.2. Quá trình Backward Propagation
def backward_propagation_with_dropout(X, Y, cache, keep_prob):
Các đối số:
X -- Dữ liệu đầu vào, kích thước (2, number of examples)
Y -- kích thước (output size, number of examples)
cache -- lưu đầu ra của forward_propagation_with_dropout()
keep_prob - như forward
Returns:
gradients -- Đạo hàm của tất cả các weight, activation
"""
m = X.shape[1]
(Z1, D1, A1, W1, b1, Z2, D2, A2, W2, b2, Z3, A3, W3, b3) = cache
dZ3 = A3 - Y
dW3 = 1. / m * np.dot(dZ3, A2.T)
db3 = 1. / m * np.sum(dZ3, axis=1, keepdims=True)
dA2 = np.dot(W3.T, dZ3)
### START CODE HERE ### (≈ 2 lines of code)
dA2 = dA2 * D2 # Step 1: Áp dụng D2 để tắt các unit tương ứng với forward
dA2 = dA2 / keep_prob # Step 2: Giảm giá trị 1 hệ số keep_prob
### END CODE HERE ###
dZ2 = np.multiply(dA2, np.int64(A2 > 0))
dW2 = 1. / m * np.dot(dZ2, A1.T)
db2 = 1. / m * np.sum(dZ2, axis=1, keepdims=True)
dA1 = np.dot(W2.T, dZ2)
### START CODE HERE ### (≈ 2 lines of code)
dA1 = dA1 * D1
dA1 = dA1 / keep_prob
### END CODE HERE ###
dZ1 = np.multiply(dA1, np.int64(A1 > 0))
dW1 = 1. / m * np.dot(dZ1, X.T)
db1 = 1. / m * np.sum(dZ1, axis=1, keepdims=True)
gradients = {"dZ3": dZ3, "dW3": dW3, "db3": db3,"dA2": dA2,
"dZ2": dZ2, "dW2": dW2, "db2": db2, "dA1": dA1,
"dZ1": dZ1, "dW1": dW1, "db1": db1}
return gradients
Sau khi có Forward và Backward, ta thay 2 hàm này vào hàm model của phần trước:
parameters = model(train_X, train_Y, keep_prob=0.86, learning_rate=0.3)
print("On the train set:")
predictions_train = predict(train_X, train_Y, parameters)
print("On the test set:")
predictions_test = predict(test_X, test_Y, parameters)
Kết quả:
Cost after iteration 10000: 0.06101698657490559
Cost after iteration 20000: 0.060582435798513114
...
On the train set:
Accuracy: 0.928909952607
On the test set:
Accuracy: 0.95
Ta thấy, độ chính xác trong tập test đã lên đến 95%, mặc dù tập training bị giảm. Thực hiện visualize:
plt.title("Model with dropout")
axes = plt.gca()
axes.set_xlim([-0.75, 0.40])
axes.set_ylim([-0.75, 0.65])
plot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)
Ta được
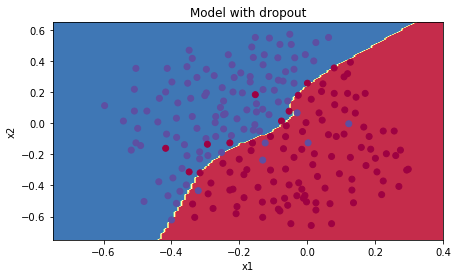
Ta thấy đường phân chia không quá chi tiết, nên đã tránh được over-fitting.
2.3. Chú ý
- Không dùng Dropout cho quá trình test
- Áp dụng Dropout cho cả quá trình Forward và Backward
- Giá trị kích hoạt phải giảm đi 1 hệ số keep_prob, tính cả cho những nút bỏ học.
Tham khảo
Cảm ơn mọi người đã xem bài viết 
All rights reserved
